Blog
Practical writing on LLM application architecture, model routing, cost optimization, and operating AI systems in production.
Latest posts
Jun 14, 2025·8 min read
Warm model pool: how to calculate reserve for peak hours
A warm model pool helps you get through peak hours without unnecessary cost. We show how to estimate GPU reserve, watch the queue, and avoid paying for idle capacity.
warm model poolLLM peak load

Jun 07, 2025·8 min read
Extracting Tables from PDFs: How to Build Clean Data
Extracting tables from PDFs takes more than parsing: you also need line normalization, total checks, and manual review of ambiguous cases.
PDF table extractionPDF table parsing
Jun 05, 2025·9 min read
When a Small Model Is Better Than a Large One for Work Tasks
We look at when a small model is better than a large one: classification, field extraction, cost, latency, errors, and a simple way to choose.
when a small model is better than a large oneLLM text classification

Jun 04, 2025·11 min read
Criteria for Evaluating a Support Assistant in Manual Review
Learn how to set criteria for manually reviewing a support assistant: accuracy, tone, usefulness, and safety without unnecessary complexity.
support assistant evaluation criteriamanual review of AI answers

Jun 03, 2025·8 min read
Migration to Multiple AI Providers Without Service Downtime
Migrating to multiple AI providers without downtime: stages, SDK compatibility checks, shadow launch, and response comparison before switching.
migration to multiple AI providersOpenAI SDK compatibility
May 27, 2025·10 min read
Planning-Based Agent or Scenario-Based Agent: How to Choose
We break down when a planning-based agent or a scenario-based one is the better fit for support, search, and internal automation, without unnecessary theory.
scenario-based agent or planning-based agentLLM agent for support
May 24, 2025·10 min read
Source citations in assistant answers: how to build them
Source citations in assistant answers help verify conclusions. Here we explain how to gather quotes by document, not by random text snippets.
source citations in assistant answersdocument-based citations
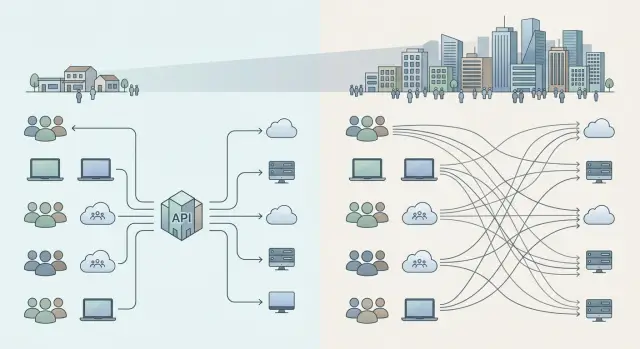
May 23, 2025·6 min read
A Single API for LLMs: When It Is Better Than Separate Integrations
A single API for LLMs helps compare a shared gateway with separate integrations in terms of cost, launch speed, access control, and team growth.
single API for LLMscentralized AI platform

May 23, 2025·9 min read
LLM Stream Cancellation: How to Stop Paying for Extra Tokens
LLM stream cancellation helps stop extra tokens when a user leaves the page. We look at signals, timeouts, logs, and checks.
LLM stream cancellationextra tokens
May 23, 2025·6 min read
LLM Gateway Metrics in Production: A Short Daily Set
LLM gateway metrics help you see quality, latency, errors, and costs every day. Here is a short set of numbers for making production decisions.
LLM gateway metricsproduction LLM monitoring

May 22, 2025·10 min read
Runbook for the On-Call Engineer on an LLM Service: First 15 Minutes
A short runbook for the on-call engineer on an LLM service: how to check error spikes, cost, and latency in 15 minutes, prioritize the right issues, and avoid service disruption.
LLM service on-call runbookLLM incident checklist

May 16, 2025·8 min read
When You Don’t Need Fine-Tuning: Data, Prompt, or Routing
When you don’t need fine-tuning: a practical guide to signs that clean data, a strong prompt, eval, and model routing will solve the task better.
when you don't need fine-tuningprompt instead of fine-tuning

May 14, 2025·11 min read
The Evolution of an Extracted Data Schema Without Analytics Chaos
How to change fields, dictionaries, and versions without breaking old reports or making the numbers diverge.
evolution of extracted data schemaschema versioning
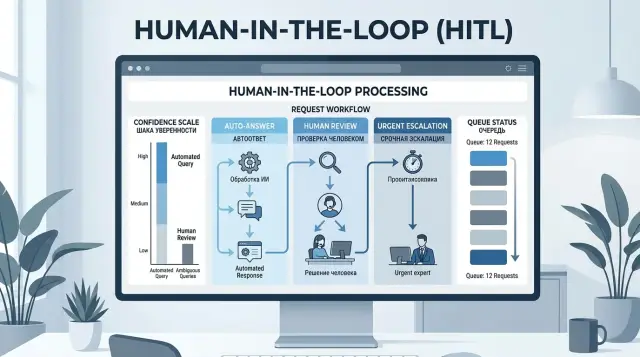
May 08, 2025·10 min read
Human in the Loop: Confidence Thresholds Without Manual Hell
Human-in-the-loop is not needed for every check: learn confidence thresholds, request types, and a simple escalation path to an operator.
human-in-the-loopLLM confidence thresholds
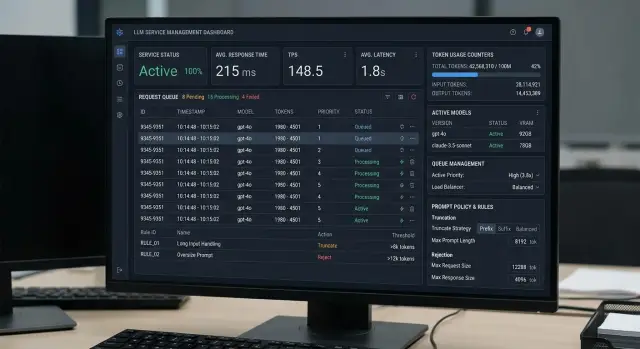
May 07, 2025·9 min read
Admission control for long prompts in an LLM service
Admission control for long prompts helps keep an LLM service available under load. We will cover priorities, truncation, rejections, and quick checks.
admission control for long promptsLLM request queues
May 07, 2025·7 min read
AI Tasks Through a Queue: When to Move to an Async Pipeline
We’ll look at when AI tasks through a queue work better than a web request, how to build an async pipeline, and where it lowers timeouts, cost, and failure risk.
AI tasks via queueasync pipeline for LLMs
May 05, 2025·8 min read
Prompt Caching: When It Actually Lowers Your LLM Bill
Prompt caching does not help in every case. We break down repeat-request thresholds, a savings formula, quality risks, and a quick way to check.
prompt cachingLLM request repetition
Apr 29, 2025·6 min read
Peak load on LLM functions: how not to bring your product down
Peak load on LLM functions should not take your product down. Learn when to use queues, simplify responses, and route traffic to lighter models.
peak load on LLM functionsLLM request queues
Apr 27, 2025·6 min read
LLM Log Retention Periods: How to Separate Records by Class
Let's break down LLM log retention periods: how to separate operational, debug, and audit records so you do not accumulate unnecessary data.
LLM log retention periodsLLM log audit

