Updating RAG knowledge without full reindexing
Updating RAG knowledge without full reindexing: how to find changed documents, recalculate only the necessary chunks, and remove stale answers from results.
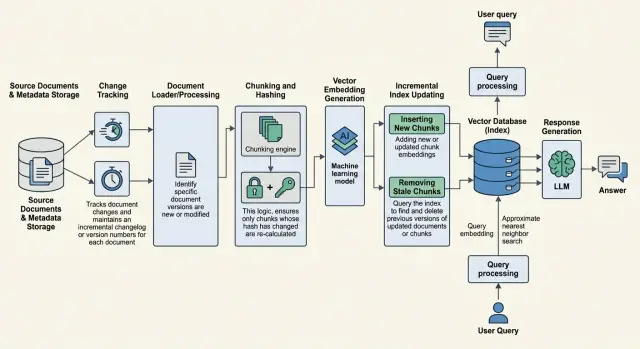
Why old answers stay in search
The problem does not start when the answer is generated, but earlier - in the index. You update a document, but the old chunks do not disappear on their own. Search still considers them relevant because, in meaning, they still look similar to the user’s question.
This is how freshness in RAG usually breaks. The new version of the document is already loaded, while the old one remains in the vector database, the search cache, or a service table. In the end, the system looks into two layers of memory at once: the current one and the outdated one.
The file date rarely helps. The retriever almost never makes a decision based on updated_at. It compares the query with the chunk text, its embedding, and the metadata you stored during indexing. If the old and new documents have the same name, a similar title, and almost identical text, both sets of fragments end up in the results.
Point edits are especially tricky. For a person, changing answer the customer within 3 days to within 1 day changes the meaning of the document. For the index, though, 90% of the text stayed the same. Old and new chunks look almost identical, so search easily returns them together.
What usually happens next is one of two scenarios. Either the old chunk ranks higher because the wording of the question is closer to the previous version. Or both versions end up in the same context, and the model builds an answer from different documents: it takes the number from the old text and the explanation from the new one. The user gets a confident but incorrect answer.
That is why the mistake feels especially frustrating. The team is sure the knowledge base has been updated, but the system keeps referring to the old policy, the previous rate, or a canceled procedure. For a bank, a medical system, or an internal policy, this is no longer a small inaccuracy - it is a real risk.
If you do not control document versions and do not turn off old chunks in search, the system starts mixing the past and the present. The model is not "lying" here. It is simply answering from what you left in the index.
How to separate a document from its version
Confusion usually starts with a simple mistake: every new upload lives as a separate document with no link to the previous one. Then search sees both the old text and the new text, and the system does not know which answer is current.
It is better to separate two things right away: what the document is and which revision it belongs to. A document needs a permanent source_id. It should not change because of a new file name, another folder, or a repeated upload. If this is a leave policy, it is still the same source even if the lawyer first sent it as final_v3.docx and then as final_v4_really.docx.
Store version_id separately. This is the identifier for one specific revision. One source_id can have many versions. This setup quickly removes half the problems: you can tell which version is active now, which one went to the archive, and which version the model answered from last week.
Each chunk should also know where it came from. Do not store fragments on their own. Link them to source_id and version_id so the system can remove the old piece precisely and keep the new one in its place.
If a version becomes effective from a certain date, it is useful to store valid_from and valid_to. Then the old revision does not disappear without a trace. It stays in history, but no longer takes part in normal search. That is very convenient for auditing.
It is better to keep the working layer and the archive layer separate. The working layer contains only current chunks. The archive layer keeps previous versions for review, rollback, and investigation of disputed answers. If you mix everything into one collection and rely only on careful filters, sooner or later someone will forget one parameter, and the old rule will show up in results again.
A good setup looks boring. That is a plus. When one paragraph changes in one policy, you know exactly which chunks to close, which to recalculate, and what to keep in the archive.
What fields are worth storing
The simplest first step is to calculate the hash of the new version and compare it with the previous one. But a single hash for the whole document is not enough. If you store only one checksum, you will not be able to tell a text change from a metadata change. And that already affects both the cost of updating and the amount of work.
In practice, it is better to keep two hashes separately: text_hash and metadata_hash. Then the pipeline behaves predictably. If only the department tag, owner, or validity period changed, it is enough to update the document card and filters. If the text itself changed, you need to rebuild the affected chunks and remove the old ones from search.
Usually this set of fields is enough: source_id, version_id, text_hash, metadata_hash, updated_at, is_active. If you want to debug issues faster, add the editor or the ID of the process that made the change.
