Search in Russian and Kazakh: Embeddings and Normalization
Search in Russian and Kazakh requires careful choices of embeddings and normalization rules so that mixed-language queries return the right answers.
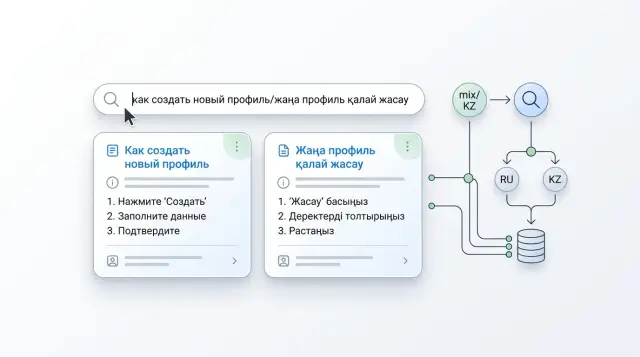
Why a mixed query often gets poor results
The problem usually does not start with the model, but with the question itself. People write the way they speak: part of the phrase in Russian, part in Kazakh, plus slang, typos, and sometimes transliteration. For a person, that is one thought. For search, it is several signals pulling results in different directions.
For example, an employee asks: "How do I open an account for an individual entrepreneur if the client is already тіркелген?" The Russian part sets the topic, the Kazakh word changes the context, and the term "IP" adds a subject-specific detail. If the index and normalization are not ready for that, the system grabs the familiar pieces and loses the overall meaning.
It also gets in the way that the same entity often lives in the knowledge base in different forms. One document says "account number", another says "zhеке шот", and a third uses only the internal product name. If these variants are not linked in the data and rarely appear in similar contexts, the model does not always understand that it is the same thing.
Usually the failure looks simple: the search catches a similar word, but not the right scenario; a Russian term finds a Russian document, while the Kazakh part of the query is ignored; transliteration like "schet ashu" drops out of matching; a conversational form sends the query toward common but useless answers.
This is especially noticeable where people do not strictly separate languages. In a bank, support team, or internal portal, an employee may start a question in Russian and finish it in Kazakh because it is faster. At that moment, the system sees not one query, but a mix of tokens, spellings, and semantic hints.
Without normalization, things usually get worse. The search layer starts surfacing documents based on superficial similarity: matching roots, frequent abbreviations, and neighboring phrasing. But the user needs not a set of similar words, but an exact answer to their task.
Weak results for mixed queries rarely mean the embeddings themselves are bad. More often, the knowledge base stores synonyms separately, the texts came from different sources, and preprocessing did not reduce the writing variants to one clear form.
What to check in the knowledge base before choosing a model
First, examine the corpus itself, not the list of models. Bilingual search often breaks not because of embeddings, but because of how the texts are stored in the knowledge base. If Russian appears only in the heading of one document, while Kazakh is hidden in a table or footnote, the model gets a weak signal and returns a strange result.
It helps to quickly go through the documents and note where the languages are mixed most heavily. The most common problem spots are headings and main text in different languages, short paragraphs and table captions, cells with terms and codes, and FAQs where the question and answer are written differently. This review takes a couple of hours, but it saves a lot of time later in testing.
After that, collect the common term pairs from your subject area. This is not a translation dictionary for the sake of a dictionary, but a practical list of synonyms and parallel formulations that really appear in questions and documents. For a bank, that might include pairs like "IP" - "zhеке кәсіпкер", "account number" - "zhеке шot", or "card reissue" - a conversational phrase from chats. Without that layer, even a good model will stumble over inconsistent wording.
Also check the document structure. Tables, scans, OCRed PDFs, and old CMS systems often break text more than it seems. The same phrase in clean HTML and in a badly recognized PDF is already two different objects for the index. If you do not remove that noise first, choosing the model will not change much.
How to choose embeddings for two languages
For Russian-Kazakh search, the usual selection logic often does not work. A model may understand Russian well on its own and Kazakh well on its own, but link them weakly in one vector space. Then a query like "how to restore a card and is there a fee" can send search in the wrong direction, even though the right answer exists in the knowledge base.
Do not look at a model's polished description. Look at whether it places documents in two languages close to each other when the user mixes them in one question. For RAG, this is a basic requirement. If the connection between the languages is weak, everything breaks before ranking and answer generation.
General benchmarks are useful only as a first filter. The final choice is better made on your own data: real user questions, your product names, abbreviations, keyboard layout mistakes, and local terms. If the knowledge base contains wording like "card reissue", "IIN", and mixed operational phrases, a public ranking guarantees very little.
Look at three metrics at once: the share of correct hits in the top 5, the cost of indexing and reindexing, and the latency under heavy search. Top 5 is often more important than top 1. The user still gets several candidates, and then a reranker or LLM finishes the selection. If one model gets 78% correct in the top 5 and another 72%, the difference is already noticeable. But if the first is three times more expensive and much slower, the choice is no longer obvious.