Apr 25, 2025·8 min read
Enterprise LLM Pilot: Where to Start and How Not to Drag It Out
An enterprise LLM pilot is easier to start with one business pain point, a short four-week plan, basic data checks, and clear success metrics.
enterprise LLM pilotlaunching LLM in a company
Apr 25, 2025·10 min read
System Prompt or Short Rules: How to Reduce Drift
System prompt or short rules: when to choose one long block and when to use a modular set to reduce drift and make review easier.
system prompt or short rulesinstruction drift

Apr 16, 2025·10 min read
When a Bot Should Hand the Conversation Over to an Operator Without Arguing
We explain when a bot should hand a conversation over to an operator: risk signals, customer emotions, uncertainty in the answer, setup mistakes, and a quick check.
hand off a conversation to an operatorchatbot escalation
Apr 13, 2025·8 min read
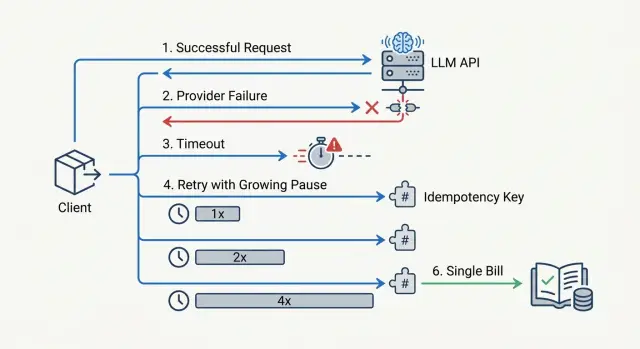
LLM API Retries: How Not to Double Your Bill When Failures Happen
Retries for LLM APIs help you survive failures, but without limits and idempotency they can quickly drive costs up. We break down timeouts, delays, and checks.
LLM API retriesrequest idempotency

Apr 13, 2025·8 min read
Prompt mistakes: 5 reasons your LLM bill is bloated
Learn how extra instructions, repetitions, and long context increase token usage, and how to remove prompt mistakes without losing quality.
prompt mistakesLLM request cost
Apr 12, 2025·11 min read
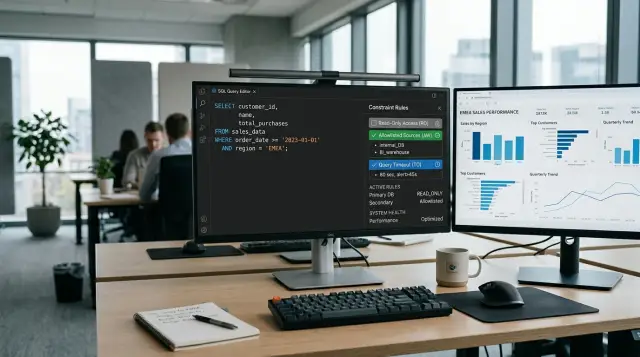
SQL Agent Without Risk to the Production Database: Read-Only and Limits
SQL agent without risk to the production database: how to set up read-only access, a SQL query allowlist, timeouts, and quick checks before launch.
safe SQL agent for production databaseread-only database access
Apr 06, 2025·8 min read
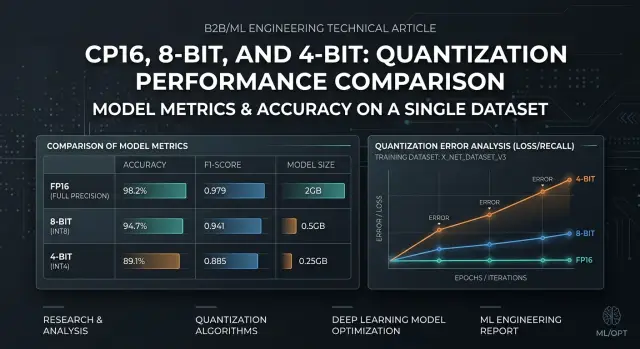
Model Quantization: Checks Before Moving to 8-bit and 4-bit
Model quantization requires quality checks on your own dataset: choose the right metrics, find failures, and compare FP16, 8-bit, and 4-bit before release.
model quantizationFP16 vs 8-bit
Apr 06, 2025·10 min read
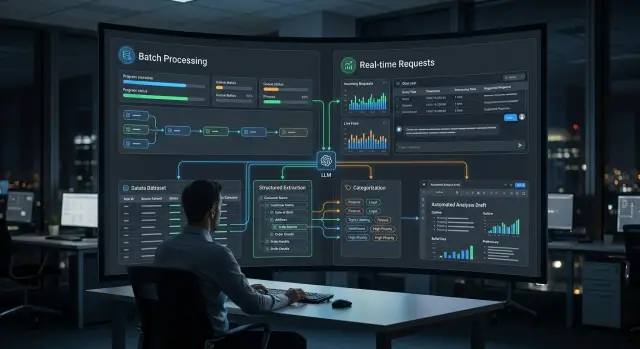
Batch Inference or Online Calls for Nighttime Tasks
Batch inference suits overnight processing, but it does not always beat online LLM calls. Let’s break down extraction, categorization, and draft generation.
batch inferenceonline LLM calls

