Normalizing LLM API Error Codes for Product and Support
Error code normalization for LLM APIs helps reduce timeouts, limits, and bad requests into one dictionary for product, logs, and support.
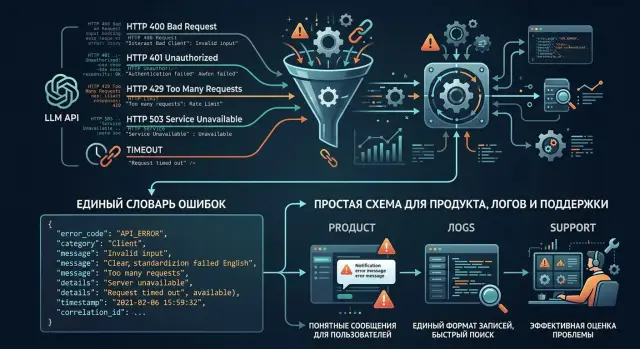
Why the same failure looks different
The same problem rarely arrives in one format. One provider returns 429 under load, another answers with 503, and a third simply drops the connection with a timeout. For the user, it is one situation: “the request failed.” For product, support, and analytics, it becomes three different events.
That is why normalizing LLM API error codes is not a minor detail or a cosmetic touch. If you do not reduce responses to a shared dictionary, the team starts arguing not about the root cause, but about wording. Support searches for similar cases manually, while product gets a distorted picture of how often problems happen.
The confusion shows up on several levels at once. Providers encode the same overload differently. Models from the same provider return different error text. SDKs and proxies sometimes replace the original status with their own exception. Monitoring then splits similar failures into separate metrics.
Because of that, the complaint “generation is stuck” looks different in logs. In one system you see 504 gateway timeout, in another 429 rate limit, and in a third something like upstream request failed with no clear code. Yet the source is often the same: the provider did not manage to process the request because of a queue or a hard limit.
Error text is unreliable too. One model says context length exceeded, another says too many tokens, and a third says invalid request. If you take those strings as they are, support ends up with three scenarios for one cause: the request is too large.
Even when you use a single gateway, the differences do not disappear on their own. A gateway simplifies access to multiple models, but the product still needs its own common error language. Otherwise, changing the model changes not only answer quality and cost, but also support behavior.
The biggest damage shows up in metrics. Errors split into dozens of small series, and you can no longer answer a simple question honestly: what breaks most often — limits, timeouts, or invalid requests?
Which error groups to keep in the dictionary
A good dictionary does not try to remember every response from every provider. It reduces different phrasings to a few clear groups so that product, engineering, and support can speak the same language. For most LLM integrations, five groups are usually enough.
The first group is timeouts and connection drops. This covers cases where the model responds too slowly, the connection breaks, the stream stops halfway, or the gateway did not get the answer in time. For the user, this looks like “the request hung” or “the answer never arrived.”
The second is limits and exhausted quota. One provider returns 429, another mentions rate limit, and a third reports a lack of credits. In the dictionary, this is one group, but inside it is useful to distinguish a short traffic spike from a fully exhausted budget.
The third is an invalid request. This is where JSON schema errors, unsupported roles, too long a context, invalid generation parameters, and incompatible API fields live. It is a frequent category, and it almost always needs a fix on the client side, not a retry.
The fourth is authorization and access errors. A wrong API key, an expired token, a ban on a specific model, or project and environment restrictions are better kept separate. In such cases, support can check permissions faster instead of looking for a model problem.
The fifth is provider failures and temporary unavailability. These are 5xx-class responses, overloaded clusters, routing errors, and internal failures of the external service. They should be marked as temporary if the request can be safely retried.
There is a simple test: from the group name alone, a person should immediately understand who takes the next step. The developer fixes the request, the platform retries the call, support checks access, and product sees a concrete failure type instead of the vague “AI is broken.”
If the team uses several models through one gateway, such a dictionary pays off very quickly. For example, when working through AI Router, different providers can still return context length exceeded, bad request, or just 400. For support, these are not three different problems, but one: the request exceeded the allowed size and needs to be shortened or split.
How to describe an error in a single format
If you have multiple providers and models, the same problem quickly turns into chaos. One API returns 429, another writes rate limit, and a third gives 503 with vague text. For product and support, this is one case, and it is better described with one internal code.
Start with a short dictionary of internal codes. The names should be simple and unambiguous: timeout_upstream, rate_limited, invalid_request, auth_failed, model_unavailable. Such a code does not depend on the provider and immediately answers what exactly failed.
Then map each code to the HTTP status the client will see. This removes unnecessary debates between teams. For example, invalid_request usually goes out as 400, auth_failed as 401 or 403, rate_limited as 429, and timeout_upstream as 504. There is no need to mirror the external status exactly. The client needs a clear and stable contract.