A change log is not just for show. When search suddenly starts answering from an old revision, you can immediately see who uploaded the new version, when it happened, and whether the document went through the full update cycle. It is useful to store at least three things: time, initiator, and type of change. A metadata_only flag saves unnecessary recalculation, while text_changed sends the document straight into the update queue.
A simple example: in a bank policy, the department name changed in the document card, but the rules text itself did not. In that case, embeddings do not need to be recalculated. But if the operation limit or customer response time changed in the same document, the text hash changes, and the old chunks must be replaced.
How to update only the changed parts
Full reindexing is only convenient at the start. Later it becomes a problem: it takes hours, spends money on embeddings, and creates an awkward moment when two versions of the same text live in search at once. A short cycle that touches only what really changed works much more calmly.
Usually the process looks like this. The system finds changed documents by hash, edit date, or version number. If a file has not changed, it is better not to touch it at all. For each changed document, the pipeline splits the text into chunks again, but only for the new version. Then it builds embeddings for the new fragments and saves them as a separate set.
Old chunks should not be deleted immediately. First the new version has to make it into the index and pass a short check. Only after that is the previous revision moved to an inactive state, for example with is_active = false or a version status that excludes it from retrieval.
Order matters here. If you hide the old chunks first and the new ones are not written yet, search goes blind for a while. If you add the new ones first but forget to turn off the old ones, the system starts mixing two revisions and giving strange answers.
It is safer to do the update in two steps: first write the new version, then switch the active flag atomically. That makes rollback easier if a freshness test finds a problem.
Imagine the response deadline in a policy changes from 10 days to 5. The pipeline should recalculate chunks only for that document, create new embeddings only for the changed pieces, disable the old ones, and check a query like what is the response time in the policy. If search still sometimes pulls up 10 days, the update cannot be considered complete, even if the index technically built without errors.
How to turn off old chunks without pausing search
Old chunks do not disappear by themselves. If you simply add a new version of a document to the vector database, the retriever will often see both the old and the new fragments at once. The model receives mixed context and answers based on an outdated rule.
The working approach is to hide old chunks logically first and delete them physically later. It is useful for each fragment to store doc_id, version_id, is_active, retired_at. When a new version arrives, you write the new chunks, verify them, and only then switch the previous revision to is_active = false.
This helps you avoid a pause when the old content is already removed but the new content has not yet reached the index. For policies, pricing, and internal instructions, this is especially important. One wrong paragraph can easily break the whole answer.
The filter matters more than physical deletion
Search should look only at the active version. The easiest way is through is_active = true and, if needed, through a pointer to the current version_id. If there is no such filter, archive chunks will eventually return in results even if their ranking is slightly lower.
It is better not to keep old chunks in the general retriever. The archive should be moved to a separate namespace, a separate index, or at least a different search class. Otherwise someone will forget to add the filter in one request, and outdated text will end up in the context again.
After an update, clear the cache as well. This is a common trap: the index is already fresh, but the user still gets the old answer from the response cache, the reranker cache, or an intermediate application layer. It is better to tie the cache at least to doc_id and version_id, and when a document is replaced, wipe the entries for that entity.
Physical deletion is more reasonable to run separately, for example at night or once a week. Deleting the archive immediately is risky: sometimes the team needs rollback, auditing, or a check that the new version did not break search.
When you need a new embedding
Embeddings do not need to be recalculated for the whole corpus every time a document is edited. If the change is local, recalculate only the chunks where the meaning changed. This saves time and does not break search where nothing happened.
One simple rule helps here: keep chunk boundaries stable whenever possible. If today a paragraph landed in one fragment, and tomorrow a small insertion shifted all the boundaries below it, you will have to recalculate too much data. With stable splitting, only the needed parts change, while neighboring chunks stay in place.
A small edit does not always require a new embedding. If you fixed a typo, updated a decree number, or slightly rewrote a sentence without changing the meaning, the old vector is often fine. But if the document changes the answer to a user’s question, the chunk is different in meaning and needs to be recalculated.
A good practical rule looks like this. Style, spelling, and formatting usually do not require a new embedding. A new deadline, limit, rate, fact, or rule does. If you insert a new paragraph into a section, recalculate that fragment, but do not touch its neighbors without a reason. If the document structure is rewritten, headings change, and the meaning of the sections changes too, it is cleaner to rebuild the whole document.
Teams often overcompensate and recalculate a few neighboring chunks around the edited area just in case. Usually that is unnecessary. If the neighboring fragment kept the same text and the same meaning, leave it alone.
