PII masking before calling the model: where and how to do it
PII masking helps hide personal data before sending a request to an LLM. We show where to place redaction, how to measure meaning loss, and how to safely return fields.
Why you should not send PII to the model as is
When an employee pastes a customer email, a ticket, or a CRM conversation into a prompt, personal data almost always comes along with it. Usually it is not just one field, but a whole set: full name, phone number, email, IIN, address, contract number, and sometimes date of birth and payment details. For the model, it is just text. For the business, it is a risk.
The problem is not limited to the model call itself. Raw text often ends up in several places at once:
- in application logs
- in chat or ticket history
- in request cache
- in tracing and APM
- in debug dumps
Even if the model did not "remember" anything, copies of the data are already sitting in your infrastructure and with external services along the way. Sometimes one debug log is enough to make the whole protection scheme pointless.
The risk grows when the team changes models and providers. Today the request goes to one service, tomorrow to another. Developers often just change the base_url and send the same prompt. That is convenient, but the data path changes. Different providers have different retention rules, different processing regions, and different sets of service logs. If you also run A/B tests in parallel, the number of risk points grows even more.
A pilot does not save you either. During the test phase, teams are actually more likely to disable filters, write more logs, and ask colleagues to paste real cases "to check quality." That is how real IINs, addresses, and phone numbers end up in the test environment. Then the pilot grows into a production service, while the raw data has already spread across chats, laptops, and monitoring systems.
There is also a quiet problem: PII sticks to data so fast that it becomes hard to remove later. If an operator sends a phrase like "Check the request for Айгерим Садыкова, IIN 030101..." to the model, that data may show up in the model response, in forwarded chat, and in manual labels for quality evaluation.
That is why personal data redaction needs to happen before the model call, not after. It is better to spend a minute setting up a filter than to later search for where exactly the system stored someone else’s IIN or address.
What counts as PII in your flow
PII rarely sits in one field with a clear "personal data" label. More often it is spread across the application form, support chat, emails, PDFs, document scans, and OCR text. If you only look for name, phone, and email, you will almost certainly miss part of the risk.
Start by gathering all real input sources: forms, chat, email, CRM exports, scans, voice transcriptions, and OCR results. Then break down which pieces the model sees in full and which ones enter the prompt in fragments. After that exercise, the list of sensitive fields usually grows quite a bit.
It helps to split the data into two groups:
- Direct identifiers: full name, IIN, phone number, email, exact address, passport number, internal customer ID.
- Indirect identifiers: order number, job title, city, workplace, hire date, rare complaint, branch number.
Indirect fields are often underestimated. Alone, they may seem harmless. But a phrase like "chief accountant in Kостанай, order 184533, hire date May 12" can already point to one specific person.
Check free text separately. That is where people add extra details: "My name is Айжан, my IIN is..., I was at the doctor yesterday." OCR has the same effect. A scan can contain a name, signature, document number, and address even if you never meant to send them to the model.
Not every field needs to be removed completely. Some data can be generalized without noticeable loss of meaning. Instead of date of birth, an age range is often enough. Instead of a full address, a city. Instead of an exact amount, a range. If the model needs the context of the request, not the identity of the customer, that is usually enough.
For Kazakhstan, it is best to add IIN to the rules from day one. This is not a rare edge case or a separate branch for a couple of customers. IIN appears in forms, emails, contracts, scans, and chats, often next to a name and phone number.
There is a simple test. Take 20–30 real requests and mark which data the model truly needs to answer and which data is only needed by your systems. In many scenarios, the model only needs to see the customer’s problem, order status, and product. It does not need IIN, full address, or phone number.
Where to place redaction in the flow
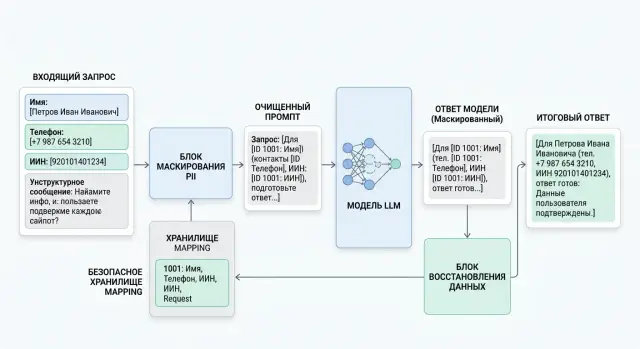
Personal data redaction should go at the very beginning of the chain. If the request first reaches logs, cache, or the agent history and only then gets cleaned, the protection has already failed. The data will already have spread across systems where it is hard to find and remove.
Usually the best layer for this is the input API or gateway, before routing and before any agent work. The text arrives, the service finds PII, replaces fragments with tags like [EMAIL_1] or [PHONE_1], and only then passes the request onward.
