Source citations in assistant answers: how to build them
Source citations in assistant answers help verify conclusions. Here we explain how to gather quotes by document, not by random text snippets.
What is the problem with random citations
When an assistant says "according to the document" and then inserts a piece of text with no clear connection to the conclusion, that does not look like proof. The user sees matching words, but does not understand why the answer follows from that exact place. That is why randomly chosen citations quickly lose their meaning.
A document is almost always more complex than a single sentence. One section contains a general rule, another contains an exception, and the appendix contains a deadline that changes the interpretation. If the model pulls out a fragment based on similar words rather than meaning, the answer may look neat but still be wrong in substance.
This is especially obvious in contracts. The text may say that payment is due within 10 days after acceptance of the goods. The assistant finds a similar phrase about 10 days after invoicing and concludes that the deadline is the same. The difference may seem small, but for an accountant, lawyer, or procurement specialist, that is already a different answer.
Even a correct overall conclusion does not always save trust. If the user opens the citation and does not see direct support for the specific statement in the answer, they begin to doubt everything else. The model may have guessed correctly, but the user does not know that. They need not a lucky result, but a verifiable path from the document to the conclusion.
Weak citations usually give themselves away with simple signs. The fragment talks about a similar topic, but not about the claim the assistant made. The citation was pulled out without the neighboring condition, exception, or date. The answer gives a precise conclusion, while the source offers only an indirect hint. Or the assistant shows several snippets at once and does not connect them to the claims.
A long list of fragments rarely helps either. When the user gets five pieces of text with no explanation, they have to reconstruct the logic themselves, check overlaps, and decide which paragraph relates to which point. That is just manual document checking, only in a more awkward form.
In RAG with citations, the mistake is often not in retrieval, but in the last step. The system finds something close, then builds an answer that is broader than the retrieved text allows. If a person has to reread the whole document to verify one sentence from the assistant, the citation did not work.
What good support from the document looks like
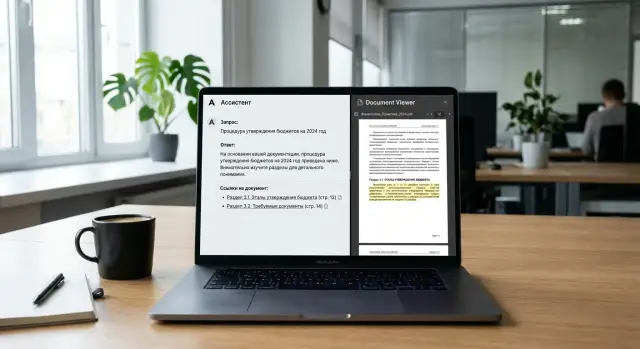
Good support from the document is simple: the assistant makes a claim, shows a short quote next to it, and immediately points to the exact place in the text. The user should not have to guess where the answer came from. They should be able to open the right page, find the paragraph, and verify the meaning in a few seconds.
A good citation does not confirm the whole answer at once. It supports each important claim separately. If the assistant says that the payment term is 30 calendar days, the citation should point to the exact clause about the payment term, not to any random page in the contract where the word "payment" appears.
A working pattern usually looks like this: one claim, one source, a short excerpt of one or two lines next to the claim, and a page, section, clause, or table row in the note or reference. If the answer has two different ideas, they should have two different sources.
This is especially important for tables. If the assistant answers about a limit, price, or date, the user should see not just a page number, but a row or a column heading. Otherwise, searching the document turns into a manual quest, and trust in the answer drops.
A bad version looks like this: at the bottom of the answer there are three long chunks of text from different pages, but it is unclear which one proves what. Formally, citations are there. In practice, they are not helpful. The person still rereads the document on their own because they do not see the link between the claim and the source.
A good version is shorter and more honest. For example: "The penalty for delay is 0.1% per day." And right below it: "clause 6.4, p. 12: 'The Supplier shall pay a penalty of 0.1% of the amount of the overdue obligation for each day of delay.'" Here it is easy to verify both the number and the context.
For checking LLM answers, that matters more than it seems. Even a strong model may correctly restate the general meaning, but make a mistake in a number, deadline, or small-print exception. A short citation next to the claim quickly catches those errors.
