Vendor lock-in: leaving without refactoring
Learn how to reduce dependence on a single vendor with an abstraction layer, compatibility tests, and step-by-step migration without a major refactor.
Why vendor lock-in becomes a problem
Dependence on a single provider rarely feels like a problem at the start. The team quickly connects one model, builds an integration for one API, and launches the first use case. The risk appears later, when that choice becomes the only path for the whole service.
The most obvious failure is provider downtime. If there is only one route, any slowdown hits the product immediately: the chat stops responding, ticket classification freezes, and the internal assistant starts returning errors. Users do not separate “the model broke” from “your service broke.”
There is also a quieter risk. You lose most of your control over pricing, quotas, and limits. The provider raises rates, tightens rate limits, or changes model availability by region, and the team gets extra costs, request queues, and an unpleasant conversation with the business about why the budget suddenly went up.
Being tied to one API also gets in the way when you want to move to another model. Even if it is cheaper and performs better, the code is often already tied to specific response fields, system message format, streaming output, and error handling. In the end, a simple model swap turns into urgent fixes across several services.
For banks, telecom, healthcare, and the public sector in Kazakhstan, there is another layer of constraints. Data residency, PII masking, audit logs, and a clear data path matter there. If the provider does not meet those requirements, the project slows down not because of model quality, but because of compliance.
In practice, the team pays in several ways at once. It loses revenue or staff time during outages, overpays after price changes, spends weeks on fixes instead of a quick model swap, and delays launch because of security and legal requirements. While everything is working, this is almost invisible. When conditions change, there is no backup exit.
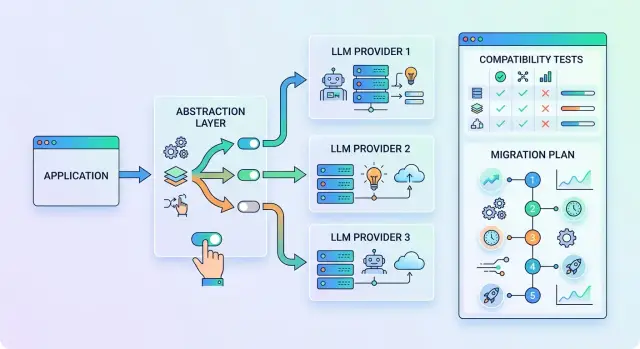
What to move into the abstraction layer
If code in ten places knows how to call a specific provider, dependence quickly becomes an architecture problem. It is better to fix that not with a large refactor, but with a thin layer between the application and the model API.
Inside this layer, you need one request format. The application does not send a “call to OpenAI” or a “call to Anthropic,” but a normal object with clear fields: model alias, array of messages, temperature, token limit, timeout, response mode, and system tags. Then the adapter translates that format into the requirements of the specific API.
Messages are also better off in a shared format. Usually, roles like system, user, assistant, and tool are enough, plus one way to pass attachments and system context. Then prompts and business logic live in one place, while provider differences do not spread through the product.
Errors should not stay “native” to each API either. For the application, the difference between a 429 from one provider and a custom rate-limit code from another means very little. It is much more useful to define a shared set of statuses: timeout, limit exceeded, authorization error, upstream unavailable, context too long, invalid request. Then retries, fallback, and alerts behave predictably.
Model selection should happen through config, not through if statements in code. A simple sign of a healthy integration is this: the team changes the model alias or base_url, and the scenario keeps working. If the input is OpenAI-compatible, the layer becomes even thinner, because the application continues to work through the same SDK and the same call format.
Normalize observability separately. A minimal set of fields usually looks like this: request_id for tracing, model alias and real provider, latency and retry count, input and output tokens, final response status. That is enough to compare routes by cost, speed, and stability. A good abstraction layer should not be large. Its job is simple: format requests, responses, errors, and logs in the same way.
What not to touch in the first iteration
The first migration rarely fails because of the model itself. More often the team makes the work too big: it changes prompts, adjusts the interface, and reshapes internal services. In the end, the project gets stuck between “almost done” and “we just need to polish a little more.”
In the first pass, the goal is simpler: separate the model provider from the rest of the product and check that the replacement happens without surprises. If you already have a chat, knowledge base search, or reply generation for operators, treat that as a stable part of the system.
So do not touch things that are not needed for the migration itself. Do not rewrite the business logic around the LLM in the same sprint. Do not change working prompts if they already give acceptable results. Do not break the response format if other services expect a specific JSON. And do not pull the user into your compatibility check: keep the screen, buttons, and flows as they are.
