Data Residency for LLMs: Local, Hybrid, or API
Data residency for LLMs helps compare local hosting, hybrid setups, and external APIs by risk, cost, and launch time.
Why this choice is hard
This problem almost never comes down to just where to run the model. In an LLM system, data lives in many places: user prompts, model answers, files for RAG, embeddings, system logs, audit records, and backups are all stored separately. Even if the model itself runs inside the country, attachments or telemetry can still leave for an external service. That is why the setup is so easy to underestimate: on the diagram everything looks neat, but in real architecture the data trail spreads in different directions.
Every team sees risk differently. A lawyer needs a clear answer to where the data is stored and who processes it. The security team looks deeper: how personal data is masked, who sees the logs, where traces and audit records are kept. The product team thinks about something else: how long launch will take, how many people will be pulled away, and what will start breaking under real load.
Usually the debate comes down to a few simple things: where the data, logs, and files physically live; who is responsible for access, logging, and deletion; how much it costs not just to launch, but also to run; and how quickly you can go live without manual workarounds.
Because of that, the same scenario can lead to different decisions. A bot that answers general company questions can often be launched quickly through an external API if the requests do not contain sensitive data. An internal assistant for a bank that sees customer applications, correspondence, and documents almost always needs a stricter setup. If you choose too loose a scheme at the start, later you will have to rebuild data routes, access logic, approvals, and the storage of accumulated data.
The cost of a mistake does not show up right away. At the start, an external API looks like the fastest option, local LLM hosting looks the most controllable, and a hybrid LLM setup seems like a sensible middle ground. A few months later, the biggest costs usually turn out to be logs, retention rules, GPU support, fault tolerance, and security reviews. The choice is hard not because architecture is fashionable, but because business, security, and development all pay for the same mistake in different ways.
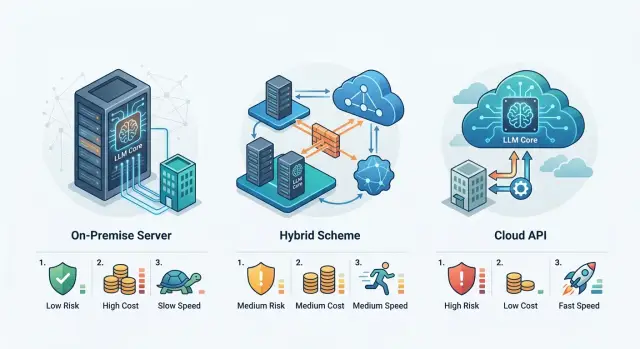
Three approaches, without the jargon
The debate is usually not about the model itself, but about where the data, logs, and access settings live. That instantly changes the risks, the budget, and how long it takes the team to show a working result.
Local LLM hosting means the model, logs, vector database, and service components all run inside your own boundary. This is usually chosen where customer texts, internal documents, or personal data cannot be sent outside. The upside is obvious: high control. The downside is just as clear: hardware, support, model updates, and fault tolerance all fall on your team.
A hybrid LLM setup separates things by sensitivity. Logs, access rules, and sensitive data stay inside. Before the model call, the system masks PII, and only the safe part of the request, or the scenarios that need a stronger model, go out. Teams often choose this approach when they want control but do not want to build the whole stack from scratch.
An external API for LLMs is the fastest way to launch. The team gets access to models without its own GPU infrastructure and plugs it directly into the product. That is convenient for a pilot, for a quick scenario check, and for cases where several teams need shared access right away. The limits show up just as quickly: less control over where processing happens, how long logs are kept, and what terms must be agreed with security.
There is no single right answer here. If control and local requirements come first, your own setup usually wins. If speed matters most, an external API is usually faster. A hybrid is chosen when you do not want to argue between extremes, but instead want to split data by sensitivity.
There are three questions that quickly cut through any debate. Who keeps the data on their side? Who pays for the infrastructure every month? And how long until the first production launch? The answers usually show which option fits you best.