On a small knowledge base, there is no need to test ten options. Usually 2–3 candidates are enough: one strong multilingual model, one cheaper option, and one with a convenient hosting setup if data residency in Kazakhstan matters to you. That set quickly shows where the model truly understands mixed queries and where it only looks good in a demo.
The test should be simple. Collect 50–100 real questions where Russian and Kazakh appear in the same phrase, and mark the correct documents for each one in advance. Then run all models on the same set. This kind of test quickly shows which model keeps the meaning and which one only follows word matches.
If two models give almost the same quality, it makes more sense to choose the one that is cheaper and more stable in latency. In production, that is usually more useful than a small gain on paper.
How to normalize text without losing too much
If people write in Russian and Kazakh mixed together, aggressive normalization often damages meaning before embeddings can help. In most cases, simple rules are enough: convert to one case, remove noise, and leave alone anything that changes the meaning of the query.
The first thing to do is choose one case format for all documents and queries. Lowercase is usually enough. That removes unnecessary differences between "Credit", "credit", and "CREDIT" without changing the meaning.
Next, clean up what came from PDFs, scans, and old CMS systems. Extra spaces, line breaks inside words, double tabs, non-breaking spaces, and invisible characters can easily ruin search. Because of them, the same phrase becomes two different strings for the index.
What is better not to break
Kazakh is easy to get wrong at the character level. A user may write a word in Cyrillic, Latin, or mix both in one query. But that does not mean you should blindly replace every similar-looking letter. If you collapse different characters into one form too early, you lose distinctions between words and reduce accuracy.
A practical compromise is usually this:
- keep the original text unchanged;
- keep a normalized version next to it for the index;
- add soft rules separately for common Cyrillic-Latin mixes;
- check questionable replacements on real queries.
For example, the query "card ashu for IP" is already mixed. If the system also distorts Kazakh letters or glues pieces of text together after PDF extraction, it will find the wrong section of the knowledge base. But if you simply clean the noise, normalize the case, and carefully handle similar characters, the chance of getting a good result goes up noticeably.
Do not rush with function words either. In Russian and Kazakh queries, short words sometimes carry important meaning: they show relationships between objects, questions, negation, or conditions. If you remove them without checking, the search will confuse "without a fee" and "with a fee", "for IP" and "for LLP".
It is always better to keep the original text next to the normalized one. This helps in three situations: showing the user a clean answer fragment, quickly investigating search errors, and changing normalization rules without losing data. For a Russian-Kazakh knowledge base, this is a simple safety net against silent failures.
How to set up search step by step
First, collect not "ideal" examples, but real questions from people. Search logs, support tickets, and operator chats work best. For the first run, 100–200 queries are enough, where Russian and Kazakh appear in different forms: fully in one language, mixed in one phrase, with typos, abbreviations, and conversational words.
Then create a simple reference set. Each question should have one document that you consider the correct answer. If a bank's knowledge base has a customer write "card blocked how to remove", the team should decide in advance that the correct answer is the card unblocking instruction, not a general safety section.
Then a simple workflow helps:
- Run the baseline search without new rules and save the results.
- For each query, mark whether the correct document appears in the first 3 and first 10 results.
- Add one normalization rule, for example lowercasing or replacing different apostrophes in Kazakh words.
- Repeat the search on the same question set.
- Compare what changed in the top 3 and top 10.
This approach may seem slow, but it saves time. If you turn on transliteration, stemming, stop-word removal, and several more heuristics all at once, it becomes hard to tell what helped and what harmed search. In practice, aggressive normalization causes more damage than weak embeddings.
Do not just look at the number of hits, but at the type of errors too. Sometimes the right document stays in the top 10, but drops from position 2 to 9. For the user, that is almost a miss. So it is better to evaluate quality in two slices: what the person sees immediately, and what the system actually found.
If quality improved only on Russian queries after one change, but got worse on mixed queries, it is better to roll the rule back. Normalization should remove noise, not erase the language. When the team moves in small steps, after a few iterations it becomes clear where the problem is: in the document text, in the embeddings, or in query processing.
An example from a bank knowledge base
A customer types into search: "How do I open a card for IP and what documents are needed?" For a person, the query is clear right away: they want instructions for a card for an entrepreneur and a list of documents. For search, this is a more complex task, because one part of the phrase is in Russian and the other is in Kazakh.
The problem shows up quickly if the knowledge base is assembled unevenly. Some articles are in Russian, others in Kazakh, and the names and phrasing do not match. One text says "IP", another says "zhеке кәсіпкер", and a third just says "entrepreneur".
