Timeouts in an LLM Chain: How to Split the Time Budget
Timeouts in an LLM chain affect the answer just as much as model choice. We’ll show how to split a shared SLA between the gateway, search, tools, and the model.
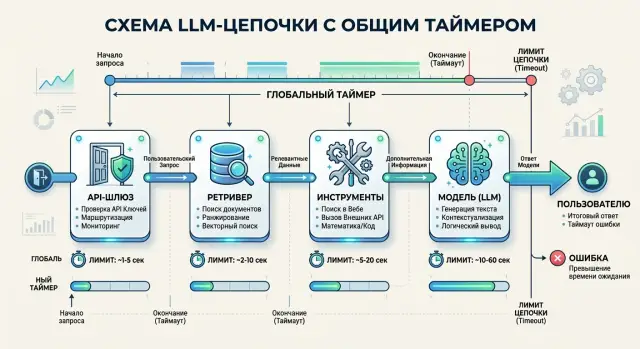
Where the overall timeout breaks
An overall timeout almost never fires at a convenient point. It cuts the chain wherever the request happens to be at that moment: at the gateway, during search, inside a tool call, or already while the model is answering. The user does not care about the difference - they see the same error either way.
The problem is that time in an LLM chain is spent unevenly. A knowledge base search can suddenly take 4 seconds instead of one, and the model is left with almost no time to generate. From the outside it looks like the model itself is slow, even though the request reached it too late.
The same thing happens with tools. One stuck HTTP call, a slow SQL query, or an external service without its own limit keeps the whole chain open. If cancellation does not propagate through every step, the system waits until the very end and then drops the response entirely.
Usually the failure looks like this: the gateway accepted the request, the retriever spent a long time looking for documents, the tool did not answer in time, and the overall limit expired before the model could finish the response.
Worst of all, the cause is often not obvious right away. The logs only show something like "request timeout" or a 504 without any step-by-step breakdown. The user is already gone, and the engineers are still arguing about who is to blame: the gateway, search, the tool, or the model.
In production this shows up especially often when the chain goes through an API gateway and several external dependencies. If the request passes through the gateway, then the retriever, and then the model, the overall timeout can cut it off before a full answer is generated. Without per-step measurements, this kind of failure is easy to mistake for random instability, even though the reason is usually very simple: one stage just ate someone else's time.
What makes up latency
A time limit almost never goes only to the model's answer. While the user is waiting for text, the system is already spending milliseconds and seconds on the network, queues, data search, and calls to other services. That is why a 10-15 second limit often leaves the model only half of that in practice.
Latency usually has four parts. First the request reaches the API gateway: there is network travel, key validation, rate limits, and sometimes a short queue if traffic suddenly spikes. Then the system searches documents in a vector store, filters the results, and, if needed, sends them for reranking. After that, tools may kick in: CRM, knowledge-base search, a payment service, an internal API, an SQL query, or a calculation function. Only then does the model start generating the answer.
Even the model itself has more than one delay. There is the time to the first token and the total generation time. For the user, those are two different experiences. If the first token arrives quickly, the wait feels normal. If the screen stays silent for several seconds, the service already looks broken.
In practice, the long tail hurts more than the average latency. One slow internal service can easily eat 2-3 seconds. Reranking a large document set adds another second. If the model then takes a while to produce the first token, the user sees silence even though the system is technically still alive.
A simple example: a bank chat assistant got a 12-second limit. About 500 ms went to the gateway and the network, 1.8 seconds to search and reranking, another 2.2 seconds to checking customer status in an internal service. The model was left with less than 8 seconds, and that is before any buffer for retries or canceling a stuck step.
If you work through a single gateway like AI Router, the picture does not change. One OpenAI-compatible endpoint makes integration simpler, but the latency budget still has to be calculated step by step. Otherwise, the overall timeout looks generous only on paper.
It helps to watch at least three markers: when the request hit the gateway, when the system received the context, and when the model returned the first token. These points usually make it immediately clear where time is going.
How to choose the overall time limit
It is better to start not with the model, but with how patient the user is. In chat, people wait the least. If the screen stays silent for 2-3 seconds, the service already feels stuck. If the first token arrives quickly, the same user will happily keep reading for another 5-8 seconds.