Where the risks grow
Risk does not start where the server sits. It starts where the request leaves a trace. Teams often look only at the model call itself and forget about prompts, answers, service logs, and attachments. If an employee uploads a PDF and the system writes a debug log to an external service, the data has already left the required boundary.
A leak and an outage are different problems. A leak affects personal data, reputation, and audits. An outage affects the product: the chat stops responding, limits are exhausted, the provider changes its rules, external traffic is blocked, or the model suddenly becomes unavailable. Local hosting usually reduces dependence on an external provider, but it adds a different set of risks: the team is now responsible for GPU, updates, backups, and overnight incidents.
Where teams most often make mistakes
The most common mistake involves PII. You need to decide in advance who masks personal data before the request is sent. If the external provider does it after receiving the text, the boundary has already been crossed. For a bank, clinic, or government service, that is a weak point. It is safer when the application or gateway inside the country hides IIN, card numbers, phone numbers, and addresses before the model is called, and stores the original values separately.
The second risk area is dependence on one provider and one model. At first that seems convenient: fewer settings, easier testing. Then the price rises, the data policy changes, or quality drops on your scenario, and the product gets stuck in an awkward position. A hybrid setup gives you a fallback route: sensitive requests stay inside the country, while less critical ones can go to an external API. A compatible gateway that can route requests to different providers through one endpoint also helps.
What to check in the requirements
Review audit logs and content labels separately. Laws and internal rules often require you to see who sent the request, when it happened, which model replied, what the system masked, and what text reached the user. If those records are stored in another country or are not collected fully, the issue will not appear on launch day, but during an audit or incident review.
In practice, the weak point is often not the model itself. Forgotten logs, attachments in object storage, and PII masking done too late are usually what cause trouble.
What makes up the cost
If you only look at the price per 1 million tokens, the picture is almost always too optimistic. In LLM systems, expenses come from several lines at once: the model, hardware, engineering support, monitoring, incident handling, and the time the team spends when something breaks or slows down.
With local hosting, the biggest downside is simple: you need money up front. You have to buy or rent GPUs, set up infrastructure, configure networks, monitoring, redundancy, logs, data protection, and team on-call coverage. Even if you only have 200 requests a day in the first month, the meter is already running.
The budget usually has five parts:
- compute: GPU, CPU, memory, and storage;
- engineering work: DevOps, ML, backend, and security;
- operating costs: monitoring, logs, alerts, and backups;
- maintenance: model updates, testing, and incident handling;
- manual work and downtime: time spent when the process is not automated.
A hybrid setup looks like a compromise, but it has its own price. Some requests go to an external API, some stay inside the country, and someone has to decide where each request goes. That means costs for routing, data-type rules, PII masking, audit logs, and constant checks to make sure sensitive data does not go where it should not. The setup is convenient, but it is not cheap by itself.
An external API usually wins at the start. You can build a pilot quickly, without buying GPUs or spending a long time on setup. But then the bill grows with traffic. Once the product is in production, more users arrive, responses get longer, and repeat requests increase, the variable part of the budget starts to bite. This shows up especially fast in teams where employees use the assistant all day, not just a couple of times a week.
There is also a cost that rarely shows up in a spreadsheet. If engineers manually move requests between models, clean personal data before sending, or handle incidents without proper logs, the business pays not only in money but also in time. An engineer hour and an hour of support downtime often cost more than the savings from cheaper tokens.
For companies in Kazakhstan, another question is how not to multiply costs through an extra integration layer. In that case, a single compatible API gateway helps. For example, AI Router provides one OpenAI-compatible endpoint for external and locally hosted models, without requiring SDK or code rewrites, and B2B invoicing is issued monthly in tenge. That layer does not make a project cheap on its own, but it makes the costs and control easier to understand.
How launch speed changes
Launch time usually depends less on the model itself and more on how many decisions the team has to make before the first production request. The more requirements there are around data, security, and infrastructure, the longer the path from idea to a working scenario.
An external API almost always gives the fastest start. If the company is allowed to send data to an external boundary, a pilot can often be built in a few days: a developer connects a ready-made API, tests prompts, and quickly gets the first answers. It gets even easier if the team already has a compatible stack. In AI Router, for example, you can replace the base_url with api.airouter.kz and keep using the same SDKs, code, and prompts.