After the update, check not only precision but also recall. A new chunk may be too narrow, and search may stop finding it through older question wording. That often happens after aggressive splitting. If users can no longer find the right answer with the usual question, the problem is often not the model, but the way the fragments were updated.
An example with one changed policy
Let’s take a bank policy for storing customer requests. In the new revision, only section 4 changed: the retention period increased from 30 to 90 days. The other sections, which describe staff roles, the log format, and the approval process, stayed the same.
If you update the knowledge base for the entire document, the system will often recalculate all chunks one after another. That is extra work. In this case, it is enough to compare the old and new versions by chunks and update only the piece where the text really changed.
Suppose the document is split into 6 chunks. After comparing them, you can see that fragments 1, 2, 3, 5, and 6 did not change. Only chunk 4 changed because it now contains the new retention period. That means a new embedding is needed only for it. The old version of that chunk should leave active search results.
It is important not just to add the new fragment. If you leave the old revision without an inactive status, search will still sometimes surface both versions. Then the model sees a conflict: one fragment says 30 days, another says 90. The answer becomes random, and that is worse than a slow index.
In practice, a simple link helps: each chunk has document_id, section_id, and version_id. Only records with the active version take part in normal search, and the previous one is closed by date or flag. Then the old revision does not participate in retrieval, but stays in history for auditing.
The check is simple too. Before the update, the question How long should customer requests be stored? returned old chunk 4 and the answer 30 days. After the partial update, the same question should return the new chunk 4 and the answer 90 days.
It is also worth checking neighboring questions. For example, Who approves archive deletion? should still pull chunk 5 without changes. That is a good sign: you removed the stale answer but did not touch the stable parts of the document.
Mistakes that most often break freshness
Knowledge base freshness is more often broken by small pipeline mistakes than by models. The document has already been updated, the new chunks have already been calculated, but search still pulls the old revision and builds an answer from both versions at once.
Usually the cause is one of a few things. The team recalculated embeddings but did not update version_id, is_active, or the filter for the current revision. Old chunks are turned off too late, and for a while search sees both versions. With each import, the system creates new doc_id and chunk_id, so it loses the link between the old and new document. Sometimes one small edit triggers a full index recalculation, wasting hours and creating extra room for errors. And people also often forget to clear search cache, answer cache, or old index snapshots.
In practice, this feels very unpleasant. You updated a leave policy where the approval time was shortened from 5 days to 2, the vector database already stores the new text, but the answer cache still holds yesterday’s result, and the version filter is not working. The user asks the question and gets the old number, even though the document has already been fixed.
The most common mistake is breaking identifiers. If doc_id changes on every import, the system does not understand that this is the same document in a new revision. Old chunks are not removed from publication and pile up next to the new ones. That is why it is better to keep a permanent doc_id for the document entity and a separate version_id for each revision.
Full reindexing for a single edit also hurts freshness. While you are running the whole corpus, one part of the index is already new, another is still old, and the update queue keeps growing. If one section changed, it is usually enough to recalculate only the affected chunks and neighboring fragments only if the splitting boundaries really shifted.
Teams often make cache mistakes twice: either they do not clear it at all, or they wipe everything. It is better to do a targeted reset by document, version, or question set. Otherwise you either keep stale answers or lose speed for no reason.
Pre-launch check
Before release, it is not enough to make sure the index built without errors. It is much more important to check whether old pieces of text are still present in search. This is where the problem most often appears: the new version is already loaded, but the answer still pulls a quote from the previous revision.
The check can be very short. The document should have a permanent document_id, the version should have its own number, date, or hash, the search layer should return only current chunks, and the cache should either account for the document version or invalidate correctly. You also need a small test set of questions where the old quote shows up immediately: deadlines, limits, rates, field names, process steps.
If even one of these points is missing, it is better to delay the release by an hour than spend the whole day figuring out why production is answering from an old instruction.
Imagine a returns policy where the deadline changed from 14 to 30 days. After the incremental update, ask a direct question: How many days do I have for a return? If the answer or quote still contains 14 days, the problem is almost always in one of three places: the old version was not deactivated, the version filter did not work, or the cache returned the previous result.
It is also useful to check metadata manually. The found chunks should have matching document_id, current version_hash, and freshness flag. Old chunks can be kept for auditing, but search should not see them without an explicit request.