Apr 06, 2025·6 min read
Response validation before writing to CRM and ERP without failures
Response validation helps catch a broken schema, wrong numbers, and bad links before writing to CRM or ERP and reduces manual corrections.
response validationschema validation
Apr 04, 2025·8 min read
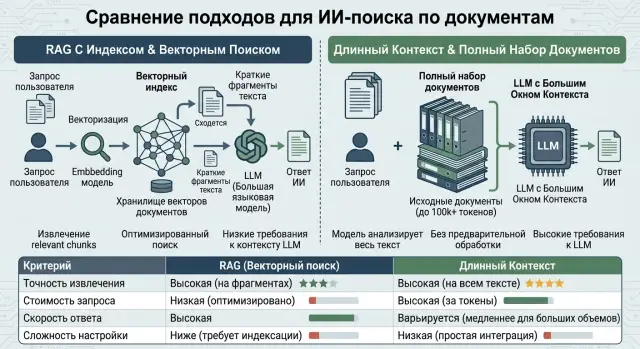
RAG or Long Context: How to Choose a Search Setup
RAG or long context: see how these approaches affect document search, cost, and latency so you can choose the right setup for your product.
RAG or long contextdocument search

Mar 31, 2025·10 min read
LLM expense report for accounting and the CTO without manual reconciliations
An LLM expense report brings tokens, models, and teams into one format so accounting and the CTO can reconcile the numbers without manual work.
LLM expense reportLLM token tracking
Mar 29, 2025·11 min read
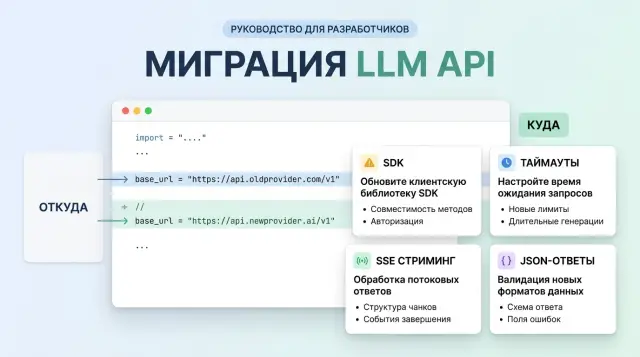
Migrating to an OpenAI-Compatible Endpoint Without Surprises
Migrating to an OpenAI-compatible endpoint looks like a simple base_url swap, but it often breaks on SDKs, timeouts, streaming, and JSON responses.
migrating to an OpenAI-compatible endpointreplacing OpenAI base_url

Mar 24, 2025·7 min read
PDF Review by Page or Whole: What to Choose
Page-by-page PDF checking works well for long files with mixed templates, while full parsing is better for stable documents and summary fields.
page-by-page PDF parsingextracting requisites from PDF
Mar 23, 2025·11 min read
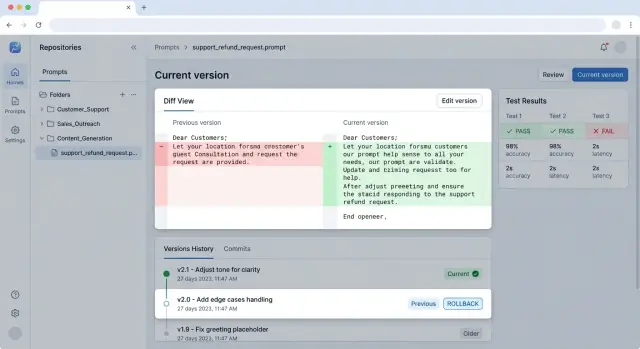
Prompt Versioning for Releases Without Surprises
Prompt versioning helps ship changes without breakage: we’ll cover repo structure, testing, rollback, and a team workflow.
prompt versioningprompt repository

Mar 15, 2025·10 min read
Shadow Traffic for a Model Migration Without Breaks or Surprises
Shadow traffic for model migration helps compare answers, latency, and cost before launch. Learn how to measure differences and switch calmly.
shadow traffic for model migrationparallel LLM requests

Mar 11, 2025·9 min read
Golden Set for LLMs: How to Keep It Without the Clutter
A golden set for LLMs helps you check quality without chaos: how to choose cases, archive old examples, and keep rare complex requests.
golden set for LLMsLLM quality evaluation
Mar 10, 2025·8 min read
Model Routing: Why the First Setup Doesn’t Pay Off
Model routing often does not pay off on the first try: teams introduce complex rules too early. Here is how to start with a small set of signals.
model routingLLM request routing

Mar 09, 2025·10 min read
Checking Links and Details After Email Generation
Checking links and details after email generation helps catch broken URLs, IIN mistakes, and old contract numbers before the client sees them.
checking links and details after email generationbroken URLs in emails
Mar 05, 2025·11 min read
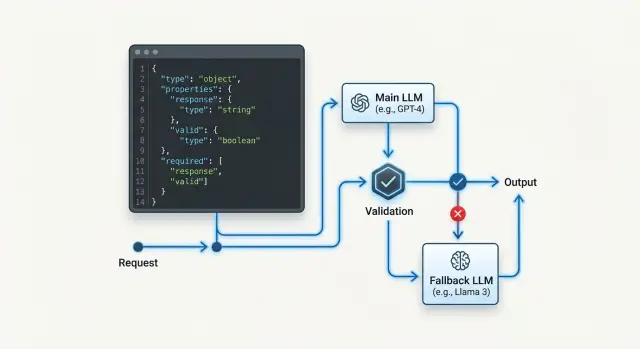
JSON Schema Fallback: How to Switch Models Without Breaking Tool Mode
JSON schema fallback matters when a backup model changes fields, types, or response format. We break down how to choose backup models, validators, and checks.
JSON schema fallbackbackup LLM models

Feb 28, 2025·9 min read
Synthetic Examples for Testing LLMs Before Production
Synthetic examples help test LLMs when real data is scarce. Learn how to build test cases, write expected results, and catch failures before launch.
synthetic examples for LLM testingLLM test cases

Feb 26, 2025·11 min read
Online and Offline Quality Evaluation: When to Trust Which
Online and offline quality evaluation answer different questions: clicks and conversions catch the effect in production, while labels and expert review surface mistakes earlier.
online and offline quality evaluationclicks and conversions

Feb 23, 2025·10 min read
Anonymizing Contracts and Medical Records for LLMs Without Losing Meaning
Anonymizing contracts and medical records before sending them to an LLM requires precise rules: which fields to hide, what to keep, and how to avoid distorting legal or clinical meaning.
anonymizing contracts and medical recordssensitive fields in documents