This approach makes API compatibility tests much easier. You are changing one layer, not five at once. Errors become visible faster: somewhere the response schema is different, somewhere token counting works differently, somewhere the model is stricter about the system prompt.
First, make the old and new routes behave the same. Quality, cost, and speed are easier to improve after that. Otherwise, the migration quickly turns into a full redesign of the system.
How to test compatibility before moving
Before switching traffic, collect not demo prompts, but 20–30 real requests from production. You need different cases: a short answer, a long answer, strict JSON, a tool call, an empty result, a model refusal, and streaming output. These requests reveal the places where the code silently depends on the old provider.
Then define what counts as a normal response. Do not judge only the text by eye. For each request, save the input parameters and a few simple expectations: the response can be parsed, the required fields are present, types did not break, the tool name matches, the arguments did not lose required values, and the stop reason does not break your logic.
What to compare
Usually five checks are enough:
- JSON stays valid and passes your schema.
- Tool calls arrive in the same format.
- Stop reason does not change application behavior.
- Timeouts stay within your limit.
- Retries and limits do not create duplicates or errors.
After that, run the same set of requests through the old and new routes. Look not only at the meaning of the answer, but also at the protocol. One provider may return “stop,” another “length” or “tool_calls.” If your code expects only one value, the migration may look fine on paper and then fall apart in production.
The same is true for JSON. The model may keep the meaning but change the structure: a string becomes an array, an empty field turns into null, and function arguments move into a different object. For a person, that is a small detail. For a parser, it is a crash waiting to happen.
Also check the load-related details that are often missed: timeouts, 429s, retries, streaming output, context size, and behavior during a burst of parallel requests. An OpenAI-compatible endpoint reduces the amount of work, but it does not guarantee byte-for-byte identical behavior.
A good test ends not with “looks like it works,” but with a table of differences. That makes it clear what can be accepted right away, what needs to be fixed in the abstraction layer, and where it is better to keep the old route for now.
Step-by-step migration order
The most common mistake is switching vendors across the whole application at once. That creates risk even though the goal is the opposite. It is easier to go step by step and change only the entry point to the model.
First, move the LLM call into one module. It does not matter much whether it is a class, a package, or a small service. What matters is that all parts of the product go through one interface instead of calling the SDK directly in five places.
Then move the API address, model name, access token, timeouts, and retry count into config. That way, switching does not require business logic changes. If the new provider offers an OpenAI-compatible endpoint, the transition often comes down to changing the base_url, model, and secret.
Next, connect the second route alongside the old one. Do not remove the current path until you have numbers. The old route is your control group: it shows where the new chain behaves worse and where you can already switch.
A practical sequence usually looks like this:
- Keep the old route as the main one.
- Add the new route through config and the same interface.
- Run the same requests through both paths.
- Move 1–5% of traffic to the new path.
- Increase the share only after the metrics stay healthy.
Watch three groups of signals: errors, cost, and latency. Errors show incompatibility in parameters or response format. Cost quickly reveals hidden overspending on long prompts. Latency matters even when quality is already good: users notice an extra 800 ms right away.
When a small share of traffic goes through without surprises, move the main flow to the new route, but keep the old one as a backup for a while longer. Then rollback takes minutes, not a week.
A simple example: a chat for bank employees
A contact center agent at a bank opens an internal chat and asks: which documents are needed to reissue a card, how to handle a disputed transaction, and what the response time is for a customer request. The chat searches the regulations and gives a short hint so the employee does not have to flip through dozens of pages manually.
If the service talks only to one API, any slowdown from the provider immediately hits the call queue. The agent waits longer, the customer stays on hold, and the contact center loses time on every request.
To remove that risk, the team does not rewrite the whole product. It adds an abstraction layer between the application and the model: one method for chat, one response format, and a separate config for the route. The operator interface, regulations search, system prompt, and dialogue logic barely change.
After that, the model can be switched through config. Today the main route goes to one provider, tomorrow to another. If the integration is already built around an OpenAI-compatible input, often all that is needed is a new base_url and model name, while the SDK and existing code stay the same.
If the main model fails, traffic moves to the backup route according to a simple rule. For example, the service waits 4 seconds for a response. If it gets a 5xx, a timeout, or an empty JSON, it repeats the request on the backup model. Most of the time the operator does not even notice the switch, because the interface does not change.
Before the full launch, the team checks compatibility on real employee questions: common policy questions, long conversations with clarifications, cases with strict JSON for the CRM, and requests in Russian and Kazakh. If the new route preserves the response format, does not break the prompts, and fits the required latency, the migration goes smoothly.
