Idempotent LLM Requests Without Double Charges
Idempotent LLM requests help avoid double charges, duplicate responses, and unnecessary retries during timeouts, network failures, and repeated clicks.
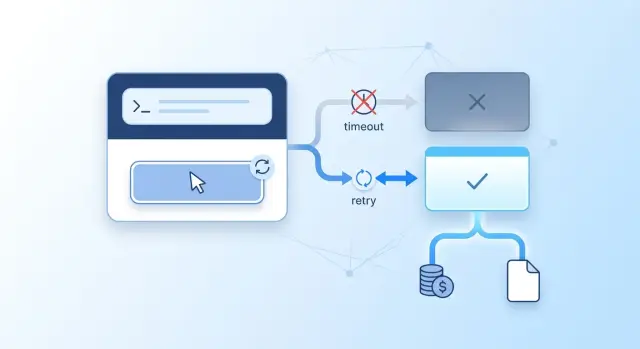
What breaks without idempotency
Without idempotency, one request can easily turn into two operations. You do not need a rare bug for that. Two clicks on the "Send" button, an automatic retry after a timeout, or a network drop on the last chunks of a stream is enough.
From the user's point of view, the picture is simple: the chat froze, they clicked again, and got two almost identical answers. For them, it feels like a small UI glitch. For the team, it is already money, logs, and disputed charges. Each repeat can go to the model as a new call.
The worst case happens during a timeout. The client decides the request failed, even though the provider has already accepted it and started generating. If the app sends the same prompt again without checking, the model processes it a second time. One user question becomes two generations, and billing counts two operations.
On low traffic, this is annoying. On high traffic, you can see it on the bill within a few days. It gets even worse when the client is sure they performed one action, but the system shows two charges.
Logs in this situation may look correct on paper, but they are not very helpful. The first request, the retry, and the repeated click all look alike: same user, same text, almost the same time. If they do not share one operation ID, support cannot tell which call came first, which one reached the provider, and which one the app created again.
In chat, the impact is visible right away. A repeated answer lands in the conversation history, breaks context, and confuses the user. If the LLM sits on top of an action like creating a ticket, summarizing a call, or sending an email, the duplicate affects not just text, but business logic too.
A simple example: an employee is waiting for a short summary of a customer call. The screen thinks for 10 seconds, and they press the button again. The first generation is already running, and a second one starts right after it. In the end, the system saves two similar summaries, the logs show several events instead of one, and the team later argues about where the real failure happened.
That is why idempotency is not needed for "pretty architecture." It is needed so that an action the user thinks of as one action stays one action for the API, billing, and logs.
Where repeats and extra charges come from
The problem usually starts not with the model, but with the network and client logic around it. The user clicks "Send," the interface pauses for a couple of seconds, and they click again. For a person, that is one attempt. For the system, it is already two identical requests.
SDKs also often retry on their own. After a 429, 500, or a network drop, the library may retry without the developer doing anything. If the first request reached the provider and only the response was lost, the second call looks new. That is how double charges appear, even though the user never asked for anything new.
Another source of duplicates is a proxy or API gateway with a short timeout. It waits 10 to 15 seconds, decides the request is stuck, and sends it again. But the model may have been calmly processing the first request the whole time. When both attempts finish, the team gets two results and pays twice.
Streaming makes things even messier. The model has already generated almost the whole answer, the client received part of the tokens, and then the connection broke. The user sees cut-off text and hits "Retry." The system sends the same prompt again, even though the computation has already happened.
A typical scenario looks like this:
- the browser sent a message to chat;
- the model finished the answer;
- the stream broke on the last chunks;
- the page refreshed or the user clicked again;
- the app created one more identical request.
After that, duplicates appear in the chat and extra costs appear in billing. And this is not exotic. The more layers there are between the app and the model, the higher the chance that one business action turns into two or three technical attempts.
What counts as the same operation
For idempotency, the important thing is not the fact that something repeated, but the meaning of the action. If the system sees several attempts as one operation, it should produce one outcome: one charge, one saved result, and one clear trail in the logs.