But a fast start does not mean you can launch everything at once. The fastest scenario is usually one clear use case: an internal knowledge base assistant, ticket handling, or draft replies for an operator. If you try to build a full platform at the same time, with roles, logging, quality evaluation, and several models, even an external API will not save you from delays.
Where time goes in a hybrid setup
A hybrid setup starts more slowly because the team first has to agree on which data can go outside and which cannot. Then they need to define routing rules: which requests go to an external API, which stay inside the country, where PII is masked, and where logs are stored.
Usually the delay comes not from code or the model itself, but from approval between security, legal, and the product team. Until they approve the data schema and processing rules, developers are just waiting.
Most of the time goes into the data map for each scenario, personal data masking rules, choosing models for the external and internal boundary, and audit logs and access limits.
Local hosting takes the longest of all. Even if the team has already chosen a model, it still needs procurement or GPU allocation, infrastructure setup, monitoring, and load and fault-tolerance testing. After that come application tests: answer quality, latency, cost per request, and behavior at peak load.
For a bank, the difference is easy to see. A pilot assistant for employees through an external API can be shown in a few days. A hybrid version often takes weeks, because open and sensitive requests need to be separated. A fully local launch stretches out even more if the infrastructure is built from scratch.
If you need fast results, it is better to pick one scenario and bring it to a working state. It is much easier to expand the setup later than to build everything at once.
How to choose the right approach, step by step
The choice between local hosting, hybrid, and an external API should start not with models, but with constraints. For many teams, keeping data in the country for LLMs is not an option but a rule, so a nice demo on its own does not solve anything.
-
First, make a short list of the data that cannot leave your boundary. This usually includes full names, IIN, contract numbers, medical records, complaint texts, and internal documents.
-
Then split the scenarios into two groups: sensitive and regular. Searching an internal knowledge base or handling customer requests often points toward local hosting or a hybrid scheme. Drafting letters and summarizing public materials can often go to an external API.
-
After that, set two numbers: the maximum cost per request and the acceptable latency. If an answer is needed in 2-3 seconds and the budget is tight, a full local setup may end up costing more than it seemed at first. If latency matters less but full control matters more, the local option looks better.
-
Separately decide how much control you need over logs, model selection, and fine-tuning. If the team has to store audits, mask PII, and choose a model for each request type, a hybrid setup often gives more freedom than an external API.
-
Do not try to cover every process at once. Pick one clear scenario, launch a pilot, and after a month recalculate the facts: cost, latency, error rate, and team workload.
After a month, the picture almost always changes. Sometimes an external API quietly covers half the tasks without extra cost, and sensitive requests are better kept inside the country through local models or through a gateway with data storage in Kazakhstan, if your rules require it.
Example for a bank with an internal assistant
A bank rarely needs a full local cluster from day one. More often, it launches an internal assistant for employees: they ask about regulations, approval timelines, limits, and how to draft a customer reply from a ready-made template. This starts not with a big server purchase, but with normal request sorting.
If an employee pastes a contract number, IIN, phone number, or application details, that request is better kept inside the country. A local model finds the right regulation, pulls relevant fragments from the knowledge base, and prepares a draft reply. The bank does not send personal data outside and keeps an audit log for every request.
But some tasks do not need that level of control. Suppose the system has already removed the sensitive fields and kept only the meaning of the message: the customer wants to change the payment date, and the employee needs a polite, clear answer. That draft can go to an external API if the bank needs a stronger model for style, short summaries, or paraphrasing.
That is why a hybrid setup often gives the fastest practical start. The bank keeps contract-related scenarios, personal data, and internal rules local, while anonymized drafts go outside. There is no need to build a large GPU fleet right away and wait months for launch. If the team already has an OpenAI-compatible integration, the move is usually simple: the endpoint changes, while the code and prompts stay mostly untouched.
After the pilot, the decision becomes much clearer. The team sees which requests arrive every day, where latency grows, which scenarios most often contain personal data, and how much each route costs. After that, the bank keeps permanent tasks like regulation search and contract replies local, and distributes the rest by price and quality.
