Блог
Практические материалы об архитектуре LLM-приложений, маршрутизации моделей, оптимизации затрат и продакшен-эксплуатации AI-систем.
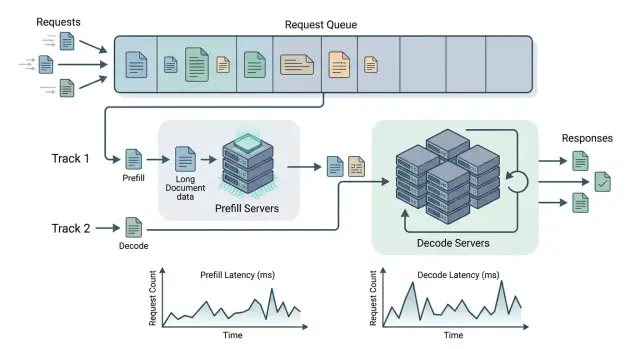
разделение prefill и decodeдлинный контекст LLMзадержка инференса
Разделение prefill и decode для длинных документов27 апр. 2026 г.·11 мин чтения
Разбираем, когда разделение prefill и decode снижает задержку на длинных документах, а когда добавляет лишние очереди, риски и расходы.
Свежие материалы
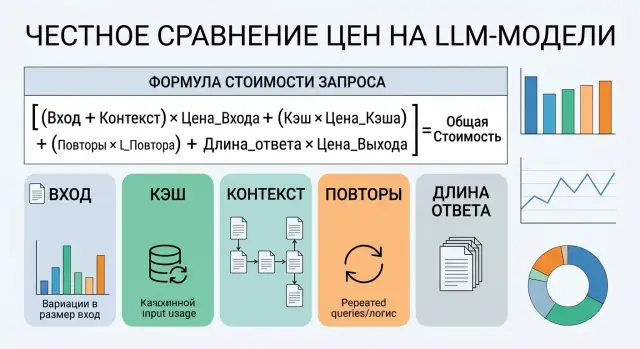
26 апр. 2026 г.·6 мин чтения
Как сравнивать цены на LLM-модели без ошибки в расчетах
Как сравнивать цены на LLM-модели: считайте цену входа, кэша, контекста, повторов и длины ответа, а не только ставку за миллион токенов.
как сравнивать цены на LLM-моделицена за миллион токенов

22 апр. 2026 г.·8 мин чтения
Версионирование схем инструментов без поломки агентов
Версионирование схем инструментов помогает менять поля и правила без сбоев: как вводить версии, сохранять совместимость и ловить ошибки заранее.
версионирование схем инструментовобратная совместимость API

20 апр. 2026 г.·9 мин чтения
Перевод LLM в продакшен: что проверить после пилота
Разбираем перевод LLM в продакшен после пилота: лимиты, наблюдаемость, доступы, выбор моделей, частые ошибки и короткий список проверок.
перевод LLM в продакшеннаблюдаемость LLM
09 апр. 2026 г.·10 мин чтения
Code-switching в чатах: что ломается в русско-казахском диалоге
Code-switching в чатах часто ломает смысл, тон и факты в ответах. Эта схема проверки до релиза помогает поймать сбои на русско-казахских диалогах.
code-switching в чатахрусско-казахские чаты

06 апр. 2026 г.·11 мин чтения
Каталог моделей внутри компании: статусы и правила
Каталог моделей внутри компании помогает командам видеть статус, доступ и сроки вывода моделей, чтобы не выбирать их вслепую.
каталог моделей внутри компаниистатусы моделей