Feb 16, 2025·8 min read
LLM Routing for Production: How to Choose a Strategy
For production LLM routing, choose based on one task set and on cost, latency, and quality metrics, not on broad benchmarks.
LLM routing for productionmodel routing
Feb 05, 2025·10 min read
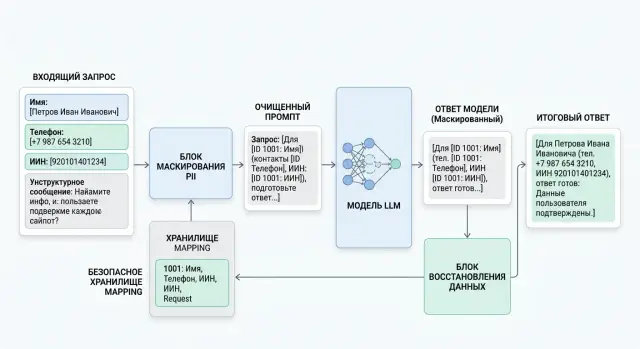
PII masking before calling the model: where and how to do it
PII masking helps hide personal data before sending a request to an LLM. We show where to place redaction, how to measure meaning loss, and how to safely return fields.
PII maskingpersonal data redaction

Feb 05, 2025·7 min read
When to Stop an AI Agent in Finance, Healthcare, and Law
When to stop an AI agent: we look at risk signals in finance, healthcare, and law, and show where the agent should hand the task to a person.
when to stop an AI agenthandoff to a human
Jan 27, 2025·7 min read
Assistant Personalization Without Extra Profile or Risk
Assistant personalization works better when you store only the signals that change the answer: role, language, request goal, and fresh context.
assistant personalizationdata minimization

Jan 27, 2025·7 min read
How to Calculate an LLM Budget for Multiple Teams
We’ll show how to break an LLM budget down by team, limits, and use cases so costs don’t grow after the pilot and the move to production.
LLM budgetLLM costs
Jan 27, 2025·11 min read
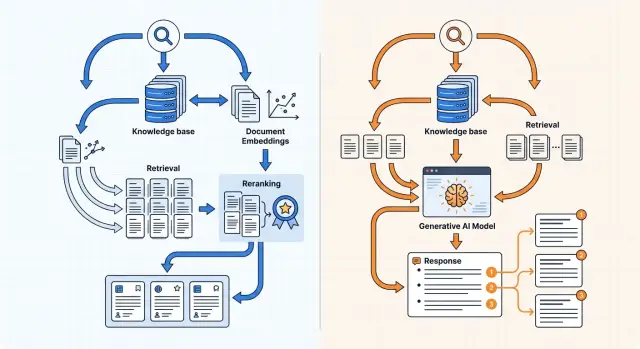
Knowledge Base Search: Embeddings or a Generative Model?
Knowledge base search can be built with embeddings or a generative model. Here we cover indexing, reranking, and answers with citations.
knowledge base searchembeddings
Jan 27, 2025·11 min read
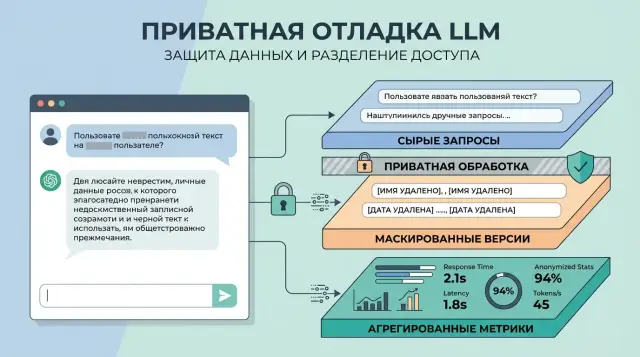
What to Store for Prompt Debugging Without Privacy Risk
What to store for prompt debugging: how to separate raw requests, masked copies, and metrics without exposing personal data.
what to store for prompt debuggingdata masking in LLMs
Jan 26, 2025·8 min read
Token Usage Forecasting: How to Spot Overspending in Time
Token usage forecasting helps you spot overspending early, set thresholds, catch model spikes, and avoid waiting for the invoice at month-end.
token usage forecastLLM usage anomalies

Jan 25, 2025·9 min read
SLOs for LLM Applications: How to Measure Against Business Goals
SLOs for LLM applications help connect latency, valid response share, and cost to business expectations, not to charts made for reporting.
SLOs for LLM applicationsLLM latency and quality

Jan 23, 2025·7 min read
Contact center call summarization without noise
Call summarization helps only when the call card shows the topic, outcome, risk, and next step without extra fields.
contact center call summarizationcall card for supervisors

Jan 18, 2025·7 min read
Source-based fact checking: how to build a test suite
Source-based fact checking helps you build tests where the answer is compared against a document, table, or database. We’ll cover the test suite structure, common mistakes, and a checklist.
source-based fact checkingautomated test suite

Jan 16, 2025·6 min read
Model Evaluation on Your Own Data for Product Use Cases
Evaluating models on your own data helps you choose the right LLM for product tasks: how to collect scenarios, gold answers, and metrics, and compare responses fairly.
model evaluation on your own datauser task scenarios

Jan 13, 2025·10 min read
Red Teaming a Corporate Bot Before Launch
Red teaming a corporate bot helps uncover data leaks, instruction bypasses, and toxic replies before release so you can fix them step by step.
red teaming a corporate botLLM data leak attacks

Dec 30, 2024·8 min read
Deleting Data at a Provider: What to Ask Before Buying
Data deletion at a provider should not be checked by word of mouth. Before buying, ask for contract clauses, logs, cleanup timelines, and the audit process.
data deletion at a providerdata storage review

Dec 25, 2024·7 min read
When Fine-Tuning Pays for Itself, and Prompting No Longer Does
When fine-tuning pays off: we look at signs that a prompt has reached its limit, which tasks benefit most, how to estimate ROI, and common mistakes before launch.
when fine-tuning pays for itselfwhen a prompt hits its limit

