Separating prefill and decode for long documents
We look at when separating prefill and decode reduces latency on long documents, and when it only adds extra queues, risk, and cost.
Why long documents create a bottleneck
The problem starts before the answer is even generated. When a model receives a long contract, an instruction manual, or a large chat history, it first has to process the entire input. This stage is called prefill. The more tokens there are in the input, the longer the GPU is tied up just reading and preparing the model’s internal state.
In a short chat, this is barely noticeable. But with a 80- or 150-page document, the difference is already huge: one such request can keep resources busy longer than dozens of short questions from support, knowledge base search, or a regular in-product assistant.
Because of that, not only the long request suffers. If short and long tasks go through the same queue, the heavy input starts slowing everyone down. Even with moderate traffic, latency grows faster than the team expects. Sometimes just a few large requests in a row are enough.
The most unpleasant effect shows up in TTFT, time to first token. The user is not waiting for a long, polished answer yet. They just want to know that the system has started responding at all. But decode will not begin until resources are free from prefill or until the queue reaches that request. The interface stays silent, even though generation itself may be fast later.
This is easy to see in an internal assistant for lawyers. One employee sends a long contract for review, while other people ask short questions like: “What penalty is listed in clause 7?” or “Compare these two versions of the paragraph.” If all of that lands in one GPU pool, the long document pushes back response times for the whole team.
That is why separating prefill and decode makes sense. The bottleneck is often not that the model writes slowly, but that it spends too long reading a long context on shared resources.
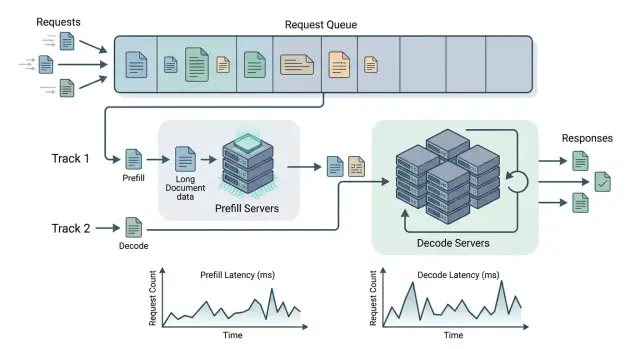
What changes when prefill and decode are separated
When the same GPU pool both reads the long input and generates the answer, long requests get in the way of everything else. A large contract or a batch of instructions consumes memory and time where the system could already be sending tokens back to the user.
After separation, the load is split across two pools. Prefill resources process the long text and prepare the model state, while decode resources handle only step-by-step generation. This changes not just the launch setup, but also queue behavior.
These stages have different load profiles. Prefill handles large chunks of input better and can tolerate a short pause if it then processes a large context quickly. Decode, on the other hand, is sensitive to any interruption. The user immediately notices if tokens arrive unevenly or if the first answer appears too late.
Because of that, the team stops looking at one overall latency number and starts breaking the request path into stages: prefill wait, prefill time, state transfer, decode wait, and generation itself. That breakdown is much more useful than just saying “response in 9 seconds.”
In practice, this quickly changes the conversation inside the team. If time to first token has increased, you can already tell why: long inputs are clogging the prefill pool, or decode nodes are busy with other sessions. Without separation, those two problems blur together, and the team often fixes the wrong thing.
A simple example: a lawyer sends an 120-page contract to an LLM and asks it to find risky clauses. In a shared queue, that request can easily delay short support chats. With separation, a dedicated pool handles the whole document, while the response generation runs on other resources that are not stuck waiting on long inputs.
For an LLM gateway like AI Router, this is also a routing issue. If requests go through one OpenAI-compatible layer, it becomes easier to see where capacity is missing for long context and where decode is already the bottleneck. Then the problem stops looking like a vague “the model is slow” and becomes a clear map of bottlenecks.
When this setup really helps
Separating prefill and decode is useful when the model spends much longer reading than answering. If a user asks a single question about a 150-page contract, most of the time goes into the input itself. In that case, splitting the stages across different resources often brings a real gain.
You can usually see it in TTFT. The user has not seen a single token yet, but the GPU is already busy handling a large context. If traces show that almost all the time is spent in prefill, the setup starts to make sense.
