Local Model Hosting: What to Keep in the Country and What Not To
Local model hosting helps separate risky scenarios from everyday ones. Here is what to keep in Kazakhstan and what to leave on an external API.
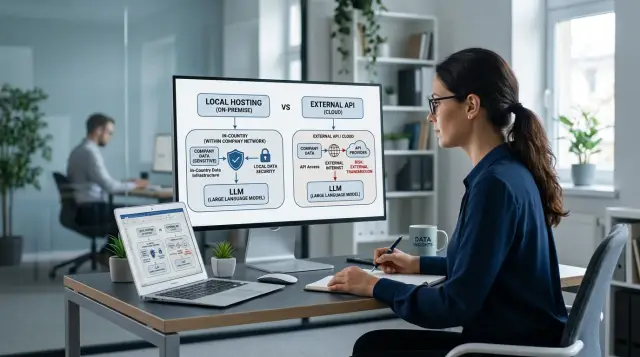
What is the problem here
The problem usually does not start with the question of which model to choose. First you need to understand what data goes into the request, who will see it, where it will be stored, and what happens if the model makes a mistake. For one task, that is just an extra edit. For another, it is a customer complaint, a fine, or an internal investigation.
Prompts almost always contain more than they seem to. The team sees a short user message and assumes there is no risk. In reality, along with it they often send the dialog history, fragments from CRM, search results from internal documents, service fields, file names, contract numbers, and pieces of employee correspondence.
This happens especially often in support chats and in scenarios where the system automatically pulls in context to make the answer more accurate. It is convenient, but this is exactly where sensitive data in LLM scenarios slips in unnoticed: national ID numbers, addresses, diagnoses, payment amounts, account details, and internal operator notes.
The cost of a mistake also varies. If the model rewrites a marketing text poorly, the team loses time. If it incorrectly summarizes a bank customer's history or shows an operator extra data, the consequences are different: risk to the person, risk to the company, and issues with data storage in Kazakhstan.
That is why a single approach almost never works. The same business may safely send anonymized texts outside for drafts, but keep the processing of customer requests, medical records, or banking documents inside the country. Sometimes even within one process, part of the request goes to an external environment while part stays local.
Before choosing a route, it is enough to answer four questions:
- Which fields actually go into the model with the prompt.
- Can the answer affect the customer or an employee's decision.
- Is data required to stay inside the country.
- Can personal data be removed or masked before sending.
When the team starts with these questions, the choice between a local environment and an external API becomes easier. Then the discussion is not about the "best model" in general, but about the cost of an error in each specific scenario.
What should stay inside the country
A local environment is needed where the request contains personal data, details of a specific case, or an internal knowledge base. In such tasks, the risk is not only about leaks. Audit, storage rules, and the review of disputed answers create just as many problems later.
Local model hosting is especially appropriate for requests with full names, ID numbers, account numbers, addresses, and any combinations that can identify a person. This also includes support conversations where a customer describes a complaint, debt, diagnosis, mistaken payment, or blocked access. Even if the operator only needs a short draft reply, the prompt often contains too much unnecessary information.
Where a local environment is needed almost always
A good rule is simple: if an employee would not confidently forward this text to an external service by hand, the model should not send it outside either.
Usually, inside the country you keep the handling of requests with personal data and customer history, searching internal policies and service instructions, draft replies for operators, lawyers, and doctors, as well as request classification that later needs an audit of the decision.
Searching internal documents is almost always better kept local. It is not only about secrecy. Internal policies change quickly, and an incorrect answer can become expensive later. If the model searches a local index and works next to the audit system, the team can more easily understand which document it relied on and why it answered the way it did.
Drafts for operators, lawyers, and doctors also make sense to generate inside the country. This is not the final decision yet, but such answers affect money, complaints, and health. Here, masking PII, request logs, and a clear chain of employee actions matter.