Dec 24, 2024·11 min read
AI-Powered Review of Credit and Legal Documents
AI-powered review of credit and legal documents helps you spot risky clauses faster, but the final decision on the case still belongs to a specialist.
credit and legal document reviewAI for contract review
Dec 24, 2024·10 min read
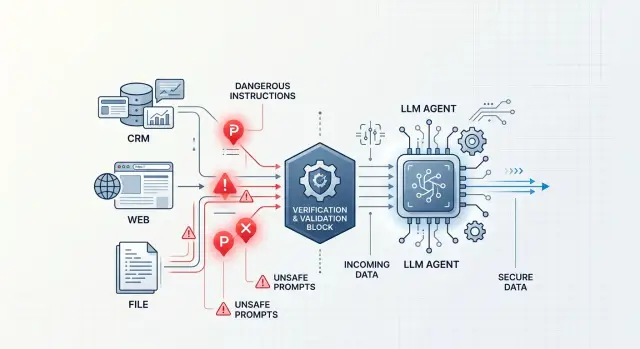
Tool-Output Injection: How to Protect an Agent
Tool-output injection often hides in CRMs, emails, and HTML. Learn how to filter data, isolate tools, and add checks.
tool-output injectionLLM agent protection
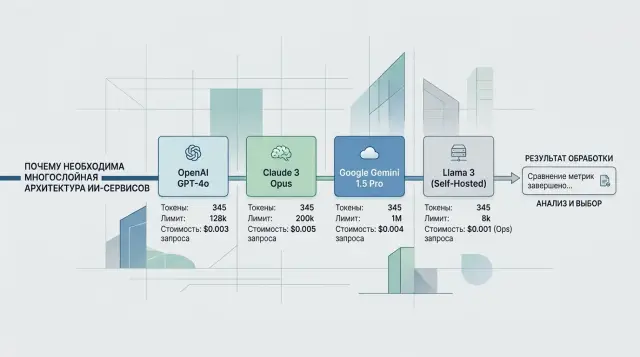
Dec 15, 2024·8 min read
Different tokenizers across providers: why the numbers don't match
Different tokenizers across providers change price, limits, and the real context length. Let's look at where the calculations diverge and how to check them in advance.
different tokenizers across providersLLM token counting

Dec 09, 2024·11 min read
LLM regressions: how to catch hidden drift before complaints
LLM regressions are not always obvious right away. Here we break down daily runs, alerts, control cases, and the checks to do before users complain.
LLM regressionsLLM control cases
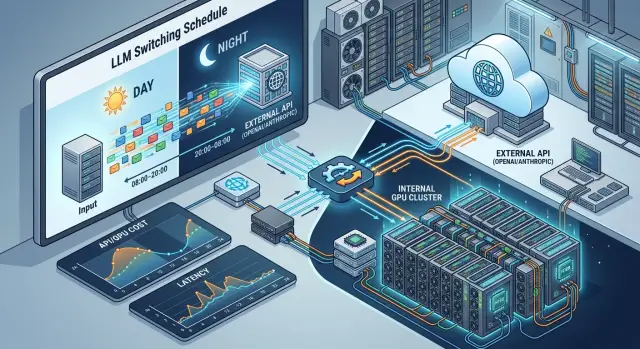
Dec 08, 2024·7 min read
Scheduled switching between hosted and self-hosted models
Switching between hosted and self-hosted models can reduce cost and latency if you separate use cases by time of day, data sensitivity, and load spikes.
switching between hosted and self-hosted modelsexternal LLM API
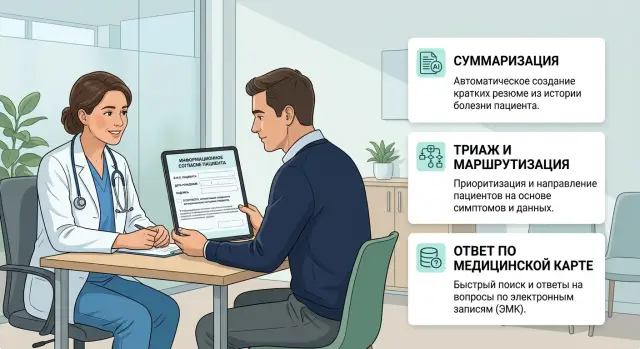
Dec 04, 2024·8 min read
Patient consent for LLMs in a clinic: what to record
We explain how to document patient consent for LLM use in a clinic: what to record before summarization, triage, and chart-based answers.
patient consent for LLMs in a clinicclinic triage
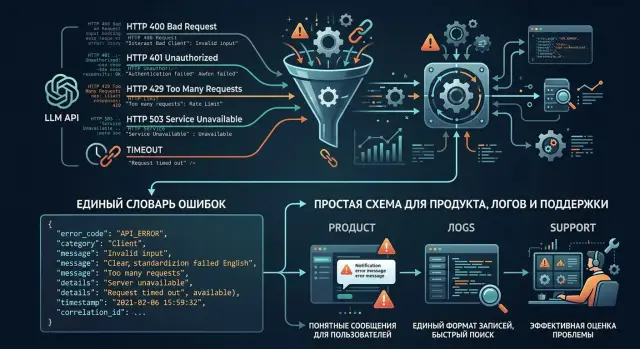
Dec 03, 2024·8 min read
Normalizing LLM API Error Codes for Product and Support
Error code normalization for LLM APIs helps reduce timeouts, limits, and bad requests into one dictionary for product, logs, and support.
LLM API error code normalizationunified error dictionary
Dec 02, 2024·9 min read
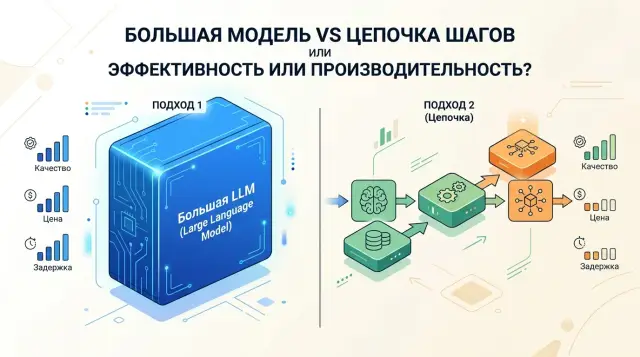
A chain of models or one strong model: which works better where
We break down when a chain of models or one strong model gives the better result: comparing price, latency, quality, and the risk of unnecessary complexity.
chain of models or one strong modelLLM pipeline

