External LLM provider outage: a day-of action plan
External LLM provider outage: a step-by-step day-of guide for switching routing, adding limits, simplifying features, and coordinating teams.
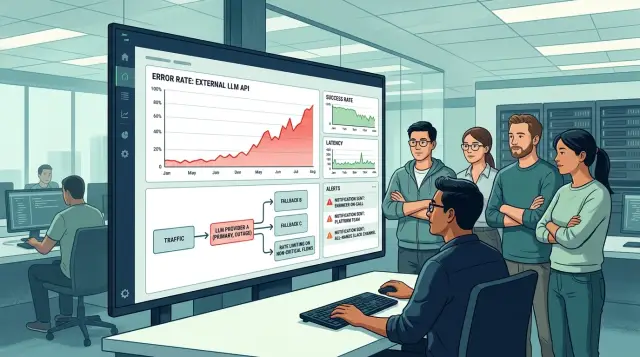
What breaks in the first minutes
The first things to fail are usually the scenarios that need an answer right away: support chat, operator suggestions, search with answer generation, and text checks before sending. The user does not see a “provider outage.” They see a button that keeps spinning too long, or an error message.
At first, asynchronous tasks create a false sense that everything is still alive. Call summaries, batch classification, nightly reports, and background agents do not stop instantly. They pile up in the queue, and after 10-20 minutes the problem reaches workers, the message broker, and connection limits.
The queue grows in several places at once: at the API entry point, in retries, in the worker pool, and in client timeouts. If the app waits 30 seconds for a response and then makes 2-3 more retries, one failed route can quickly exhaust resources, even though the app is technically still “running.”
Because of that, an external incident is easy to mistake for a bug in your own product. Errors arrive unevenly: one user gets a timeout, another gets 429, a third gets an empty response, or the text cuts off halfway through. The frontend looks at spinners, the backend hunts for a regression after release, and the cause is outside.
The provider’s status page often lags behind. Your latency and errors are already rising, while everything still looks “green” from the outside. Waiting for confirmation is dangerous: in that time, retries inflate traffic, and dependent services start failing too.
If you already have a single gateway for model routing, the first minutes are calmer: you can see that one route is failing, not the whole system. If you do not have that layer, look at your own metrics. A sharp rise in errors on one provider while the database, queues, and network are normal is already enough reason to treat it as an external incident and act immediately.
Who takes control
When an external provider goes down, the biggest problem is not the error itself but the chaos inside the team. If platform, product, and support all make decisions at the same time, time gets lost in arguments and duplicated effort.
From the first minute, you need one incident owner on duty. That person does not fix everything personally. They set priorities, record the current status, and assign the next step. If opinions differ, they have the final say.
The roles should be split within the first 10 minutes. The platform team checks errors, quotas, timeouts, and backup routes. Product decides which scenarios must be preserved at any cost and which can be temporarily reduced. Support prepares one clear message for internal teams and gathers real user cases, not rumors from chats.
You need one incident channel: one chat, one call, or one room, but not three parallel threads. All updates go there. Keep a short log there too: start time, first symptoms, and what users saw. For example: 09:12 - 5xx errors rose for one provider; 09:15 - responses are taking more than 20 seconds; 09:18 - support chat stopped answering long requests.
One owner, one channel, and a short log are usually enough to keep the first hour from being wasted on confusion.
How to understand the scale of the outage
First, build the picture from symptoms, not feelings. The same outage can look different in different places: latency may rise somewhere, timeouts may appear elsewhere, and 5xx errors may show up only on one model.
Quickly break errors into four slices: model, region or network egress zone, request type, and time in at least 5-10 minute steps. That makes it almost immediately clear whether the problem is broad or hitting a narrow spot. If one model fails for one provider, that is very different from widespread timeouts across all routes.
Then separate a provider failure from your own problems. Check three simple things: whether the API key has expired, whether a fresh release broke something, and whether there is a network incident between your environment and the external API. People often get this wrong: they blame the provider, then discover a new rate limit, a proxy, or an incorrect base_url.