RAG with citations works better when the system does not dump every found fragment into the answer. It needs discipline: first the claim, then the concrete support. If the support does not fit into one clear citation with a short excerpt, then the answer is not ready yet.
What counts as a source for a citation
A source for a citation is not the whole document and not a random piece of text that search returned first. A source should be a fragment that can be shown to a person on its own, and they will understand the meaning without guessing. If the assistant cites half a page without boundaries, the user sees noise, not support.
It is better to treat different kinds of fragments as separate sources: a paragraph, a table row, a footnote, an appendix, a definition block, a contract clause. A page is also useful, but only as an address, not as a meaningful unit. One page often contains several ideas, and a citation to the whole page makes the reference vague.
Each fragment should have a stable identifier. Not a temporary index number or a search result position, but a clear ID that does not change after reindexing. For example: doc_17:p_12:sec_4.3:para_2 or contract_A:appendix_1:table_3:row_5. Then the answer, logs, and manual review all refer to the same piece.
There is also a simple rule: do not break apart a meaningful pair. If one place gives a definition and the next sentence gives a restriction, keep them together. If a table contains a rate and the note under the table contains an exception, connect those parts clearly. Otherwise, the model will take the convenient number, miss the caveat, and answer confidently but incorrectly.
Usually it is enough to keep the text of the fragment itself, the page or sheet number, the section heading, and the neighboring context before and after it. The last point is needed more often than it seems. It helps explain what a pronoun refers to, what exactly the condition limits, and whether the thought continues in the next paragraph. This is especially noticeable in contracts, policies, and PDFs with tables.
If the document is long, it helps to have two layers of sources. The first layer is a small fragment for an exact quote. The second is a parent block, for example the whole contract clause or the whole table. Then the assistant can show a short citation but still verify itself against a broader excerpt. This approach noticeably reduces the number of answers where a citation exists on paper but says nothing useful.
How to set up document search
If you want source citations to look honest, you should start not with answer generation, but with search. Bad search almost always leads to a bad citation: the model finds a random paragraph with similar words and pretends that is enough.
It is better to index a document not as plain text, but as structure. Headings, subclauses, and body text should be stored separately. Then search understands not only the words, but also where the idea sits in the document. A phrase from the section "Liability of the parties" and the same phrase from an appendix are not the same thing.
Chunks should not cut off the meaning halfway through a sentence. If a contract clause continues in the next block, the system should pull that in too. Otherwise, the assistant will quote the first half of the rule, while the exception stays out of view. In practice, this is usually solved simply: in addition to the found fragment, add the neighboring block above or below if they belong to the same section and share numbering.
What to store next to the fragment
Without metadata, search quickly starts mixing similar pieces. For each block, it is useful to store the document ID, its version, the path through headings, and the page number or range of lines.
These fields prevent old and new versions from getting mixed up. If the contract was updated yesterday, the assistant should not take a citation from the previous revision just because the wording looks familiar. Versions should be separated strictly: a separate version_id, a separate date, and an explicit status such as "current" or "archived".
Tables are a separate story. Do not turn them into a set of rows without the relationships between columns. When price, term, and payment condition live in different text fragments, the model starts combining the data at random. Store the table as a table: with a title, columns, rows, and a link to the section. Then the assistant can cite not a random snippet, but a specific row.
For RAG with citations, mixed search usually works better. First it searches by words, then by meaning, and then it ranks the results using the heading, version, and neighboring blocks. It is not the most flashy part of the architecture, but it is what produces citations that can be checked in a minute.
How to assemble the answer step by step
The mistake usually starts early: the system takes the question as a whole, finds a couple of similar fragments, and asks the model to "answer based on the document." That is how answers appear where one sentence comes from the right clause and the next one is already inferred. If you need reliable source links, build the answer not as one block, but as separate claims.
Take the question: "When can the supplier raise the price, and what is the penalty for missing the deadline?" There are already two different claims here. The first is about the conditions for changing the price, the second is about sanctions for delay. Searching for both in one request is inconvenient: good search will almost always surface one piece more strongly than the other.