It works best when the input is long and the output is short. For example, a service reads a contract, a report, a form, or a medical record, then answers in a few sentences: whether the needed clause was found, whether there is risk, which data is missing, or what does not match the template.
There are a few common signs that this setup is a good fit:
- documents are large, but answers are short;
- input length varies a lot from request to request;
- users often upload contracts, reports, forms, or medical records;
- the problem is visible in TTFT, not in total response length;
- monitoring shows that prefill is more loaded than decode.
A wide spread in input size matters a lot. If one request arrives with 3,000 tokens and the next with 120,000, the shared pool starts to behave unevenly. Short requests wait beside long ones, and latency grows even where it should not. A dedicated prefill resource smooths out that queue.
The same lawyer assistant is a good example. In the morning, it gets short questions about templates, and in the afternoon, employees upload scanned contracts and long attachments in bulk. Without separation, one heavy batch of documents can easily slow everyone down. With separation, prefill takes care of reading and preparing the context, while decode returns short answers without an extra pause.
In systems with routing, this is especially visible. Heavy prefill can be sent to a more suitable resource, while decode stays on a low-latency group. That approach is useful when predictability matters: users forgive a short answer, but they do not tolerate long silence before the first token.
If the metrics do not show a clear prefill skew, the scheme is unlikely to pay off. But when the service mostly reads long documents and gives short conclusions, the effect is usually visible quickly.
When it only adds complexity
Separating prefill and decode does not bring value on its own. If almost all requests are short, you are just building a more complex setup with no noticeable gain. The system gets more failure points, more queues, and more reasons for strange latency.
A common mistake looks like this: the team notices rare long documents and rebuilds the whole inference setup ahead of time. But if 90% of traffic has short context, a dedicated prefill pool will sit idle. New routing rules, separate limits, new alerts, and extra debugging appear, while response time barely changes.
Another bad scenario is when the system bottlenecks not on the input, but on decode. That happens if the document is not very long, but the answer has to be detailed: a one-page summary, a thorough explanation, or a long JSON. Then the expensive part of the request starts after prefill. You speed up the smaller part of the pipeline, but the user still waits almost the same amount of time.
Steady traffic also changes the picture. If there are no sharp spikes, one shared pool often works better than two specialized ones. It is easier to manage and usually stays more evenly utilized. Separate pools can easily create the opposite effect: one is underused, the other overheated.
The worst idea is to introduce this setup without stage-level metrics. If the team does not measure TTFT, prefill duration, decode speed, queue length, and the delay between pools, the discussion quickly turns into guesswork.
Then it is easy to mistake a network hop for an optimization. In practice, the extra hop between pools, state serialization, and repeated limit checks can eat up the entire gain. Sometimes that is only a few dozen milliseconds per request, but on a steady stream they add up fast.
If the team already uses a single gateway like AI Router to work with different models, internal separation should only be introduced after measurement. Otherwise support becomes harder to follow: incidents are more difficult to debug, bottlenecks are harder to find, and it is harder to explain where the time went.
When context is short, decode dominates, and traffic is predictable, the simpler setup usually wins.
How to implement the setup step by step
Start by measuring the baseline. Without it, you will have nothing to compare against. Measure TTFT, generation speed in tokens per second, and the real input length. Look not only at the average, but also at p95: long documents usually hurt the tail of latency the most.
Then split traffic into simple context ranges. You do not need ten classes right away. Usually three buckets are enough: short requests, medium ones, and long ones. If you have lots of contracts, reports, or long message threads, the boundary for long inputs will usually become clear fairly quickly.
After that, spin up two small pools. One handles prefill, meaning reading the long input and building state. The other handles decode, where steady token output matters. At the start, do not move all traffic. Take only part of the long requests so you can see the difference without getting lost in debugging.
The routing rule should stay simple. For example: short input goes through the old path, long input goes to a separate prefill pool, decode always stays in its own pool, and if there is an error, the request falls back to the regular route. This is easy to test and easy to roll back.
If you already have a single OpenAI-compatible gateway, it is better to keep the logic in one place rather than duplicate it across services. That reduces drift between teams and makes testing easier.
Next, check behavior in two modes: during peak hours and during quiet hours. At peak, the setup often improves TTFT for long documents. In quiet periods, it can cost more because of the idle pool and the extra switching.
