A Single API for LLMs: When It Is Better Than Separate Integrations
A single API for LLMs helps compare a shared gateway with separate integrations in terms of cost, launch speed, access control, and team growth.
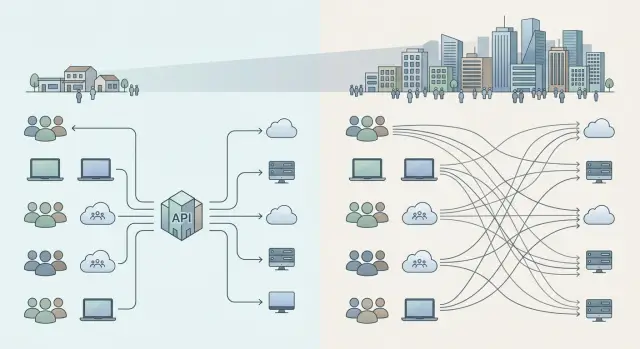
Why the choice of setup quickly becomes a problem
It almost always starts quietly. One team tests an idea on a single model, another is already building a customer-facing feature, and a third is trying an internal search tool. When there are only a few people, direct integrations seem reasonable: each team chooses its own provider and moves ahead without extra approval.
A couple of months later, it turns out that every product has its own account, billing, limits, and key storage method. Finance sees several bills instead of one clear picture. The engineering lead cannot tell where spending is rising because of real usage and where money is going to bad prompts, extra repeats, and failed retries.
The most painful part starts when you need to switch models or providers. If integrations are independent, every team has to update base_url, error handling, timeouts, limits, logging, and response formats separately. The work is not especially hard, but it is tiring. And it repeats again and again.
Usually the chaos starts with simple things: access lives in different dashboards, limits are set without common rules, bills arrive from several places, and logs do not form one clear picture. After that, the discussion quickly stops being purely technical. It turns into a control question: who sees the total spend, who can quickly shut down a risky scenario, who understands which teams are sending personal data to external services, and which teams already mask PII.
For companies in Kazakhstan and Central Asia, local requirements add another layer. You may need to consider data storage inside the country, audit logs, content labels, and clear access rules. If every team handles that separately, the differences build up quietly and then turn into a long list of manual checks.
That is why the choice between direct integrations and a single API rarely stays a small architectural decision. Today you have one pilot, tomorrow five internal services, and next quarter the product team asks to connect two more models. At that point, a single API no longer looks like unnecessary overhead. It looks like a way to avoid fixing the same problem in six different places.
What a single API gives you
A single API removes one of the most boring and expensive problems: every team works with models in the same way. Instead of five different SDKs, tokens, and connection rules, the company gets one entry point and one shared way of working. A new service launches faster because the developer does not have to spend a week figuring out someone else’s integration.
The difference becomes especially clear after the first successful pilots. When you have one chatbot, a separate connection feels normal. When you have four or six bots, confusion starts: one team goes directly to OpenAI, another works with Anthropic, and a third manually changes limits in code. A single API makes new product connections predictable and removes unnecessary variation in approach.
Shared rules are also easier to keep in one place. Access, limits, audit logs, PII masking, and content labels are easier to define centrally than to check separately in each app. If the company must keep data inside Kazakhstan, it is better to enforce that at the system level instead of relying on every team to be careful.
Another benefit is not obvious at first. Teams can switch models without changing every application. If one model is the best fit today and another delivers the same result faster or cheaper next month, the transition is smoother. For engineers, that means less routine work. For the business, it means less dependence on one provider.
Finance usually notices the value before engineers expect it. When all calls go through one layer, costs are easier to break down by department, product, and individual scenario. Then it becomes clear who is spending the budget on customer support, who is using it for internal search, and who is spending it on experiments. The money conversation gets simpler because everyone is looking at the same number.
In practice, implementation is often simpler than it seems. The team changes base_url, keeps the familiar SDK, and continues working. That is how AI Router works: it is an OpenAI-compatible LLM API gateway that lets companies centralize access, limits, audit logs, and billing in tenge without rewriting their current code from scratch.
When direct integrations are more convenient
Direct integrations often win at the start, when a team is building one service and wants to test an idea in a couple of weeks. If there is only one product, the request flow is easy to understand, and the risks are still low, connecting to a single provider is usually faster. Developers choose the SDK, limits, and retry logic themselves, without waiting for shared rules.
This approach is especially convenient for a small team. If four people are launching an internal assistant for support, they do not need a shared model catalog or complex routing. They need to build a working scenario quickly, check answer quality, and understand whether the project is worth continuing.