First, break the question into short, verifiable claims. Not "explain the contract terms," but "can the price be changed," "who must notify whom," "what is the penalty amount," "what period is used to calculate delay."
Then search for a separate fragment for each claim. If the claim is about a penalty, do not let search pull in paragraphs about payment or acceptance. Four precise searches are usually better than one broad one.
Then merge neighboring pieces if the meaning is spread across several paragraphs. Often the rule is in one clause, and the exception or notice period is in the next one. If you give the model only one piece, it will fill in the missing part itself.
Before generation, prepare a small support package for each claim: the citation, clause number, page, and neighboring context. After that, allow the model to write only what is present in this package. If there is no support, the model should say directly that the document does not provide an answer.
It is better to place the citation right after the statement or short block, not at the end of the whole answer. The user should immediately see what each idea is based on: "The supplier may change the price only after written agreement from both parties [cl. 4.2, p. 7]."
This order noticeably reduces the number of polished but false answers. For RAG with citations, this is almost a must: first the claim, then the support, then the wording. If you let the model write freely, it quickly turns the document into a paraphrase with guesses.
In practice, a simple rule also helps: one claim without a found fragment equals one clear omission in the answer. It looks stricter, but the user understands the limits of the system and argues less with the citations.
Example from a supply contract
A procurement manager asks the assistant a simple question: "Is there a penalty for late delivery?" This is a good example of why citations matter at all. If search is weak, the system pulls two random pieces: one about liability of the parties, another about force majeure. Formally, citations are there, but there is no clarity.
A normal answer is built differently. The system finds the main clause about the penalty and the neighboring clause with exceptions. Suppose clause 8.4 on page 12 says: "The Supplier shall pay a penalty of 0.1% of the value of the goods not delivered on time for each day of delay, but no more than 10% of the total value of such shipment." And clause 8.6 on page 13 clarifies that no penalty is charged if the buyer delayed acceptance, failed to provide required data, or force majeure occurred.
Then the assistant answers substantively: yes, there is a penalty, the rate is 0.1% per day, the cap is 10% of the shipment value, and the exceptions are delay by the buyer and force majeure. The sources are listed separately: cl. 8.4, p. 12 and cl. 8.6, p. 13.
That kind of answer can be checked in a few seconds. The user sees the amount, the condition for application, and the limits, not just the phrase "liability is provided for by the contract."
There is one more important point. On click, the system should open not the whole PDF, but the right paragraph on the right page. If someone clicks the link to cl. 8.4, they should land on page 12 with the line about the 0.1% rate highlighted. If they open the exception, the system should take them to the paragraph on page 13. On paper, that sounds minor. In reality, details like these decide whether the user trusts the answer.
For this, storing the text of the chunk is not enough. The system must save the coordinates of the fragment: the page, clause number, paragraph boundaries, and neighboring sentences. Then the citation looks like real support from the document. The person can see that the assistant found the right place in the contract, not assembled the answer from random fragments.
Where the system fails most often
A common mistake is linking not to the rule itself, but to the heading of the section. The user asks about the payment deadline, and the answer cites a line like "Payment procedure." That is not support from the document. You need a fragment with the exact deadline, condition, exception, or calculation formula.
A lot of problems appear at page and chunk boundaries. Search finds a similar piece from the neighboring page because the same words repeat there: "delivery," "acceptance act," "deadline," "parties." As a result, the answer looks plausible, but the citation points to a nearby place, not to where the relevant rule is written. This often happens in contracts where similar wording appears in several sections one after another.
A scheme where one citation covers several conclusions also works poorly. For example, the assistant says that the goods must be paid for in 10 days, delay triggers a 0.1% penalty, and the contract can only be terminated after notice. If one general citation sits next to that, the answer is almost impossible to verify. The user does not understand which conclusion comes from which place. It is better to tie a citation to one statement or to two neighboring sentences from the same paragraph.
Versioning makes the error even more dangerous. A draft, an old appendix revision, or a contract without the latest edit can easily end up in the index. The model answers confidently because it really found the text, but it is no longer the document you need to answer from. If the storage contains contract_final, contract_final2, and contract_signed, the system will almost certainly make a mistake without metadata.