Do not look only at average latency. Compare cost per thousand requests, GPU utilization, timeout rate, and p95 TTFT. Sometimes the first token arrives faster, but the overall bill rises by 15-20%, and support becomes noticeably more complex.
A normal test feels boring, and that is a good sign. If, after a week of measurements, the win is visible only in the lab and not in live traffic, do not push the scheme to production.
A simple long-contract scenario
Imagine a bank uploads a 120-page contract and asks the model to review it against 12 points: where the penalty risk is, how termination is written, who changes the pricing, what the notice periods are, and where the wording is too vague. For a person, this is a normal legal review. For an LLM, it is a heavy request with a long context.
The longest part here is not the answer, but reading the document. During prefill, the model processes the entire contract text and builds internal state. That takes noticeable time and puts more load on the GPU than the short generation that follows.
Then decode begins. The model is no longer rereading the contract, but writing the output: 12 points with risk markers and short explanations. The answer may take one or two pages. In other words, the input is huge, while the output is relatively small.
If requests like this go through the same resource as ordinary queries, the queue gets messy quickly. One heavy prefill can delay short tasks: email summaries, customer chat analysis, or ticket classification. The user gets a slow answer even where the text was small and the task was simple.
This is where separating prefill and decode can really help. The contract goes to a resource designed for long reading, while answer generation runs on another resource where low latency matters. In a single LLM gateway, this is especially useful when long documents and regular chat requests live side by side. One contract stops holding the whole flow hostage.
But the setup has a cost. If documents like this arrive rarely, say only a few times a week, the extra work may outweigh the benefit. You will need separate resource pools, state transfer between stages, retries, metrics, and debugging. For rare tasks, it is often easier to cap the queue for long requests or move them to a separate route.
The takeaway is simple: the more often very long documents appear in the system, the more sense it makes to have a separate prefill resource. If the traffic is rare, the setup looks nice on a diagram but quickly becomes annoying to support.
Mistakes that break the setup
Most often, the team breaks everything at the observability level. It combines prefill and decode into one total-latency chart and gets a pretty average number. The problem is that such a chart hides the reason: prefill is already clogged with long context while decode is barely affected, or the other way around.
If the metrics are mixed, you cannot see where the queue is growing or what is hurting the user experience. At minimum, keep these four signals separate: queue before prefill, prefill time, decode speed, and p95/p99 split for short and long requests.
Averages almost always comfort people for the wrong reason. Users do not notice average latency; they notice the rare response that froze for 18 seconds.
The second common mistake is sending every long request to the new pool without a clear threshold. Length alone does not mean a request needs separation. A 9,000-token input may pass through a shared pool just fine, while a 60,000-token contract with a heavy system prefix will clog prefill for a long time. If the threshold is chosen by feel, you are just moving extra traffic into a new branch.
Another problem is a dedicated pool that is too small. The team removes the queue from the shared pool and immediately creates a new one somewhere else. On paper, the architecture looks smarter. Under real load, long documents simply line up in another queue, and p95 gets worse.
People also often forget prompt cache. That is an expensive mistake. If your system repeats instructions, answer templates, legal disclaimers, or the first pages of a standard contract, cache can sometimes bring more value than a separate pool. And it is easier to maintain.
A good example is processing a long contract. If every request reruns the same prefix with rules, classifiers, and system text, prefill wastes time needlessly. At that point, the team may think it needs a new routing scheme, when the first step should have been removing the repetition.
A bad sign is easy to spot: the system became more complex, but the cause of the latency is still unclear. If you do not see prefill and decode separately, do not measure p95 and p99, and have not checked the cache, separation quickly turns into an expensive tuning exercise with an extra queue.
A quick check before launch
This setup should be enabled based on numbers, not feeling. If the team does not understand where the time goes, separating prefill and decode quickly becomes another support layer that is hard to explain and even harder to fix.
Before launch, it helps to check a few things. First, see what share of latency is spent in prefill. If more than half of the total time sits there, the test makes sense. If the main pain is already in decode, the gain will be modest.
Then compare input length and output length. When the average answer is several times shorter than the source document, separate resources for prefill often make a noticeable difference. After that, assess the spread in request length. If one request carries 3,000-5,000 tokens and another 30,000-50,000, the shared pool almost always behaves unevenly. A difference of at least 5-10x is already a reason to test the split setup.