It is also better not to send classification of requests outside if the result triggers a process with consequences: escalation, refusal, manual review, or a change in priority. When a dispute reaches internal control or the regulator, you need a clear trail: what text came in, which model was used, and what class it returned.
For such scenarios, open-weight models are often enough if the task is narrow and well defined. They do not always need the highest quality. Usually, control, repeatability, and data storage in Kazakhstan matter more.
What can stay on an external API
An external API is suitable for tasks where the request contains no personal data, trade secrets, or internal documents. If a prompt leak would not create problems for the customer, lawyers, or security team, a local environment is often not needed here.
A typical example is marketing text without customer data. A promotion description, slogan ideas, mass email copy, social media posts, and landing page drafts can be generated externally as long as the prompt does not include CRM exports, named segments, or internal campaign plans.
The same applies to translating general materials. Public FAQs, product descriptions, template support replies, and employee instructions are convenient to translate through an external AI API if the text does not contain contract numbers, diagnoses, financial details, or internal notes.
The same rule applies to code as well. You can send drafts with closed-off parts outside: SQL queries, tests, regular expressions, examples of a service structure. But pieces with real keys, internal addresses, access schemes, and anti-fraud logic should not be sent out.
An external API has another practical advantage: new models appear there faster. That is why first experiments, comparisons of several models, and quality checks on training examples are often easier to do outside. There is not always a reason to run every model yourself just for a short test.
It is also a normal path for prototypes. If you are building a demo, testing an idea, or creating a test scenario with synthetic data, the external environment is usually cheaper and faster. There is no point in deploying local model hosting for a one-week pilot with no sensitive load.
The boundary is not defined by the task name, but by the prompt content. The same translation can be safely sent outside if it is a public instruction, and it cannot if the text contains patient data or the terms of a large contract.
If the team works through a single gateway such as AI Router, separating these scenarios is easier. Safe draft tasks can be sent to the external API, while customer and internal data can stay in the local environment. That creates a clear balance between speed and control.
How to make a decision for each scenario
Start not with the model, but with the request route. Take one real scenario and break it down step by step: what the user enters, what fields the system pulls in, what goes into the prompt, where the answer is stored, and who later sees the logs. Teams often look only at the request text and forget about attachments, cache, tracing, and history in the help desk.
Then mark the data by layers. Separately label personal data, internal employee comments, contract numbers, amounts, diagnoses, scoring features, and any service fields that can be used to reconstruct the context. If the task still works after masking names, ID numbers, phone numbers, and account numbers, it does not always need to stay inside the country. But if the answer loses its meaning without the original fields, the local environment is needed for a real reason, not just for show.
If security, audit, or the regulator needs a trail for every call, plan for it right away. You do not need one daily log; you need a record at the request level: who sent the data, to which model, with which prompt version, what was masked, and what answer came back. Without that, disputed cases take hours to sort out.
How to choose a route
In practice, almost all scenarios fall into three options:
- Local, if the request contains original personal or service data and an action log is mandatory.
- With masking, if the model needs the meaning of the text, but not the identifiers and account details themselves.
- External, if the data is already anonymized or the task is not related to customer records at all.
The cost of a mistake often helps more than a GPU table. If one leaked request could trigger a review, a fine, an incident investigation, and a loss of trust, your own infrastructure may be cheaper. If the biggest risk is a slightly awkward draft email, an external API is usually the smarter choice.
In practice, one product is almost always split. Request classification, reply drafts, and translation often go outside after masking. Internal document review, customer case search, and answers where the model sees the full record stay inside the country. If the team has a single OpenAI-compatible gateway, routing rules are easier to keep in one place instead of spreading them across each service's code.
Example: how a bank splits tasks between two environments
In a retail bank, the flow of requests quickly mixes simple and risky tasks. One customer asks about a fee, another disputes a charge, and a third writes about an account block. In some of these conversations there are ID numbers, balances, transaction history, and internal bank notes. The bank keeps these requests in the internal environment and runs them through a locally hosted open-weight model.