Because of that, the old search breaks the meaning of the query apart. It finds either materials about opening a card or articles about documents. The user gets two incomplete hints instead of one needed instruction.
In this situation, search usually improves not after one clever setting, but after two clear changes: the team normalizes the texts into one form and switches the embedding model to a multilingual one.
Normalization often brings a quick effect. The team lowercases text, removes extra symbols and inconsistent spelling, adds synonyms like "IP", "entrepreneur", and "zhеке кәсіпкер", and preserves important banking terms without rough simplification.
After that, the query and the documents become closer in form. Search no longer stumbles over a mix of two languages and different variants of the same term.
Then a lot depends on the embedding model. If the bank uses separate models or a weak model for one language, vector search lifts only the texts that match part of the question. A multilingual model keeps the overall meaning better and connects Russian and Kazakh phrases in one space.
In practice, the right article rises higher if one chunk contains the steps for opening the card and another block contains the documents. Even when the documents are split into a separate article, good search more often places both instructions nearby instead of one random article.
For a bank, this is a practical effect. The customer does not need to rephrase the question, and support gets fewer repeated requests about the most common operations.
Where teams most often make mistakes
Search in Russian and Kazakh rarely breaks because of one bad model. Usually, the reason is a chain of small decisions. The team tries to fix everything at once, and then it is no longer clear what exactly broke the results.
What breaks the result
The first common mistake is to mix translation, transliteration, and normalization in one step. For example, the query "card according to the limit" can be translated, then the word forms simplified, then Latin letters replaced with Cyrillic. After that, the system is no longer working with the original question, but with an imprecise copy of it. It is better to separate the stages: text cleaning separately, handling spelling variants separately, and translation separately if it is needed at all.
The second mistake is chunking too small. If you cut a document into pieces of 100–150 characters, meaning falls apart. In a Russian-Kazakh knowledge base, this is especially noticeable: the term may be in one language and the explanation in another. The user asks in a mixed way, while the search only sees fragments. It is usually better to use chunks that keep one complete idea together, rather than just a fixed length.
Another mistake is checking quality only on your own questions. The internal team knows the structure of the knowledge base, the right words, and even the section names. Real users write differently: they shorten, mix languages, mistype layouts, and insert product numbers and abbreviations. If those queries are not in the test, you are evaluating a comfortable scenario, not live usage.
Numbers, abbreviations, and product names suffer separately. Search may understand "card limit" well, but fail on "limit for Gold", "IBAN", "KZT", "3DS", or an internal tariff name. For a bank, telecom, or SaaS company, this is a normal type of query. These tokens are better collected in a variant dictionary and checked separately.
Experiment mistake
The most expensive mistake is changing embeddings, chunking, and reranker at the same time. After that, the charts may look better or worse, but they will tell you almost nothing. Change one thing at a time and keep the same test set of questions. Then it is clear what brought the improvement: the new model, chunk size, or ranking.
What usually gets in the way is not the complexity of the languages themselves, but the lack of discipline in the experiment. With mixed queries, that becomes obvious very quickly.
Quick check before launch
Before the pilot, put together a small but honest test set. Often 20–30 Russian queries, 20–30 Kazakh queries, and another 20–30 mixed ones are enough. That is sufficient to quickly see where the system gets confused.
Do not use cleaned-up examples. Take real wording from chats, tickets, and emails. A user rarely writes perfectly. They may ask "card limit in tenge", "close the loan early", or mix both languages in one phrase.
Each query should already have the correct result marked: the needed document, section, or specific fragment. Without that, the team quickly starts arguing based on intuition. If there can be several correct answers, record one main one and one acceptable fallback.
Normalization rules should also be checked before launch. They need to be clear and repeatable, without manual tweaks for every miss. If you lowercase text, remove double spaces, clean noisy symbols, and handle abbreviations the same way, any engineer on the team should be able to reproduce it.
Before launch, it is useful to check a few things:
- there are three groups of queries: Russian, Kazakh, and mixed;
- each query has an expected document or fragment;
- normalization rules are written in one place;
- quality is measured separately for all three groups;
- misses from logs are added to the next test set.
Do not reduce everything to one average number. Overall Recall@5 or MRR may look fine even if mixed queries are failing. Metrics are better viewed separately for each group. If Russian is 82%, Kazakh is 79%, and mixed queries are only 54%, the problem is already visible.
After the first real queries, do not throw away the misses. On the contrary, they are the most useful. If users search for "income certificate download" and the system goes the wrong way, that example should immediately go into the next test set.
A good launch looks boring: a clear test, simple rules, and automatic error collection. Without that, search will not break in the demo, but in the working chat.
What to do after the pilot
After the pilot, do not rush to connect all documents and all teams. It is better to start with one live scenario where a search error costs a lot of time: a customer FAQ, a support base, or internal procedures for employees.