Nov 28, 2024·11 min read
Two Answers to One Request: When Choice Beats a Single Answer
We break down when two answers to one prompt help users choose tone, format, or action faster, and when that approach only creates confusion.
two answers to one queryAI answer alternatives
Nov 26, 2024·7 min read
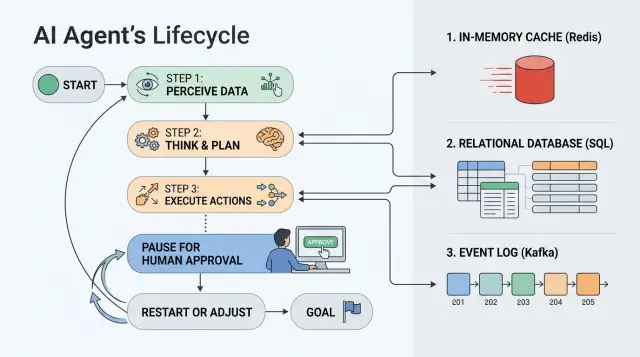
AI Agent State Storage: Redis, DB, or Event Log
How AI agent state is stored affects pauses, approvals, and restarts. We look at when to choose Redis, a database, or an event log.
AI agent state storageRedis for paused workflows
Nov 22, 2024·10 min read
How to avoid overpaying for long context: what to cut and what to keep in memory
How to avoid overpaying for long context: we break down chat history trimming, compression, and dialog memory choices to preserve meaning and reduce tokens.
how to avoid overpaying for long contextcontext compression
Nov 15, 2024·9 min read
Sandbox for AI Tools: Write Access Without Extra Permissions
A sandbox for AI tools helps isolate writes in CRM, databases, and documents so the agent changes only the needed fields and does not get extra access.
sandbox for AI toolsAI agent write permissions
Nov 08, 2024·10 min read
Token Spike: How to Find the Cause Before the Bill After Release
A token spike after a release is easy to miss. Learn how to check prompt length, call frequency, retries, and strange post-release behavior before the bill arrives.
token spikeprompt length

Nov 02, 2024·11 min read
Query Cache Payback: Formula and Calculation Examples
Query cache payback is easy to calculate with a simple formula. We show the repeat threshold for search, support, and email generation.
query cache paybackquery caching formula
Nov 02, 2024·6 min read
What to Log in an LLM App Without Unnecessary Risk
Learn what to log in an LLM app to debug failures, track incidents, and pass audits without storing prompts, PII, or extra data.
what to log in an LLM appminimal LLM log set
Oct 31, 2024·10 min read
When a reranker pays off: recall, latency, and cost
Let’s look at when a reranker pays off in search: how to measure recall gains, the impact on latency, request cost, and when the extra step is not worth it.
when a reranker pays offreranker in search
Oct 30, 2024·8 min read
AI Content Labeling in the Interface: Editor, CRM, Chat
Show how AI content labeling works in the interface and where to place the label in an editor, CRM, and chat so it helps instead of getting in the way.
AI content labeling in the interfaceAI label in the editor
Oct 11, 2024·11 min read
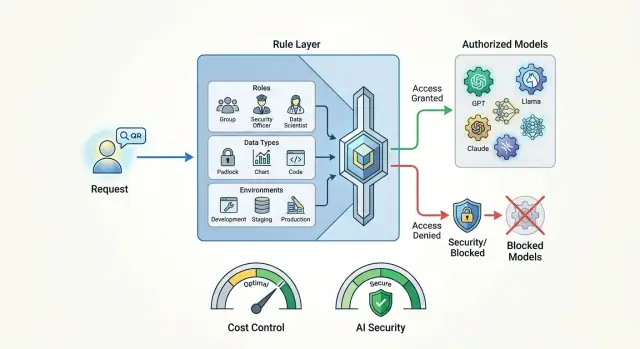
Model access policies for single requests without unnecessary risks
Model access policies help set rules by role, data, and environment so you can control costs and keep sensitive data from leaving your systems.
model access policiesrestricting expensive models
Oct 07, 2024·6 min read
Deduplicating Repeat Requests in Chats and Forms Without Hurting UX
Deduplicating repeat requests helps remove double form submissions and duplicate chat messages, preserve UX, and avoid losing data during network and queue failures.
duplicate request deduplicationdouble form submissions
Oct 06, 2024·9 min read
Customer Complaint Classification: How to Combine Rules and LLMs
Customer complaint classification helps assign queues and SLAs faster when you combine simple rules, LLMs, confidence checks, and manual review.
customer complaint classificationrequest routing

Sep 26, 2024·9 min read
LLM Service Load Testing: Peak, Queues, Bottlenecks
Load testing an LLM service helps you find where queues grow, what breaks under peak load, and where the bottleneck sits in the API, network, and retries.
LLM service load testingqueues in LLM API
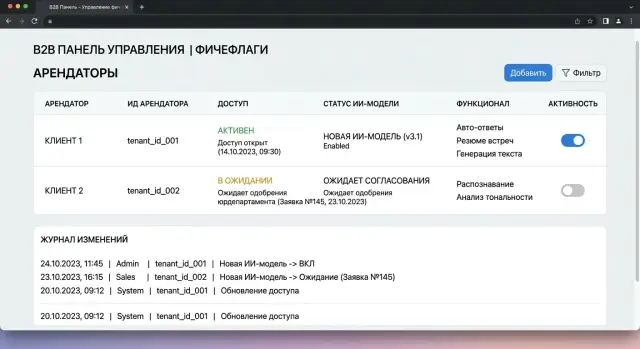
Sep 23, 2024·8 min read
Tenant-based feature flags for AI features: launch plan
Feature flags for AI features let you enable new models by tenant without a global release: launch plan, checks, failures, and an example.
feature flags for AI featurestenant-based model rollout
Sep 17, 2024·6 min read
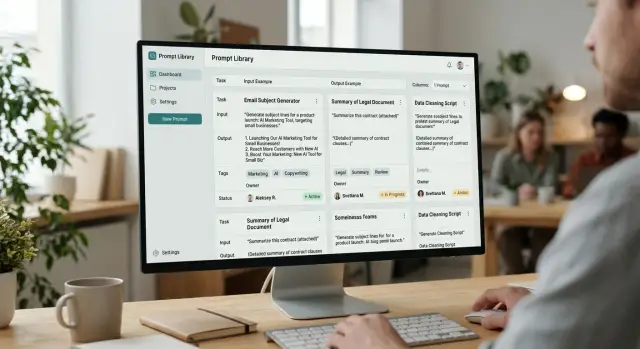
Prompt Library for the Team: Cards, Tags, Owners
A prompt library helps a team keep working templates in one place: cards, tags, owners, examples, and an update routine.
prompt libraryprompt card
Sep 04, 2024·10 min read
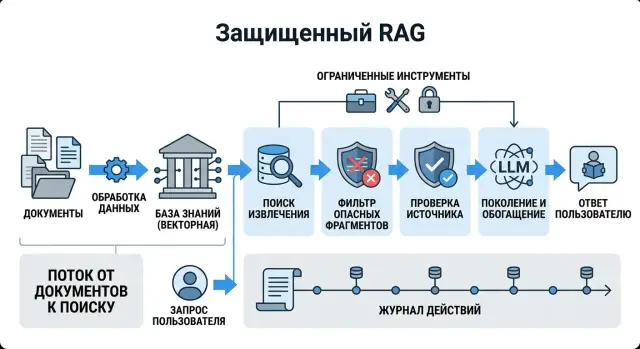
Protecting RAG from Prompt Injection Through Documents in Practice
Protect RAG from prompt injections: clean documents, limit tools, verify sources, and reduce the risk of false answers.
RAG prompt injection defenseRAG security
Aug 30, 2024·10 min read
Enriching Product Listings with Small Models Without Extra Cost
Product listing enrichment can be handled by a small local model when you need attributes, tags, and short descriptions without complex generation.
product listing enrichmentlocal model for attributes