Where teams most often go wrong
Most problems start before migration, when the code becomes too tightly coupled to one provider’s API. Business rules, model parameters, and response parsing end up in the same place. That kind of setup is convenient only until the first provider switch.
The second common mistake is testing one successful scenario and assuming everything is ready. The request “answer the user’s question” passes, and the team relaxes. But failures usually hide elsewhere: an empty tool call, a long context, a truncated JSON, a timeout on the second retry, an unexpected limit refusal.
Another mistake is looking only at the price per token. In practice, budgets are broken not only by rates, but also by quotas, rate limits, long prompts, daily peaks, and the backup route. A pilot may look cheap, but after launch the request queue and retry count quickly eat up the savings.
The riskiest move is switching all traffic in one day. It is much calmer to move a small share of requests first, compare responses, cost, and latency, and then expand the flow. The plan is boring, but it is the one that usually works.
Before launch, check the basics too. One client should handle all model calls. The API address and model name should change through config. Logs should show request_id, model, tokens, request cost, error type, and retry reason. Rollback to the old route should not just exist on paper; it should be tested manually once in staging.
What to do next
Do not stretch the transition over a quarter. Pick one clear scenario and run it in a week. The best choice is a low-risk flow: internal knowledge base search, email summarization, or a draft reply for an operator. That way the team quickly sees where the real vendor lock-in is and where a config change is enough.
Start with read-only flows, where the model only answers a request and does not change anything in external systems. Then add writing: generating text that goes to the user or is saved in the CRM. Leave tool calls and agent chains for the end. That is where hidden differences between providers most often appear: tool call format, limits, timeouts, and error handling.
A simple plan looks like this:
- Choose one scenario and define the set of inputs and expected results.
- Run that set through two providers with the same prompts, temperature, and limits.
- Compare answer quality, latency, JSON format, response length, and error rate.
- Move a small share of traffic to the new provider and review the real logs.
If you need one OpenAI-compatible entry point without changing the SDK and prompts, you can look at AI Router for the pilot. It works as a single API gateway to different models, and for teams in Kazakhstan it also covers practical needs like data residency, PII masking, audit logs, and monthly B2B invoicing in tenge.
The idea of the migration is simple: first get your choice back, and only then improve quality, cost, and speed. In that order, the transition stays manageable and does not turn into a large refactor.
Frequently asked questions
Why is dependence on a single LLM provider actually risky?
Because one outage can hit the entire service at once. If the provider times out, raises prices, or tightens limits, you do not have a simple backup path, and the team has to fight the fire in the middle of regular work.
What should be moved into the abstraction layer first?
Put in a single request format, a shared error format, and route config. The application should send a model alias, messages, temperature, token limit, timeout, and the adapter will translate that into the API of the needed provider.
Should prompts be rewritten during the first migration?
No, it is better not to do that in the first iteration. First separate the model provider from the rest of the code and make sure the old and new routes behave almost the same.
How do you know the code is too tied to one vendor?
Look for a simple sign: if changing the model requires edits in several services, the integration is already too tightly coupled. Another signal is when the code expects specific response fields, stop reasons, or tool call formats from only one API.
How can you check compatibility before switching traffic?
Take 20–30 real requests from the live workflow, not polished demo examples. Then run them through the old and new routes and compare not only the meaning of the answer, but also the JSON, tool calls, stop reason, timeouts, and errors.
What requests should be included in the test set?
Use different cases: short and long answers, strict JSON, tool calls, empty results, streaming output, and limit errors. This kind of set quickly reveals hidden dependencies on the old provider.
How can you move to another provider without high risk?
First build one module for all model calls and move the base_url, model, token, and timeouts into config. Then add the new route next to the old one, give it 1–5% of traffic, and increase the share only after the metrics look good.
What metrics and logs do you need for this kind of migration?
Watch errors, latency, tokens, retry count, and request cost. In logs, keep the request_id, model alias, real provider, and final status so the team can quickly see where the route breaks or becomes more expensive.
How do you set up a fallback to a backup model?
Set a simple switching rule. For example, if the main route returns a 5xx, timeout, or empty JSON, the service immediately repeats the request on the backup model within the same interface.
When does it make sense to use a single API gateway like AI Router?
If you need one OpenAI-compatible entry point without changing the SDK and code, this is a good option for a pilot. For teams in Kazakhstan, it is especially useful when you need data residency, PII masking, audit logs, and B2B invoicing in tenge, as with AI Router.