Common mistakes when choosing
When a company chooses an approach to data storage for LLMs, it often starts not with calculations, but with fear. The most common mistake is simple: the team immediately goes with local hosting because it feels safer. But if request volume is still low, the scenario is simple, and the model changes rarely, your own setup can become an expensive and slow solution.
Local hosting makes sense when the load is clear, data residency requirements are already fixed, and the team is ready to support the infrastructure every day. If that is not the case, servers quickly become an expensive reserve for the future.
The second mistake is looking only at token prices. An external API may seem expensive, while a local setup looks cheap after buying GPUs. In practice, the costs grow elsewhere: on-call work, model updates, monitoring, audit logs, API key limits, PII masking, and fault tolerance. If you do not count those in advance, the comparison will be false.
Another common mistake is not splitting data by sensitivity before launch. The team discusses all company data as one big pile and tries to find one answer for every case. That almost always creates unnecessary complexity. It is much more useful to identify at least three groups right away: public texts, internal documents, and data with personal or banking secrecy. After that, some tasks can stay safely in an external API, while others can go to a local or hybrid setup.
Many people forget to check where logs are stored and who can see prompts. This applies not only to the main traffic, but also to debug records, traces, caches, and exports for the support team. It happens that the data itself is stored inside the country, while logs with request fragments go to an external service. On the diagram everything looks safe, but the weak point is already there.
The last mistake appears in almost every first project: the company tries to move all scenarios into one setup at once. That is almost always too expensive. It is much cheaper to start with one process where the risk is clear and the impact can be measured, such as an internal assistant for employees without access to the most sensitive data.
Short checklist
Before choosing a setup, do not debate local hosting versus cloud without looking at the details. Usually five checks are enough: where the data stays, who cleans sensitive fields, how long it takes to reach a pilot, how you will switch model providers, and who controls the key functions.
First, sort the data by type. In many teams, prompts are stored in one place, answers in another, logs in a third, and attachments go to a separate store. If that is not documented in advance, you can easily get an unpleasant surprise: the model is in a local boundary, while attachments or request traces live outside the country.
Next, check who masks PII before the request is sent. This is not a small detail. If masking is done only by the external provider, the sensitive data has already left your boundary. It is safer when cleanup happens before the model call, on your side or in a trusted gateway.
It helps to review a list like this:
- where prompts, answers, logs, and processed files physically live;
- who deletes or masks PII before the first network request;
- how many days the team will really spend on the pilot and how much more will go into production;
- whether you can switch model providers without rewriting SDKs, prompts, and business logic;
- who is responsible for audits, request limits, and content labels required by law.
Timelines should also be calculated honestly. An external API often gives you a pilot in a few days, a hybrid setup can take weeks, and local hosting often takes even longer because of GPU procurement, access, logging, and security checks.
Also look separately at provider switching. If the integration is tightly tied to one API, the team will pay for it later in time. It is more practical to keep a compatibility layer. For teams in Kazakhstan, AI Router can be such a layer: one OpenAI-compatible endpoint for 500+ models from 68+ providers and locally hosted open-weight models, with data storage inside the country, PII masking, audit logs, content labels, and key-level limits. That does not remove architectural decisions, but it does make it easier to change the route without rebuilding the app.
If you have a clear answer, an owner, and a deadline for all five points, the decision already looks like a working setup rather than a pretty presentation.
What to do after you choose
After the decision, do not roll the system out to the whole business right away. First, you need one real scenario with clear value: an internal assistant for employees, a knowledge base search, or ticket handling. One pilot is almost always better than three parallel projects.
This is especially useful for data residency topics. In meetings, risks are often discussed too abstractly, while a pilot quickly shows where the real problem is: latency, cost, data access, or security requirements.
Start with a pilot and baseline numbers
Before launch, record a baseline, otherwise the team will argue by feeling a month later. Measure numbers on the same task set, not on random examples.
