What to Store for Prompt Debugging Without Privacy Risk
What to store for prompt debugging: how to separate raw requests, masked copies, and metrics without exposing personal data.
Where the risk is
A team needs prompt logs for a simple reason: without them, it is hard to understand why the model gave a strange answer, broke the format, or started mixing up roles in the conversation. One bad case almost never explains anything. You need context: what the request was, which system instructions were applied, what answer came back, and at which step things went wrong.
The problem starts when the full text of everything gets into the log. In the first days of debugging, that feels convenient. Later, those logs quickly turn into a warehouse of unnecessary data. A request to an LLM often contains not only the user’s question, but also pieces of CRM data, chat history, internal fields, team notes, and data from attached documents.
The most common mistake is thinking the risk is only in the message text. In practice, personal data is often hidden in ordinary fields that nobody notices at first glance: first and last name in a profile, phone number and email in application metadata, delivery address, IIN, contract number, bank account, or passport details. Free-form operator comments are especially dangerous. They usually contain almost everything.
There is a second problem too: raw requests stay around much longer than the team planned. They get turned on “for a week of diagnostics,” and six months later they are already sitting in analytics, backups, and test exports. The more copies there are, the harder it is to know who can access them and why.
Debugging and long-term archiving are different tasks. For debugging, you usually need the latest incidents, a few typical examples, and the technical context of the error. Keeping the full text for months is often pointless if the goal is only to fix the prompt, not to meet a separate legal requirement or internal policy.
In banking, telecom, or healthcare, this becomes especially clear: one badly configured log can collect more personal data than the business function itself. That is why the rules should be defined before launch. Even if requests go through a single API gateway like AI Router, the logging policy, retention periods, and access rights are still the team’s responsibility.
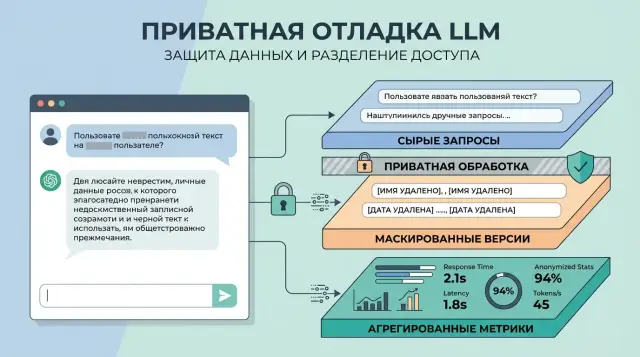
Three log layers
If you are deciding what to store for prompt debugging, do not put everything into one log. Troubleshooting, quality control, and reporting need different data, which means different lifespans too.
Usually three layers are enough:
- raw requests for rare investigation of serious incidents
- masked copies for everyday debugging and quality analysis
- aggregated metrics for the big picture without text
The raw layer is not needed every day. It is used when the team sees a disputed answer, a failure in the tool chain, or a complaint that cannot be understood from an anonymized version. That is why this layer should be kept very briefly — from a few hours to a few days. Access should go only to on-call engineers and people who have formal authority to investigate incidents. If the company works with sensitive data, it is better to keep the raw layer separate from the regular logs and record who opened it and why.
The masked copy lives longer. This is what developers usually use to look for weak spots in the prompt: where the model loses context, mixes up roles, or fails to follow the response format. In this version, names, phone numbers, emails, IINs, contract numbers, and other identifiers are replaced with clear markers like [NAME] or [ACCOUNT_ID]. The text remains useful, but it no longer reveals the person directly.
Aggregated metrics should not contain text at all. Numbers and labels are enough here: error rate, average latency, token count, model failures, filter triggers, cache hit rate, and the number of manual escalations. These make it easy to see that a new prompt increased cost by 18% or doubled the number of empty responses, even if nobody reads a single request.
Set a separate retention period and access circle for each layer. Raw data should have the shortest retention and the narrowest access. Masked logs can live longer. Metrics can live the longest and be available to the widest group.
If you work through AI Router on airouter.kz, it is worth aligning this right away: where PII masking starts, who can see the audit logs, and how long raw requests live. The gateway reduces some operational risk, but it does not replace an internal retention policy.
What to keep in the raw layer
The raw request is not for analytics, but for rare investigations when the answer breaks and the team needs to understand why. So keep only what is necessary to reproduce the failure. Everything else is better moved to the masked layer or to metrics.