One scenario is easier to measure. If a bank employee enters a query like "how do I increase the card limit", the system should consistently find the right material in both Russian and Kazakh. Get that working on a narrow dataset first, then expand the scope.
The most useful habit after the pilot is to keep a miss list. Not a general complaint chat, but a short working log that the team reviews once a week. Usually five fields are enough: original query, what showed up in the top results, what the user expected, the reason for the error, and what changed after the review.
After 2–3 weeks, that list almost always shows repeating failures. Usually they are mixed-language queries, different forms of the same term, overly aggressive text cleaning, or weak coverage of Kazakh phrasing in the knowledge base.
Before scaling, lock in one normalization scheme. If today you remove punctuation and lowercase text, and tomorrow you start handling Russian and Kazakh documents differently, quality will quickly become uneven.
It is better to choose one clear version of the rules and give it a number. For example: keep Kazakh letters, remove extra spaces, normalize case, do not break abbreviations, and do not translate terms manually without a reason. If the rules change later, the team should know which collections have already been reindexed and which have not.
After that, look not only at the average metric, but also at how the system behaves on real queries. If 85% of questions work well, but the remaining 15% hit the most common support scenarios, it is too early to call the pilot successful.
If the team is comparing several LLMs for RAG answers in parallel and also wants to keep data in Kazakhstan, AI Router can be used separately as a single OpenAI-compatible API layer for such tests. It will not fix poor normalization or weak embeddings, but it simplifies model comparison through one endpoint and helps avoid rewriting the integration for each provider.
The next practical step usually sounds boring, but it gives the best result: one text scheme, one list of errors, one live scenario for weekly review. That is how search stops being a demo and becomes a normal working tool.
Frequently asked questions
Why does a mixed Russian-Kazakh query often break search results?
Because the search sees not one idea, but a mix of signals. Russian words point to some documents, Kazakh words point to others, and abbreviations, transliteration, and typos blur the meaning even more.
As a result, the system grabs familiar pieces of the phrase and misses the right scenario. Usually the problem is not one model, but the data and preprocessing.
Should you start with the model or with the knowledge base?
Start with the document corpus. If the texts are stored in different forms, the model will not save the search.
Check where the languages are mixed, how tables are formatted, what OCR produced, and whether the same entity has different names in the knowledge base. Only then compare embeddings.
What should you check in documents before testing embeddings?
Most failures are hidden in headings, tables, FAQs, scans, and old PDFs. One language may be in the heading, while the other is in a caption, cell, or footnote.
Also check how the knowledge base stores synonyms. If "IP", "entrepreneur", and "zheke кәсіпker" live separately and rarely appear together, the search will get confused.
How many embedding models is it really worth testing?
At the start, 2–3 options are enough. Take one strong multilingual model, one cheaper model, and one model with convenient hosting if keeping data in Kazakhstan matters to you.
A huge list only stretches the test out. It is much more useful to run a small set of candidates on real queries from the team and users.
Which metrics matter most when choosing embeddings?
Look at the share of correct hits in the top 5, the cost of indexing, and latency. For RAG, top 5 is often more important than top 1, because a reranker or LLM still chooses from the candidates.
If two models give nearly the same quality, it is usually better to choose the cheaper one with more stable response time.
How do you normalize text without ruining the meaning?
Do not touch everything at once. Usually lowercasing, cleaning noisy characters, fixing broken spaces, and carefully handling common Cyrillic-Latin mixups are enough.
Keep the source text separate from the normalized version. That way you will not lose data and can change the rules without blindly moving the whole database.
Should you translate the whole knowledge base into one language?
No, you do not need to. Full translation often adds errors and erases the real wording users use.
It is better to link common term pairs and keep both forms in the index. That approach usually works more accurately than trying to force all documents into one language.
What chunking works best for a Russian-Kazakh knowledge base?
Too-small chunks are harmful. If you cut text into 100–150 character pieces, the term may stay in one chunk and the explanation in another.
Use chunks that keep one complete idea together. This is especially important for a bilingual knowledge base, because meaning is often split between two languages within one fragment.
How do you set up an experiment so you can actually draw conclusions later?
Change one thing at a time. If you update embeddings, chunking, and normalization rules at the same time, you will not know what helped and what broke search.
Build one test set from real queries and run every version through it. That way the team quickly sees where the model helps and where text processing gets in the way.
What should you do after the pilot so search does not fall apart in production?
After the pilot, choose one live scenario and keep a miss log. Record the original query, what appeared in the top results, what the user expected, and what the team changed.
After a couple of weeks, you will see repeating failures: weak synonyms, over-aggressive text cleaning, or poor coverage of Kazakh wording. At that stage, it helps to lock in one normalization scheme and stop changing it randomly.