01 апр. 2026 г.·8 мин чтения
Тестирование галлюцинаций LLM для банка, клиники и госуслуг
Тестирование галлюцинаций LLM для банковских, медицинских и государственных ответов: шкала риска, сценарии проверок, частые ошибки и чек-лист.
тестирование галлюцинаций LLMшкала риска для ответов ИИ
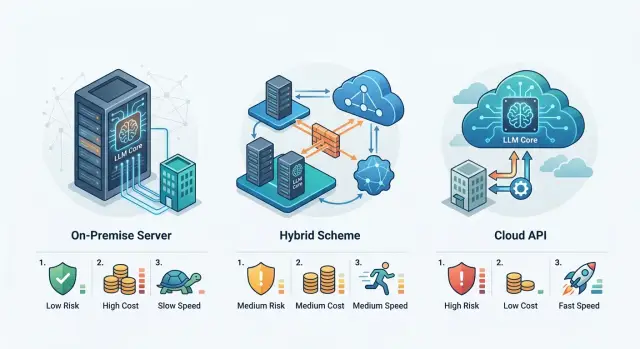
01 апр. 2026 г.·7 мин чтения
Хранение данных в стране для LLM: локально, гибрид или API
Хранение данных в стране для LLM помогает сравнить локальный хостинг, гибридный контур и внешний API по рискам, цене и срокам запуска.
хранение данных в стране для LLMлокальный хостинг LLM
29 мар. 2026 г.·7 мин чтения
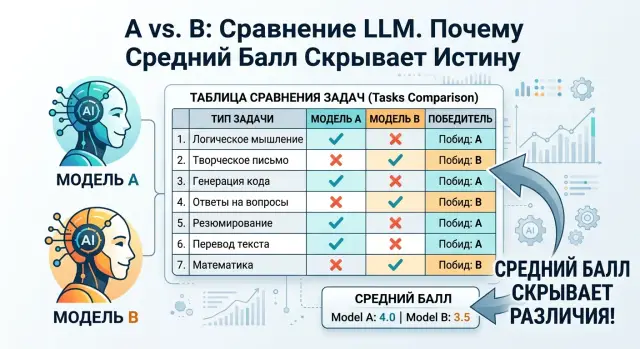
Парные сравнения моделей: где A лучше B без среднего балла
Парные сравнения моделей показывают, где одна LLM выигрывает на извлечении данных, а другая - на диалогах, суммаризации и длинных ответах.
парные сравнения моделейоценка LLM по задачам
28 мар. 2026 г.·10 мин чтения
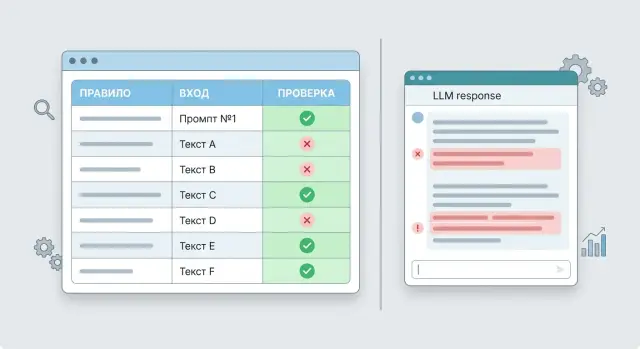
Юнит-тесты для промптов: как ловить ошибки до релиза
Юнит-тесты для промптов помогают проверять правила, шаблоны и граничные случаи без долгого чтения ответов. Покажем формат тестов и простой чек-лист.
юнит-тесты для промптовтестирование промптов
25 мар. 2026 г.·6 мин чтения
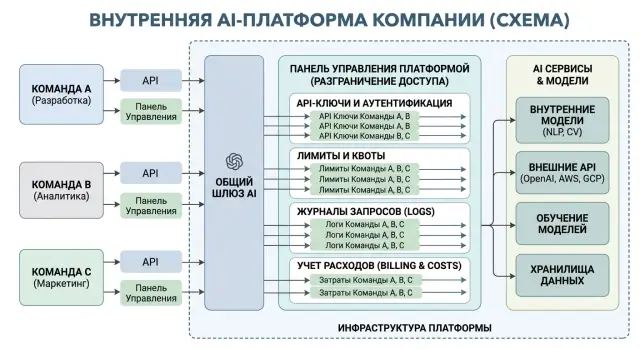
Мультиарендность в AI-платформе без лишних сервисов
Мультиарендность в AI-платформе помогает разделить ключи, лимиты, логи и расходы между командами без отдельного набора сервисов.
мультиарендность в AI-платформеразделение API-ключей
21 мар. 2026 г.·9 мин чтения
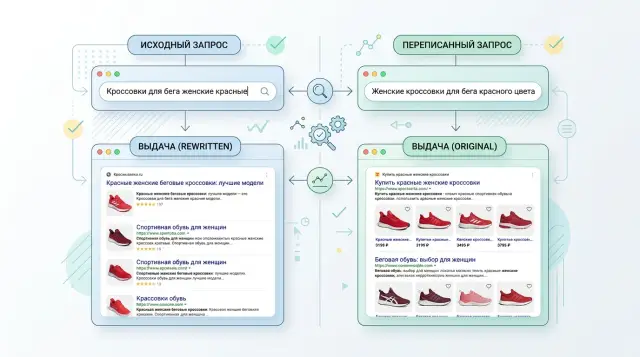
Тестирование query rewrite: как не потерять смысл запроса
Тестирование query rewrite помогает понять, когда переписанный запрос улучшает выдачу, а когда уводит смысл. Разберем метрики, тесты и ошибки.
тестирование query rewriteоценка переписывания запросов
21 мар. 2026 г.·7 мин чтения
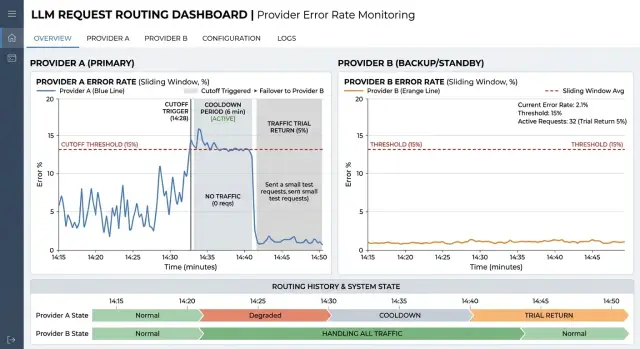
Автоматическое отсечение провайдера при сбоях без флаппинга
Автоматическое отсечение провайдера при сбоях снижает каскадные ошибки: разберем окна ошибок, пороги, возврат трафика и быстрые проверки перед продом.
автоматическое отсечение провайдера при сбояхокно ошибок
18 мар. 2026 г.·11 мин чтения
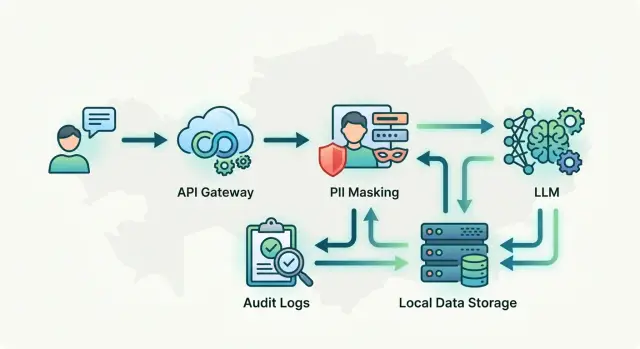
Хранение данных в Казахстане для LLM без лишней сложности
Хранение данных в Казахстане для LLM: простая схема вызовов, логов и маскирования PII под местные требования без лишних слоев.
хранение данных в КазахстанеLLM-архитектура
13 мар. 2026 г.·6 мин чтения
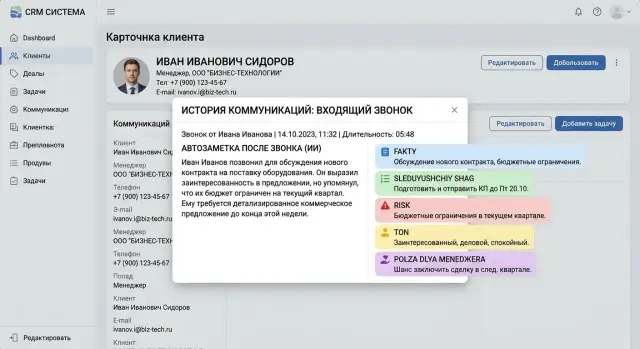
Автозаметки в CRM: как оценить полноту, тон и пользу
Автозаметки в CRM стоит проверять не по гладкости текста, а по фактам, тону и пользе для менеджера. Разбираем критерии, ошибки и чек-лист.
автозаметки в CRMоценка заметок после звонка
07 мар. 2026 г.·10 мин чтения
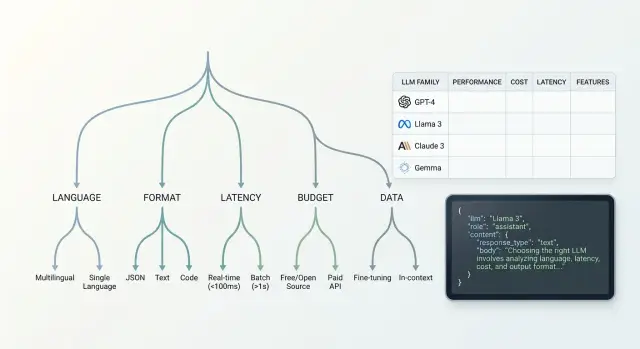
Выбор семейства моделей под новую функцию: дерево решений
Выбор семейства моделей для новой функции: разберем дерево решений по языку, формату ответа, задержке, бюджету и требованиям к данным.
выбор семейства моделейдерево решений для LLM

