Blog
Practical writing on LLM application architecture, model routing, cost optimization, and operating AI systems in production.
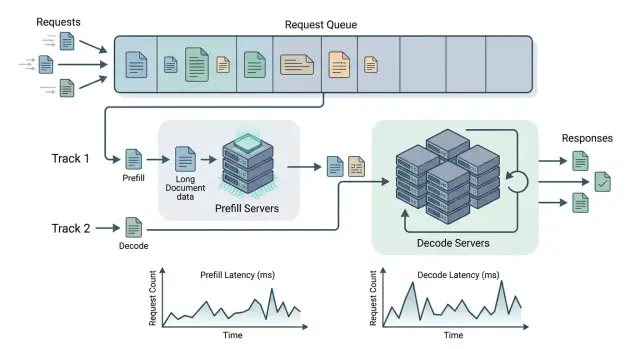
separating prefill and decodelong-context LLMinference latency
Separating prefill and decode for long documentsApr 27, 2026·8 min read
We look at when separating prefill and decode reduces latency on long documents, and when it only adds extra queues, risk, and cost.
Latest posts
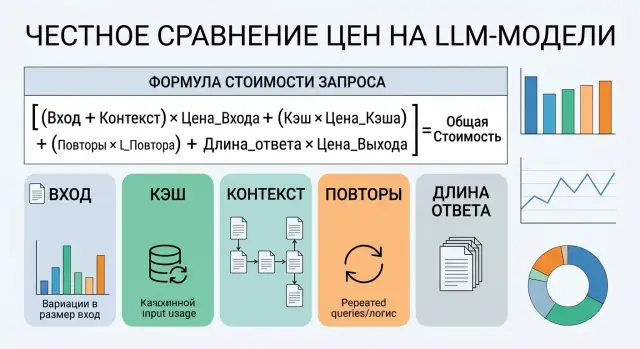
Apr 26, 2026·7 min read
How to Compare LLM Model Prices Without Calculation Mistakes
How to compare LLM prices: calculate input, cache, context, retries, and response length, not just the price per million tokens.
how to compare LLM model pricesprice per million tokens

Apr 22, 2026·8 min read
Versioning Tool Schemas Without Breaking Agents
Tool schema versioning lets you change fields and rules without outages: how to introduce versions, keep compatibility, and catch errors early.
tool schema versioningAPI backward compatibility

Apr 20, 2026·9 min read
LLM Production Deployment: What to Check After the Pilot
A practical guide to moving an LLM from pilot to production: limits, observability, access control, model selection, common mistakes, and a launch checklist.
LLM production deploymentLLM observability
Apr 09, 2026·6 min read
Code-switching in Chats: What Breaks in Russian-Kazakh Dialogue
Code-switching in chats often breaks meaning, tone, and facts in replies. This pre-release review framework helps catch failures in Russian-Kazakh dialogues.
code-switching in chatsRussian-Kazakh chats

Apr 06, 2026·10 min read
Internal Model Catalog: Statuses and Rules
An internal model catalog helps teams see model status, access, and retirement timelines so they do not choose models blindly.
internal model catalogmodel statuses