That is why the limit is better split into two parts: time to the first token and time to the full answer. For the interface, the first number matters more. For the backend and SLA, both matter, because a long tail hurts the experience just as much as a slow start.
You can set starting ranges by scenario type:
- chat: 1.5-2.5 seconds to the first token and 8-12 seconds for the full answer;
- search with RAG: 2-4 seconds to the first token and 10-15 seconds for the full answer;
- an agent scenario with tools: 3-5 seconds to the first token or a fast interim status, and 20-40 seconds for the full cycle.
Do not give the entire budget to the model and retriever. Leave room for the network, request cancellation, logging, and gateway tails. If you have PII masking, audit logs, or routing through a shared API gateway, a 10-20% reserve often saves you from false timeouts.
A working rule is simple: first take the limit a person would consider acceptable, then subtract operational overhead, and divide the rest among the chain steps. For example, if the support team wants answers within 12 seconds, you can reserve about 1 second for network and service operations, keep a separate target of 2 seconds to the first token, and give the rest to search, tools, and generation.
And do not try to live with one limit for all routes. A short FAQ, knowledge-base search, and an agent that talks to CRM all work by different rules. One shared ceiling for everything usually hurts either speed or answer quality.
How to split the budget across steps
First, define the SLA for a single request. Not the average time, but the point after which the answer is no longer useful. If chat must answer in 8 seconds, that is the number you should use to calculate the budget.
Then break the request path into separate stages. Most often that means an API gateway, a retriever, external tools, and the model. Sometimes post-processing, policy checks, or logging are added too. Until these parts are visible separately, timeouts are usually set by guesswork.
Every step should have a hard limit. That is the time after which the stage stops without discussion. A soft threshold is also useful: if the step has not hit the hard timeout yet but has already gone outside the normal window, the system can switch to a fallback.
For a total limit of 8 seconds, the split might look like this:
- gateway and routing - up to 300 ms;
- retriever - up to 1.2 seconds;
- one external tool - up to 1.5 seconds;
- model - up to 4.2 seconds;
- reserve for network, serialization, and unexpected delays - about 800 ms.
The soft threshold is especially useful where there is a fallback. If the retriever has not finished within 700 ms, you can return an answer without part of the context. If a tool is slower than 1 second, you can show a draft answer and note that the data is incomplete. Users are usually more forgiving of a slightly less precise answer than of a blank screen.
There is another simple check: the sum of all step limits should be less than the overall timeout, not equal to it. Otherwise, any network spike will break the whole request. In production, a 10-15% buffer is normal hygiene, not overcaution.
If you route models and traffic through a shared gateway, it is convenient to keep this budget next to the routing rules and rate limits. That way the whole chain follows the same rules instead of separate settings in different places.
How to configure the retriever and tools
Retrievers and external tools usually break the answer not because of one big outage, but because of small delays. Search runs 400 ms slower than usual, CRM answers on the third try, the pricing calculator waits in a queue, and the model already has too little time left for the final answer.
Search is best kept short and predictable. If the database usually needs only 3-5 fragments, there is no reason to ask for top-k=20 just in case. Extra documents rarely make the answer smarter. They do increase latency and add noise to the context.
The basic rules here are boring, but they work: set a hard time limit for the retriever, keep top-k to a number that actually helps, give each tool its own timeout, and after the deadline return a partial result or skip the step.
One shared timeout for all calls almost always ends badly. For knowledge-base search it might be 150-300 ms, for CRM or billing 500-800 ms, for a rare external API a bit more if the answer loses meaning without it.
Not all tools are equally important. Split them into required and nice-to-have. If the support assistant has already found the right article and sees the order number in the message, there is no reason to wait for two more slow calls just to repeat the same data.
Extra requests are better canceled as soon as the answer can already be assembled. If one tool has provided enough facts, the orchestrator should stop the other calls instead of waiting for them "for completeness." This is especially noticeable in systems where the path to the model is fast, but slow tools before it ruin the overall response.
You also need a clear fallback. If the retriever did not make it in time, the model can answer without search and honestly say that the exact data was not loaded. That is much better than silence after 12 seconds.