07 мар. 2026 г.·11 мин чтения
Лимиты на шаги для AI-агентов и контроль расхода в продакшене
Лимиты на шаги для AI-агентов помогают держать расход под контролем: задайте бюджет на сессию, ретраи по правилам и условия остановки.
лимиты на шаги для AI-агентовбюджет на сессию
28 февр. 2026 г.·7 мин чтения
Dense, sparse и hybrid retrieval: как честно сравнить
Dense, sparse и hybrid retrieval можно сравнить честно, если заранее выровнять корпус, запросы, метрики и правила чанкинга для разных типов документов.
dense, sparse и hybrid retrievalчестный тест retrieval
16 февр. 2026 г.·10 мин чтения
Вызов инструментов через несколько провайдеров без сюрпризов
Вызов инструментов через несколько провайдеров часто ломается на схемах, типах и кодах ошибок. Разберём, что проверить до продакшена.
вызов инструментов через несколько провайдеровtool calling у LLM
15 февр. 2026 г.·10 мин чтения
Разделение доступа к промптам и данным: схема ролей
Разделение доступа к промптам и данным снижает риск утечек логов, помогает настроить роли для команды и не мешает обычной разработке.
разделение доступа к промптам и даннымроли доступа для LLM

10 февр. 2026 г.·6 мин чтения
Вопросы провайдеру LLM перед договором: что уточнить
Вопросы провайдеру LLM помогут заранее проверить логи, хранение данных, обновления моделей и порядок действий при сбоях и инцидентах.
вопросы провайдеру LLMдоговор с LLM провайдером
10 февр. 2026 г.·8 мин чтения
Tail latency у LLM: как найти медленные 1% запросов
Tail latency у LLM часто прячется в длинных промптах, холодных моделях и инструментах. Покажем, как найти медленные 1% и убрать узкие места.
tail latency у LLMмедленные запросы LLM

08 февр. 2026 г.·7 мин чтения
OCR или vision-модель для документов: как выбрать
OCR или vision-модель для документов - выбор зависит от качества скана, таблиц, печатей и структуры страницы. Разберем признаки и простой порядок проверки.
OCR или vision-модель для документовмультимодальный ввод документов

05 февр. 2026 г.·10 мин чтения
Микробатчинг LLM-вызовов: как снизить цену без срыва SLA
Микробатчинг LLM-вызовов помогает снизить цену внутренних задач без лишней задержки. Разберем, где пачки уместны, как держать SLA и что мерить.
Микробатчинг LLM-вызововснижение стоимости LLM
03 февр. 2026 г.·11 мин чтения
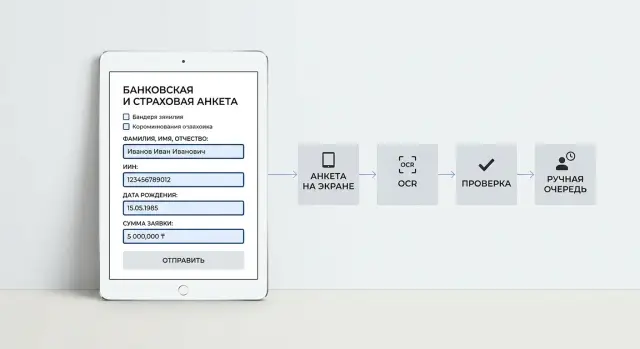
Извлечение полей из заявлений: OCR, проверка и ручной разбор
Показываем, как настроить извлечение полей из заявлений: выбрать OCR, проверить данные, отправить спорные случаи на ручную проверку и снизить ошибки.
извлечение полей из заявленийOCR для анкет
28 янв. 2026 г.·10 мин чтения
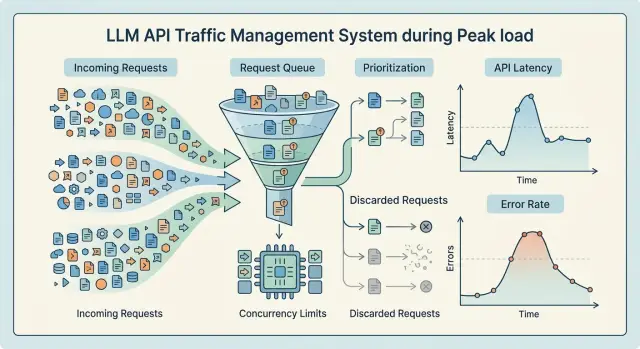
Backpressure для LLM-сервиса без каскадной аварии
Backpressure для LLM-сервиса помогает пережить пики нагрузки: разберём очереди, лимиты и сброс второстепенных запросов без каскадной аварии.
backpressure для LLM-сервисаочереди запросов LLM

25 янв. 2026 г.·8 мин чтения
OCR перед LLM: как мерить потери на сканах документов
OCR перед LLM помогает читать сканы договоров и медформ, но ошибки копятся. Разберём метрики, пороги проверки человеком и простой процесс.
OCR перед LLMсканы договоров

24 янв. 2026 г.·7 мин чтения
Аудит-логи для LLM: что хранить банку и госсектору
Аудит-логи для LLM помогают банку и госсектору разбирать инциденты: что писать в событие, сколько хранить записи и кому давать доступ.
аудит-логи для LLMсостав события LLM
23 янв. 2026 г.·9 мин чтения
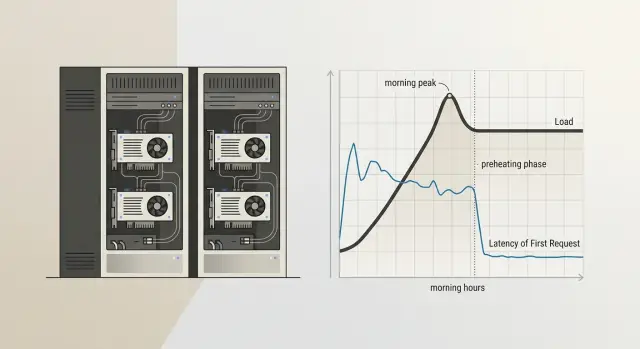
Холодный старт self-hosted модели: как убрать задержки
Холодный старт self-hosted модели дает лишние секунды на первом запросе дня. Разберем прогрев, пул копий и расписание без лишних затрат.
холодный старт self-hosted моделипрогрев модели
20 янв. 2026 г.·8 мин чтения
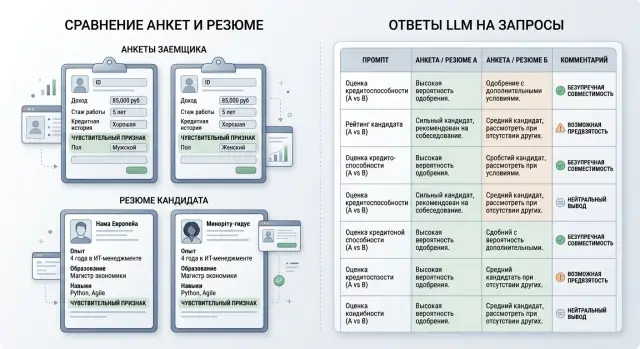
Тест на предвзятость: какие пары кейсов прогонять до запуска
Тест на предвзятость перед запуском LLM в скоринге и найме: какие парные кейсы собрать, что менять в паре и как проверить ответы модели.
тест на предвзятостьпарные кейсы для LLM