If the team compares several models, it is better to keep the retrieval layer unchanged and change only generation. In that setup, it is convenient to use a single OpenAI-compatible gateway like AI Router on airouter.kz: you can keep the same SDKs, code, and prompts, while model comparison becomes cleaner. It also makes it easier to control audit logs and cache rules in one place.
What to do after the first rollout
After the first rollout, do not touch the entire document corpus. Pick one source where changes are visible right away: policies, an internal knowledge base, or a contract catalog. That way you will understand faster whether incremental reindexing works, and you will not drown in noise.
Metrics should be collected from day one. Otherwise, in a week you will see that the system seems to update, but you will not know where it is breaking. At the start, four indicators are enough: how many minutes pass from a document change to new search results, how often search surfaces an old chunk version, how much one partial update costs, and how many documents the system skipped or processed twice.
If you already have a test set of questions, run it after every update. The same setup may work well on new documents and still pull old answers from the cache, the index, or an intermediate version table.
Freshness control is better built into the normal release cycle. When the team ships a new parser, changes chunking, or edits deletion rules, the release should include a short test: update a document, wait for the refresh, and make sure the old version no longer appears in search.
It is also useful to compare full and partial recalculation in numbers. If 2-3% of the base changes every day, full reindexing often just burns the budget. Look not only at embedding costs, but also at queue length, index readiness time, and the number of unnecessary deletion operations.
For teams in Kazakhstan, there is another practical question: where the source documents, index, logs, PII masking, and version tables are stored. A RAG setup often looks local only on the diagram, while part of the data actually leaves the country. It is better to check that in advance, not after launch.
A good result looks simple: a fresh document quickly appears in search, the old chunk does not resurface in results, and the cost of updates stays predictable. When this works reliably on one source, you can connect the next one.
Frequently asked questions
Why does RAG still answer from the old version after a document update?
Most often, both versions live in the index at the same time. Search finds old chunks almost as confidently as new ones, and the model builds an answer from both versions.
Store the document and its revision separately. First load the new version, verify it, then disable the old one with is_active = false or a filter for the current version_id.
What is the difference between `source_id` and `version_id`?
source_id describes the document itself and does not change because of a new upload, file name, or folder. version_id describes one specific revision of that document.
This setup makes it easy to see which version is active now, what moved to the archive, and which revision the system answered from before.
What fields should you store for a document and a chunk?
Usually source_id, version_id, text_hash, metadata_hash, updated_at, and is_active are enough. For chunks, add a link to the document and version so you can quickly disable old fragments.
If you want to debug failures more easily, also store who made the change and the type of edit, for example metadata_only or text_changed.
When is a partial update enough, and when should you rebuild the whole document?
If the meaning of the answer changed, recalculate only the affected chunks. That way you do not waste money on embeddings or touch stable parts of the corpus.
It makes sense to rebuild the whole document when the structure shifted, headings changed, or chunk boundaries moved so much that a targeted update no longer gives a clean result.
How do you remove old chunks without stopping search?
First write the new version to the index and make sure search can see it. Then switch the previous revision to an inactive status in one step.
That way search does not go blind during the update and does not start mixing old and new fragments. Physical deletion is better done later, outside the main traffic.
Do you need to recalculate the embedding after a small edit?
Not always. If you fixed a typo, formatting, or a decree number without changing the meaning, you can often keep the old vector.
When a term, limit, tariff, rule, or any fact a user asks about changes, create a new embedding for that chunk.
What should you do with the cache after a document update?
Clear the cache selectively, not all at once. Tie entries to doc_id and version_id so that when a document is replaced, you remove only the affected answers and search results.
If you leave the old cache in place, the user will see yesterday’s answer even with a fresh index. If you clear everything, you lose speed for no reason.
How can you quickly check that the fresh version really made it into search?
Ask a direct question about the changed part of the document and check not only the answer, but also the chunk that was found. Its current document_id, version_id, or version_hash should match, and the old fragment should not appear in retrieval.
Also run adjacent questions where the text did not change. If those still work as before, the update was clean.
Why does full reindexing often make things worse?
It creates a long queue, burns budget on the entire corpus, and increases the risk of mixing old and new data in one index. For one change in one policy, this approach creates more noise than value.
Incremental updates are calmer: you change only what actually changed and control freshness more easily.
Where should you start if you do not have incremental updates yet?
Start with one source where mistakes are easy to spot, such as policies or an internal help guide. Add a permanent source_id, a separate version_id, an active-version filter, and a test set of questions about deadlines, limits, and rules.
Then measure the time from document edit to new search results, the share of old chunks in search, and the cost of a partial update. Once the setup works reliably on one set, expand it further.