OCR also damages citations more than it seems. It pulls running headers, page numbers, footnotes, signatures, and broken table pieces into the text. Then search elevates a noisy fragment above a useful one, and the model inserts it as proof. It is especially bad when OCR merges two lines or breaks a word in half: the meaning of the phrase changes, but the citation still looks similar from the outside.
These failures are usually visible through simple signs: the citation is too general and does not contain the actual answer, the page number looks plausible but the relevant rule is missing, one source sits after a long paragraph with several conclusions, the citation contains junk such as repeated headers or footnote fragments, or the answer disagrees with the latest approved version of the file.
If these issues are not caught, source citations turn into decoration. Outwardly everything looks neat, but the user checks the citation and does not find support for the conclusion.
Quick checks before sending the answer
Before sending an answer, it helps to run a short manual or automated check. It takes seconds, but it saves you from the worst situation: the assistant sounds confident, yet the document support falls apart at the first look.
Each conclusion should have its own source. Not a general comment like "the document confirms it," but a clear link: a clause, paragraph, table, or page. If the assistant says the payment term is 10 business days, the user should immediately see where that came from.
In practice, a few checks are enough. Match each specific claim with one citation next to it. Verify numbers, dates, company names, and clause numbers character by character. Make sure the citation opens the right place immediately, without a long search through the file. And separately check which version of the file the system refers to if the document was updated.
Numbers break most often. The model can easily confuse "10 calendar days" and "10 business days," or "up to 5%" and "5%". For a contract, tariff, or policy, that is already a different meaning. That is why amounts, rates, deadlines, and names should be checked separately, even if the rest of the text looks plausible.
File versions also cause many misses. A draft may be in the database while the user is looking at the signed version. Then the formal links exist, but they are not very useful. The system should store the document version ID and pull citations only from the current file that participates in the answer.
A good citation opens in one click and shows exactly the fragment the answer relies on. Not the whole 80-page PDF and not a set of neighboring text chunks. The user should not have to guess where the model found the basis for the conclusion.
If the support is weak, it is better to say that directly. For example: "I found a similar fragment, but it does not confirm the deadline unambiguously" or "The document mentions a penalty, but it is not clear which case it applies to." That kind of honesty is more useful than a smooth answer with a questionable citation.
A simple test sounds like this: can a person verify the answer in 5-10 seconds and agree with it without rereading the whole document? If not, the answer assembly should be improved.
What to do next in production
In production, citations break not because of one big mistake, but because of small things that nobody tracks. Today the answer looks convincing, and a week later the model points to a different fragment because the model version, index, or chunk order changed.
That is why you should keep a trace of every answer. For each request, it is useful to log the question itself, the retrieved fragments, their positions in the document, the final prompt, the model version, and the answer text. Without that, you will not know whether search, generation, or citation post-processing broke.
Usually four checks are enough: the question should lead to the same fragments when run again, the citation should support the actual conclusion rather than the topic as a whole, the model should not cite a piece that matches by words but belongs to another clause of the document, and after a model update the quality should not drop on typical questions.
You also need a fixed set of control questions. Not ten random examples, but a compact set of real scenarios: payment terms, exceptions, penalties, effective dates, termination conditions. With such a set, it quickly becomes clear where the system likes to make things up, where it confuses neighboring paragraphs, and where it pulls too broad a fragment instead of an exact citation.
It is better to compare models on the same pipeline. The same retriever, the same chunks, the same rules for inserting citations. Otherwise, you are comparing not the models, but the whole stack at once. In practice, one model writes more cleanly while another ties the conclusion to the document more accurately. For citation-heavy tasks, link accuracy matters more than polished wording.
When a team reaches regular testing, another practical question quickly comes up: how do you switch models without rewriting client code. Here, a single OpenAI-compatible gateway is convenient. For example, AI Router on airouter.kz lets you change the base_url and work through one endpoint with different models while keeping familiar SDKs and prompts. Audit logs help you investigate disputed answers and internal checks.
A good sign of a mature system is simple: any bad answer can be broken down step by step in a few minutes. If that requires bringing up three services and guessing which model answered, the system is not ready for serious load.