Apr 01, 2026·8 min read
Testing LLM Hallucinations for Banks, Clinics, and Public Services
Testing LLM hallucinations for banking, medical, and government responses: a risk scale, testing scenarios, common mistakes, and a checklist.
LLM hallucination testingAI answer risk scale
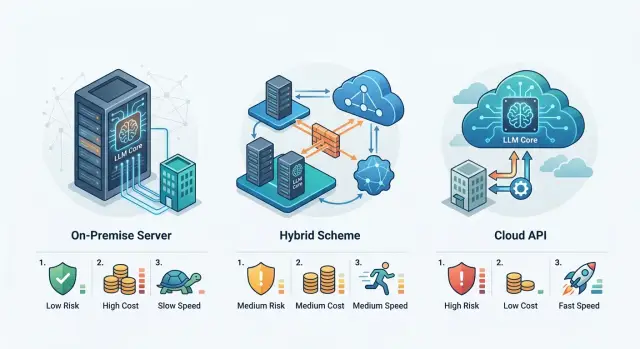
Apr 01, 2026·8 min read
Data Residency for LLMs: Local, Hybrid, or API
Data residency for LLMs helps compare local hosting, hybrid setups, and external APIs by risk, cost, and launch time.
data residency for LLMslocal LLM hosting
Mar 29, 2026·8 min read
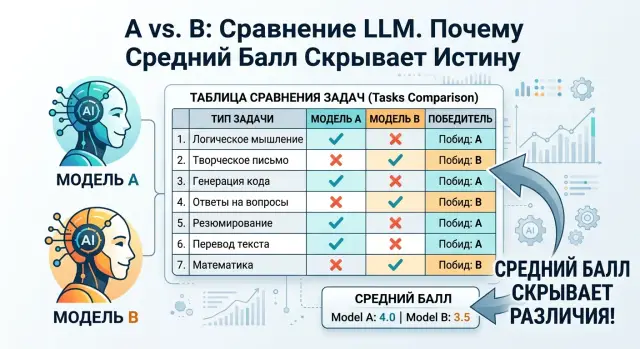
Pairwise model comparisons: where A beats B without an average score
Pairwise model comparisons show where one LLM wins at data extraction and another wins at chat, summarization, and long answers.
pairwise model comparisonsevaluating LLMs by task
Mar 28, 2026·8 min read
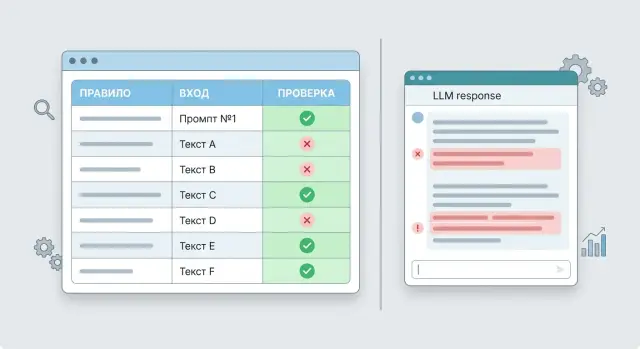
Prompt Unit Tests: How to Catch Errors Before Release
Prompt unit tests help check rules, templates, and edge cases without reading every answer by hand. We’ll show a test format and a simple checklist.
prompt unit testsprompt testing
Mar 25, 2026·6 min read
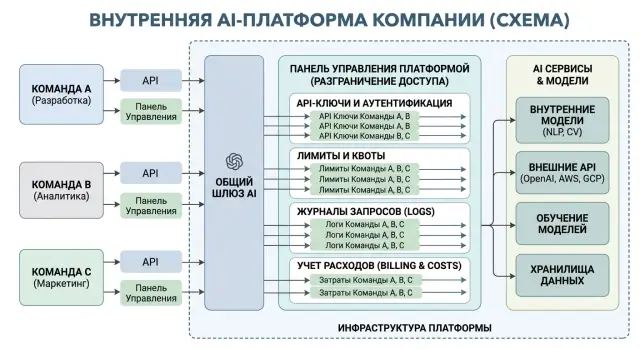
Multi-tenancy in an AI platform without extra services
Multi-tenancy in an AI platform helps teams separate keys, limits, logs, and spending without a separate stack of services.
multi-tenancy in an AI platformAPI key separation
Mar 21, 2026·10 min read
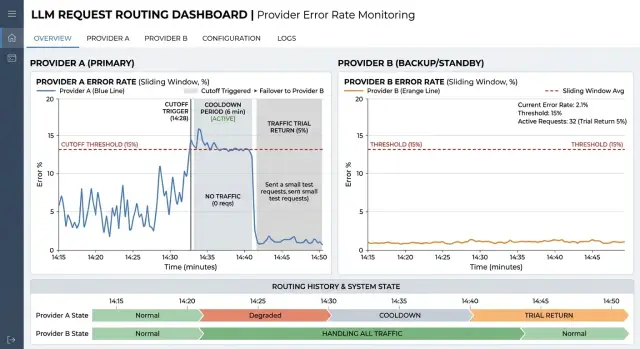
Automatic Provider Cut-Off on Failures Without Flapping
Automatic provider cut-off during failures reduces cascading errors. We look at error windows, thresholds, traffic return, and quick checks before production.
automatic provider cut-off during failureserror window
Mar 21, 2026·9 min read
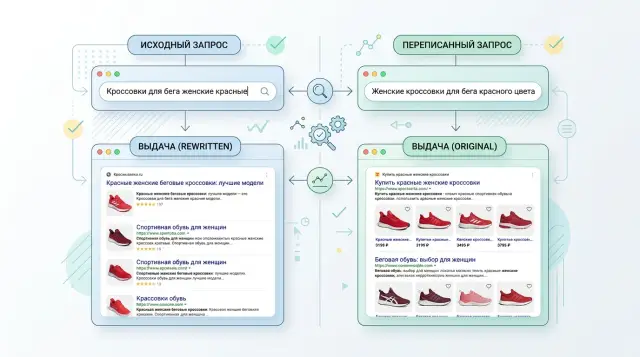
Testing query rewriting: how not to lose the meaning of a query
Testing query rewriting helps reveal when a rewritten query improves search results and when it distorts meaning. We cover metrics, tests, and common mistakes.
query rewriting testingevaluating query rewriting
Mar 18, 2026·8 min read
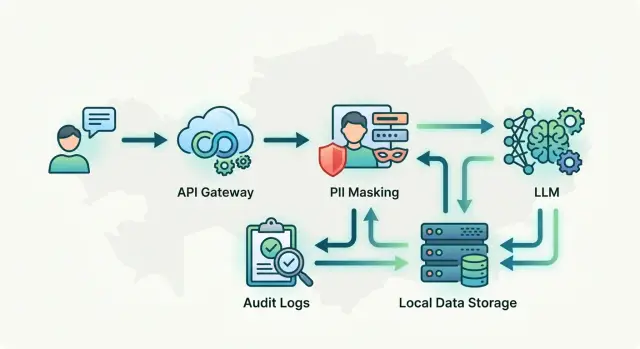
Storing Data in Kazakhstan for LLMs Without the Extra Complexity
Storing data in Kazakhstan for LLMs: a simple setup for requests, logs, and PII masking that meets local requirements without extra layers.
data storage in KazakhstanLLM architecture
Mar 13, 2026·7 min read
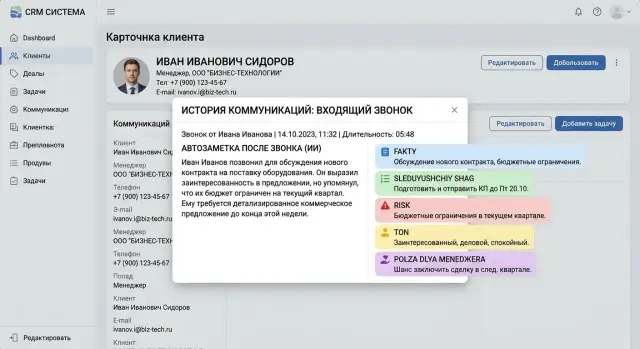
Auto-Notes in CRM: How to Judge Completeness, Tone, and Usefulness
Auto-notes in CRM should be judged not by smooth wording, but by facts, tone, and usefulness for the manager. We break down the criteria, common mistakes, and a practical checklist.
auto-notes in CRMpost-call note evaluation

Mar 07, 2026·7 min read
Step Limits for AI Agents and Spend Control in Production
Step limits for AI agents help keep spend under control: set a session budget, rule-based retries, and stop conditions.
step limits for AI agentssession budget
Mar 07, 2026·6 min read
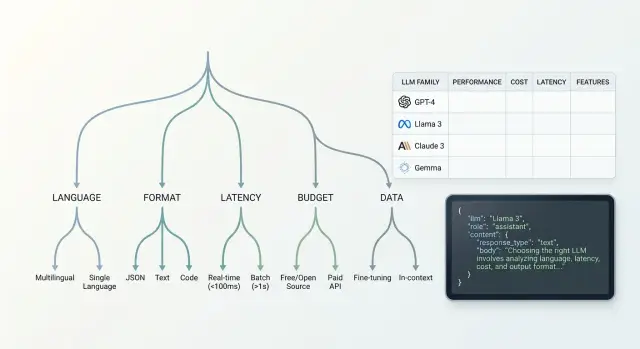
Choosing a Model Family for a New Feature: A Decision Tree
Choosing a model family for a new feature: we break down the decision tree by language, response format, latency, budget, and data requirements.
model family selectiondecision tree for LLMs
Feb 28, 2026·7 min read
Dense, sparse, and hybrid retrieval: how to compare them fairly
Dense, sparse, and hybrid retrieval can be compared fairly if you align the corpus, queries, metrics, and chunking rules for different document types in advance.
dense, sparse, and hybrid retrievalfair retrieval test
Feb 16, 2026·11 min read
Tool Calling Across Multiple Providers Without Surprises
Tool calling across multiple providers often breaks on schemas, types, and error codes. Let’s look at what to check before production.
tool calling across multiple providersLLM tool calling
Feb 15, 2026·6 min read
Separating access to prompts and data: a role scheme
Separating access to prompts and data reduces the risk of log leaks, helps you set team roles, and does not get in the way of everyday development.
separating access to prompts and dataLLM access roles

Feb 10, 2026·10 min read
Questions to Ask an LLM Provider Before Signing a Contract: What to Clarify
Questions for an LLM provider help you check logs, data retention, model updates, and what happens during outages and incidents before signing the contract.
questions for an LLM providerLLM provider contract
Feb 10, 2026·8 min read
Tail latency in LLMs: how to find the slowest 1% of requests
Tail latency in LLMs often hides in long prompts, cold models, and tools. We show how to find the slowest 1% and remove the bottlenecks.
LLM tail latencyslow LLM requests