17 янв. 2026 г.·9 мин чтения
Реестр изменений API у LLM-провайдеров без боевых сбоев
Реестр изменений API помогает вовремя замечать новые поля, лимиты и снятие методов, чтобы проверять интеграции до сбоев в продакшене.
реестр изменений APIизменения API LLM

15 янв. 2026 г.·8 мин чтения
Модели для ассистента на русском и казахском: как выбрать
Разбираем, как выбрать модели для ассистента на русском и казахском: что проверить на смешанных запросах, смене языка и задачах бизнеса.
модели для ассистента на русском и казахскомсмешанные запросы для LLM

14 янв. 2026 г.·8 мин чтения
Ответ по цитате, потом по интерпретации: как строить ответ
Ответ по цитате, потом по интерпретации помогает показать основание вывода. Разберем, где этот формат нужен и как внедрить его без путаницы.
Ответ по цитате, потом по интерпретацииответ с опорой на источник
11 янв. 2026 г.·10 мин чтения
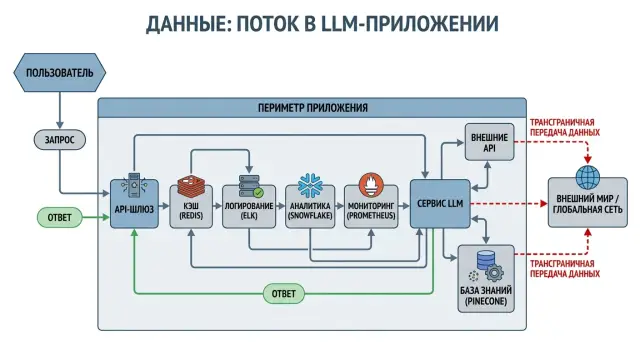
Трансграничная передача данных в LLM: риски вне API
Трансграничная передача данных в LLM возникает не только в вызове модели, но и в логах, аналитике и вспомогательных сервисах. Разберем точки риска.
трансграничная передача данных в LLMлоги LLM-приложений
10 янв. 2026 г.·8 мин чтения
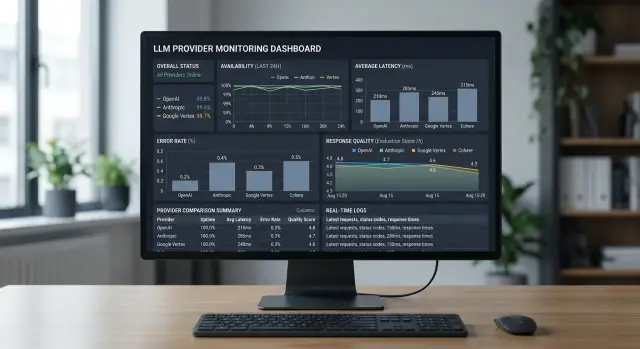
Скоринг здоровья провайдера по своим метрикам для LLM
Скоринг здоровья провайдера помогает видеть реальные сбои, рост задержки и просадку качества по вашим запросам, а не по общей статус-странице.
скоринг здоровья провайдерадоступность LLM API

08 янв. 2026 г.·9 мин чтения
Сравнение тарифов LLM: как честно посчитать итоговую цену
Сравнение тарифов LLM часто ломается из-за разных единиц учёта. Покажем таблицу пересчёта, формулы и сценарии, где низкая ставка даёт дорогой итог.
сравнение тарифов LLMстоимость токенов

07 янв. 2026 г.·7 мин чтения
Контрактные тесты для OpenAI-совместимых провайдеров
Контрактные тесты для OpenAI-совместимых провайдеров помогают за час найти сбои в streaming, tools, embeddings и формате ошибок до релиза.
контрактные тесты для OpenAI-совместимых провайдеровсовместимость OpenAI API

31 дек. 2025 г.·9 мин чтения
Дообучить модель на внутренней переписке без потери стиля
Покажем, как дообучить модель на внутренней переписке: выбрать письма и чаты, убрать шум, проверить стиль и не перенести ошибки в ответы.
дообучить модель на внутренней перепискеочистка датасета для llm
26 дек. 2025 г.·10 мин чтения
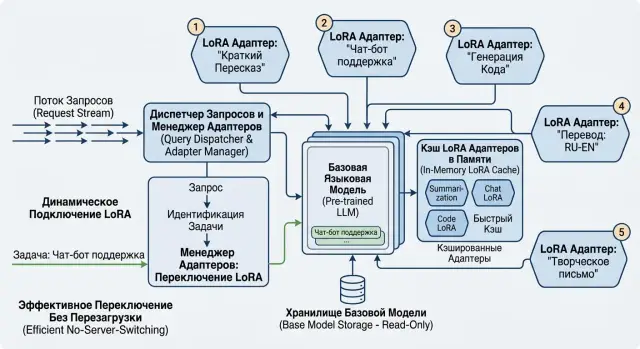
LoRA-адаптеры одной модели: хранение и переключение
Разбираем, как хранить LoRA-адаптеры одной модели, быстро выбирать нужный вариант по запросу и не поднимать отдельный сервер под каждый сценарий.
LoRA-адаптеры одной моделихранение адаптеров LoRA
24 дек. 2025 г.·9 мин чтения
Семантический кэш в диалогах: как измерить пользу и риск
Разберём, как оценить семантический кэш в диалогах: долю попаданий, ложные срабатывания, экономию токенов, денег и времени на длинных сессиях.
семантический кэш в диалогахизмерение попаданий кэша

17 дек. 2025 г.·8 мин чтения
Выбор модели для комплаенса: как собрать пакет фактов
Выбор модели для комплаенса проще согласовать, если дать факты: логи, риски, сроки хранения, доступы и список контролей.
выбор модели для комплаенсакарточка выбора LLM