A workable order looks like this:
- Right after receiving the request, identify sensitive fields in the text, metadata, and service fields.
- Replace the found values with clear tokens: [NAME_1], [PHONE_1], [IIN_1]. The same fragment should get the same token within a request.
- Save the mapping table separately from the prompt only if it is truly needed. It is better to bind it to request_id and keep it for a short time.
- Send only cleaned text to logs, cache, the agent, and the model.
- After the model response, return fields only to allowed places and only by strict rules.
The last step is often where teams break things. They take the model response and simply replace every [NAME_1] with the original name anywhere in the text. That is risky. The model may move the token into a new context: for example, insert [PHONE_1] into a note for an operator or into an extra paragraph. It is safer to define the allowed field list in advance, such as greeting, contact_block, or contract_number. If a token appears outside that list, leave it masked and send the response for review.
The same rule applies to attachments. PDFs, scans, document photos, and voice transcriptions after OCR often contain even more sensitive data than regular chat. Files should not have a separate path without filtering: first extract the text, then clean it, and only after that index, summarize, or call the model.
Raw text only makes sense to keep in a separate closed environment. Usually you need it for disputed cases, manual checks, or archive tasks where you cannot do without the original. In that case, keep it separate from the main application, restrict access by role, and set a short retention period.
If the team has a single LLM gateway, the rule does not change. First clean, then send the request onward. This also applies to AI Router: in api.airouter.kz, it is better to send already anonymized text, even if the gateway itself helps meet data residency, audit-log, and PII masking requirements.
A good sign of a mature process is simple: the prompt, cache, and model response live without personal data, and reverse substitution happens only at the end and only by the rules.
How not to lose meaning after masking
PII masking can easily break the meaning of a request if you only test it on a couple of lucky examples. You need a simple test: take the same task, the same prompt, and compare the model’s answer on raw text and cleaned text.
You do not need a huge dataset for this check. A set of real requests that commonly appear in work is enough: support tickets, forms, applications, emails, operator notes. Rare and exotic cases are better kept separate, otherwise they will distort the picture.
You should not only look at the "answer quality" in a general sense. Check at least five things:
- did the model understand who is who in the text
- did it confuse dates, amounts, and addresses
- did it produce more unnecessary refusals
- did important details for solving the task disappear
- did the answer start sounding too generic
Unnecessary refusals are often missed. The original request may be clear, but after replacing the name, contract number, and address with blunt tags, the model suddenly says there is not enough data and it cannot help. Formally that is safe, but for the business it is a weak result.
Check mask types separately. The same scheme affects meaning differently. A name rarely breaks the task. An address can break request routing. An amount changes the priority of the inquiry. A document number is sometimes needed to tell two similar cases apart.
So it is better to test in steps. First replace only names. Then only amounts. Then only documents. Then only addresses. That makes it faster to see exactly what hurts the answer.
A small example: a complaint contains the phrase "write off the incorrectly charged 12 500 tenge under the contract dated March 14." If you replace both the amount and the date with the same token like [REDACTED], the model may lose the connection to the event and answer vaguely. If you use different tags, such as [SUM_1] and [DATE_1], the meaning is usually preserved better.
If you call models through a gateway like AI Router, the test is still necessary. The gateway handles routing and infrastructure, but it is your task to decide how much masking still leaves the text understandable.
Example with a customer request
A regular support email already gives the model all the context it needs. The original personal data is usually not needed for that.
Здравствуйте. Меня зовут Айгуль Садыкова, мой телефон +7 701 123 45 67, ИИН 930512400123.
У меня второй день не проходит оплата в мобильном приложении. После подтверждения перевода вижу ошибку "операция отклонена", хотя лимит не превышен.
Проверьте, пожалуйста, что не так и как мне завершить платеж.
Before the model call, the text goes through PII masking. The service changes the name, phone number, and IIN into tokens, and keeps the replacement map separately. It is better to keep it in request memory or in protected storage with a short lifespan.
Текст для модели:
Здравствуйте. Меня зовут [NAME_1], мой телефон [PHONE_1], ИИН [IIN_1].
У меня второй день не проходит оплата в мобильном приложении. После подтверждения перевода вижу ошибку "операция отклонена", хотя лимит не превышен.
Проверьте, пожалуйста, что не так и как мне завершить платеж.
Карта замен:
[NAME_1] -> Айгуль Садыкова
[PHONE_1] -> +7 701 123 45 67
[IIN_1] -> 930512400123
The meaning of the email barely changes. The model still sees the problem: a payment failure in the app, a repeated error, and a request to explain the next step. That is enough to classify the request, suggest a check, and draft a reply.
It is best to check meaning loss on a simple pair of tests. Give the model the original text and the masked text, then compare the result on three things: whether the topic of the request was identified correctly, whether urgency disappeared, and whether the recommendation for the customer changed. If the answers match in substance, personal data redaction is not breaking the task.