Inside the local environment, the model does clear work: it classifies the request, extracts facts from the text, prepares a draft reply for the operator, and creates a short summary of the case. Full data does not leave the country, and the bank stores the request logs itself. Usually these include masked input, prompt version, model response, processing time, and the employee's action. If the customer files a complaint, the control team can quickly reconstruct the full decision chain.
The bank uses the external API for low-risk tasks. For example, the system first removes the customer's name, ID number, account number, amounts, and transaction dates, then sends an anonymized letter template outside. In return, the bank gets a smoother style, a short summary, or several wording options. This is convenient for mass notifications, letters about routine situations, and rewriting text in simpler language.
How the bank compares the two environments
To avoid arguing based on impressions, the team takes the same set of requests and runs it through both setups. Usually they look at factual accuracy, the share of dangerous errors and fabricated details, average latency and peak latency, cost per thousand requests, and how many edits the operator makes after the model.
After such a test, the picture becomes clear quickly. The local environment often wins where control, audit, and data storage in Kazakhstan matter. The external API often produces stronger text for anonymized tasks and can be cheaper for rare complex requests.
The bank does not need to move everything inside the country. It is smarter to split the flows: keep sensitive data in LLMs inside, and send safe text operations outside. Then local model hosting stops being an expensive "just in case" idea and becomes a normal part of the architecture.
Where a local environment makes sense, and where it does not
A local environment pays off not by itself, but because of the workload profile. If the team runs the same type of request all day, costs and latency are easier to predict. This is especially noticeable where the model does short, repeatable work: classifying requests, extracting fields from documents, checking text against rules, and returning JSON in a strict schema.
When a local environment makes sense
Local model hosting usually makes sense if the request flow is constant, the answers are short and fit a strict format, quality can be checked with clear metrics, and the team needs data storage in Kazakhstan.
For such tasks, open-weight models often cover the need without extra costs. If the model needs to find an ID number in a document, remove personal data, or sort a letter into categories, you do not need the strongest external API. You need predictability, low latency, and a clear price per volume.
A local environment also works well where requests are similar to one another. Errors are easier to notice, prompts are simpler to tune, and GPU load is easier to plan by the hour. Sometimes that is already enough, and fine-tuning is not needed. Teams often think about it too early, when they should first test the base model on a good sample.
When it is better not to bring everything inside the country
Rare, complex, and long tasks are often cheaper to leave outside. If an analyst sends a large batch of documents once a day, asks for a long comparison, or waits for careful reasoning across dozens of pages, your own GPUs quickly hit memory and response-time limits. Large context is expensive even on your own infrastructure.
A simple test helps here. If the task happens rarely and answer quality matters more than full control over the environment, an external API often gives a better result for less money. You pay for actual usage instead of keeping compute capacity on hand for a rare spike.
A good boundary is usually this: keep standard operations and sensitive data local, and send rare complex analysis outside. That is more useful than trying to move everything inside the country.
Mistakes when moving models inside the country
Local model hosting is often started too broadly. The team moves everything at once: support chat, knowledge base search, internal documents, email drafts, call analytics. At first it looks neat, but later costs grow and the benefit turns out smaller than expected. It is much wiser to first split scenarios by risk and keep inside the country only those involving personal data, financial history, medical data, or data storage requirements in Kazakhstan.
Another common mistake is looking only at token price and forgetting the daily work around the model. Even if open-weight models are free under the license, they still need to be run, updated, monitored, and protected against failures. You need GPUs, spare capacity, an on-call person, clear logs, and a fallback path. Otherwise, a cheap token quickly becomes an expensive service.
It is also a mistake to assume the internal environment is automatically safe. It is not. If the team sends account numbers, ID numbers, phone numbers, diagnoses, or contract texts to the model without masking, the risk does not disappear. Data can end up in logs, debug dumps, test sets, and other people's chats. Even inside the country, it is better to hide PII before sending and return the original fields only where the business process truly needs them.