There is another case too: the service depends on a rare feature from a specific provider. That may be convenient tool calling, a special audio mode, a long context window, or a specific log format. In that case, a single API can sometimes get in the way. It standardizes the interface, but it can also hide the very thing that made the team choose that provider in the first place.
Direct integrations are also useful when a product lives separately from the rest. It has its own owner, its own budget, and its own metrics. The team does not want to share limits, costs, or priorities with other services. For a large company, that is a normal situation: one product is already generating revenue, while new ideas are still being tested nearby.
There is also a very practical reason. A company may simply not have the people who will maintain a single API. That layer does not appear by itself. Someone needs to watch access, pricing, audit, fallback logic, and the rules for different teams. If there is no owner, the shared layer quickly turns into a no-one’s project.
But that freedom has an expiration date. When there are only one or two services, it barely matters. When the number of teams grows, the same work starts repeating: everyone tracks costs differently, fixes timeouts differently, and handles logs and security differently. If growth is already visible, it is better to agree in advance where direct integrations will stay the exception and where it is time to move to a single API.
How company growth changes the requirements
When a company has only one pilot, the team almost always chooses speed. It needs to connect a model quickly, test the scenario, and understand whether the idea works in a real task. At that moment, direct integrations are often more convenient: fewer approvals, fewer shared rules, faster first results.
Then the pilot stops being an experiment. A second product appears, then a third. One department builds a chatbot for support, another connects search over internal documents, and a third tests a voice assistant. At that stage, old decisions start getting in the way more than they seem.
With three teams, manual settings are still manageable. Someone keeps their own keys, someone sets their own limits, and someone tracks costs in a spreadsheet. It is inconvenient, but tolerable. When there are ten teams, this setup starts eating time every week. People argue about which model is used where, why one service hit a limit, and who is actually responsible for a provider outage.
Finance usually notices the problem before engineers are ready to admit it. If every team works with separate providers, costs spread across different dashboards, currencies, and billing rules. It becomes hard to build one forecast for the quarter. For businesses in Kazakhstan, this is especially noticeable when they need one clear invoice and proper B2B invoicing in tenge, not a pile of scattered payments.
Security also changes the discussion. When there are only a few requests, teams often agree informally. When models are used in several internal systems, that is no longer enough. You need shared rules for masking personal data, unified activity logs, clear key limits, and a clear answer to where the data is stored.
At that point, a single API starts paying off. Not because it is trendier, but because the job itself has changed. At first, you are just connecting a model. Later, you are managing access, budget, risk, and quality for several teams at once.
A good rule of thumb is simple: one service can still survive messy processes. Eight products and one shared budget cannot.
Example: from one pilot to eight products
It usually starts with a clear pilot. One team launches an internal chatbot for call center agents: answers from the knowledge base, script suggestions, and short call summaries. For that test, one token, one provider, and a couple of limits are enough.
A month later, the pilot shows good results, and other departments want to use the model. The mobile team adds an assistant to the app. Marketing asks for text generation and A/B variants. The risk team reviews requests and looks for suspicious wording. Each team goes its own way: creates its own account, gets its own tokens, chooses the provider it likes, and sets its own limits.
At first, people even like it. Nobody has to wait for anyone else, integrations move fast, and experiments do not slow down. But by the time the company has eight products and several internal scenarios, a different problem appears: nobody sees the full picture.
Finance sees the total bill, but does not know which product consumed the budget. The infrastructure team gets outage complaints, but cannot quickly tell where the rate limit was hit and where the external provider failed. Security asks for an access and data audit, and the teams send screenshots, spreadsheets, and bits of logs from different places.
Usually, the same symptoms show up at that point:
- limits live in different dashboards and conflict with each other
- tokens are stored in different ways, sometimes directly in services
- costs are calculated manually across several bills
- when something fails, people spend a long time figuring out whose provider it is and who is responsible
That is when a single API becomes less about control for its own sake and more about order. Teams can still work with their own prompts, SDKs, and scenarios, but the company moves into one layer the things that already need to be coordinated manually: access, budgets, limits, logs, and failover rules.
For companies in Kazakhstan, this often solves some very practical operational issues too. For example, a gateway like AI Router gives you one OpenAI-compatible entry point, audit logs, per-key rate limits, and monthly B2B invoicing in tenge. For a new team, that usually means faster onboarding and fewer manual approvals.