Do not look only at the error rate. If median latency doubled while 5xx errors are still low, the incident has already started. For LLMs, that is a common early signal. It helps to compare timeout share, p95 and p99 latency, 5xx share, and the number of retries per successful response.
Also check which functions have already moved to the backup route and which are still on the primary provider. After 15-20 minutes, the team should have a short status: what is broken, where it is broken, who is affected, and which scenarios are already running on the fallback.
How to switch routing
During an external LLM provider outage, do not move all traffic to the first available replacement. That can easily break scenarios that are still working and burn through quotas. First reduce unnecessary load: stop batch jobs, reindexing, auto-summaries, nightly jobs, and anything the product can live without for a few hours.
Then split traffic by importance. Move critical scenarios first, where the user needs an answer right now. That is usually support chat, knowledge base search, and internal assistants for operators. Long report generation, text rewriting, and other heavy tasks are better left for later.
For each critical scenario, predefine a primary fallback model and a second fallback. Look not only at quality, but also at price, context window size, and available RPM. Start with 1-5% of live traffic on the new setup, and only then increase the switch.
While testing, do not watch only the response code. Watch response length, the number of empty or cut-off messages, JSON format stability, average latency, and odd filter triggers. A fallback model may respond “successfully” but still handle structure poorly and produce much more text than expected.
One more practical step: set temporary rules until the incident ends. Record which models are active, which fallback comes first, which limits are in effect, and who is allowed to change the routing. Otherwise, after an hour, teams will start moving traffic in different directions.
Where to apply limits
On outage day, limits should not be the same for everyone. First, reduce the things that consume many tokens and do not directly affect revenue, customer support, or daily operations. Otherwise, the system will quickly hit the queue, and useful requests will wait alongside less important ones.
The first candidate is long context. If you have chats with 30-50 messages, large attachments, long system prompts, or generation that runs to thousands of tokens, cut that back immediately. Even a simple reduction in maximum input and output size often removes a noticeable share of the load within the first 10-15 minutes.
Concurrency is also better reduced selectively. Internal assistants, call analysis, email drafts, and other non-urgent scenarios can run slower. But payment checks, support, antifraud, and operational flows should get their own bandwidth reserve.
Usually four measures are enough. Lower max input tokens and max output tokens for non-critical routes. Reduce the number of simultaneous requests for internal services and background tasks. Move analytics and data re-enrichment into a queue. And make sure to set a hard rate limit on each API key so one looping worker does not take down the whole system.
The last point is underestimated most often. A retry bug or one bad worker can create a spike on a single key in a couple of minutes and consume the entire available volume. Separate limits by key, a simple quota, and a circuit breaker are more useful on a day like this than a single global limit for the whole cluster.
Which functions to reduce
During an incident, do not try to keep the whole product exactly as it was. That almost always hurts latency, cost, and stability at the same time. A better approach works faster: keep only the scenarios where the answer affects money, a request, an order, or the customer response time.
First, remove everything the user can still finish without. Regenerations, “try again” buttons, alternative response versions, and automatic paraphrasing eat a lot of requests and rarely save the day. In normal times they are nice. During an outage, they are a luxury.
Old conversations should be touched early too. If the service compresses long history through background summarization, turn it off temporarily. It is much cheaper to keep only the last few messages and work with a short context than to spend limits maintaining long threads that nobody reads all the way through.
Keep the LLM where you truly need free-text understanding. FAQ handling, order status, form-field checks, and routing tickets by tags can often be moved back to rules, search, and the app’s regular logic for one day.
In support chat, ask the model to answer more briefly. You do not need a long, friendly 2,000-character message. You need the status, the next step, and a list of what should be attached. Often a 300-400 character answer solves the task better and reduces load faster.
How to communicate with teams without noise
On outage day, the worst thing after the failure itself is a flood of conflicting messages. One person writes that “everything is down.” Another says the problem is only affecting some customers. A third is already promising recovery in 15 minutes. That wastes time and gets teams arguing instead of working.