Feb 08, 2026·10 min read
OCR or a Vision Model for Documents: How to Choose
OCR or a vision model for documents — the right choice depends on scan quality, tables, stamps, and page structure. We break down the signals and a simple testing process.
OCR vs. vision model for documentsmultimodal document input

Feb 05, 2026·6 min read
Microbatching LLM Calls: How to Cut Costs Without Breaking SLA
Microbatching LLM calls helps cut the cost of internal tasks without adding too much latency. We’ll look at where batches make sense, how to protect SLA, and what to measure.
LLM microbatchingreducing LLM cost
Feb 03, 2026·10 min read
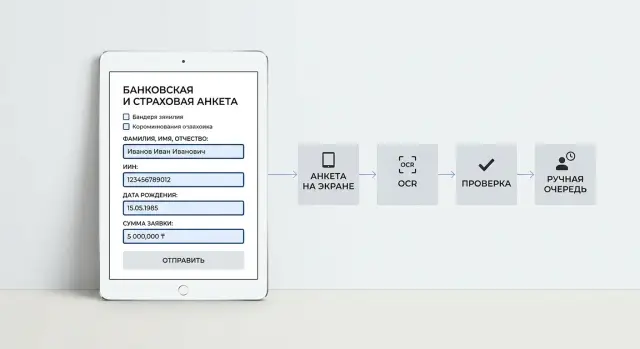
Field Extraction from Applications: OCR, Validation, and Manual Review
We show how to set up field extraction from applications: choose OCR, validate the data, send borderline cases for manual review, and reduce errors.
field extraction from applicationsOCR for forms
Jan 28, 2026·8 min read
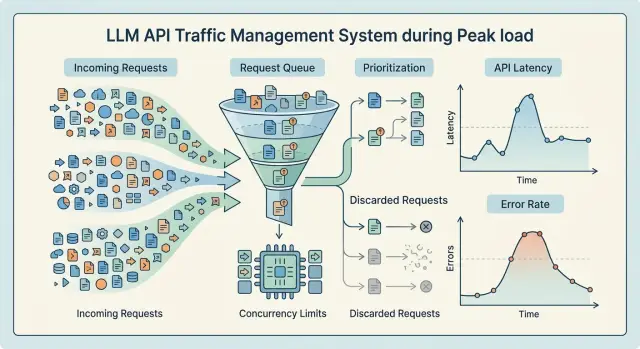
Backpressure for an LLM Service Without a Cascade Failure
Backpressure for an LLM service helps you survive traffic spikes: we break down queues, limits, and dropping low-priority requests without a cascade failure.
backpressure for an LLM serviceLLM request queues

Jan 25, 2026·9 min read
OCR Before an LLM: How to Measure Loss on Document Scans
OCR before an LLM helps read scans of contracts and medical forms, but errors pile up. Let’s break down metrics, human review thresholds, and a simple process.
OCR before LLMdocument scans

Jan 24, 2026·10 min read
Audit Logs for LLMs: What Banks and the Public Sector Should Store
LLM audit logs help banks and public agencies investigate incidents: what to put in each event, how long to keep records, and who should have access.
LLM audit logsLLM event payload
Jan 23, 2026·11 min read
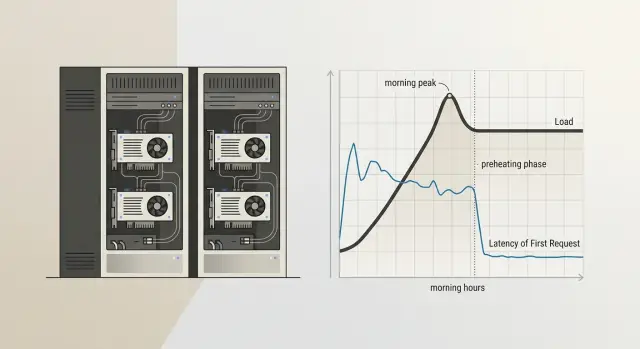
Cold start in a self-hosted model: how to eliminate delays
A self-hosted model cold start adds extra seconds to the first request of the day. Here’s how to handle warm-up, a ready-replica pool, and a schedule without unnecessary cost.
self-hosted model cold startmodel warm-up
Jan 20, 2026·9 min read
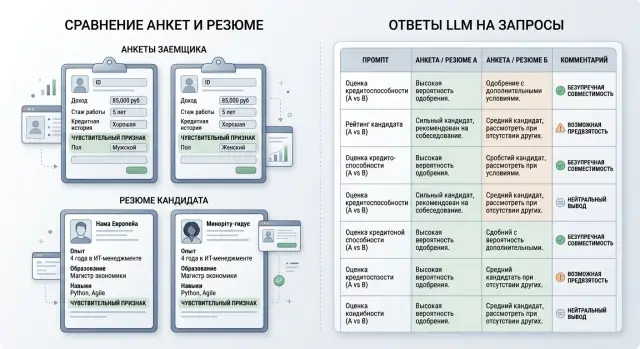
Bias Test: Which Case Pairs to Run Before Launch
Bias testing before launching an LLM for scoring and hiring: which paired cases to build, what to vary in each pair, and how to check the model’s responses.
bias testpaired cases for LLM

Jan 17, 2026·10 min read
API Change Log for LLM Providers Without Production Breakages
An API change log helps you spot new fields, limits, and method removals in time so you can verify integrations before production breaks.
API change logLLM API changes

Jan 15, 2026·7 min read
Models for a Russian and Kazakh Assistant: How to Choose
A practical guide to choosing assistant models for Russian and Kazakh: what to check in mixed requests, language switching, and business tasks.
models for a Russian and Kazakh assistantmixed queries for LLMs

Jan 14, 2026·10 min read
Quote first, then interpretation: how to structure the answer
Quote first, then interpretation helps show what the conclusion is based on. Let’s look at where this format is needed and how to use it without confusion.
quote first, then interpretationanswer with source support
Jan 11, 2026·9 min read
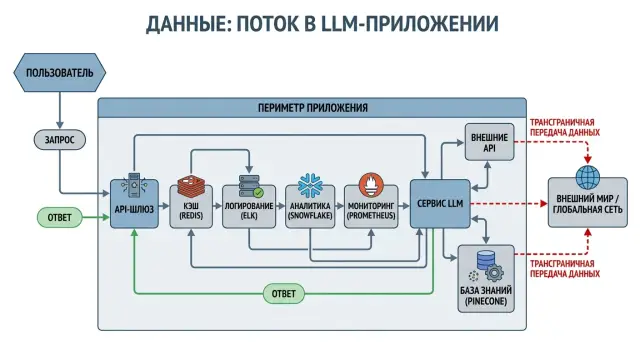
Cross-Border Data Transfer in LLMs: Risks Beyond the API
Cross-border data transfer in LLMs does not happen only in the model call, but also in logs, analytics, and supporting services. Let’s look at the risk points.
cross-border data transfer in LLMsLLM application logs
Jan 10, 2026·10 min read
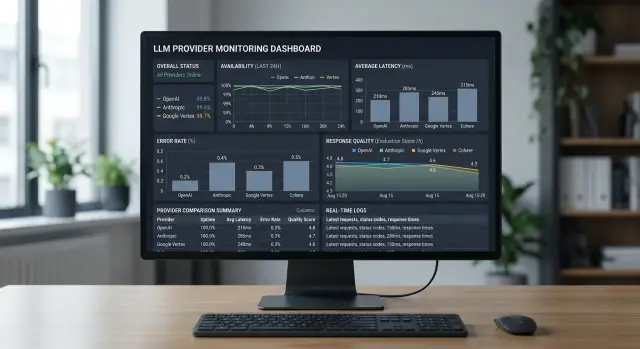
Provider Health Scoring by Your Own Metrics for LLMs
Provider health scoring helps you see real outages, latency spikes, and quality drops on your own requests, not on a generic status page.
provider health scoringLLM API availability