How to choose a setup
You should choose a setup not by what is convenient for one team today, but by how many teams, products, and constraints you will have in a year. If you have one pilot now and five teams plus several services in 6-12 months, an early decision can become expensive very quickly.
First, estimate the future load in organizational terms, not just in tokens. How many teams will use models? How many scenarios will move into production? Where will night incidents appear, where will budget limits matter, and where will disputes arise about who is responsible for switching providers?
Four questions before deciding
- How many teams and products will use models in the next year
- Which scenarios will stay as pilots, and which will need audit logs and predictable behavior
- Who owns access, limits, budget, and the rules for changing a model or provider
- What is cheaper: setting up a single API now, or migrating later when integrations are already numerous
After that, divide use cases into two groups. For pilots, internal tests, and fast experiments, direct integrations are often more convenient. The team moves faster and does not wait for shared infrastructure.
For customer-facing services and systems with security requirements, a single API is often the better choice. Those scenarios need shared limits, unified logs, a clear access model, and the same routing rules.
This is especially visible in banks, telecom, and healthcare. If data has to stay inside Kazakhstan and model actions need to be reviewed later, separate connections quickly create mess: every team has its own keys, its own logs, and its own way of switching providers.
Another step people often skip is assigning an owner. They do not have to write code, but they should be responsible for access, budget, the shared layer choice, and the transition plan if the current provider stops being a good fit.
In many companies, a hybrid approach works best. Pilots stay separate, while production goes through a single API. If you need an OpenAI-compatible entry point, audit logs, PII masking, and data storage inside the country, such a layer removes a lot of operational busywork. With AI Router, that scenario is built in: teams can keep their current SDKs, code, and prompts, while access and control rules are brought together in one place.
Where companies most often make mistakes
The first mistake is simple: companies build a shared layer too early. The team has one pilot, two developers, and one clear scenario, but they already introduce complex access rules, a shared gateway, approvals, and separate routing. In the end, people spend weeks not on the product, but on a setup that is not needed yet.
At the start, a direct integration is usually enough if the team understands the risks and leaves itself a path to replace the provider later. Problems begin when the pilot turns into several services and the code becomes tightly tied to one API, one log format, and one set of limits. Then any replacement affects timelines.
The opposite extreme is just as common. A leader leaves full autonomy to every team even after the company has already grown. One product uses OpenAI, another Anthropic, a third a local model, and a fourth its own proxy. A couple of months later, finance cannot quickly reconcile the bills, security does not know where the logs are, and the platform team cannot see the overall load.
The warning signs are easy to spot: teams count tokens and costs differently, logs are stored in different places or not kept at all, personal data is masked in different ways, key limits are set manually, and switching providers requires edits in several services.
Another common mistake is not about code but about rules. Teams argue about which model to choose, but they do not agree on who is responsible for audit logs, data masking, limits, and content labels. Then the first serious client, audit, or internal risk committee arrives, and it turns out that the technical setup is much weaker than it seemed.
Buying a platform too early, without internal agreements, also causes trouble. A single API by itself will not fix disorder if simple questions are still unresolved: who adds new teams, who approves providers, who reviews the bills each month. Even if the gateway lets you change only base_url and keep the SDK, code, and prompts, it will not build the process for you.
The working sequence is simple: agree on the rules first, then enforce them at the shared entry point. Otherwise, you end up with either an expensive layer on top of one pilot, or a set of integrations that nobody really controls anymore.
Quick check before deciding
Architecture usually breaks not on launch day, but six months later. New teams connect to the models, budgets spread out, and the provider suddenly becomes slower than usual. That is why, before choosing a setup, it helps to look not only at the current pilot but also at the next 12 months.
First, count future services, not just current ones. If one product uses the model today and support, search, an internal assistant, and analytics will be added next year, a single API often removes a lot of extra manual work. If you have one narrow scenario and one owner, a direct integration may live comfortably.
Then check who can see total spending across all products. When every team pays and tracks tokens separately, the company notices too late that one scenario is already consuming a significant part of the budget. You need one overview point where you can see which models teams are using and where spending jumped.
It is also useful to model a provider outage on a normal workday. If switching requires code changes in several services, re-issuing keys, and checking limits manually, the setup is already fragile. A healthy option lets you move traffic quickly and without panic.
Decide in advance where logs, prompts, and sensitive data will live. For a bank, clinic, or government team, this is not a formality. You need to know who can see PII, where request history is stored, which audit logs are required, and whether data must stay inside Kazakhstan.