The first message should be short and precise. Name the products affected and the business risk. For example: support chat is down, answers in the internal assistant are delayed, batch jobs are paused, risk is high for customer-facing scenarios and medium for internal ones.
Then give one clear status: what broke, what the team has already done, what it is checking now, and when the next update will come. That is enough for the first touchpoint. If traffic has already moved to a fallback route, limits have been lowered, and expensive functions are disabled, say that directly. People need facts, not long explanations.
A good update rhythm cuts noise better than any long report. Set a specific time for the next update, even if there is little news yet: in 15 minutes, at 12:30, after checking the request queue. Then engineers will not be pinged every two minutes in private chats.
Warn support and account teams separately. They do not need a technical breakdown. They need working text for customers: what is unavailable, who is affected, whether there is a workaround, and what should not be promised. If chat is slower but not fully unavailable, they should say exactly that.
When it comes to timing, be blunt. Do not write “we’ll fix it in 15 minutes” if that is only a guess. It is better to write “next update at 12:30.”
Example: support chat on outage day
A customer writes to a bank’s chat: “My payment is not going through, what should I do?” Normally the bot replies in 4-6 seconds, but now the pause stretches to 20. For the user, that is already an outage, even if the system has not fully gone down.
The team does not wait for a full stop. It immediately moves the flow to a backup model and splits requests by complexity. Simple things like application status, limits, business hours, and password resets stay with the bot. Complex cases that need a longer reasoning chain or precise context handling move to the second route.
To reduce load, the bot changes its response mode. It writes more briefly, adds no extra personalization, and does not offer optional suggestions at the end. If the answer used to take 8-10 sentences, now it is 3-4 short phrases and one action for the customer. This often saves tokens and clears the queue within the first few minutes.
Support agents also get a simple manual handoff template. It includes just four things: acknowledge the delay without a long explanation, give one next step, name the time of the next response, and hand the conversation to a human if the bot makes the same mistake twice in a row.
After an hour, the picture is usually clearer. If the queue has eased, the team gradually brings functions back: first personalization, then longer answers, and only after that complex scenarios like summarizing the conversation history. That is safer than turning everything back on at once and hitting the limits again.
Common mistakes on a day like this
Most of the time, the team loses time not because of the outage itself, but because of sudden moves. The most expensive mistake is sending all traffic to one backup provider and assuming the issue is solved. Ten to twenty minutes later, you get the same problem in a different place: the queue grows, responses get more expensive, and some functions behave unpredictably.
The second mistake is keeping the old limits when latency has already risen. If the system handled 50 requests per second before the outage, that does not mean it can handle the same volume after switching. When response time triples, the old limits only finish off the service.
The third mistake is changing the route and the prompt in the same release. If answer quality drops, you will no longer know the cause: the new provider, a different system prompt, or reduced context. On an incident day, change one thing at a time. First the route, then the limits, and only after that the prompt text if you absolutely must.
Another common issue is forgetting about background processes. Nightly batch jobs, eval runs, automated tests, and analyst sandboxes consume the same request budget as production. They need to be slowed down quickly, otherwise production competes for resources with work that can safely wait until tomorrow.
And finally, silence. The business does not need a full forensic report just to learn there is a problem. Within 15 minutes, it needs a short status: what is affected, what still works in a reduced mode, and when the next update will come.
Short checklist for outage day
- First check the source of the error: is it 5xx, timeouts, 429, rising latency, or a failure in only one region.
- Assign one owner and one channel for updates.
- Move critical traffic to a fallback route, and pause secondary tasks.
- Lower limits, shorten long responses, and disable expensive features.
- Set the time for the next status update immediately, even if there is little news yet.
By the end of the first hour, the team should already have clear answers to four questions: what broke, how much traffic was saved, where the limits are, and who gives the next update.
What to do after the incident
It is better to review a day like this with numbers, not impressions. Gather three sets of data: how many requests failed, how much latency increased, and where the business actually lost money, requests, or users. If support chat was 40 seconds slower and the error rate rose from 1% to 12%, that is already material for decisions, not a vague statement like “everything was slow.”