Aug 24, 2024·6 min read
Open-Weight Model: Choosing for the Internal Stack
How to choose an internal LLM: compare open-weight models by size, languages, response format, and GPU needs on real-world tasks.
open-weight modelinternal LLM
Aug 16, 2024·10 min read
Choosing the Right Model Type for a Task on a Single Domain Dataset
Choosing the right model type is easier when you run one domain dataset through summarization, extraction, classification, and chat, then compare the metrics.
choosing the right model type for a tasksummarization vs extraction comparison
Aug 16, 2024·8 min read
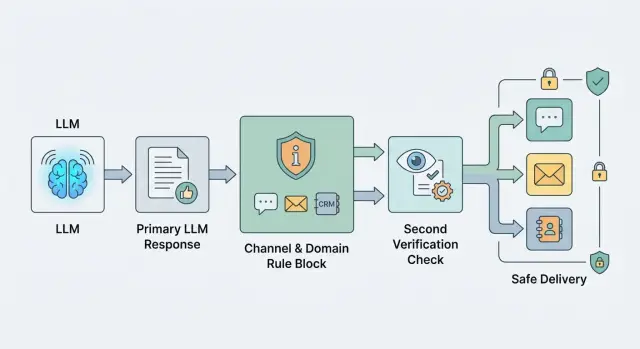
Moderating Outgoing Replies: Where to Place Filters and a Second Model
Outgoing response moderation helps prevent risky text from slipping into chat, email, and CRM. We will look at where to place rules, filters, and a second model call.
outgoing response moderationLLM filters
Aug 14, 2024·7 min read
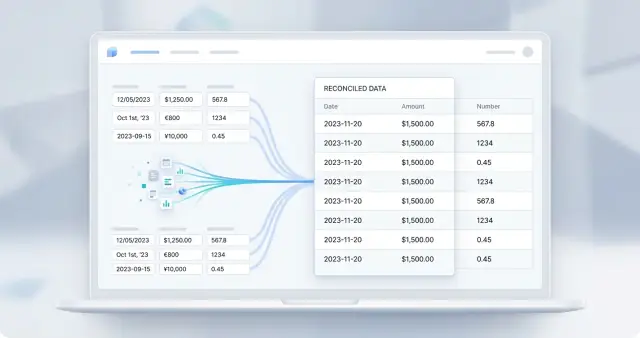
Normalizing Dates, Currencies, and Numbers After LLMs Without Confusion
Normalizing dates, currencies, and numbers helps bring LLM outputs into one format by removing inconsistency in dates, amounts, separators, and currency codes.
date, currency, and number normalizationdate formatting after LLMs
Aug 13, 2024·10 min read
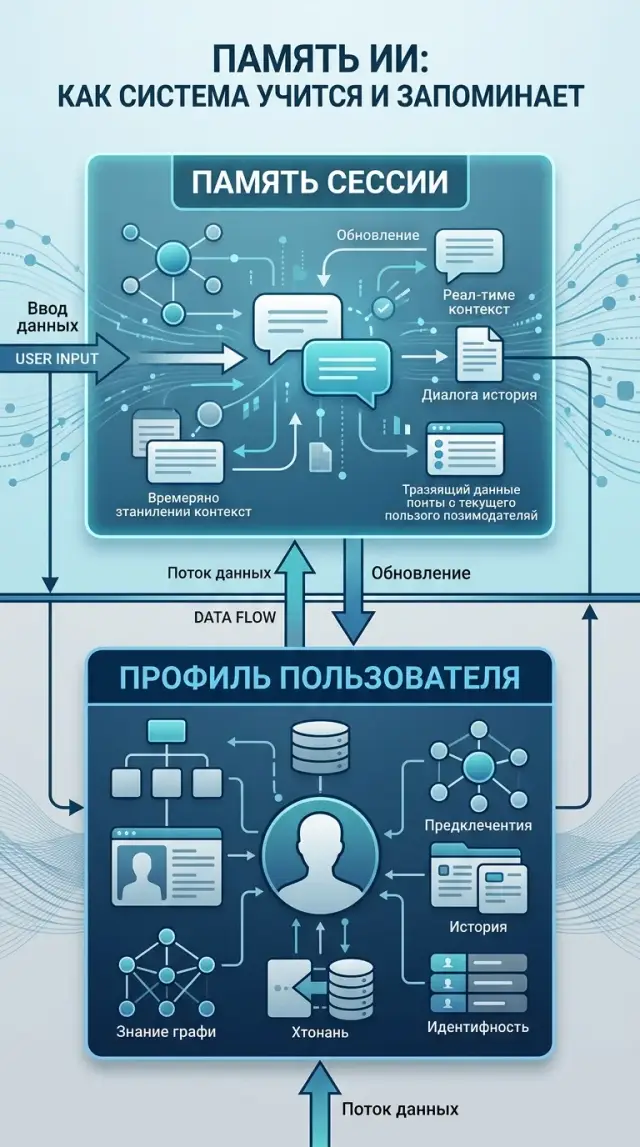
Session Context and User Profile: How to Separate Them
Session context and user profile should be stored separately so the assistant does not mix one-time details, preferences, history, and personal data.
session context and user profileassistant memory
Aug 07, 2024·7 min read
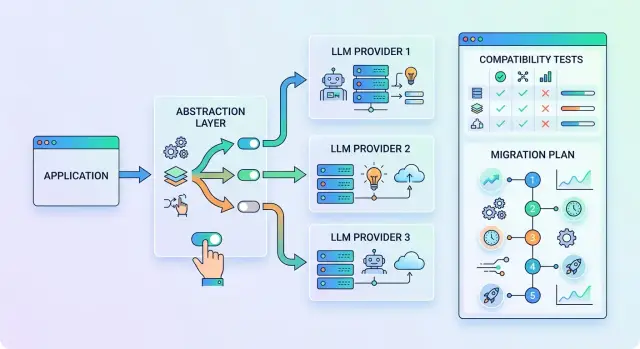
Vendor lock-in: leaving without refactoring
Learn how to reduce dependence on a single vendor with an abstraction layer, compatibility tests, and step-by-step migration without a major refactor.
single-vendor lock-inLLM abstraction layer
Aug 06, 2024·7 min read
LLM Context Trimming Without Losing Meaning: Windows and Summaries
LLM context trimming helps keep a conversation within the token limit. We’ll cover context windows, priorities, conversation summaries, and quick checks.
LLM context trimmingcontext window
Aug 04, 2024·8 min read
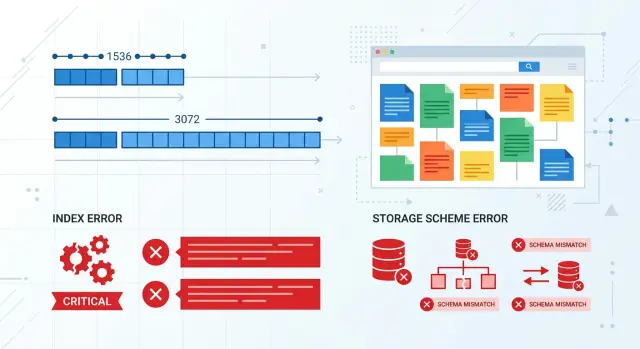
Embedding Dimensionality: Where Search Breaks and Code Breaks
Embedding dimensionality affects search, indexes, and storage schemas. We show where code breaks, where quality drops, and how to migrate safely.
embedding dimensionalityvector search