And finally, assess the amount of manual work as you grow. If you separately create access, limits, masking rules, and reports for every new team, people will soon end up maintaining the setup itself instead of the product.
Here is a simple mental test. Imagine that in six months you no longer have one pilot, but eight live scenarios across different departments. If your current approach in that picture requires a lot of manual work, hides the budget poorly, and makes provider changes difficult, a single API will almost certainly cause less pain.
For companies in Kazakhstan, this choice often comes down to data storage inside the country and clear auditing. If those requirements are already on the table, it is better to account for them from the start, not after the first incident.
What to do next
Do not try to choose a setup for the next three years right away. It is much more useful to describe the next two growth scenarios: what happens if you stay with one product, and what happens if two more teams with different tasks appear in six months. That view quickly shows where a single API will cause less pain and where direct integrations are still simpler.
For example, today you may have one service that generates responses for customers. In a few months, it may be joined by internal document search, a voice bot, or a request-checking module. If these products share budgets, access policy, and logging requirements, a single API usually saves time. If the product is one, the team is small, and the model is likely to stay chosen for a long time, a direct connection may be faster.
It is better not to argue in the abstract, but to run a short test. Put one product through a single API. Leave another on a direct provider integration. You do not need a large project for this. A 1-2 week pilot with the same tasks and similar load is enough.
Compare more than just answer quality. Look at more practical things: how many days it took to launch, how many bills and contract touchpoints appeared, who gives access to teams and how, and how many times the code had to be changed when switching models or providers.
If the difference is small, do not make the architecture more complex than it needs to be. But if a single API already removes extra code changes in the pilot, simplifies access, and makes costs clearer, that is a strong argument for centralization.
For teams in Kazakhstan and Central Asia, there is a practical way to test this scenario without a large migration. For example, AI Router lets you change base_url to api.airouter.kz and keep working with the same SDKs, code, and prompts. At the same time, you can see how useful local data storage, PII masking, audit logs, and monthly B2B invoicing in tenge really are.
It is best to write down the result of the test. Often one page is enough: which option you are testing, which four metrics you compare, and what result would trigger the next stage. Then the decision is made by facts, not by the loudest voice in the room.
Frequently asked questions
When is it better to keep a direct integration with a provider?
A direct integration works well when you have one service, a small team, and a short pilot. In that case, it is easier to validate the idea quickly and avoid spending time on a shared layer, as long as you leave yourself a path to switch providers later.
How do we know our company already needs a single API?
A single API is usually needed when the number of models and teams grows beyond two or three, and costs, limits, and logs start living in different places. If changing a model already requires edits in several services, you are very close to the point where a shared entry point saves time every week.
Do we need to rewrite code when moving to a single API?
Often, no. If the gateway is OpenAI-compatible, the team can change base_url and keep working with the same SDK, code, and prompts. That is exactly the basic scenario for AI Router.
What does a single API give us when changing a model or provider?
With a shared layer, you change the route in one place instead of going through each app separately. That reduces manual edits, lowers the risk of mistakes, and makes it easier to move traffic to a cheaper or faster model.
Does a single API make it easier to see costs?
It gathers calls in one place, so costs are easier to break down by product, team, and scenario. Finance gets one clear picture instead of a pile of separate bills, and engineering teams can see faster where the budget goes to useful work and where it is lost on extra retries and bad reattempts.
How does a single API help with audits and incident reviews?
Logs, limits, and access are easier to keep in one place, especially when several teams use LLMs. Then it is simpler to investigate failures, check key activity, and answer security questions without screenshots and manual cross-checks.
What should we do if we need to store data in Kazakhstan and hide PII?
If you have requirements to keep data inside the country, it is better to enforce them at the shared system level instead of relying on each team to be careful. For Kazakhstan, this is especially convenient when the gateway supports local storage, PII masking, audit logs, and content labels out of the box.
Can we combine pilots on direct integrations with production through a single API?
Yes, that is often the most sensible approach. You can keep pilots and fast experiments on direct integrations, while sending customer-facing and sensitive scenarios through a single API, where access rules, logs, and budgets are easier to manage.
Who should be responsible for the shared LLM API in the company?
You need a specific owner, even if that person does not write code. This person is responsible for access, limits, budget, rules for onboarding new teams, and the action plan if the provider or model stops being a good fit.
How can we check which setup fits us without a big migration?
Do not debate it in the abstract — run a short test for one or two weeks. Put one product through the single API, keep another on a direct provider integration, and compare launch time, the number of manual changes, how clear the costs are, and how the team handles a model switch or a provider outage.