13 дек. 2025 г.·7 мин чтения
Календарь обновлений моделей и провайдеров внутри команды
Календарь обновлений моделей и провайдеров помогает синхронизировать релизы, замены и дедлайны между продуктом, аналитикой и комплаенсом.
календарь обновлений моделей и провайдеровсинхронизация релизов моделей
12 дек. 2025 г.·7 мин чтения
Идемпотентность запросов к LLM без двойных списаний
Идемпотентность запросов к LLM помогает избежать двойных списаний, повторов ответа и лишних ретраев при таймаутах, сбоях сети и повторных кликах.
идемпотентность запросов к LLMдвойные списания API

11 дек. 2025 г.·6 мин чтения
A/B-тест промпта или модели: как понять, что сработало
A/B-тест промпта или модели легко даёт ложный вывод, если менять всё сразу. Покажем, как отдельно проверить промпт, модель и маршрут.
A/B-тест промпта или моделисравнение LLM-моделей

03 дек. 2025 г.·9 мин чтения
Стабильность ответов при температуре 0: как мерить риск
Стабильность ответов при температуре 0 не гарантирует одинаковый результат. Разберём причины расхождений и способ измерить риск на своих сценариях.
стабильность ответов при температуре 0детерминизм LLM

02 дек. 2025 г.·10 мин чтения
Единый учёт токенов у разных провайдеров без споров
Единый учёт токенов помогает свести вход, выход, кэш и служебные поля в одну модель данных, чтобы счета, логи и отчёты сходились.
единый учёт токеновнормализация токенов
02 дек. 2025 г.·8 мин чтения
Метаданные в RAG: какие фильтры правда улучшают ответ
Метаданные в RAG помогают сузить поиск по дате, типу документа и правам доступа, но лишние фильтры часто режут recall и портят ответ.
метаданные в RAGфильтры в RAG

01 дек. 2025 г.·8 мин чтения
Обратимая псевдонимизация данных: где хранить таблицу
Обратимая псевдонимизация данных помогает разбирать инциденты без лишнего доступа к PII. Где хранить таблицу соответствий и кому давать обратную подстановку.
обратимая псевдонимизация данныхтаблица соответствий персональных данных
28 нояб. 2025 г.·7 мин чтения
Фолбэки моделей без лишних расходов: как не платить дважды
Фолбэки моделей помогают пережить сбои, но без правил быстро удваивают счет. Разберем цепочки, лимиты и проверки, которые сдерживают расходы.
фолбэки моделейрезервные модели
25 нояб. 2025 г.·6 мин чтения
Стоп-последовательности в продакшене без мусора после JSON
Стоп-последовательности в продакшене помогают вовремя обрывать ответ модели после JSON, письма или цитаты без лишнего текста и поломки формата.
стоп-последовательностистоп-токены

22 нояб. 2025 г.·7 мин чтения
Kill switch для AI-функции: как остановить риск за минуту
Kill switch для AI-функции помогает сразу отключить чат, автозаполнение и агента без релиза. Разберем схему, роли команды и быстрые проверки.
kill switch для AI-функцииаварийное отключение AI

22 нояб. 2025 г.·7 мин чтения
Бенчмарк для казахского языка из реальных сценариев
Бенчмарк для казахского языка стоит строить на живых сценариях: запросы клиентов, формы, поиск, поддержка. Разберем набор, метрики и ошибки.
бенчмарк для казахского языкаоценка LLM на казахском

19 нояб. 2025 г.·6 мин чтения
Внутренний биллинг AI-расходов без споров между командами
Внутренний биллинг AI-расходов помогает считать затраты по продуктам, объяснять счёт без разговоров о токенах и снимать споры между командами.
внутренний биллинг AI-расходовучёт затрат на LLM
17 нояб. 2025 г.·9 мин чтения
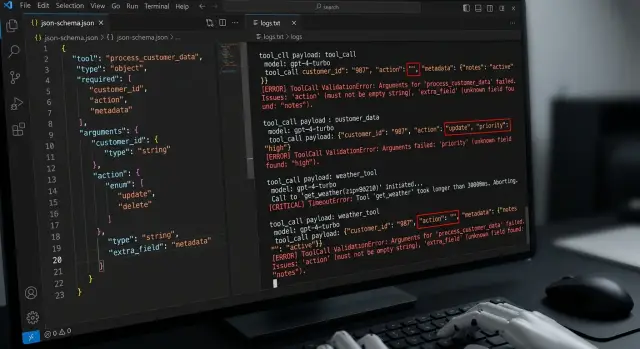
Тестирование tool calling: что ломается вне happy path
Тестирование tool calling не сводится к happy path. В статье разберём пустые аргументы, лишние поля, неверные типы, таймауты и ретраи.
тестирование tool callingошибки вызова инструментов
11 нояб. 2025 г.·7 мин чтения
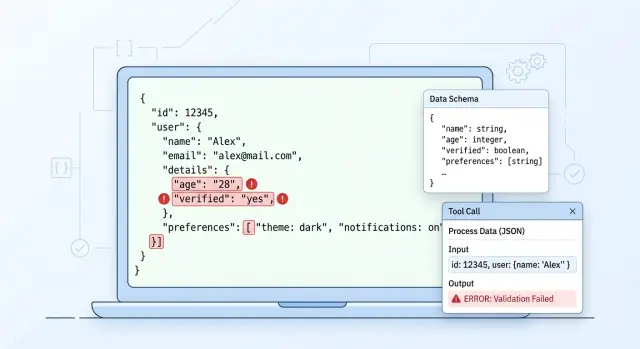
Структурированный вывод LLM: почему он ломается в продакшене
Структурированный вывод LLM часто ломается в продакшене из-за битого JSON, дрейфа схем и сбоев вызова инструментов. Разберем проверки и ретраи.
структурированный вывод LLMошибки JSON
05 нояб. 2025 г.·8 мин чтения
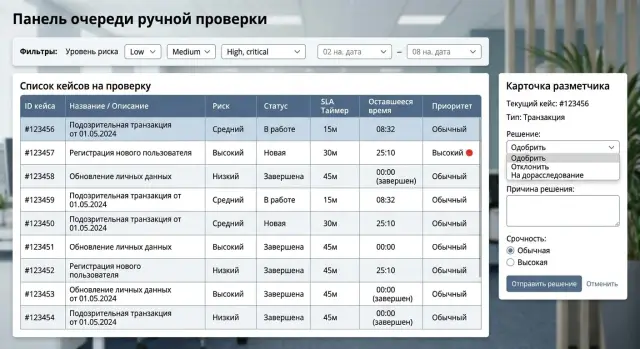
Очередь ручной проверки без бэклога: как настроить SLA
Очередь ручной проверки не должна расти сама по себе. Разберем приоритеты кейсов, SLA, правила эскалации и удобный интерфейс разметчика.
очередь ручной проверкиприоритизация кейсов