Set the retry policy separately. You need a direct answer, not guesses from logs: can the request be retried immediately, should it not be retried without fixes, or should it be retried later when the load drops.
It is better to split the error text into two layers. In the interface, you need a short and calm message without internal jargon: “The service did not respond in time. Try again in a minute.” For support, you need a different format: cause, action, and a link to the dictionary. For example: timeout_upstream: the provider did not respond for 30 seconds, retry is safe, check the traffic spike and route timeout.
In logs, keep the minimum fields without which investigation almost always stalls: provider, model, request_id, latency, internal_error_code. If requests go through a router, it also helps to add the route, number of retries, and whether fallback was triggered.
Normalization only works when one internal code connects four things at once: what happened, what status to return to the client, whether a retry is allowed, and what the interface and support will see. Then the product behaves predictably, and the noise in support drops noticeably.
How to build a dictionary from logs
It is better to start not with provider documentation, but with your own logs. Over the last 2–3 weeks, they usually already contain everything you need: timeouts, 429s, bad request, stream drops, empty responses, and rare 5xx errors. Save not only the HTTP code, but also the error text, provider, model, request type, and whether a retry helped.
Then it is convenient to follow a simple sequence:
- First, export the raw errors without manual cleanup.
- Then merge duplicates by meaning, not by text.
- Assign one internal code to each group.
- For each code, write a reaction rule: whether a retry is needed, which backoff to use, when to switch models, and when to open an incident.
- Finally, run the mapping against test responses from all providers.
A good sign of a simple dictionary is the same action for the same meaning. If one provider returned 408 and another returned 524 through a proxy, but in both cases the request hung and a retry after a couple of seconds usually helps, keep one internal code. Support does not need a museum of other people’s wording. It needs a clear answer: what happened and what to do next.
Also check the fields that product and support see. For the user, a short status like “the model did not respond in time” is usually enough. For the operator, you already need the details: the original code, provider, trace id, number of retries, and whether fallback was triggered.
If you use a gateway that both routes requests and hosts part of the models, test both failure types separately: external provider errors and errors in your own infrastructure. For the product they may look the same, but they need to be handled differently.
If the internal code does not suggest an action, it should be redesigned. Otherwise, the dictionary will quickly become just another list of unclear names.
What to show the user, support, and the engineer
The user, support, and the engineer do not need the same text. If everyone sees the provider response as is, the user gets noise, support starts guessing, and the engineer spends time decoding someone else’s wording.
The user should get a short reason and a clear action. For example: “The service is busy right now. Try again in 30 seconds.” Or: “The request is too large. Shorten the text and try again.” Phrases like upstream 429 or provider validation error only confuse people.
In the API, keep a stable internal code that does not depend on the provider. Today one says rate limit exceeded, another returns 429 with different wording, and a third calls it quota error. For product, this should be one code, such as RATE_LIMIT. The same applies to UPSTREAM_TIMEOUT, INVALID_INPUT, AUTH_ERROR, and CONTENT_BLOCKED. Then analytics, alerts, and retry rules do not break when the model or route changes.
At the same time, you cannot lose the raw provider response. Store the status, response body, headers, provider request_id, model, route, and response time. If the infrastructure already supports audit logs and PII masking, as AI Router does, such data can be stored more carefully and handed to engineers faster for investigation.
The same incident is easy to split into three layers:
- The user sees a short message without jargon or unnecessary details.
- Support sees the internal code, likely cause, and next step.
- The engineer sees the full technical trace, including the raw provider response.
Support benefits not only from the code, but also from an action hint. If RATE_LIMIT arrives, the system can immediately show: “Check the traffic spike, retry-after, and the fallback route.” If INVALID_INPUT arrives, support should see: “Ask the user to shorten the context or remove the unsupported parameter.”
This separation works well when requests go through one OpenAI-compatible layer to several models. Outside, the product speaks simply and calmly. Inside the API and logs, all the necessary precision remains.
Example for a team with multiple models
A bank has a support chat in its mobile app. During the day, traffic jumps around: in the morning customers ask about transfers, in the evening about cards and limits. The team does not keep all traffic on one model. It sends requests first to a fast model, and if that one cannot cope, it moves part of the load to a backup.
The problem starts when both providers describe the same thing in different words. The first model returns a standard HTTP 429. The second answers with rate_limit_exceeded, even though the meaning is the same: there are too many requests, and the user needs to wait a little.
If the product reads these responses as is, users see different text, and support wastes time guessing. One operator writes that it is an “API error,” another thinks the integration is broken, even though the cause is one.