In this example, the model may suggest checking the card status, trying the payment again later, confirming whether the error repeats on another network, and, if needed, sending the case to the payments team. Neither the name, phone number, nor IIN is needed for that.
Put back only the fields that the final answer cannot do without. Usually a name is enough for the greeting. There is no need to insert the IIN into the customer response. The phone number is also unnecessary if the system already knows the contact channel.
Финальный ответ клиенту:
Айгуль, здравствуйте. Мы видим повторяющуюся ошибку при оплате в приложении.
Попробуйте обновить приложение и повторить платеж чуть позже.
Если ошибка сохранится, мы передадим обращение в профильную команду и свяжемся с вами по текущему каналу.
This flow noticeably lowers the risk of leakage while preserving the meaning of the request for the model.
How to safely restore fields in the response
After PII masking, the most dangerous step is reverse substitution. A mistake here quickly breaks the whole protection: the model changes the token, moves it into another text fragment, or inserts personal data where it should not be.
Put data back only for tokens that the model returned unchanged. If you sent [PHONE_1] and got the same [PHONE_1] back, the number can be restored. If the model wrote [PHONE], PHONE_1 without brackets, or just "the customer’s phone number," it is better to block the replacement.
You also need type checking. A phone number can be returned only into the phone field, email only into email, and IIN only into IIN. A simple string replacement without type checks quickly leads to absurd and dangerous mistakes, where an email suddenly ends up in a letter signature and a phone number ends up in the name field.
Usually the following order is enough:
- find only exact, unchanged tokens in the response
- match the type of each token to the target field type
- substitute data only into allowed parts of the response
- delete the temporary mapping table immediately after the response is sent
It is better to define the allowed parts of the response in advance. For example, you can return data in the customer-facing text or in specific CRM fields. Do not return it in service notes, technical logs, error traces, or internal comments. If you have audit logs at the gateway level, store tokens and the fact of replacement there, not the original values.
The model itself does not need a mapping table like [EMAIL_1] = [email protected]. It should only see tokens. Keep the map on your side: in request memory, in protected storage with a short TTL, or in a separate service that does not write values to logs.
A short example: the customer writes "Call me on [PHONE_1] and send the contract to [EMAIL_1]." The model answers "We will contact you at [PHONE_1] and send the contract to [EMAIL_1]." Such an answer can be restored automatically. If it answered "We will call you" or moved [EMAIL_1] into a note for the operator, substitution is not needed.
Temporary mapping tables should not be kept for hours. For most scenarios, a few minutes is enough. The response is sent to the customer, the rollback window closes, and the map should be deleted.
Mistakes that break protection
Most often, protection breaks not at the model level, but earlier. The team seems to have added PII masking, but one wrong step in the chain wipes out the result: raw data has already hit a log, the replacement map is sitting next to the prompt, and the response is being stitched back together without checks.
The most common mistakes are these:
- Redaction is added too late. If the API gateway, proxy, tracing, or debug log managed to record the original text before masking, the protection has already failed.
- Everyone is replaced with the same marker. In a phrase like "Иван transferred money to Ольга," the token [PERSON] quickly breaks roles and meaning. It is better to use [PERSON_1], [PERSON_2], [ACCOUNT_1].
- Only regular text is cleaned. In practice, PII also lives in PDFs, screenshots, tables, CSV files, and OCR text.
- Hidden fields are returned in free-form text without a template. The model may place the field in the wrong spot, change the number format, or mix data from two customers.
- The mapping table is stored next to the request. If the prompt, replacements, and original values live in the same record and are available to one service without restrictions, the risk does not go away.
There is a good quick test: imagine someone got access only to the model logs. Could they recover the person, account, phone number, or address? If yes, masking was only done on paper.
It also helps to check the other direction: does the model still understand the meaning after replacement? Take 20–30 real examples and compare the result before and after cleanup. If quality drops sharply, the problem is often not the masking idea itself, but overly blunt tokens with no distinction between entities.
Also check the data return path separately. The service that does reverse substitution should not guess where to insert a field. It should work only with allowed slots, such as [CLIENT_NAME] or [PHONE_1], and reject any extra text around them. It is a dull rule, but it is often what saves you from quiet leaks.
Pre-launch checklist
Before release, you do not need a hundred-page audit. A short check is enough, but you have to do it honestly. If you answer "no" to even one item, it is better to stop for a day and fix the setup.
- Check whether the model can see any real name, phone number, IIN, card number, address, or contract number.
- Make sure redaction runs before logs, cache, queues, retries, and tracing.
- Run meaning-loss tests on 20–30 real requests without unnecessary exotic cases.
- Limit the places where reverse substitution can happen. Restoration should happen only in the final response layer and only by a field whitelist.