With LLMs, it is convenient to define this by the context that affects the answer and the price. Usually it is enough to check:
- the user, project, or API key;
- the model;
- generation settings;
- the request body, including messages and the system prompt;
- connected tools, if any.
If even one of these changes, it is a new operation. Even a small edit changes the meaning. The user added a line to the prompt, switched the model, raised max_tokens, or changed temperature - that means you need a new idempotency key.
This rule feels strict, but otherwise billing disputes start quickly. Two requests may look almost identical, but one goes to a cheaper model and the other to a more expensive one. You cannot merge those. The same goes for different users inside the same company: the text may match, but the operation is still different.
A repeat later on is not always a duplicate either. If the person returned to the chat later and sent the same text again for a different task, the system should not automatically treat it as the old operation. Otherwise, they will see an old answer where they expected a new run.
A good rule of thumb is simple: a retry preserves the original intent, while a new send creates a new intent. If the request repeated because of a timeout, network loss, or a double click, it is one operation. If the person consciously starts the task again, you need a new key.
In practice, it is best to tie idempotency to the business-action boundary. For chat, that is one message send. For batch processing, it is one document, one queue item, or one worker task. That keeps the system behavior predictable.
How an idempotency key works
You need to create the idempotency key before sending the request, not after an error. The client or backend generates a unique identifier for one operation: one chat message, one report generation, one tool call. That key goes with the request.
Then the service does one simple thing. It stores a record with that key, the operation status, and a fingerprint of the input data. The fingerprint is usually based on the fields that affect the result and the cost: model, messages, temperature, tools, and other parameters.
The basic flow looks like this:
- The client creates the key before sending the request.
- The server receives the request and reserves a record with
in_progressstatus. - After a successful response, the server stores the final result or a link to it and moves the record to
done. - If the same key arrives again, the server does not start a new generation, but returns the saved answer or the current status.
This is what saves you from the most expensive retries. If the network broke after the model had already finished, the repeated request will not trigger a second generation or a second charge. The user simply gets the same result the service already saved.
There is one important rule: you cannot use the same key with a different request body. If the client sends the same idempotency key but changes the prompt or model, the server should return a conflict. Otherwise, the protection loses its meaning: from the outside it looks like a repeat, but in fact it is a new operation.
You do not need to keep these records forever. Usually a TTL of hours or days is set, depending on how long retries may happen and how clients behave. That is enough to handle timeouts, repeated clicks, and automatic SDK retries, while the table does not grow without bound.
A good rule is short: one user intent, one key, one result.
How to implement it without race conditions
Idempotency is best implemented not in one place, but across the whole request path. If you close only the frontend or only the model call, gaps will remain.
First, decide who creates the key. In a web chat or mobile app, it is convenient to generate it on the client at the moment the message is sent. If you cannot trust clients or requests come from several systems, the backend can issue the key. In practice, a mixed approach often works: the frontend sends its action ID, and the backend adds the user, operation type, and other needed fields.
Then the order matters. First you reserve a record with the key and in_progress status. Only then do you call the external LLM API. If you do it the other way around, a race window appears between the external call and saving the result. That window is enough for a second process to send the same request again.
After a successful response, it is useful to save more than just the text. Save usage, the model, the provider response code, creation time, and a normalized hash of the input data. That makes disputed charges much easier to review.
If the first call is still running, a repeated request with the same key should not get a new generation, but a waiting status or the already ready result. Without the intermediate in_progress state, the second worker will assume nothing happened and will start another call.
The scheme is simple, but in practice this is exactly the part teams break most often. The team sends the request to the model and creates the record afterward. On tests, everything looks fine. Under load, race conditions, duplicates, and extra costs begin.
Example with chat and a timeout
Imagine a normal shift in a bank. An operator replies to a customer in chat and asks the model to draft a polite message: explain the application status, the timeline, and the next step. The request goes to the LLM, the model manages to generate the answer, but the network drops one second before the interface receives the result.
The operator sees an error and presses the button again. For the person, it is the same request. For a system without protection, it is two different calls. That is how double charges and two almost identical answers appear in the history.