Jan 08, 2026·6 min read
LLM Pricing Comparison: How to Calculate the Final Price Fairly
LLM pricing comparisons often break because providers use different billing units. We show a conversion table, formulas, and scenarios where a low rate still leads to a high final bill.
LLM pricing comparisontoken cost

Jan 07, 2026·9 min read
Contract tests for OpenAI-compatible providers
Contract tests for OpenAI-compatible providers help you find failures in streaming, tools, embeddings, and error formats in about an hour before release.
contract tests for OpenAI-compatible providersOpenAI API compatibility

Dec 31, 2025·8 min read
Fine-tune a model on internal correspondence without losing style
We’ll show how to fine-tune a model on internal correspondence: choose emails and chats, remove noise, check style, and avoid carrying mistakes into answers.
fine-tune a model on internal correspondencellm dataset cleaning
Dec 26, 2025·10 min read
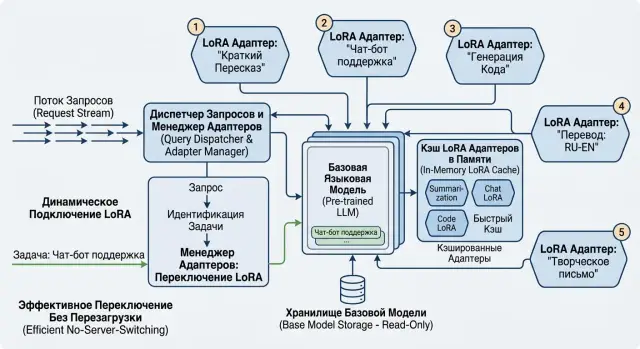
LoRA Adapters for One Model: Storage and Switching
We look at how to store LoRA adapters for one model, quickly pick the right variant on demand, and avoid running a separate server for every scenario.
LoRA adapters for one modelLoRA adapter storage
Dec 24, 2025·9 min read
Semantic caching in conversations: how to measure benefit and risk
Learn how to evaluate semantic caching in conversations: hit rate, false positives, token savings, cost, and time savings in long sessions.
semantic cache in dialoguesmeasuring cache hits

Dec 17, 2025·10 min read
Model Selection for Compliance: How to Build a Fact Pack
Model selection for compliance is easier to approve when you bring facts: logs, risks, retention periods, access rules, and a list of controls.
LLM model selection for complianceLLM selection card

Dec 13, 2025·6 min read
Model and Provider Update Calendar Inside the Team
A model and provider update calendar helps product, analytics, and compliance teams stay aligned on releases, replacements, and deadlines.
model and provider update calendarmodel release synchronization
Dec 12, 2025·6 min read
Idempotent LLM Requests Without Double Charges
Idempotent LLM requests help avoid double charges, duplicate responses, and unnecessary retries during timeouts, network failures, and repeated clicks.
idempotent LLM requestsdouble API charges

Dec 11, 2025·6 min read
A/B Test Prompt or Model: How to Tell What Worked
A/B tests for a prompt or model can easily produce false conclusions if you change everything at once. Learn how to test the prompt, model, and route separately.
A/B testing a prompt or modelLLM model comparison

Dec 03, 2025·8 min read
Answer Stability at Temperature 0: How to Measure Risk
Temperature 0 does not guarantee the same result. We break down why answers drift and how to measure the risk in your own workflows.
answer stability at temperature 0LLM determinism
Dec 02, 2025·8 min read
Metadata in RAG: Which Filters Actually Improve Answers
Metadata in RAG helps narrow search by date, document type, and access rights, but extra filters often hurt recall and degrade the answer.
metadata in RAGRAG filters

Dec 02, 2025·8 min read
Unified Token Accounting Across Providers Without Disputes
Unified token accounting brings input, output, cache, and service fields into one data model so invoices, logs, and reports match.
unified token accountingtoken normalization

Dec 01, 2025·10 min read
Reversible Data Pseudonymization: Where to Store the Mapping Table
Reversible data pseudonymization helps investigate incidents without broad access to PII. Learn where to store the mapping table and who should be allowed to reverse the lookup.
reversible data pseudonymizationpersonal data mapping table
Nov 28, 2025·9 min read
Model fallbacks without extra cost: how not to pay twice
Model fallbacks help you survive failures, but without rules they quickly double the bill. Here we break down the chains, limits, and checks that keep costs under control.
model fallbacksbackup models
Nov 25, 2025·7 min read
Stop Sequences in Production Without Garbage After JSON
Stop sequences in production help cut off model output right after JSON, emails, or quotes without extra text or broken formatting.
stop sequencesstop tokens

Nov 22, 2025·7 min read
AI Feature Kill Switch: How to Stop Risk in a Minute
An AI feature kill switch lets you instantly turn off chat, autocomplete, or an agent without a release. We’ll break down the setup, team roles, and fast checks.
AI feature kill switchAI emergency shutdown

Nov 22, 2025·9 min read
A Benchmark for the Kazakh Language Based on Real-World Scenarios
A Kazakh-language benchmark should be built on real scenarios: customer requests, forms, search, and support. Let’s look at the dataset, metrics, and common mistakes.
benchmark for the Kazakh languageLLM evaluation in Kazakh

