Testing query rewriting: how not to lose the meaning of a query
Testing query rewriting helps reveal when a rewritten query improves search results and when it distorts meaning. We cover metrics, tests, and common mistakes.
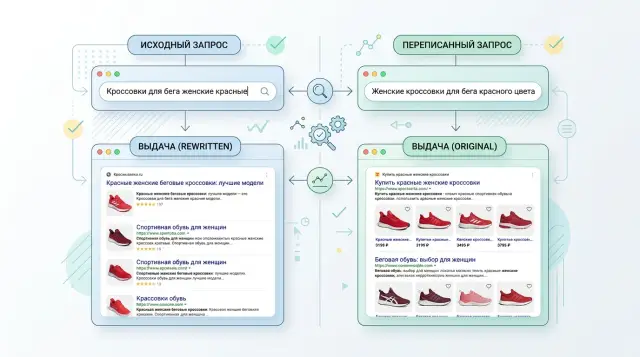
Where rewrite helps and where it gets in the way
Rewrite is useful when it removes noise instead of changing the task. If a user types "iphone 15 pro mah", the system can safely correct "mah" to "max". The meaning stays the same. But if it rewrites "iphone 15" into "iphone 15 Pro", that is no longer help, but a substitution of intent.
This is easiest to see on short queries. In two or three words, there is very little context, so the model starts guessing. The query "credit" can mean terms, a calculator, refinancing, or a complaint about a rejection. The shorter the phrase, the more carefully rewriting should be handled.
Longer queries are easier, but the risk is still there. If someone writes "how to reduce latency for an OpenAI-compatible API in Kazakhstan", rewrite can really help: remove extra words, turn the phrase into a search-friendly form, and keep the region and API type. The mistake starts when the model cuts too aggressively and drops "in Kazakhstan" or "OpenAI-compatible". Then the search finds more documents, but not the right ones.
A rise in clicks by itself also proves nothing. A user may click more often simply because the results became broader or more debatable. They open three results instead of one, spend more time, and still do not get an answer. That is why query rewriting is better judged by whether the person found the right material faster and had fewer unnecessary clicks.
The most dangerous failure looks almost reasonable. The model adds a meaning that seems similar to the original. In searches over a model catalog, this happens all the time. The query "cheap model for summarization" can easily be rewritten into "best model for summarization". One word changes everything. "Cheap" sets a price constraint, while "best" shifts the search toward quality.
A simple rule works here:
- fix typos, keyboard layout issues, and obvious junk with confidence;
- handle short queries carefully;
- do not add new constraints, objects, or goals;
- do not treat click growth as proof that relevance improved.
A good rewrite does not win because the query sounds smarter. It wins when search preserves the original meaning and gets the person to the answer faster.
What counts as a good rewrite
A good rewrite does not make a query prettier. It preserves the user's intent and helps search surface the right documents. If the meaning shifts even a little, the rewrite is already questionable, even if the results look more complete.
A simple example: someone types "limit on transfers for sole proprietors". A normal rewrite can carefully expand the abbreviation and the word form, for example into a version about transfer limits for an individual entrepreneur. A bad rewrite goes off track and turns it into a general search for business pricing. There are more words, but less accuracy.
You can see a good result not by the rewrite text itself, but by the results. After rewriting, the documents at the top should answer the original question faster and more accurately. At the same time, the system should not hide rare but precise results: a page with a specific error code, an order number, or the name of an internal product.
Errors are especially common where the query is short but very precise. Error codes, SKUs, model names, abbreviations, contract numbers, and rare terms should not be touched without a strong reason. One extra synonym can ruin the whole search.
For evaluation, it helps to keep a few simple signs in mind. The meaning after rewrite should stay the same. The right documents should move up, not just get shuffled around. Precise rare matches should not disappear from the first page. And one more important sign: the system should be able to leave the query unchanged if rewriting is not needed.
Cases with no change should definitely be part of the test. This is not an empty category. If the user already wrote the query exactly right, the best rewrite is to do nothing.
In offline tests, it is useful to mark each example like this: rewrite helped, had no effect, or hurt. That kind of labeling quickly shows where the system really improves search and where it is just rewriting for the sake of rewriting.
How to build a query set for testing
A test set should look like real search traffic. If you only take clear queries, rewriting will almost always seem helpful. The mistakes usually hide in short, rare, and noisy phrasing.
Collect queries from several groups. Frequent ones show whether rewrite helps where users search every day. Rare and long ones are needed for tail cases. Separately pull out problematic phrasing: one-word queries, ambiguous meaning, mixed Russian and English, internal jargon, product numbers, abbreviations.
It is also worth adding "dirty" examples. Users make typos, change word order, and use synonyms the team would not have come up with. For a bank, that could be "credit without a certificate" and "loan without income proof". For a telecom service, "roaming turkey" and "service abroad in turkey". If rewrite can fix things like that, you can see it quickly.
What to store for each query
A single line of text is not enough. For each query, it is better to save:
- the original text without edits;
- a short note about what the user probably wanted to find;
- 1-3 expected documents or result categories;
- a note saying "rewrite allowed" or "rewrite not allowed";
- the reason if the wording should not be changed.