A practical minimum looks like this:
- the system prompt text in a separate field
- the user prompt text in a separate field
- tool calls and tool responses separate from the dialogue text
- model name, version, provider, and the actual request route
- call parameters: temperature, max tokens, top_p, and others if they really affect behavior
- number of input and output tokens, response code, response time, and request id
This separation makes investigations easier. If the model started behaving strangely after the system prompt changed, that is visible immediately. If a tool call caused the failure, you will not have to search for it inside a large JSON object where roles, text, and service fields are mixed together.
Do not put everything into the raw layer. Attachments, files, images, document scans, long customer profiles, and CRM history should not be copied there in full. For error searches, a link to the object, its type, size, MIME type, and processing status is usually enough. If a file got corrupted, you will know that even without a copy of the passport or statement.
The same rule applies to customer data. There is no need to log the full profile, addresses, card numbers, or complete history of requests. If context matters for the investigation, keep short technical fields: internal user id, segment, language, channel, and scenario version. That is usually enough.
If the team uses one LLM gateway, it is helpful to store not only the external endpoint, but also the actual model and provider where the request went. Otherwise every investigation gets stuck on the phrase “everything went through one API,” which explains almost nothing.
Raw text is better removed on a timer. Not manually, and not with a “we’ll clean it up later” approach, but through TTL and automatic cleanup. For many teams, 7–30 days is enough if incidents are handled quickly. Longer retention is usually reserved for separate cases with a clear basis. This is easier to check, easier to explain to security, and much harder to violate by accident.
How to build a masked copy
A masked version is needed for everyday debugging. It shows where the prompt breaks, but does not carry unnecessary risk with it. For most teams, this is the most useful layer: you can see the shape of the request, the order of fields, and the point of failure, but not another person’s personal data.
Sensitive fragments are best replaced with simple tags. A name can become [NAME], a phone number [PHONE], email [EMAIL], and IIN [IIN]. If the text contains a card number, address, or contract number, those should get their own tags too.
The point is not to turn the phrase into an empty template. Keep the structure. If the user wrote, “My name is Aizhan, my IIN is 990101300123, please check the application status,” the log should ideally read, “My name is [NAME], my [IIN], please check the application status.” Then you can still see where the model failed: during entity extraction, request routing, or in the response itself.
You should mask both the input text and the model response. Otherwise the team removes data from the request, and the model brings it back in its answer. In bank chatbots, clinic bots, or support systems, this happens all the time: the response repeats the client’s name, phone number, or part of a document.
The replacement dictionary is best stored separately from the logs. The regular journal should contain only masked text. A mapping table where [NAME_17] is linked to the real value, if it is needed at all, should live in a different storage system with a short lifespan and very narrow access. Most developers do not need it at all.
There is another unpleasant trap: masking often misses messy input. People write email addresses with spaces, phone numbers without a country code, or IINs with an extra character. OCR from a scan adds noise: “8” becomes “B,” “@” disappears, and a name gets split into pieces. That is why masking should be tested on real examples with typos, mixed language, and text after document recognition.
The rule is simple. If the mask makes it hard to understand the flow of the conversation, it is too aggressive. If the log still lets you identify a person, it is too weak.
Which metrics to track without text
To understand where a prompt breaks, you do not always need the text itself. Often, numbers give an even more honest picture: they do not carry personal data with them and quickly show where the team is losing money, time, and quality.
Instead of storing every message, start with the events around it. For each call attempt, it is usually enough to store the task type, model, route, response time, token count, final status, and a few service flags.
Five metric groups are usually enough:
- failure rate by task type
- tokens and cost by model and route
- latency, timeouts, and network drops
- frequency and depth of human edits to the response
- number of repeats within one scenario
Failure rate quickly shows where the prompt is not holding the task. The same instructions may work fine for summarization, but regularly fail on field extraction or customer replies. For that signal, you do not need the request text. You need the scenario label and a clear reason: empty answer, policy refusal, wrong format, or overly long output.
It is worth tracking tokens and cost by model and route. This is especially noticeable where requests go through a single LLM gateway and the team is not locked to just one model. Sometimes the same result is achieved on a cheaper model. Sometimes the expensive model simply uses twice as many tokens because of extra context. You can see that from the numbers in just one day.
Latency should not be viewed only by the average. The user does not care that the average was good if every twentieth request freezes for 18 seconds. That is why p95, p99, timeouts, retries, and network drops are useful.
The frequency of manual edits shows real quality better than a dry “error or no error” status. If a bank operator changes the model’s answer in 40% of cases, the prompt is still rough, even if formal failures are rare. It also makes sense to track the depth of the edit: fixing one date and rewriting the entire answer are different problems.