Nov 19, 2025·10 min read
Internal AI cost billing without disputes
Internal billing for AI costs helps allocate expenses by product, explain the bill without talking about tokens, and reduce disputes between teams.
internal AI cost billingLLM cost accounting
Nov 17, 2025·6 min read
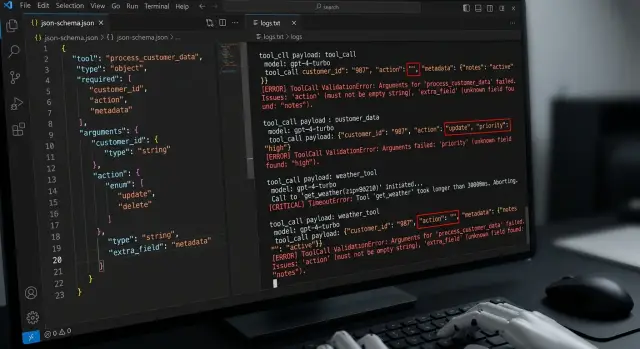
Testing tool calling: what breaks beyond the happy path
Tool calling testing is more than the happy path. This article covers empty arguments, extra fields, wrong types, timeouts, and retries.
tool calling testingtool call errors
Nov 11, 2025·8 min read
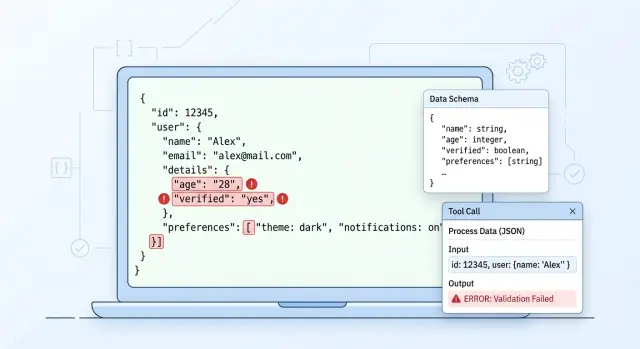
LLM Structured Output: Why It Breaks in Production
LLM structured output often breaks in production because of malformed JSON, schema drift, and tool-calling failures. We'll cover checks and retries.
LLM structured outputJSON errors
Nov 05, 2025·9 min read
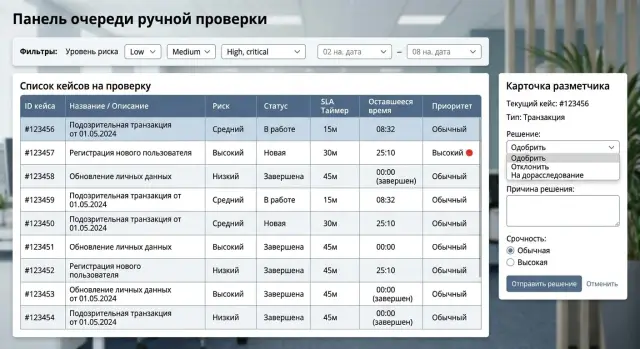
Manual Review Queue Without Backlog: How to Set SLA
The manual review queue should not grow on its own. We break down case priorities, SLA, escalation rules, and a reviewer-friendly interface.
manual review queuecase prioritization

Nov 01, 2025·10 min read
Reasoning Model or Regular Model: When to Pay More
Reasoning model or regular model: we break down where an expensive answer pays off and where a fast answer is cheaper and more useful for production.
reasoning model or regular modelLLM cost per task
Oct 31, 2025·11 min read
Key-Level Request Limits for Teams Without the Chaos
Key-level request limits help separate load by service, environment, and role so a noisy client doesn't slow down everyone else.
key-level request limitsAPI request limiting
Oct 28, 2025·11 min read
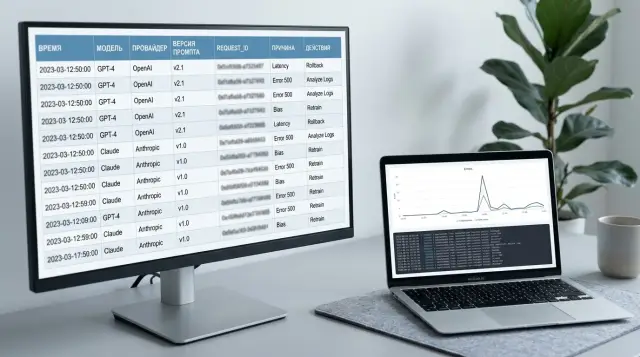
LLM Postmortem After an Outage: Which Fields Should You Capture
A practical guide to writing an LLM postmortem after an outage: which fields to record, who fills them in, and how to turn lessons into release tasks.
LLM postmortemLLM incident review
Oct 26, 2025·10 min read
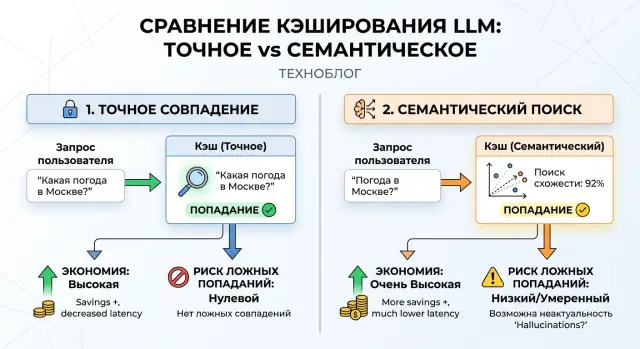
Semantic Cache vs Exact Match: Where the Savings Are Greater
We look at when exact match saves more, and when semantic caching catches more repeats but starts returning someone else’s answers.
semantic cacheexact match

Oct 24, 2025·8 min read
Document Chunking for RAG: How to Test It
Compare chunk sizes, overlap, and reranking on one question set to choose RAG document chunking based on data, not opinion.
RAG document chunkingchunk size
Oct 21, 2025·6 min read
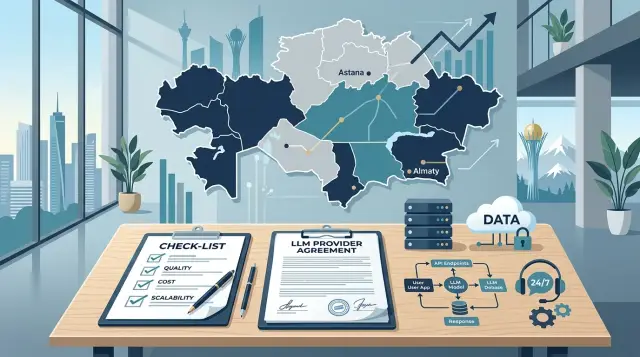
Choosing an LLM Provider for a Company in Kazakhstan: Questions
Choosing an LLM provider for a company in Kazakhstan is easier when you start with a list of questions: where data is stored, what documents are available, SLA, support, and API compatibility.
choosing an LLM provider for a company in KazakhstanLLM data storage in Kazakhstan
Oct 21, 2025·11 min read
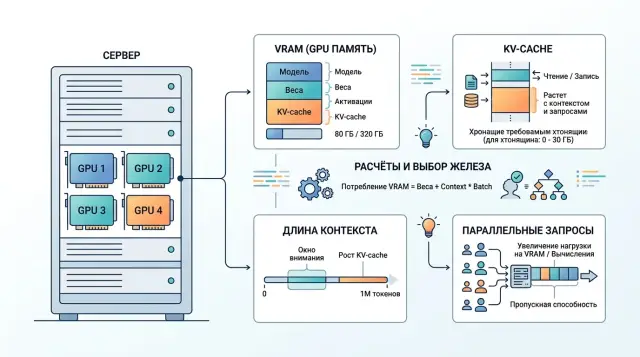
GPU for open-weight models: VRAM, context, and KV-cache
GPU for open-weight models are not chosen by VRAM alone. We explain how context length, KV-cache, and parallelism change the GPU sizing calculation.
GPU for open-weight modelsKV-cache size