- average latency and p95;
- cost per request and cost per 1,000 tasks;
- share of answers that go through manual review;
- how many requests contain PII and how the system masks them;
- how often limits, timeouts, and failures occur.
Immediately leave room to switch the model and provider. If the app is tightly bound to one API, any migration later turns into extra weeks of work. It is easier to build the compatibility layer from the start.
Lock down the rules before production
If the law requires data to be stored in Kazakhstan, do not argue about the approach in theory. Run the same scenario in two variants: an external route with the required restrictions and local hosting of open-weight models inside the country. Then you will see not only the difference in risk, but also the difference in quality, latency, and support cost.
Before production, the team needs simple written rules: what counts as PII and where it is masked, which audit logs you keep and who can access them, what limits are set at the key, team, and service level, and which data can go to the external boundary and which cannot.
Another practical step is to agree on a rollback plan in advance. If the model starts making mistakes after an update, the team should be able to return to the previous route, the previous model, or the previous limits within minutes. It is the boring part of the work, but it is often what saves an LLM production launch when a pilot becomes real load.
Frequently asked questions
When is local LLM hosting unavoidable?
Choose the local option if your requests contain IIN, contract numbers, medical data, complaint texts, or internal documents. It also fits when your rules require data, logs, and audit records to stay inside the country.
You pay for that with time and support: the team needs GPU, monitoring, backups, and on-call coverage.
When is it safe to choose an external API?
An external API usually works well for pilots, drafts, summarization of public materials, and scenarios without sensitive data. If the team needs results within a few days, this is often the best place to start.
First, though, check where the provider stores prompts, responses, and logs. Otherwise, a fast launch can later get stuck in security and legal approvals.
What does a hybrid setup actually solve?
A hybrid setup is useful when some requests cannot leave the country, while others can. For example, regulations, contracts, and PII stay inside the country, while anonymized drafts or paraphrasing go to an external API.
That way, you do not build the whole stack from scratch and you do not send everything outside. But you still need clear routing and masking rules.
Where do teams most often lose control over data?
Teams usually lose control not because of the model, but because of everything around it. Debug logs, traces, attachments, caches, and support exports are the things that most often leave the boundary.
Check the whole chain: prompt, response, file, log, backup. One external service in that chain can break the setup.
Who should mask PII before the model call?
Masking should happen before the first network request, on your side or in a trusted gateway inside the country. If an external provider hides PII after receiving the text, the data has already left your boundary.
At the start, it is enough to cover IIN, card numbers, phone numbers, addresses, and contract numbers. Keep the original values stored separately.
What is usually cheaper: your own setup or an external API?
If requests are few and the scenario is simple, an external API is often cheaper at the start. You do not have to pay right away for GPU, infrastructure setup, and constant support.
As traffic grows, the costs shift. With a local setup, hardware, monitoring, and on-call work get more expensive. With an external API, tokens and long responses drive the bill up. Count not only the model, but also logs, incidents, and engineer time.
Which option gets to a pilot the fastest?
The fastest option to launch is usually an external API, if company rules allow that route. A simple pilot can often be built in a few days.
A hybrid setup takes longer because of the data map, routing rules, and approvals. Local launch takes the longest, because you need to set up the infrastructure and test load.
How can you reduce dependence on one provider?
Do not hardwire the app to one API and one model. Keep a compatibility layer between the product and providers so you can change the route without rewriting code and prompts.
Also check right away how you will switch models, where logs are stored, and who changes limits. Then a price increase or outage at one provider will not stop the product.
Where should a bank start with LLM adoption?
Start with one scenario where the value is visible quickly. For a bank, that is often an internal assistant for regulations and response templates, not a full local cluster from day one.
Separate requests in advance: keep those with PII and contracts inside the country, and move anonymized tasks outside. That gives you facts instead of arguments.
What should you check in a pilot before production?
Track average latency and p95, the cost per request, the share of responses that need manual review, the number of requests with PII, and how often timeouts or failures happen. Measure these numbers on the same task set, not on random examples.
Before production, also lock down the rules: what counts as PII, where you hide it, which logs you store, and how you roll back the model or route after a bad update.