You should track not just one metric, but at least three: TTFT, throughput, and queue length. If TTFT drops but the decode queue grows, it means you only moved the bottleneck elsewhere. And before launch, you need a simple rollback to one pool. Switching should take minutes, not a full sprint.
A good sign looks like this: users send long contracts, reports, or message threads, the model reads a large input, and then responds briefly and directly. In this mode, prefill stresses the system more than answer generation. Then separation can noticeably cut time to first token and make the queue smoother.
A bad sign is easy to recognize too. If documents are similar in length, answers are just as long, and the team is only looking at average latency, the scheme will bring little benefit. It will add new routing rules, new queues, and more failure points.
For teams that already run production LLM workflows through a single API gateway, the check usually comes down to request logs and a couple of load tests. That is enough to answer a simple question: are you really fixing prefill, or just making the application architecture more complicated?
What to do next
Do not roll out prefill-decode separation across all traffic at once. Pick one type of long document where the input is fairly stable: 80-150 page contracts, tender packages, or long medical discharge summaries. Run an A/B test on part of the traffic and compare the normal route with the split setup on the same prompts.
Do not look only at average latency. On long documents, averages often mislead: one fast run hides a slow prefill during peak hours. Break the measurements down by model, input length, total request cost, and time to first token. Separately note routing errors, repeated prefill, and cases where decode waits for a free resource longer than you save.
It helps to build a simple table: model and provider, input length in tokens, prefill and decode time, total response cost, and the share of requests where the setup helped. After a few days, it becomes clear where long context truly justifies a more complex architecture and where it does not. Usually the boundary is not by industry, but by document length and how often the same text is queried again.
If documents cannot be stored outside the country, there is another question you should not postpone: do you need local hosting for open-weight models? For banks, the public sector, and part of healthcare, this is a normal requirement. In that case, it is worth comparing not only cloud routes, but also a local setup for open-weight models.
If the team is testing several routes at once, do not create separate integrations for each provider. If you already have a stack built around the OpenAI API, AI Router can simplify this test: just change the base_url to api.airouter.kz and send the same SDKs, code, and prompts through one OpenAI-compatible endpoint. For experiments, that is convenient: less time goes into glue code, and logs and audit are easier to review in one place.
A good result from this stage looks plain, and that is a good thing. You end up with a threshold for input length, a list of models for prefill and decode, and a clear answer about where the setup saves seconds and money, and where it only makes the system more complicated.
Frequently asked questions
When does separating prefill and decode actually help?
Split the stages when the service reads a very long input but gives a short answer. This is usually contracts, reports, forms, and medical records, where TTFT grows because of context reading, not generation itself.
How can I tell that prefill is the bottleneck?
Look at stage-level traces. If most of the time is spent before the first token, and prefill is more loaded than decode, the problem is almost certainly in the input stage.
Is there any point in this setup if most requests are short?
Usually no. If almost all traffic is short and predictable, one shared pool is simpler, cheaper, and more stable.
What should we do if long documents arrive rarely?
In that case, start with a separate route or cap the queue for heavy requests. Keeping a permanent dedicated pool for just a few documents a week is usually not worth it.
Which metrics should we capture before launch?
Look at TTFT, p95 and p99, input length in tokens, prefill duration, decode speed, and queue length. Averages alone do not show much, because long documents hurt the tail of latency.
Will the scheme help if the model’s answer is long too?
Probably not much. If the model later spends a long time writing a summary, a large JSON, or a long explanation, decode becomes the bottleneck itself.
How can we introduce separation without too much risk?
Roll it out to a slice of traffic and keep a fast rollback to the old path. Usually a simple rule is enough: long inputs go through a separate prefill pool, everything else stays on the regular route.
What mistakes most often break this setup?
The most common mistakes are mixing prefill and decode metrics into one chart and losing sight of the cause of latency. Other problems are a length threshold chosen by feel, a pool that is too small, and an extra network hop between stages.
Can prompt cache be more useful than separating pools?
Yes, often. If you repeat system instructions, response templates, or the same parts of a document, cache removes extra prefill more simply than a new architecture.
How does a single gateway like AI Router help test this idea?
When traffic goes through one OpenAI-compatible layer, it is easier to compare routes and see where prefill or decode gets stuck. In AI Router, you can keep the same SDKs, code, and prompts and change only the base_url, while keeping logs and audit in one place.