01 нояб. 2025 г.·10 мин чтения
Модель рассуждений или обычная модель: когда платить больше
Модель рассуждений или обычная модель: разберем, где дорогой вывод окупает себя, а где быстрый ответ дешевле и полезнее для продакшена.
модель рассуждений или обычная модельстоимость LLM за задачу
31 окт. 2025 г.·9 мин чтения
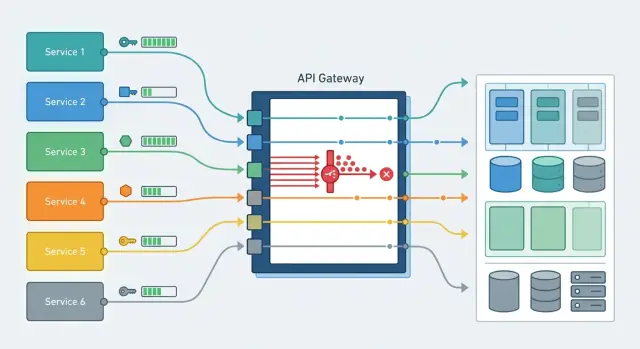
Лимиты запросов на уровне ключа для команд без хаоса
Лимиты запросов на уровне ключа помогают разделить нагрузку по сервисам, окружениям и ролям, чтобы шумный клиент не тормозил остальные команды.
лимиты запросов на уровне ключаограничение запросов для API
28 окт. 2025 г.·8 мин чтения
Postmortem LLM после сбоя: какие поля стоит фиксировать
Практичный разбор того, как оформить postmortem LLM после сбоя: какие поля записывать, кто их заполняет и как превратить выводы в задачи релиза.
postmortem LLMразбор инцидента LLM
26 окт. 2025 г.·10 мин чтения
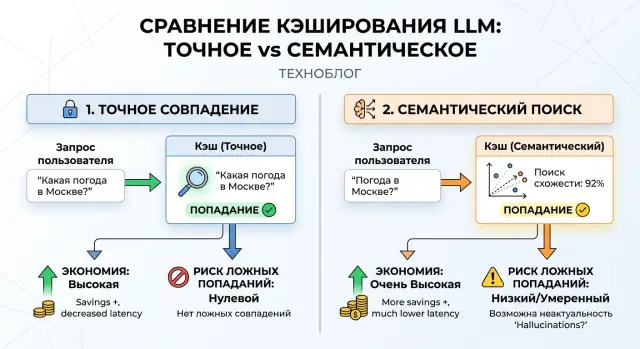
Семантический кэш и точное совпадение: где больше экономии
Разбираем, когда точное совпадение дает больше экономии, а когда семантический кэш ловит больше повторов, но начинает возвращать чужие ответы.
семантический кэшточное совпадение

24 окт. 2025 г.·6 мин чтения
Разбиение документов для RAG: как проверить его тестом
Сравните размеры фрагментов, перекрытие и реранжирование на одном наборе вопросов, чтобы выбрать разбиение документов для RAG по данным.
разбиение документов для RAGразмер фрагментов
21 окт. 2025 г.·11 мин чтения
Выбор провайдера LLM для компании в Казахстане: вопросы
Выбор провайдера LLM для компании в Казахстане лучше начинать с списка вопросов: где хранятся данные, какие есть документы, SLA, поддержка и API.
выбор провайдера LLM для компании в Казахстанехранение данных LLM в Казахстане
21 окт. 2025 г.·7 мин чтения
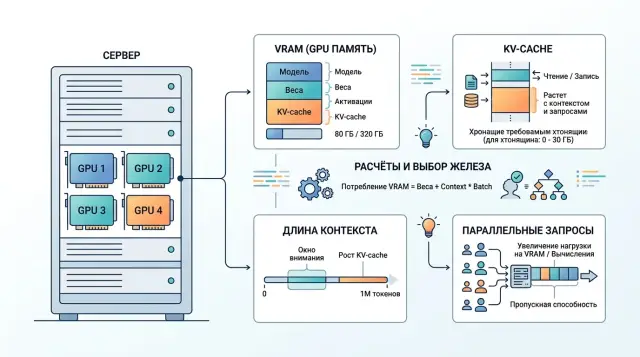
GPU для open-weight моделей: VRAM, контекст и KV-cache
GPU для open-weight моделей выбирают не только по VRAM. Разберём, как длина контекста, KV-cache и параллелизм меняют расчёт GPU.
GPU для open-weight моделейразмер KV-cache

16 окт. 2025 г.·10 мин чтения
Повторное использование KV-cache в длинных диалогах
Повторное использование KV-cache ускоряет длинные диалоги, если у запросов совпадает начало истории. Разберем схему, риски, метрики и проверки.
повторное использование KV-cacheускорение длинных диалогов LLM
13 окт. 2025 г.·9 мин чтения
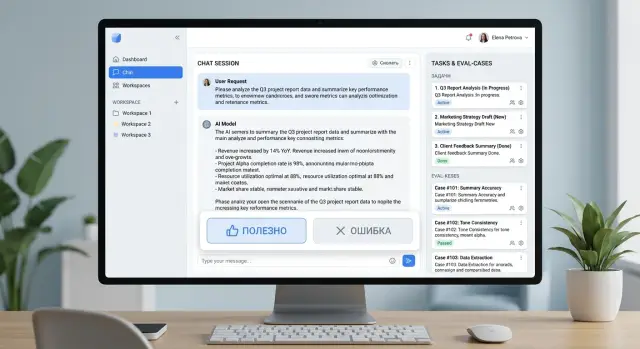
Фидбек пользователей для eval: как не копить скриншоты
Фидбек пользователей для eval помогает превратить кнопки «полезно» и «ошибка» в очередь задач: что собирать, как размечать и что проверять.
фидбек пользователей для evalкнопки полезно и ошибка
09 окт. 2025 г.·11 мин чтения
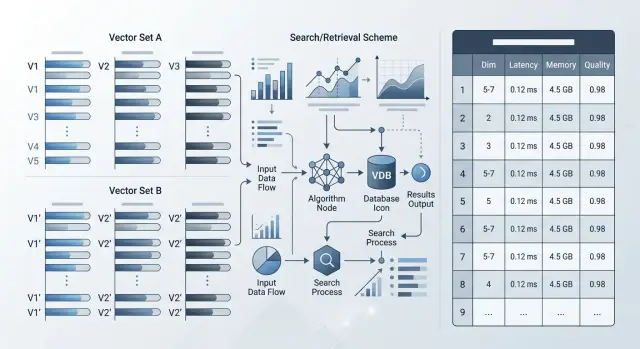
Миграция на новую модель эмбеддингов: что проверить
Миграция на новую модель эмбеддингов требует проверки размерности, качества поиска, скорости, памяти и совместимости старых векторов.
миграция на новую модель эмбеддинговразмерность эмбеддингов
09 окт. 2025 г.·8 мин чтения
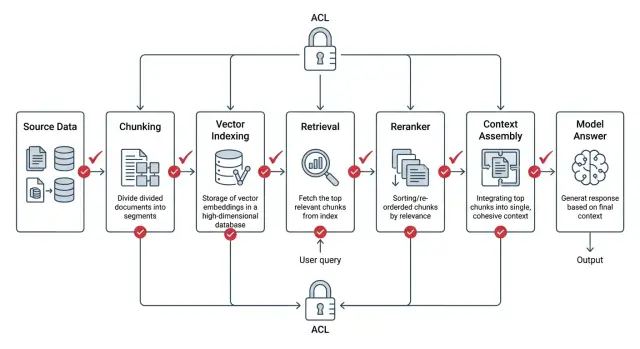
ACL в RAG: как закрыть доступ на уровне документа
ACL в RAG нужно применять до поиска, в ранжировании и при сборке контекста. Показываем схему, частые ошибки и короткий чек-лист.
ACL в RAGправа доступа в поиске
06 окт. 2025 г.·11 мин чтения
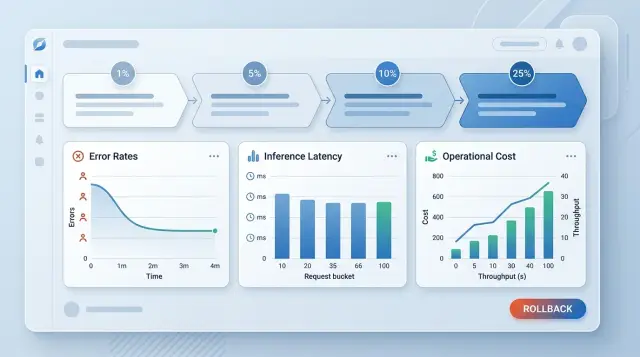
Канареечный выпуск модели: трафик, стоп-метрики, откат
Канареечный выпуск модели помогает проверить новую версию на 1-50% трафика, задать стоп-метрики и вести отчёт, чтобы откатить решение за минуты.
канареечный выпуск моделипроценты трафика LLM