Problems also begin where no one set simple access rules. Who can work with the model? Which teams see which data? Which answers need to be marked as AI content? How long are logs kept? If there are no clear answers to these questions, the internal environment quickly turns into a gray area. Such systems need roles, separate keys, audit logs, and limits at the team or service level.
Many teams test a local model on convenient examples and get a false sense of control. On a demo, everything looks good: a short prompt, clean text, one task. In the real queue, it is different. Scans with poor OCR come in, long conversations, a mix of Russian, Kazakh, and English, nighttime traffic spikes, and unusual prompts.
A good test should always be closer to real production load than to a presentation. If a bank or retailer takes an anonymized real sample from a week, it quickly sees where the local environment makes sense and where the external API is still more reliable and cheaper.
A quick check before launch
Before the first real traffic, it helps to go through five points. A local environment by itself does not solve the security question if the team has not described the data route, measured the numbers, and agreed on who is responsible for the result.
Failures rarely start in the model. Usually the problem appears earlier: in an extra field with an ID number, in logs that went to the wrong place, or in a prompt that three people changed without a clear owner.
- First, split scenarios by risk level. Knowledge base search, email drafts, and internal text classification are often safer. Customer dialogs, payment data, medical data, contracts, and complaints should be marked right away as scenarios for the local environment.
- Then fix which fields you hide before sending a request to the model. A name, phone number, ID number, account number, address, contract number, and free text with personal details should not be left for later.
- After that, decide where prompts, answers, errors, and audit logs are stored. If there is a requirement to keep data in Kazakhstan, check not only the main system, but also monitoring, request retries, debug tables, and analytics exports.
- Next, compare the local model and the external API on the same set of requests. Look at latency, the cost of one answer, and the error rate. For the first test, 100–200 real requests without manual tuning are usually enough.
- And finally, assign an owner. One person or a small group should be responsible for the model version, prompts, fallback rules, and incident reviews. If there is no owner, changes will quickly spread across chats.
A simple test is very grounding. Imagine that tomorrow a bank launches an assistant for call center operators. If the team cannot show, in 10 minutes, a list of risky scenarios, masking rules, log storage location, latency numbers, and the owner's name, it is still too early to launch the system on real customers.
What to do next
Do not move all requests into the local environment at once. Start with one process where the data risk is clear and the result is easy to verify. For example, customer request handling, internal document summarization, or search across an employee knowledge base.
That kind of start quickly shows whether you need local model hosting in your case. If the team sees less manual work, acceptable latency, and clear costs within a couple of weeks, you can expand the scope. If not, you only lose a little time and money.
Split the routes right away. Send requests with personal data, banking secrecy, medical information, or internal documents to the local environment. Simpler tasks with lower risk can stay on the external API: draft text, translation of general materials, classification of public reviews, and help for developers with non-sensitive code.
Without shared metrics, this quickly turns into an argument of opinions. Measure the same things for both environments: answer quality, cost per 1,000 requests, average latency, error rate, and the amount of manual editing after the model. It is also useful to track how many requests had to be resent and how often users accept the answer without changes.
A good pilot usually looks simple: choose one process with a clear owner, prepare a small set of real requests under internal control, run them through the local model and the external API using the same rules, compare the result by quality, cost, and latency, and then define which data can go outside and which cannot.
If the team does not want to maintain separate integrations for external providers and locally hosted models, it can be compared with a single API approach. For example, AI Router gives one OpenAI-compatible endpoint for routing requests to external models and for teams that need a local environment on their own infrastructure. That simplifies the pilot: less code changes, and the difference between routes becomes visible faster. If data storage inside the country, PII masking, audit logs, and key-level limits matter to you, this option is especially convenient.
The whole point is simple: do not argue about strategy in general terms, but collect your own numbers on your own data. After a short pilot, it is usually already clear what should stay inside the country permanently, and what is cheaper and easier to leave outside.