In this kind of failure, the following happens: the server sent the request to the provider, the provider counted the tokens and returned the answer, the answer did not reach the interface because of the timeout, and the repeated click created a new call and a new charge.
Idempotency removes this trap. At the first click, the system creates a key and ties it to a specific operation: this chat, this message, and this operator action. When the operator presses the button again, the backend does not treat it as a new task. It looks up the record by the same key.
If the first call has already completed, the system returns the saved result. The text is the same one the model generated the first time. There is no new request to the provider, and no new charge either. For the operator, it feels simple: the error disappears, and the answer appears.
For this scenario, it is enough to store three things: the idempotency key itself, the operation status, and the final response together with token usage data. Everything else is implementation detail.
How LLMs differ from a normal API
With a normal API, repeating the same request often gives you the same object and the same status. With LLMs, that is not always true. Even if the prompt did not change, the model may generate different wording, choose a different phrasing, or call a different tool.
That is why you cannot check idempotency by looking at the response body. The same operation does not have to return the same words. What matters is something else: the system must understand that this is the same attempt to perform the same action and must not charge money a second time.
What streaming changes
With LLMs, the response often comes as a stream. The client has already received the first tokens, but the final usage data has not arrived yet. If the network stalls at that moment or the user clicks again, the server may receive a repeated request while the first generation is still alive.
This breaks familiar logic. The stream may have started, the client may see a timeout, and the model may already have generated almost the whole answer. Comparing complete text does not help, because the client may not have the full text.
The story gets even worse with external actions. If function calling creates a ticket, sends an SMS, or writes to a CRM, a repeated retry can trigger the same tool again. Then you do not have two similar answers in chat, but two real actions.
Why cache does not save you
Cache solves a different problem. It helps return a ready result faster and sometimes reduces the cost of repeated requests. But cache does not answer the main question: did you already perform this operation, and do you need to block the repeat?
A simple example: the user sent a message, the model called a tool to place an order, then the client did not wait for the stream to finish and repeated the request. Cache may not help, because the second answer may be slightly different. Even if the cache does work, it will not cancel the external action that has already happened.
So cache and idempotency should not be mixed. Cache stores a useful result. The idempotency key stores the fact that you already started or completed a specific operation.
Common implementation mistakes
Most failures do not come from the model itself, but from small decisions around the request. One wrong step, and the system either charges twice, returns two answers for one click, or mixes up other people's operations.
The first common mistake is treating all requests with the same prompt as identical. That is not enough. If you do not include the model, temperature, max_tokens, system prompt, tools, and other important parameters in the fingerprint, the service will start merging different operations into one.
The second mistake is saving the record only after calling the provider. Then there is a blank window between sending the request outward and recording the result. In that moment, the client may click again, the network may break, and your backend will send the same call a second time.
The third mistake is using the same key for different users or tenants. The key must live in a clear scope: user, project, operation. Otherwise, two clients with the same key may end up with a strange exchange of responses.
The fourth mistake is cleaning up too early. If you delete the record after one minute and the mobile app retries after two, the protection is gone. The retention time should match the real window for timeouts, retries, and reopening the screen.
The fifth mistake is endless automatic retries without checking the request body. Then the same key starts covering a different operation, and the team spends a long time trying to understand where the strange conflicts and repeated costs came from.
A useful minimum self-check looks like this:
- the fingerprint includes the model and all parameters that change the result or price;
- the record is reserved before the external call, not after it;
- the key is isolated by user, project, or tenant;
- the TTL is longer than the possible retry window;
- a repeat checks not only the key, but also the request body.
Quick check before launch
Before release, a series of annoying everyday scenarios is more useful than a big load test. That is where double charges and duplicate answers usually show up: the user clicks the button twice, the mobile client hits a timeout, the stream breaks in the middle, and the server has already sent the request to the model.
A good sign is simple: one user request produces one billing event and one final result, even if the client acted up several times.
Check it manually and with automated tests:
- a repeated click on "Send" does not create a second model call and does not trigger a new charge;
- if the client gets a timeout, the server first looks up the record by key instead of blindly sending a new request;
- streaming and normal responses follow the same accounting flow;
- logs connect the idempotency key, user, model, request parameters, and usage;
- the team can see the request path by status:
received,sent_to_provider,first_token,completed,failed,expired.