Then review the routing rules. Often the outage shows that the setup was fragile: one provider took too much traffic, the backup route kicked in too late, and the limits did not hold back the spike. Fix the failover thresholds, the share of traffic on the backup, and the restrictions by team, function, or request type.
It is useful to run the same scenario in staging: manually disable the primary provider, check failover time, error growth, queue health, and budget usage. If the test still breaks the system, the plan is still rough. A healthy outage scenario should be boring: traffic moves to the backup route, some functions are disabled by rules, and teams get clear signals.
And there is one more conclusion that is better made in advance, not in the middle of the next outage. If you need one layer for routing, fallbacks, per-key limits, and hosting models locally in the country, that is something to decide before the next incident. For teams in Kazakhstan, that layer can be AI Router: one OpenAI-compatible endpoint, routing between providers, and your own models on local GPU infrastructure. But even with a tool like that, incidents do not disappear on their own - discipline, metrics, and simple rules matter more than any convenient dashboard.
Frequently asked questions
How can we tell quickly whether the problem is with the provider or with us?
Look at your own metrics, not the status page. If timeouts, 5xx errors, and p95 latency suddenly rise for one provider while your database, network, and queues stay normal, treat it as an external incident and start failover.
Check three things on your side right away: whether the API key has expired, whether a fresh release broke something, and whether the network path to the external API is healthy. These checks take minutes and often remove a false alarm.
What should we do in the first 10 minutes after an outage?
First, stop everything the product can live without for a few hours: batch jobs, nightly jobs, auto-summaries, and reindexing. Then assign one incident owner, open one communication channel, and record the first status with the time and symptoms.
Do not wait for official confirmation from the provider. While you wait, retries and long timeouts will fill up the queue.
Who should make decisions during the incident?
One incident owner. That person makes the hard calls, sets the next step, and keeps teams from pulling traffic in different directions.
The platform team checks errors and routes, the product team decides what must stay up, and support prepares one message for internal teams and customers.
Which traffic should move to the backup first?
First, move the scenarios where the user needs an answer right now. That is usually support chat, an operator assistant, and search with answer generation.
Heavy and non-urgent tasks should be paused. Long reports, text rewriting, and background analysis can wait until things stabilize.
Should we move all traffic to the backup model right away?
No, moving all traffic at once is risky. You can overload the fallback route, burn through quotas, and create a new queue with the second provider.
Start with 1-5% of live traffic, check latency, response format, and text length, then increase the share. That way you catch issues before they affect everyone.
Where is the best place to introduce limits on outage day?
Start by reducing long context and long output for non-urgent scenarios. That quickly cuts load and barely affects the product.
Then lower concurrency for internal services and background jobs. Put a hard rate limit on each API key so one stuck worker cannot consume all available capacity.
Which features can be temporarily reduced without much harm?
Disable anything the user can still live without to finish the task. Repeated generations, alternative answers, extra personalization, and background history summarization usually cost a lot and help very little on an outage day.
Wherever possible, fall back to rules and the app's regular logic. FAQ, order status, and form-field checks can often work without an LLM.
How do we inform teams and support without causing panic?
Write briefly and without guesses: what broke, who it affected, what the team has already done, and when the next status update will come. That format reduces noise better than a long explanation.
Give support a separate text for customers. They do not need a technical deep dive; they need an exact phrase: what is unavailable, where delays exist, and what can be promised right now.
What should we do if the provider's status page shows nothing?
Do not wait for it to turn green. If your metrics already show rising latency and errors, follow your plan and treat it as a real incident.
Status pages often lag behind. In those moments, your charts, event log, and backup route checks are more useful.
What should we review after the incident so the next outage is easier to handle?
Collect numbers in three areas: how many requests failed, how much latency increased, and where the business lost applications, money, or time. These numbers help you fix switching thresholds, limits, and the share of traffic on the backup.
Then repeat the same scenario manually in a staging environment. If the system still chokes, the plan is not ready yet. If you use a gateway like AI Router, check routing rules, key limits, and local model behavior too.