What to give the model
The model should not eat the whole budget. First subtract the time for the gateway, retriever, and tools, then give the model the remainder plus a small buffer for canceling the request and returning a clean error. If the total limit is 8 seconds, the model often gets 4-5 seconds, not all 8.
Measure the time to the first token and the time to the end of the answer separately. For the user, these are different things. It is one thing to see the first token after 700 ms and then calmly read a long answer. It is quite another to stare at a blank screen for 5 seconds. A rise in time to the first token often points to an overloaded model, queueing at the provider, or a prompt that is too heavy.
Before calling the model, it is useful to cap max_tokens strictly. That is the easiest way not to burn the budget on a task that only needs a short answer. A classification may need 20-50 tokens, a short summary 120-200, and a long draft email needs a different budget altogether. If you do not set a ceiling in advance, the model can easily become wordy and steal extra seconds.
It is also worth splitting requests by complexity. Simple tasks should go straight to a faster model, while the slower one should be reserved for cases where it is truly needed.
- Field extraction, labels, and short answers - a fast model and a small token limit.
- Answers with multiple sources or complex verification - a stronger model and a slightly larger budget.
- Long text for a person - streaming enabled so the user sees the beginning of the answer immediately.
- A long queue or a slow first token - a fallback route to another model or another provider.
Streaming is especially useful when the final answer is long. It does not make generation itself faster, but it greatly improves the feeling of speed. For chat, it is almost always a good choice.
The fallback route should be prepared in advance, not after an incident. If time to the first token exceeds your threshold, the request can be switched to a faster model with slightly simpler answer quality. In AI Router, this is convenient to do through the same OpenAI-compatible endpoint without changing the SDK, code, or prompts.
And one more rule that is often missed: look not at the model's average latency, but at the worst 5-10% of requests. Those are the ones that break the SLA most often.
Example with a real scenario
Imagine a bank chatbot. A customer asks: "Where is my credit card application?" The bot cannot just call the model and wait as long as it takes. First it searches for an answer in the knowledge base, then it tries to check the application status through an internal service, and only after that does it assemble the final response.
The team gave the whole request 8 seconds. That is no longer an abstract number, but a hard budget that needs to be divided across the steps so the answer arrives on time even with bad network conditions.
One workable split might look like this:
- 300 ms goes to the API gateway for request intake, key check, routing, and trace start;
- 1.2 seconds goes to the knowledge-base search;
- 2 seconds goes to the tool that checks the application system;
- 4 seconds remains for the model to build the answer;
- 500 ms is kept as a reserve for canceling a stuck step, network spikes, and sending the result to the customer.
The point of such a budget is that every step knows its own limit. If search does not finish in 1.2 seconds, the bot does not wait longer and follows a shortened path. If the status service hangs for more than 2 seconds, the system cancels the call and does not waste another couple of seconds.
What this looks like in the answer
Suppose the search found an article about application review times, but the status service did not respond. Then the bot does not write vague text. It honestly states the usual review time, explains where the customer can see the status update, and suggests trying again later.
That is better than keeping the user waiting for all 8 seconds and then returning an error. In banking, this compromise usually wins: the person gets a useful answer right away, even without the exact status at that moment.
The 500 ms reserve is not a luxury here. Without it, a nice spreadsheet calculation breaks in production. Canceling the tool, closing the connection, and sending the text to the customer all take time. If you do not build in a buffer, the SLA starts to drift even when the rest of the system is working normally.
What to look at in logs and metrics
Average response time almost always gives false reassurance. The same request may finish in 2 seconds in half of the cases, but every hundredth one hits the deadline and breaks the whole flow. That is why you should not look only at total time, but at the latency tails: p50, p95, and p99 separately for the gateway, retriever, tools, and model.
If p95 for search looks fine but p99 suddenly grows, you already know where the budget is disappearing. The same goes for the model: it may have a good median response, but rare long generations will eat the entire limit and trigger cancellation at the gateway level.
A single trace id helps connect all the steps. Without it, logs look like noise: one model call, one search call, one gateway timeout. With a trace id, you can see the full chain for a specific request and easily understand where it started slowing down and who first used up their limit.