Also check the client timeout separately. A common mistake looks harmless: the frontend marks a request as "dead" after 15 seconds and sends a new one, even though the backend is still waiting for the model's response. In the end, the user gets two similar answers and billing counts two calls. Protection only works when the key check happens before the retry is sent.
If there is a gateway between the app and the model, do not lose these fields at the service boundary. The logs should match the key, the internal request_id, the provider's external request_id, and usage. Then the on-call engineer can quickly tell whether it was a real duplicate, a broken connection, or just a late response.
What to do in production
If this protection is still just a ticket or a diagram, start with one scenario where the mistake hurts money or trust right away. Usually that is a paid model call, document creation, sending a reply in chat, or any action where a repeated request creates a new charge.
One well-covered flow is more useful than an abstract "idempotency support" without testing it under real load.
After that, collect a minimal monitoring set:
- log the idempotency key, request status, and final result;
- count the share of timeouts, retries, and real duplicates;
- look separately at how many responses you returned from saved results instead of sending the request to the model again;
- compare the number of client requests with the number of provider charges;
- set an alert if the share of duplicates or timeouts rises sharply.
These metrics quickly show where the system is leaking. Often the problem is not in the app, but in the fact that retries are already enabled somewhere lower in the stack: in the SDK, the queue, the API proxy, or the load balancer. One user request can easily turn into two or three calls if each layer repeats it by its own rules.
It is useful to trace one request end to end and answer a simple question honestly: who can repeat it, and how many times? If the team cannot name every place, extra charges are almost inevitable.
If requests go through a single OpenAI-compatible gateway like AI Router, tracing usually gets easier: the team has one entry point, unified audit logs, and limits at the key level. But the idempotency key itself should still live at the level of your business action, not only at the level of the external provider.
This kind of protection should not be postponed. In a few days, you can close one expensive scenario, add metrics, and check all the retries along the request path. After that, idempotency stops being theory and starts saving money in the current release.
Frequently asked questions
Why do LLM requests need idempotency at all?
So that one click, one retry, or one timeout does not turn into two generations and two charges. Idempotency keeps the API, billing, and logs in one frame, so a repeated request returns the same result or the current status instead of starting the model again.
Where do duplicates and extra charges usually come from?
Most duplicates come from a double click, an automatic retry in the SDK, a short timeout in a proxy, or a stream breaking near the end of the response. The user makes one action, but the system sends the same prompt several times.
What counts as the same operation?
Treat one user intention as one operation. If the user or project, model, messages, system prompt, generation settings, and tools are the same, it is the same run; if any of these changed, it is a new request.
When should a new idempotency key be created?
A new idempotency key is needed whenever you change something that affects the answer or the price. If you change the model, temperature, max_tokens, message text, system prompt, or tools, the old key no longer fits.
What should you do if the client gets a timeout?
First look up the record by idempotency key instead of sending the request again. If the first call has already finished, return the saved result; if it is still running, return a waiting status and do not start a second generation.
What should be saved under the idempotency key?
Keep the record for the key in storage before calling the provider. It usually only needs in_progress or done, the input hash, the final answer, usage, and the provider request ID.
How do you avoid race conditions during retries?
First reserve a record with a unique key and in_progress status, and only then call the external model. That way, the second process sees that the operation is already running and does not send the same request again.
Can cache replace idempotency?
No. Cache solves a different problem. It can return a ready answer faster, but it does not prove that you already performed this operation, and it does not protect you from calling a tool twice or getting charged twice.
How does idempotency work with streaming?
Use the same key for the whole streamed response and keep the request state until the end. If the connection breaks on the last chunks, the retry should return the already saved result or the status, not start generation again.
What should you check after launch in production?
Compare the number of user requests with the number of provider charges, and watch the share of timeouts, retries, and real duplicates. If you also log the idempotency key, internal request_id, external request_id, and usage, you can quickly find where the system is repeating requests.