- Assign an owner for the rules: who changes the dictionaries, who approves new PII types, and who handles incidents.
One end-to-end test catches half the problems. Take a customer request like "My name is Алия, my number is 8..." and run it through the whole path: input, log, cache, model call, response, field substitution. At each step, it should be clear where the real data lives and where only masks live.
If you send requests through a gateway, check the same chain not only in the application but also at the integration level. Otherwise you can neatly close the front end and leave raw data in service layers where nobody expected to see it.
What to do next
Start with one entry point. All requests to models should go through the same layer, even if you have several applications, teams, and providers. Otherwise one integration will mask data, while another will accidentally send a phone number, IIN, or contract number to the model as is.
After that, put the rules into one document. Not in chat and not in scattered notes, but in a short working description: which fields you mask, which tokens you use, where you store the mapping table, who can restore the original values, and in which responses that is allowed. If the rule cannot be read and checked quickly, people will interpret it differently.
A sensible starting plan looks like this:
- choose a single entry point for all LLM calls
- describe masks, exceptions, and field restoration in one place
- run a pilot on 50–100 real requests
- review errors manually and adjust the rules before a broader launch
It is better to run the pilot on live scenarios, not made-up examples. Take customer requests, internal employee requests, or typical documents and check two things: whether personal data leaked and whether meaning was lost after replacement. Usually problems show up quickly. The model confuses tokens, loses links between fields, or starts answering too generally if you hide more than necessary.
Manual review is mandatory here. Look at where the mask breaks the task and where the rules, on the contrary, are too loose. It is useful to mark every failure with a simple scheme: what you hid, what the model was supposed to understand, what it actually understood, and whether the field can be safely returned after the response without sending the raw data to the model again.
If you work with several providers, there is no need to duplicate this logic in every service. It is easier to move masking, audit logs, and field restoration control into one layer. For teams in Kazakhstan and Central Asia, that layer can be AI Router: a single OpenAI-compatible API gateway that helps centralize model routing and data residency requirements inside the country. But even then, the safer base rule stays the same: clean the text first, then call the model.
A good outcome at this stage looks simple: every request passes through one filter, the rules live in one place, and after the pilot you have a list of specific fixes instead of the feeling that "it all seems safe."
Frequently asked questions
Why can’t I just send a customer email to the model as is?
Because the risk does not live only in the model itself. Raw text often ends up in logs, cache, chat history, tracing, and debug dumps. Even if the model does not store the request, copies of the data are already sitting in your system and in services along the way.
What counts as PII besides name and phone number?
Look wider than name, phone number, and email. Your flow may also include IIN, address, contract number, internal ID, date of birth, payment details, and indirect clues such as city, job title, order number, or an unusual complaint. In combination, these fields can also identify a person.
Where is the best place to mask data in the flow?
Put the filter at the very start, before logs, cache, queues, retries, and the model call. An input API or LLM gateway is usually the right place. If another part of the system sees the text first and you clean it later, the protection has already cracked.
Do PDF files, scans, and OCR text also need cleanup?
Do not create a separate path for files. First extract text from the PDF, scan, or audio, then find and replace sensitive fragments, and only after that send the data to indexing, summarization, or the model. OCR often brings in more extra data than it seems at first.
How do I replace data without losing meaning?
Use clear tokens with a type and a number, such as NAME_1, PHONE_1, IIN_1. Do not replace everything with one marker like REDACTED, or the model will lose roles and relationships in the text. If there are two people in the request, give them different tokens so actions and context do not get mixed up.
How can I check whether quality dropped after masking?
Take 20–30 common real requests and compare the answers on raw and cleaned text. Check whether the model understood the topic, whether urgency was lost, and whether the recommendation became too generic. If quality drops, the problem is usually the blunt masking, not the cleanup idea itself.
Where should I store the mapping table and for how long?
Keep it separate from the prompt and for as little time as possible. It is better to tie the map to request_id, keep it in request memory or in protected storage with a short TTL, and avoid writing values to logs. If the prompt and raw data sit next to each other, the risk barely changes.
How do I safely restore fields in the final response?
Return only the tokens the model kept unchanged, and only into allowed fields. If you sent PHONE_1 but received a different format or a new context, block the substitution. A name can go into a greeting, but IIN or phone should not be inserted into free text without a strict template.
What mistakes most often break the protection?
Most often teams clean too late, clean only regular text, and store the replacement map next to the request. Another common mistake is putting the original data back with a simple string replace, without checking location and field type. In the end, the leak happens not in the model but in the service layers.
If we already have an LLM gateway, do we still need masking?
No, the gateway does not replace cleanup on your side. It helps centralize routing, logs, and access rules, but you decide which fields the model should see at all. The safe order is always the same: first anonymize, then send the request onward, even if you use a single layer like AI Router.