Oct 16, 2025·10 min read
KV-cache Reuse in Long Conversations
KV-cache reuse speeds up long conversations when requests share the same opening history. We’ll cover the setup, risks, metrics, and checks.
KV-cache reusespeeding up long LLM conversations
Oct 13, 2025·10 min read
User Feedback for Eval: How Not to End Up with a Folder of Screenshots
User feedback for eval turns “helpful” and “error” buttons into a task queue: what to collect, how to label it, and what to check.
user feedback for evalhelpful and error buttons
Oct 09, 2025·9 min read
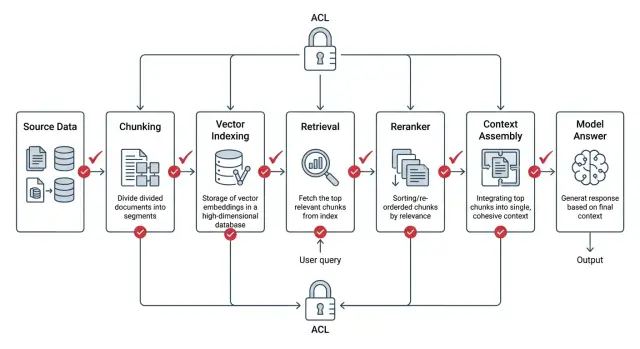
ACL in RAG: How to Lock Down Access at the Document Level
ACL in RAG must be applied before search, during ranking, and while assembling context. We show the setup, common mistakes, and a short checklist.
ACL in RAGaccess rights in search
Oct 09, 2025·8 min read
Migrating to a New Embedding Model: What to Check
Migrating to a new embedding model requires checking dimensionality, search quality, speed, memory, and compatibility with old vectors.
migration to a new embedding modelembedding dimensionality
Oct 06, 2025·11 min read
Canary model release: traffic, stop metrics, rollback
A canary model release helps you test a new version on 1-50% of traffic, define stop metrics, and keep a report so you can roll back the decision in minutes.
canary model releaseLLM traffic percentages

Oct 04, 2025·7 min read
Separating Access Rights for an AI Assistant Without Leaks
Separating permissions for an AI assistant helps keep knowledge search separate from answer generation. We’ll cover the architecture, common mistakes, and checks before launch.
access rights separation for AI assistantknowledge base access control
Sep 29, 2025·7 min read
End-to-End trace_id for LLM Requests Without Blind Spots
End-to-end trace_id for LLM requests helps tie the model response, search, tool calls, and application logs into one incident review.
end-to-end trace_id for LLM requestsLLM incident debugging
Sep 27, 2025·8 min read
Local Model Hosting: What to Keep in the Country and What Not To
Local model hosting helps separate risky scenarios from everyday ones. Here is what to keep in Kazakhstan and what to leave on an external API.
local model hostingopen-weight models

Sep 20, 2025·11 min read
Support ticket benchmark: how to build a live set
A support ticket benchmark helps test a model on real cases. We cover anonymization, labeling, and how to launch the first set quickly.
support ticket benchmarksupport conversation anonymization
Sep 15, 2025·9 min read
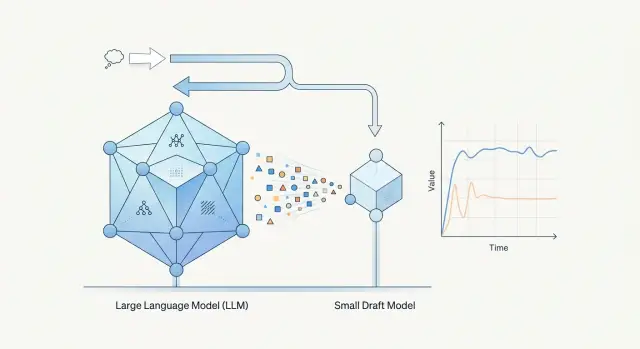
Speculative Decoding: Where It Speeds Things Up and Where It Doesn’t
Speculative decoding doesn’t always speed up LLMs. We’ll show where a draft model really cuts latency—and where it eats the gain instead.
speculative decodingdraft model
Sep 12, 2025·11 min read
Multi-provider LLM access without rewriting the SDK
Multi-provider LLM access: how to build a single endpoint, shared authentication, and fallback without changing SDKs or adding extra logic to your code.
multi-provider LLM accesssingle LLM endpoint

Sep 11, 2025·8 min read
SDK Compatibility After Changing base_url: Where It Breaks
SDK compatibility after changing base_url often breaks not at authentication, but in streaming, tool calls, and JSON schemas. Here are the common failures.
SDK compatibility after changing base_urlLLM response streaming

Sep 04, 2025·7 min read
Retiring a Model Without Breaking the Product
Model retirement needs a plan: notify teams, check dependencies, keep a dual-support window, and move traffic in stages.
decommissioning a modeldual-support window
Sep 01, 2025·7 min read
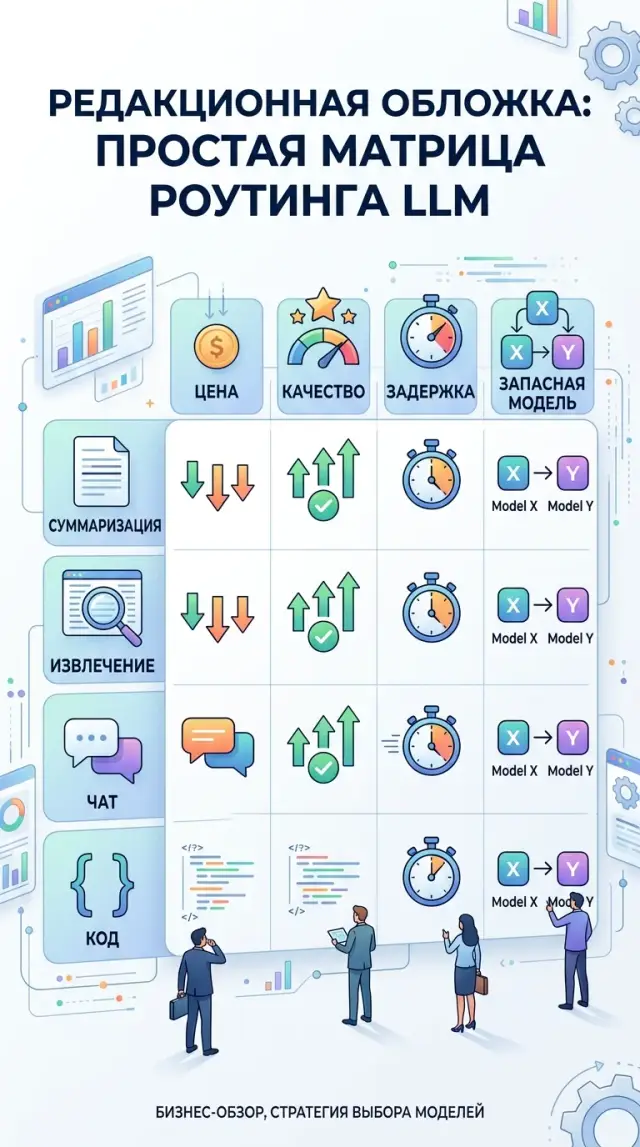
Task-based routing: a model matrix without unnecessary costs
Task-based routing helps you choose models for summarization, extraction, chat, and code in a way that lowers costs without sacrificing quality.
task-based routingmodel selection matrix