The last point often saves you from false wins. There are queries where even a gentle rewrite breaks the meaning. These include law names, SKUs, tariff numbers, error codes, company names, exact models, and phrases from internal rules. The query "deepseek v3.2" should not be blindly turned into "latest deepseek model", and "order 102" should not be changed into a general query about regulatory documents.
Do not overwrite the original with the rewritten version. Keep both strings side by side. Otherwise, later it is hard to tell whether rewrite really helped or just replaced the task with an easier one.
For the first cycle, 150-300 queries is usually enough if they are chosen well. A small but honest set is better than a large table of near-identical phrasing. If search works across several domains, such as a knowledge base, products, and internal documents, distribute the queries across them manually. Then the test will show not an average temperature, but specific weak spots.
How to run the test step by step
Testing query rewrite is easy to spoil if you change too many things at once. For a fair check, lock the index, ranking, filters, data range, and result size. Only rewrite should change. Then you will see its real effect, not noise from neighboring changes.
- First capture the baseline results without rewrite. Run the same query set and save the top 10 or top 20 documents for each query.
- Then run the same set with rewrite. Use the same search parameters, the same index, and the same result limit.
- Compare the results for each query, not just the average score across the whole set. Mark where the relevant document moved up, stayed in place, or disappeared.
- Review failures manually. Numbers show the big picture, but meaning-related mistakes are almost always easier to spot by eye.
In practice, it helps to keep a simple table: original query, rewritten query, positions of the relevant document before and after, and a short comment. After 30-50 examples, the same failures start repeating.
A good test looks not only at metric growth, but also at meaning preservation. For example, a user searches for "loan for a sole proprietor without collateral", and rewrite turns it into "business loan". Formally, the text became cleaner and maybe even more popular. In fact, the system lost the "without collateral" constraint and surfaced the wrong documents.
During manual review, it is useful to use short labels:
- loss of user intent;
- unnecessary query expansion;
- replacement of a term or entity;
- removal of an important constraint;
- cosmetic rewriting with no benefit.
If you have many queries, do not try to read them all in order. Start with the cases where the relevant document dropped sharply or disappeared from the results. Then look at the queries where rewrite gave a noticeable boost. That makes it easier to understand both sides: where rewriting helps and where it distorts the meaning.
Which metrics to look at together
One metric rarely gives the full picture. Query rewriting can improve one number and quietly break another. That is why it is better to look at a set of signals that catch different kinds of mistakes.
Recall@k answers a simple question: did the needed document make it into the top k results. If the answer was not found before rewrite and then starts appearing at least in the top 10, that is already a plus. In offline tests, recall is especially useful on rare and long queries where the system often misses completely.
NDCG@k shows not just whether the document was found, but also the order of the results. A document in position 1 and the same document in position 9 give a very different user experience. If recall@10 goes up and NDCG@10 barely changes, rewrite probably expanded the query but did not help raise the right answer higher.
The zero-results rate catches broken queries. It quickly shows that rewrite removed an important term, broke a filter, or made the query too narrow. But this metric is easy to "improve" in a bad way. If rewriting makes the query more general, empty results will decrease, but relevance will suffer.
That is why you also need a meaning-drift metric. Drift should cover cases where rewrite changes the intent, entity, constraint, or time. The query "plan for sole proprietors without monthly fee" cannot be turned into "business plans" without loss. The system will find more documents, recall will go up, zero results will go down, but the original meaning will already have shifted.
Drift can be measured manually on a small sample or with a judge model, but questionable cases are better checked by hand. Most errors usually come from numbers, negations, dates, role names, and short two- or three-word queries.
A healthy pattern looks like this:
- recall@k goes up or at least does not fall;
- NDCG@k rises along with it;
- the zero-results rate drops without a spike in meaning drift;
- drift stays low for queries with numbers, dates, and exact constraints.
If one metric goes up and two others go down, it is too early to ship rewrite. The most unpleasant case looks beautiful on a chart: fewer empty results, more documents found, and the user is reading an answer to a different question.
One real-world scenario
Let's take a bank knowledge base. A user writes: "card reissue after loss". The intent here is fairly narrow. The person lost the card and wants to know how to issue a new one, how long it will take, and what to do first.
Rewrite changes the query to "restore access to the card". At first glance, the difference seems small. In terms of meaning, it is already a different query. The words "access" and "restore" often push search toward app login, PIN code, unlocking, and identity checks.
After such a rewrite, search starts surfacing the wrong documents. The top results include articles like "How to recover a PIN", "What to do if your card is blocked", or "How to log back into mobile banking". These may be useful in nearby cases, but they do not solve the original task.
Manual review catches this kind of substitution very quickly if you look not only at similar words, but also at the user's goal. For the check, three steps are usually enough:
- show the original query and its rewrite side by side;
- open the top 5 results before and after rewriting;
- ask the reviewer which set better solves the original task.