The solution is simple: place a shared mapping layer between the app and the models. It does not argue with the provider format and does not drag every detail into the interface. It translates different responses into one internal code, for example limit_retry_later.
After that, the product shows a short message: the service is temporarily overloaded, please try again in a minute. That is enough for the customer. They do not need code 429 or the provider’s text.
Support, on the other hand, gets more details: which provider the system called, which model the router chose, what original code the provider returned, what internal code the system assigned, and when it is best to retry the request.
This approach removes confusion. For teams that route traffic through one gateway to multiple providers, it is especially useful: identical failures stop looking like different incidents.
Where teams make mistakes most often
Most problems do not start in the integration itself, but in the small things around errors. One provider writes a dry code, another sends a long text, and a third changes the format from model to model. If you feed this into the product without translation, support gets chaos instead of a clear picture.
The first common mistake is showing the user the provider’s raw text. Such text is noisy, sometimes alarming, and almost never explains what to do next. In the interface, it is better to keep a short message and store the full response in logs and the incident card.
The second mistake is putting 400 and 422 into one bucket just because both look like a “request error.” In practice, the meaning is different. 400 usually means the request was assembled incorrectly, while 422 often means the format is correct, but the data does not pass validation: input too long, unsupported parameter, or field conflict.
The third mistake is automatically retrying any failed request. For bad request, that is useless: the system wastes time, quota, and sometimes money, and the result does not change. A retry makes sense for timeouts, some 429s, and some 5xx errors, but not for broken parameters.
The fourth mistake is losing the provider request_id. It seems minor until the first serious incident. Then support sees a complaint, the engineer opens the logs, and the request can no longer be linked to the provider response. If you have multiple models and multiple providers, this trace is always needed.
The fifth mistake is inventing too many internal codes. When there are twenty or thirty of them, people stop remembering the difference, and new employees open the table like a dictionary of rare terms. It is better to keep a short set of categories and add a new code only when it changes the action of product, support, or the on-call engineer.
A good error dictionary should not look smart. It should quickly answer three questions: what happened, does the request need to be retried, and who can fix it.
Quick check before release
Before release, it is worth checking more than the success path. One unclear 429 or timeout quickly turns an ordinary failure into a long back-and-forth with the customer, where product, support, and engineering call the same problem by different names.
The short checklist below is usually enough:
- Every internal code has a simple name.
- Every code leads to one action.
- Support sees not only the code, but also an example real message with the first answer to the client.
- The dashboard counts errors by the internal dictionary, while the raw provider response is stored alongside it.
- Automated tests and manual checks cover at least 429, timeout, 400, 401, and 503.
There is one more detail people often forget: the same class of error should have the same name in logs, in the support panel, and in product reports. If the log says RATE_LIMIT, but the support interface says “temporary provider issue,” confusion starts in the very first week.
It is useful to check the scheme with a short example. Provider A returned 504, provider B returned a text error without a status, and your gateway marked both events as UPSTREAM_TIMEOUT. Support immediately understands what to tell the client: “The request got stuck on the model side, the system is already retrying, please come back in a minute.”
If after this check anyone on the team can look at the code and immediately understand the cause, the next action, and the text for the customer, the dictionary is ready for release.
What to do next
Do not try to describe the whole world of errors at once. It is better to take the 10–15 failures the team sees most often: timeouts, rate limit, bad request, provider refusal, authorization problems, and empty responses. If these cases get the same codes and the same explanations, product and support start speaking the same language almost immediately.
The dictionary should have an owner. Usually this is a backend lead, a platform engineer, or the person responsible for integrations. They decide where a new code belongs, keep the group names consistent, and stop the team from creating similar statuses like provider_timeout, model_timeout, and request_expired when it is really the same failure for the product.
A useful rule is simple: a new code first goes into a normalized group, and you add details later. Product and support need a stable code, clear text, and a clear action. Fields for analytics, such as provider, model, number of retries, and latency, can be added after the basic scheme stops changing.
If the team works with multiple models and providers, it is better to keep the normalization layer close to the single endpoint. Then you catch provider response differences in one place, not in every service separately. If an OpenAI-compatible gateway like AI Router is already used for this, where you can keep the existing SDKs, code, and prompts and simply change base_url, it becomes much easier to maintain routing and the error dictionary side by side.
Once a month, it is useful to review fresh logs and look at four things: which codes appeared for the first time, which errors landed in the wrong group, where support text is too generic, and which failures should already be split into more precise subtypes.
Do not chase perfect analytics in the first month. Stable codes for product and support bring more value than a detailed but shifting catalog with hundreds of lines. If you choose an owner for the next sprint, lock in the rule for new codes, and describe the first 15 errors, the noise in logs will drop noticeably and incident review will move faster.