Aug 27, 2025·9 min read
LLM Latency Budget: Where Time Goes in a Request
Learn how to break down an LLM latency budget across network, routing, model, and post-processing so you can find bottlenecks from data, not guesswork.
LLM latency budgetLLM API latency
Aug 23, 2025·6 min read
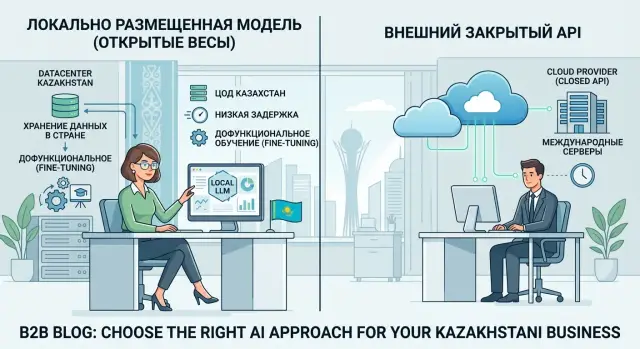
Open-Weight Model or Closed One: Where Each Works Best
An open-weight model often wins where local data storage, low latency, and fine-tuning for your own processes matter most.
open-weight modeldata storage in the country
Aug 23, 2025·9 min read
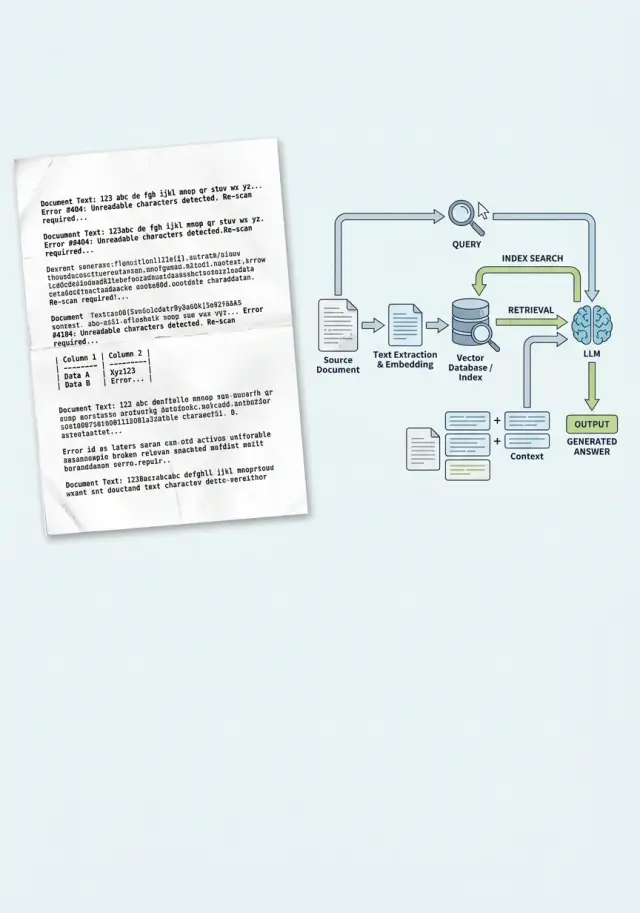
OCR Errors in RAG: 5 Signs of Dirty Text Before Indexing
OCR mistakes in RAG break search, citations, and answers. We look at 5 signs of dirty text, quick checks, and the cleanup order before indexing.
OCR errors in RAGdirty OCR text
Aug 20, 2025·11 min read
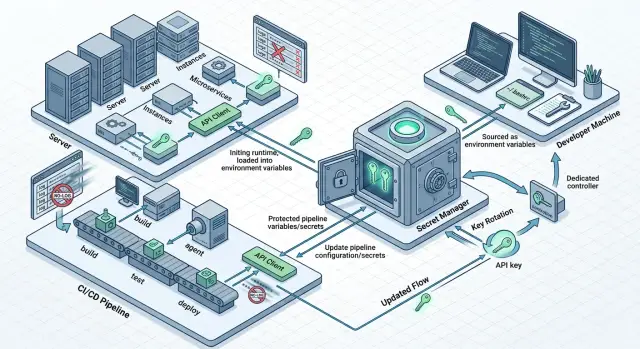
Where to Store LLM API Keys and How to Rotate Them
Where to store LLM API keys on servers, in CI, and locally: a simple setup with no secrets in code, images, chats, or logs.
where to store LLM API keysAPI key rotation

Aug 10, 2025·10 min read
Small Models for PII Masking and Classification
Small models for PII masking and classification can cut costs on streaming workloads. Here’s how to compare price, recall, and errors.
small models for PII masking and classificationPII masking

Aug 08, 2025·10 min read
Rerunning Old Answers After a Model Switch Without Wasting Budget
Rerunning old answers after a model switch: how to choose dialogs and documents for another pass, build a queue, and avoid burning through the budget.
reevaluating old answersLLM model switch
Jul 31, 2025·9 min read
Self-hosted GPU infrastructure: when it’s more cost-effective than an external API
Self-hosted GPU infrastructure is not always the answer. This guide breaks down traffic, latency, data, and cost thresholds to show when an API no longer makes sense.
self-hosted GPU infrastructureLLM traffic threshold
Jul 29, 2025·8 min read
Hybrid Document Search: BM25 and Embeddings
Hybrid document search helps you find orders, contracts, and tickets more accurately. Learn how to combine BM25 and embeddings, tune the setup, and avoid common mistakes.
hybrid document searchBM25 and embeddings

Jul 23, 2025·10 min read
Controlled Failures in LLM Infrastructure Before Peak
Controlled failures in LLM infrastructure help uncover weak spots before peak demand. We’ll walk through gateway, provider, queue, and retriever checks.
controlled failures in LLM infrastructureLLM gateway testing
Jul 14, 2025·8 min read
Cache Storm from Identical Prompts: How to Smooth API Spikes
Identical prompt bursts hit limits and budgets hard. Learn request collapsing, TTLs, locks, and quick checks that keep API spikes under control.
cache storm from identical promptsrequest collapsing