Aug 03, 2024·9 min read
Domain Search Glossary: Often More Useful Than the Model
A domain search glossary helps the system understand company terms, synonyms, and codes. Often it brings more accuracy than switching models.
domain search glossarycorporate terminology dictionary
Jul 29, 2024·9 min read
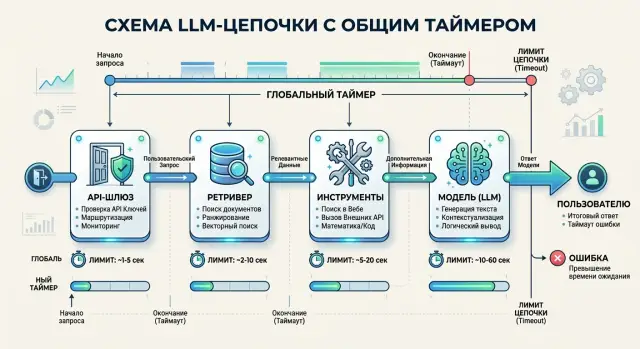
Timeouts in an LLM Chain: How to Split the Time Budget
Timeouts in an LLM chain affect the answer just as much as model choice. We’ll show how to split a shared SLA between the gateway, search, tools, and the model.
LLM chain timeoutsLLM latency budget

Jul 25, 2024·7 min read
LLM Cost in Tenge: How to Build an Annual Budget
We show how to calculate the cost of LLMs in tenge for a year: tokens, exchange rates, traffic spikes, a test buffer, and a clear budget for the team.
LLM cost in tengeannual LLM budget
Jul 23, 2024·10 min read
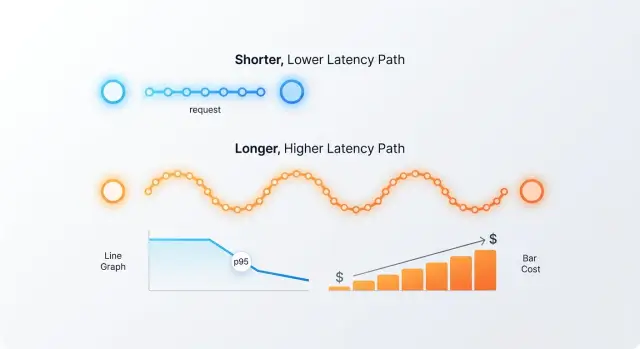
Hedged Requests to Two Models: When p95 Drops
Hedged requests to two models can remove rare slow responses, but sometimes they only double costs. Let’s break down thresholds, metrics, and mistakes.
hedged requests to two modelsreducing p95

Jul 17, 2024·9 min read
Draft and Action in the AI Workflow: How to Set a Barrier
Draft and action in the AI workflow help prevent a model from immediately changing a ticket status, limit, or record. Let’s break down the rule, steps, and checks.
draft and action in the AI workflowseparating draft from action
Jul 16, 2024·10 min read
External LLM provider outage: a day-of action plan
External LLM provider outage: a step-by-step day-of guide for switching routing, adding limits, simplifying features, and coordinating teams.
external LLM provider outagemodel routing

Jul 15, 2024·11 min read
Who Can Change Prompts in Production: A Practical Framework
Who should be allowed to change prompts in production? Let’s break down roles, review, change logs, and rollback so the team does not rely on private agreements.
who can change prompts in productionprompt ownership

Jul 06, 2024·10 min read
Judge Model for Auto-Evaluation: Where to Trust and Where to Check
Judge models for auto-evaluation help you check answers quickly, but not everywhere. Here is how to use a rubric, manual sampling, and signs of systematic errors.
judge model for auto-evaluationLLM evaluation rubric

Jul 03, 2024·8 min read
Pre-release evaluation pipeline: from golden set to regressions
A pre-release evaluation pipeline helps catch regressions before launch: how to build a golden set, choose metrics, and create a report people can read in 10 minutes.
pre-release evaluation pipelinegolden set for LLM