Repeats in the same scenario also say a lot. If a user or operator sends the same request twice, the first answer did not help. That is a good signal for improvement, even when the text itself is not stored.
These metrics are convenient to review by day, prompt version, and task type. Then after each change, the team can see exactly what improved and what stayed the same.
How to roll it out step by step
It is better to start not with a long field table, but with roles. First decide who will actually look at the logs. A developer needs text to understand why the prompt gave a weak answer. An analyst often only needs the masked version and counters. A support agent usually only needs the session number, time, and final status.
Then build the storage scheme and assign permissions by layer.
- Keep the raw layer the narrowest. Store only what is necessary to investigate a failure: request ID, time, model, system prompt, user input, response, error code, and call parameters. Keep the retention period short.
- Write the masked layer before the record is logged, not after. If the request contains a name, phone number, IIN, card number, or address, the service should replace those parts with tags before the entry reaches the log.
- Keep metrics separate. They do not need text. Length of request, token count, latency, error rate, cost, and a quality score, if you have one, are enough.
- Test the scheme on one clear scenario. For example, take one stream of user requests and run it through the whole chain: intake, masking, logging, metrics collection, incident review.
- Expand coverage only after a short check with the team. Let the developer, security lead, and product owner answer one simple question: can the cause of an error be found without extra personal data?
This order removes half the disagreements before launch. The team understands faster where the original text is truly needed and where a masked copy and simple metrics are enough. For companies with requirements to keep data inside the country and to maintain audit logs, it also makes access review and data retention much easier.
Example with a bank chatbot
A customer writes in a bank chat: “Hello, I cannot see the status of my card reissue. My name is Aliya, my phone number is 8 701 123 45 67.” For the team, this is a normal support request. For logging, it is already a mix of useful signal and personal data.
In this situation, one shared log with everything in it is not needed. It is better to split the record into three layers and give each its own lifespan.
The raw layer is only needed for rare failures. There the bank stores the prompt ID, selected model, request time, technical status, and the text itself in a short retention window — for example, 24 hours or a few days under internal rules. That is enough to investigate a specific failure: the model did not understand the customer’s intent, asked an unnecessary question, or got stuck on the response.
At the same time, the system creates a masked copy. In it, the customer’s sentence looks like this: “Hello, I cannot see the status of my card reissue. My name is [NAME], my phone number is [PHONE].” If there is a contract number, IIN, or address in the conversation, those are replaced with tags too. The meaning of the request stays intact, but the personal data is removed.
This layer is more useful than it first appears. The product team can still see that people often ask about card status, confuse reissue with blocking, or do not understand what data the bot is allowed to ask for. But for everyday analysis, nobody needs to read real names and phone numbers.
Separate aggregated metrics live without text. The bank tracks the rate of follow-up questions, average response time, the number of handoffs to an operator, and the frequency of errors by prompt template or model. If the rate of follow-up questions rises from 12% to 27%, the problem is obvious right away. No real phone number is needed for that.
After a week, the raw text is deleted. Masked examples can be kept longer for scenario analysis and testing new prompt versions. Metrics usually live even longer, because they help compare models over months and do not contain personal data.
For a bank, this is a sensible compromise. Engineers do not lose debugging material, and security does not get an endless archive of customer messages.
Where teams go wrong
The first mistake is simple: the team keeps full request text longer than it is needed for incident analysis. At first, this seems convenient. A month later, the logs already contain customer names, contract numbers, email fragments, attached documents, and the full conversation. Then nobody can honestly explain why all of it is still being stored.
The second mistake looks cleaner, but it is no better in practice. The team masks the input request, but leaves the model response untouched. That is enough for sensitive data to return to the log. The user enters an account number in the input, masking hides it, and the model repeats the number in the response.
The third mistake is giving everyone the same access. Development, analytics, and security all get the same permission level simply because it is faster. That is convenient at the start. Later it becomes clear that a developer rarely needs the full raw text, analysts almost never need original messages, and the security team does not need permanent access to every session.
The fourth mistake appears when the log captures the entire context without any filtering. It includes the system prompt, chat history, RAG search results, and attached files. One bad debug dump in that case turns into an archive of private data.
There is also a quieter problem: the team looks only at tokens, cost, and latency. These numbers are useful, but they do not show where the model started mixing up roles, losing instructions, or answering off topic. If you only track aggregated metrics, you can miss a failure that users already see every day.