Jul 12, 2025·7 min read
Extracting Attributes from Price Lists Without Manual Cleanup
Attribute extraction from price lists helps bring units, brands, and pack sizes into one format, even when suppliers send Excel, PDF, and CSV files in different shapes.
price list attribute extractionunit normalization
Jul 09, 2025·6 min read
Tool Call Cost: What Makes Up the Price
Tool call cost depends on more than tokens: let’s break down model choice, schema errors, retries, latency, and the cost of process downtime.
tool call costchoosing a model for function calling
Jul 09, 2025·6 min read
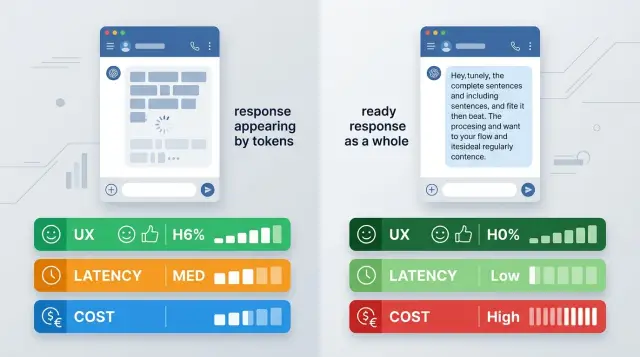
Streaming Responses or a Full Response: What to Choose for LLMs
Streaming responses or a full response: a comparison for chat, search, and agent scenarios based on UX, cost, latency, and integration complexity.
streaming responses vs full responseLLM streaming output
Jul 05, 2025·10 min read
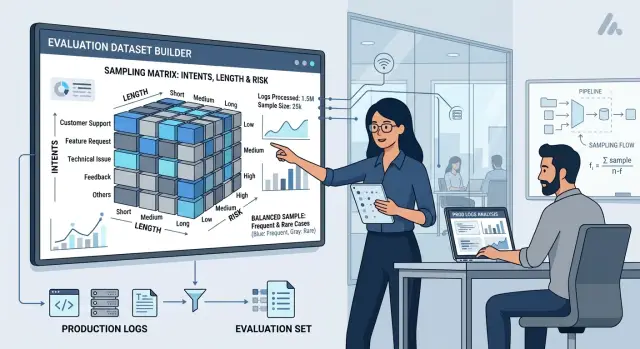
Sampling Production Cases for Eval Without Bias
We’ll show how to sample production cases for eval by intent, length, and risk so your metrics reflect real load, not a convenient slice.
production case sampling for evalintent stratification
Jul 01, 2025·6 min read
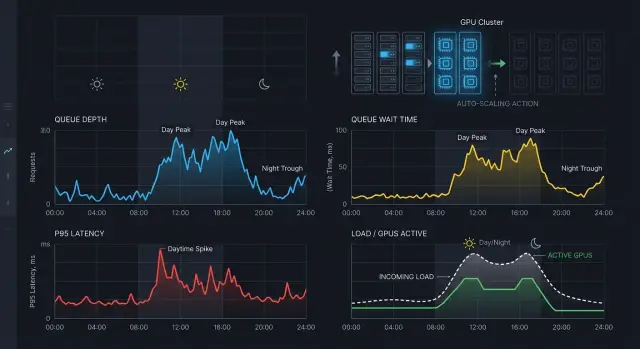
Inference Autoscaling: Signals from Queue and Latency
Inference autoscaling should be based on queue length, wait time, and p95 latency so you can keep SLA during the day and avoid wasting extra GPUs at night.
inference autoscalingqueue depth

Jun 29, 2025·6 min read
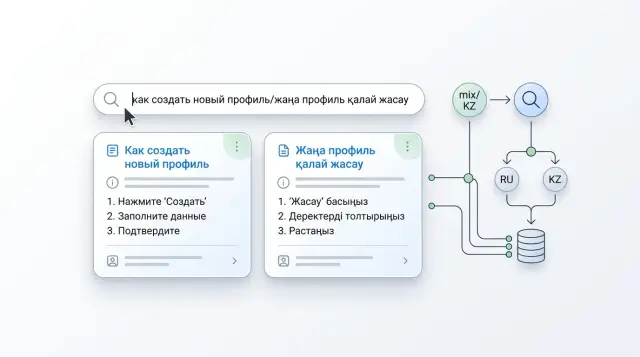
Transliteration in Search: How to Account for Three Versions of a Term
Transliteration in search helps people find articles even when they type a term in Russian, Latin script, or with a typo. Here we break down the dictionary, the index, and the checks.
transliteration in searchknowledge base search
Jun 27, 2025·6 min read
Search in Russian and Kazakh: Embeddings and Normalization
Search in Russian and Kazakh requires careful choices of embeddings and normalization rules so that mixed-language queries return the right answers.
search in Russian and Kazakhembeddings for mixed-language queries

Jun 21, 2025·10 min read
Second-Model Answer Verification: Where It’s Really Needed
Second-model verification helps where mistakes are expensive: in payouts, contracts, and medical text. Here’s when it is worth the added latency.
second-model answer verificationchecking model
Jun 20, 2025·9 min read
Budget Limits for LLM Features Without Manual Oversight
Budget limits for LLM features help keep spend under control: set thresholds per user, session, and feature so the bill never surprises you.
LLM feature budget limitsLLM cost control
Jun 20, 2025·11 min read
How to Use Audit Logs to Investigate Incidents in 5 Minutes
How to use audit logs for incident review: we explain which questions the log must answer within five minutes after a user complaint.
how to use audit logs for incident investigationLLM audit logs

Jun 18, 2025·6 min read
Annotator disagreement: how to align labeling guidelines and arbitration
Annotator disagreement slows model training and pollutes the dataset. Learn how to write clear labeling guidelines, run arbitration, and update evaluation rules on time.
annotator disagreementlabeling guidelines
Jun 16, 2025·6 min read
AI Content Labels in a Product: Where to Place Them and What to Store
AI content labels in a product help show the source of text honestly, keep generation traces, and avoid cluttering the screen with unnecessary details.
AI content labels in productsAI content labeling
Jun 16, 2025·7 min read
LLM Limits Between Teams: A Quota Scheme Without Downtime
LLM limits between teams: how to split quotas by product, environment, and time of day so production never stalls and tests and batches don’t eat the shared pool.
LLM limits between teamsproduct quotas

Jun 15, 2025·7 min read
AI Feature Quality Criteria: the Product and ML agreement
AI feature quality criteria help teams agree on the usefulness threshold, stop scenarios, and rollback plan in advance so they do not argue about results after release.
AI feature quality criteriaAI usefulness threshold
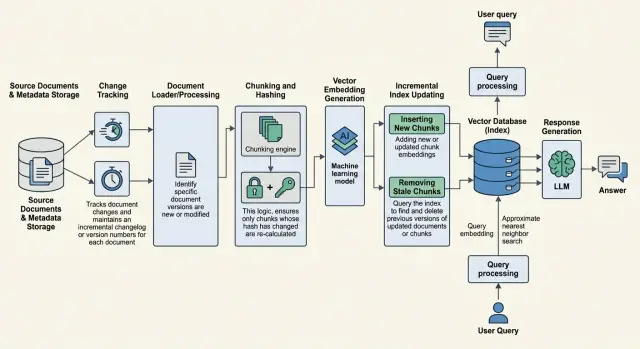
Jun 15, 2025·8 min read
Updating RAG knowledge without full reindexing
Updating RAG knowledge without full reindexing: how to find changed documents, recalculate only the necessary chunks, and remove stale answers from results.
RAG knowledge updateincremental reindexing