For request logging, a few fields are usually enough:
- a trace id for the whole chain;
- the step name and its duration in milliseconds;
- the stop reason: success, timeout, error, or retry;
- the overall deadline and remaining time before each step;
- who canceled the request: the user or the system by deadline.
It is better to write the timeout reason clearly at each stage. An entry like "request timeout" is almost useless. It is much more helpful to see something like "retriever timeout after 180 ms" or "model canceled because 320 ms remained and tool used 900 ms".
Cancellations should also be separated. The user closed the chat, the network dropped, the frontend canceled the request, the gateway stopped the chain by deadline - these are different events, and they need different fixes. Logs often mix them together, and then the team spends days chasing the wrong problem.
A mature system looks simple: by one trace id you understand the request path, the remaining budget at each step, and the exact cause of failure within a minute.
Common mistakes
Most often the problem is not the model, but the rules around it. The team sets the same limit for the gateway, retriever, tools, and the model call itself, then wonders why the request sometimes lives longer than the overall deadline. If every step gets its own 10 seconds, the whole chain can easily stretch to 20-30.
The same mistake shows up with retries. A retry is fine on its own, but it should respect the remaining time. If the first retriever call already used 700 ms out of a 1-second limit, a second run with the same 700 ms is almost always pointless. It does not save the answer - it only pushes the SLA over the edge and keeps resources busy.
Parallel tools make the picture even worse. On a diagram everything looks fast: three calls run at the same time. In reality, one tool hangs, another returns with a long tail, and the orchestrator waits longer than it can afford. Parallel branches need a shared deadline, not just separate timeouts for each call.
A fallback mistake usually looks like this: the main model is kept alive almost until the end, and the backup is only started when there is no time left. In the end the system makes two expensive calls and still does not finish in time. The fallback needs to kick in earlier, while the backup path still has a chance to return a full answer.
There is also a quiet but expensive problem: the client request is already closed, but the backend keeps working. The gateway, tools, and model continue running even though there is no one left to send the answer to. For an OpenAI-compatible API gateway, that is especially painful: tokens, GPU time, and quotas are spent on work nobody will ever see.
The rule is straightforward: every step should know not its own maximum timeout, but the remaining shared budget. And once the client cancels the request, the whole chain must stop immediately.
Quick pre-launch check
Before release, it is useful to do a short check with numbers, not feelings. Failures often happen not because of one very slow step, but because of a small overspend at each stage.
First, check the math. If the total response limit is 12 seconds, the sum of the gateway, retriever, tools, and model limits should be less than that number. Leave at least 5-10% for network spikes, retries, and response serialization. If you have allocated all 12 seconds with nothing left, the system is already living on the edge.
Then check diagnostics. Each stage should have its own error code so the team can immediately see where the chain hit the limit. One generic "timeout" is almost useless.
The minimum set looks like this:
- the gateway returns its own timeout code;
- the retriever returns a separate code;
- each tool marks its timeout separately;
- the model has its own limit-exceeded code;
- the orchestrator logs which step the request stopped at.
After that, run three simple tests with artificial delay. Slow down search on its own and check whether the chain stays within the limit and whether the team gets a clear error. Then test a slow tool the same way. Then slow down the model separately and make sure the system does not wait longer than allowed.
It is worth asking yourself two questions. Will the on-call engineer see the cause within 30 seconds? Will the product still give the user a clear answer if one step hangs? If the answer to either is "no," it is better to delay launch by a day and clean up the setup.
What to do next
Do not try to rebuild all timeouts at once. Pick one working chain where latency is already noticeable: for example, knowledge-base search with one model call and one external tool. On a route like that, it is easier to see who is eating time and where requests are being cut off too early.
Next, collect real measurements. Do not set limits by eye. Look at p50, p95, and the share of timeouts for each step: gateway, retriever, tool, model. If the retriever usually answers in 120 ms but sometimes in 900 ms, that is already enough to build a sensible budget.
Then you can move forward with a short plan:
- choose one chain with a clear scenario;
- collect step-by-step measurements over several days;
- set limits with a small buffer;
- check where cancellation happens and who fails to finish;
- review the numbers against live traffic after a week.