It is also worth marking whether rewrite introduced a new meaning that was not in the query. In this example, the mistake is obvious right away. An article about card blocking may be relevant as an extra step, because a lost card often needs to be blocked urgently. But if such materials push the reissue guide out of the results, rewrite has already hurt.
A simple score is useful here: 2 points if the result leads directly to reissue, 1 point if it helps partially, 0 points if it veers into PIN, access, or other neighboring topics. Then meaning substitution is visible not as a vague impression, but as an evaluation card.
Cases like this are very sobering. Plain text similarity does not mean the rewrite worked. If it changes the user's intent, offline metrics may look acceptable, while in the live product the person simply will not find the answer.
Where mistakes happen most often
The most common mistake in testing query rewrite is using only frequent queries. The system often handles these fairly well anyway, so metrics rise even when rewrite harms rare and difficult phrasing. The team sees a nice report, while users with long or unclear queries get worse results.
This is especially visible in queries with narrow meaning. The user writes "loan for a sole proprietor without collateral", and rewrite simplifies it to "business loan". CTR may not drop: people still click the top documents. But the meaning has already shifted, and search is answering a different question.
The second common mistake is looking only at CTR, as if it explained everything. CTR is useful, but it does not show whether the meaning stayed intact, whether the results became more precise, or whether important constraints disappeared. If rewrite makes the query broader, there are sometimes even more clicks, because the results look more general. For search, that is a trap, not a win.
Usually several things break at once:
- important clarifiers disappear: region, time, price, user role;
- a rare term is replaced with a more popular but less precise one;
- an abbreviation is expanded incorrectly;
- the query is rewritten too boldly and changes the person's intent.
Another typical problem is mixing rewrite and ranking in one test. If you change query rewriting, the ranking formula, and the source set all at once, you will no longer know what caused the growth or the drop. Such a test is almost useless. First, check rewrite on the same index and with the same ranking, and only then move the next layer.
Many teams forget to keep bad examples. That gets expensive. The same failure returns a month later after a new release because nobody saved it in the test set. You need not only a list of good queries, but also an archive of errors: the original text, the rewrite version, why it is bad, and which document should have been found.
A small failure base is often more useful than another thousand easy queries. It quickly shows whether you are losing meaning. That is the line between rewrite that helps search and rewrite that only makes queries look better in a report.
Checklist before launch
Query rewriting can easily look smarter than it really is. If you do not have a clear baseline for comparison, rewrite may improve some metrics and quietly break the meaning in important scenarios.
Before launch, check five things:
- keep a baseline version of search without rewrite;
- prepare a small but realistic query set with expected results;
- decide in advance when rewrite should be skipped;
- send questionable cases for manual review;
- set a rollback threshold before release.
Usually, rewrite should be used less often for exact and navigational queries: names, SKUs, contract numbers, people’s names, and phrases in quotation marks. Informational queries can be rewritten more boldly.
Otherwise, the query "order 37" suddenly turns into "internal regulatory documents", and relevance drops even though there are more words. Formally, rewrite worked; in terms of meaning, it did not.
Manual review does not require hundreds of examples. Often 30-50 questionable cases are enough, where offline tests diverge from expectations. Look at two things: what exactly the model changed and whether that helped find the right answer faster.
If you use multiple models or prompts to evaluate rewriting, do not change everything at once. First check the rewrite rule itself, then adjust the model and settings. That makes it easier to tell what created the gain and what pushes the query off track.
What to do after the pilot
A pilot rarely gives one single answer for all traffic. Usually rewrite helps only part of the queries. If it steadily improves quality for short, conversational, or too vague phrasing, keep it there. For exact queries with SKUs, company names, service codes, and quotes, it is better to keep the original text.
Work does not end after the pilot. Now you have early data, and based on it you can enable rewriting not everywhere, but only where it brings value without losing meaning.
For each query class, it is useful to choose one of four decisions:
- enable rewrite by default;
- enable it only when the baseline search performs poorly;
- leave the original query unchanged;
- send the query class for rule or prompt improvement.
Separately, keep a log of errors where rewriting changes the meaning. It pays off very quickly. For each entry, four lines are enough: the original query, the rewritten version, what was lost or added, and which document the search showed first.
Such a log helps you notice repeated failures. For example, the user writes "loan without collateral for a sole proprietor", and the model compresses the query into "business loan". The text is shorter and cleaner, but the important condition has disappeared. Examples like this should live in a permanent regression set and be run through every new version of rewrite.
If you compare several LLMs for rewrite, it is important to switch models quickly and not rewrite the integration every time. For such runs, AI Router on airouter.kz may be a good fit: it is an OpenRouter-compatible API gateway where you can switch models through one OpenAI-compatible endpoint and keep your existing SDKs, code, and prompts. In the context of evaluation, it is simply a convenient way to run the same query set through different models without extra glue code.
A good pilot result is simple: you have a list of query classes where rewrite can already be enabled, a separate log of meaning-related errors, and a test set for the next run. Then rewrite does not turn into "magic" inside search. It remains a regular part of the system that the team checks and keeps under control.