04 окт. 2025 г.·8 мин чтения
Разделение прав доступа для ИИ-ассистента без утечек
Разделение прав доступа для ИИ-ассистента помогает не смешивать поиск по знаниям и выдачу ответа. Разберем схему, ошибки и проверки перед запуском.
разделение прав доступа для ИИ-ассистентаконтроль доступа к базе знаний
29 сент. 2025 г.·7 мин чтения
Сквозной trace_id для LLM-запросов без слепых зон
Сквозной trace_id для LLM-запросов помогает собрать в один разбор ответ модели, поиск, вызовы инструментов и логи приложения.
сквозной trace_id для LLM-запросовразбор инцидентов LLM
27 сент. 2025 г.·11 мин чтения
Локальный хостинг моделей: что держать в стране, а что нет
Локальный хостинг моделей помогает отделить рискованные сценарии от обычных: разберем, что держать в Казахстане, а что оставить на внешнем API.
локальный хостинг моделеймодели с открытыми весами

20 сент. 2025 г.·9 мин чтения
Бенчмарк из тикетов поддержки: как собрать живой набор
Бенчмарк из тикетов поддержки поможет проверить модель на живых кейсах. Разберём анонимизацию, разметку и быстрый запуск первого набора.
бенчмарк из тикетов поддержкианонимизация диалогов поддержки
15 сент. 2025 г.·11 мин чтения
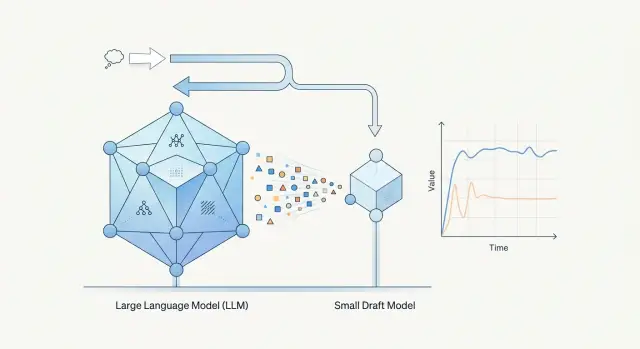
Спекулятивное декодирование: где ускоряет, а где нет
Спекулятивное декодирование не всегда ускоряет LLM. Покажем, где черновая модель реально снижает задержку, а где съедает выигрыш.
спекулятивное декодированиечерновая модель
12 сент. 2025 г.·7 мин чтения
Мультипровайдерный доступ к LLM без переписывания SDK
Мультипровайдерный доступ к LLM: как собрать единый эндпоинт, общую аутентификацию и резервирование без смены SDK и лишней логики в коде.
мультипровайдерный доступ к LLMединый эндпоинт LLM

11 сент. 2025 г.·8 мин чтения
Совместимость SDK после замены base_url: где она ломается
Совместимость SDK после замены base_url часто ломается не на авторизации, а на стриминге, вызовах инструментов и JSON-схемах. Разберем типовые сбои.
Совместимость SDK после замены base_urlстриминг ответов LLM

04 сент. 2025 г.·6 мин чтения
Вывод модели из эксплуатации без поломки продукта
Вывод модели из эксплуатации требует плана: предупредите команды, проверьте зависимости, держите окно двойной поддержки и снимайте трафик поэтапно.
вывод модели из эксплуатацииокно двойной поддержки
01 сент. 2025 г.·8 мин чтения
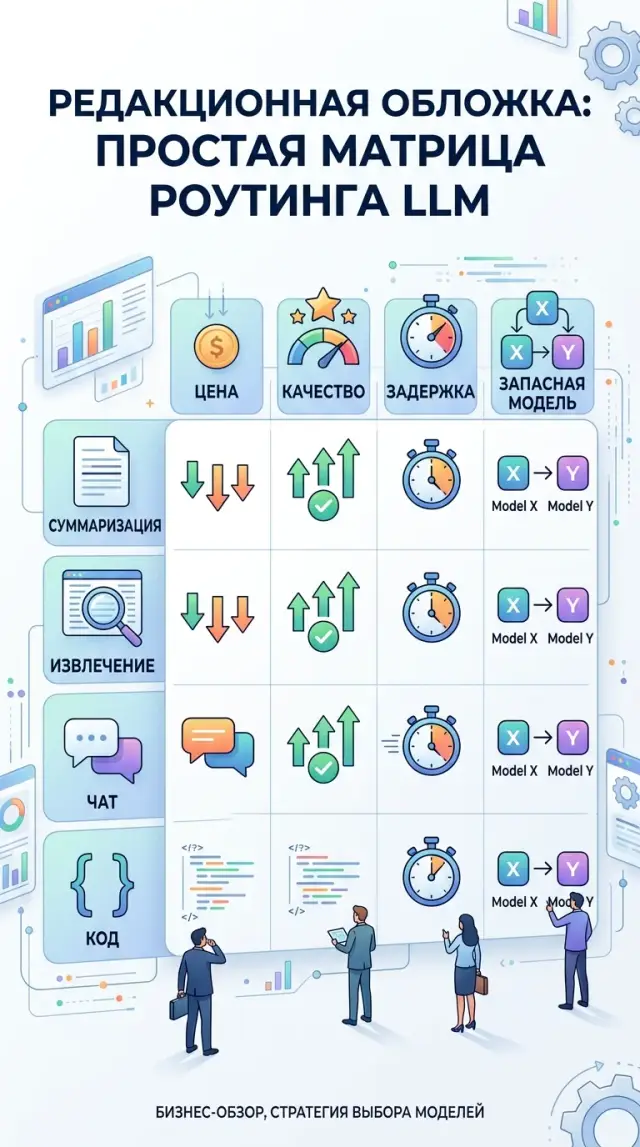
Роутинг по типу задачи: матрица моделей без лишних затрат
Роутинг по типу задачи помогает выбрать модели для суммаризации, извлечения, чата и кода так, чтобы снизить расходы и не потерять качество.
роутинг по типу задачиматрица выбора моделей