A week of real traffic often changes the picture. In tests, the model may fit the limit almost every time, but in production you may find that the search tool sometimes slows down and that long prompts shift the whole budget. After that check, it usually becomes clear what should be tightened and what should still keep a buffer.
If the team needs to quickly compare limits across different models and providers, it is convenient to test them through the same interface. For that, you can use airouter.kz: it lets you change only the base_url to api.airouter.kz and run the same SDK, code, and prompts through one OpenAI-compatible endpoint. This is useful when you want to compare not theory, but how the chain behaves under the same load.
The point of all this tuning is quite practical. Timeouts should not just stop requests - they should protect the answer from unnecessary waiting. If each step knows its limit, can cancel itself, and leaves time for the next stage, the chain starts behaving predictably. And in production, that is worth more than any pretty diagram.
Frequently asked questions
Why is one shared timeout not enough?
Because it cuts the chain at a random point and explains almost nothing. The user sees one error, while the team later has to guess who ate the time: the gateway, search, a tool, or the model.
It is much better to give each step its own limit and watch the remaining budget before the next call. Then the failure is obvious right away, and the system does not wait until the last second for nothing.
Where should you start when setting up timeouts in an LLM chain?
Start not with the model, but with what a person expects. If the screen stays silent for more than 2–3 seconds in chat, the service already feels broken, even if the full answer would arrive later.
First choose an acceptable time to the first token and a full response limit, then subtract network, operational overhead, and a buffer. Only then split the rest between search, tools, and the model.
What limits are a good starting point for chat?
For a normal chat, you can start with a target of 1.5–2.5 seconds to the first token and 8–12 seconds for the full response. That is usually enough for the interface not to feel frozen and for the model to have time to finish the thought.
Then adjust the numbers using live traffic. If the first token arrives too late, shorten the prompt, speed up the route, or turn on streaming.
How do you split the total time budget across steps?
Take the total SLA and split it from the top down. If the whole request must finish in 8 seconds, first assign time to the gateway, search, tools, and only then the model.
A practical setup looks simple: a short limit for the gateway, a separate limit for the retriever, a separate limit for each external call, and the remainder for generation. The sum should stay below the overall deadline, or any network spike will break the response.
Do you need to leave extra time?
Yes, without a buffer the math only works on paper. Canceling the request, serializing the response, network spikes, and writing logs all take time.
Usually a reserve of 10–15% is enough, and if you have audit logs, PII masking, or an extra network hop through a gateway, it is better to keep 10–20%. This buffer often saves you from false timeouts.
What if the retriever takes too much time?
First, reduce the search itself. If you usually need only 3–5 snippets, do not pull top-k=20 just to be safe: it adds latency and noise to the context.
Then give the retriever a hard limit and a soft threshold. If search does not fit into the normal window, it is better to return an answer with incomplete context than to lose the entire request.
How should you set timeouts for external tools?
Do not use one timeout for every tool. CRM, billing, SQL, and external HTTP services behave differently, so their limits should be different too.
Split tools into required and optional. If the answer loses meaning without a call, give it a little more time. If the tool only adds details, cancel it earlier and build the answer without it.
When should you switch to a fallback model?
Do not wait until the very end. If time to the first token has already crossed your threshold, or the provider is clearly slow, switch routes earlier while the backup model still has a chance to return a proper answer.
It is best to prepare this transition ahead of time. For simple tasks, keep a fast route ready from the start and leave the stronger, slower model for complex requests only.
What should be logged to quickly find the source of a timeout?
Log the duration of each step, the overall deadline, the remaining time before the next call, and the exact stop reason. An entry like request timeout is almost useless because it explains nothing.
One trace id makes debugging much easier. With it, you can quickly see where the request started slowing down and who first used up their limit.
What should you verify before releasing this setup?
Check the math first, then break the chain on purpose. The sum of the step limits should be smaller than the overall deadline, and each stage should have its own error code.
After that, artificially slow down the search, the tool, and the model one by one. If the system stops each step in time, returns a clear error or a partial answer, and does not keep working after the client cancels, the setup is ready to ship.