A simple structure usually helps: raw requests live for a short time and are available to a narrow group, masked versions are kept longer and are suitable for quality analysis, and aggregated metrics live the longest and contain no text.
Check before launch
This kind of setup does not fail in theory, but on the first day after release, when someone tries to find the cause of a model response failure. If the logs mix raw text, masked copies, and metrics, the team spends hours and creates extra privacy risk at the same time.
A normal sign of readiness is simple: an engineer can find the cause in a few minutes and does not need access to everything at once.
Before launch, check a few things:
- the raw layer has an exact deletion period and automatic cleanup
- the masked copy does not let a person be reconstructed from the field set
- metrics do not contain text, user_id, email, request number, or other direct identifiers
- access is separated by role, not given equally to everyone
- the incident review path is clear: first metrics, then masked examples, and only then the raw layer
In practice, the second and fourth points are the ones most often missed. The team masks email, but leaves the contract number, a rare address, or a free-form comment with a doctor’s surname. Formally the data is already “anonymized,” but the person can still be identified. Access works the same way: if one shared log is visible to the analyst, developer, and support contractor, there is no real separation.
A small test quickly finds weak spots. Take 20 real records, show the masked version to someone outside the project, and ask: can they guess the customer, product, or specific case? If the answer is “yes” even a couple of times, masking is not ready yet.
If you are rolling out LLM integrations through AI Router on airouter.kz, before the first production traffic separately check four things: where raw requests live, how PII masking is enabled, who sees the audit logs, and which data must stay inside the country. It is better to solve this in advance than to redesign the setup under live traffic.
What to do next
Do not try to rebuild all logs at once. Pick one scenario where there are many requests and mistakes affect the service quickly: support chat, knowledge base search, or an assistant for operators. On one flow, it is easier to see which data is really needed for debugging and which fields you are keeping only by habit.
Agree on retention periods before launch. Product, development, security, and legal should decide in advance how long raw text lives, how long masked copies are kept, and who can view them. After an incident, these decisions almost always get worse: the team gets nervous and leaves too much in place.
A practical sequence usually looks like this: the raw request is kept only by a narrow group and only for a short time, the masked version lives longer because it is convenient for finding error patterns, and only aggregated metrics without text go into reports and dashboards. It is useful to review the log scheme once a month and remove fields that nobody uses.
It is a simple discipline, but it cuts risk well. Very often, logs keep pieces of chat history, customer identifiers, and internal notes for months, even though debugging only needs request length, error type, model, latency, and cost.
A good first step this week is simple: take one frequent scenario, draw three storage layers for it, and remove at least one field that does not help anyone investigate errors.
Frequently asked questions
Why store raw requests at all if masking exists?
Raw logs are needed for rare investigations when the masked version is no longer enough. They help you see the exact system prompt, user input, model response, and call parameters so you can find the cause of a failure faster.
How long should the raw log layer be stored?
Usually a window from a few hours to a few days is enough. If your team resolves incidents quickly, do not keep full text for months and delete it by TTL, not manually.
What should actually be recorded in the raw log?
Keep only what you need to understand the failure: the system prompt, user prompt, model response, tool calls, model name, provider, route, call parameters, tokens, response code, time, and request id. That is enough for most debugging.
What should not go into the raw layer?
Do not send full customer profiles, attachments, scans, the entire CRM history, or extra service fields there. For files, a link to the object, its type, size, and processing status is usually enough.
How do you know PII masking works properly?
Test masking on real examples with typos, OCR noise, and mixed language. If the log still lets someone identify the person, the mask is too weak; if you can no longer follow the dialogue, it is too aggressive.
Should you mask only the request or the model response too?
Yes, absolutely. If you hide only the input, the model often repeats a name, phone number, IIN, or contract number in the response, and the data ends up in the log again.
What metrics can be collected without request text?
Start with error rate, latency, timeouts, tokens, cost, manual edits, and repeats within one scenario. These numbers quickly show where the prompt breaks, even without reading the text.
Who needs access to raw logs and who can work with masked ones?
Separate access by role. Give engineers narrow, time-limited access to the raw layer, let developers and analysts work with masked logs, and open metrics more widely because they contain no text.
How do you check the logging setup before launch?
Run a short test on one scenario: request intake, masking, log writing, metrics collection, and incident review. Then show the masked records to someone outside the project and ask whether they can identify the customer or the case.
Where should you start with this setup?
Take one common scenario, such as support chat, and split it into three layers right away: raw, masked, and metrics. That helps the team quickly see which fields are truly needed for debugging and which ones are kept in logs out of habit.