27 авг. 2025 г.·10 мин чтения
Бюджет задержки для LLM: где уходит время в запросе
Разберём, как считать бюджет задержки для LLM: сеть, маршрутизация, модель и постобработка, чтобы искать узкие места по данным, а не по ощущениям.
бюджет задержки для LLMзадержка LLM API
23 авг. 2025 г.·7 мин чтения
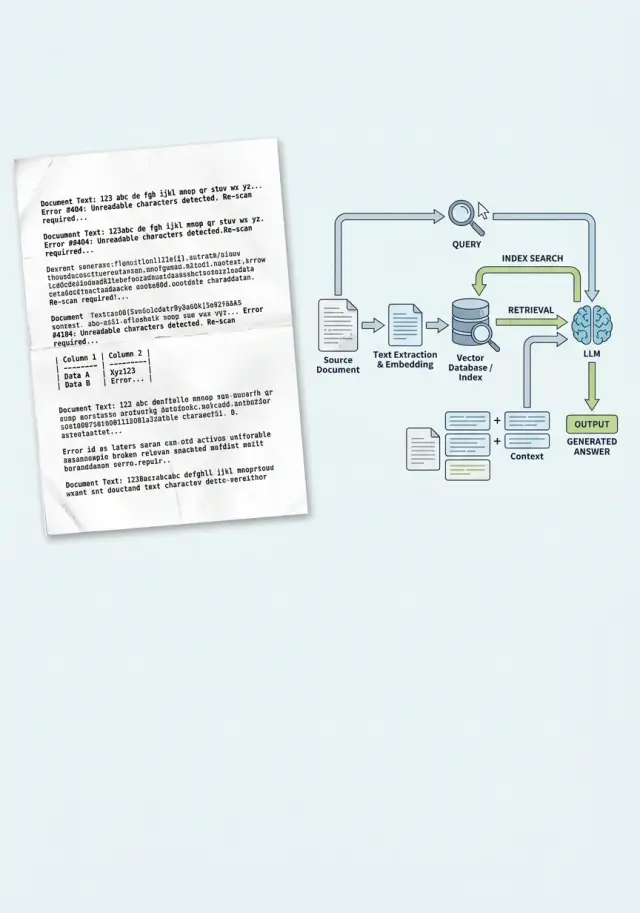
Ошибки OCR в RAG: 5 признаков грязного текста до индекса
Ошибки OCR в RAG ломают поиск, цитаты и ответы. Разберем 5 признаков грязного текста, быстрые проверки и порядок очистки перед индексом.
ошибки OCR в RAGгрязный текст OCR
23 авг. 2025 г.·11 мин чтения
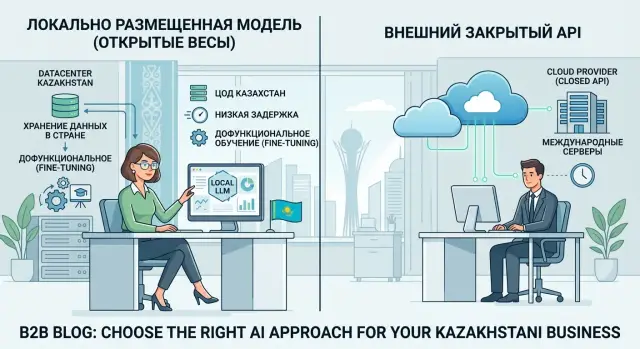
Модель с открытыми весами или закрытая: где что лучше
Модель с открытыми весами часто выигрывает там, где важны хранение данных в стране, низкая задержка и дообучение под свои процессы.
модель с открытыми весамихранение данных в стране
20 авг. 2025 г.·8 мин чтения
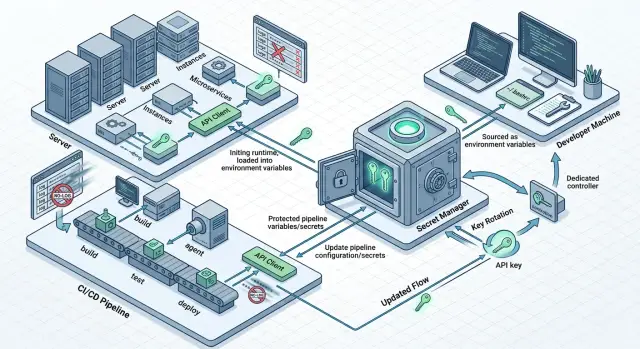
Где хранить API-ключи для LLM и как их ротировать
Где хранить API-ключи для LLM на серверах, в CI и локально: простая схема без секретов в коде, образах, чатах и логах.
где хранить API-ключи для LLMротация API-ключей

10 авг. 2025 г.·10 мин чтения
Небольшие модели для маскирования и классификации PII
Небольшие модели для маскирования и классификации PII снижают затраты на потоковые задачи. Покажем, как сравнить цену, recall и ошибки.
небольшие модели для маскирования и классификации PIIмаскирование PII

08 авг. 2025 г.·6 мин чтения
Переоценка старых ответов после смены модели без лишних затрат
Переоценка старых ответов после смены модели: как выбрать диалоги и документы для повторного прогона, собрать очередь и не сжечь бюджет.
переоценка старых ответовсмена модели LLM
31 июл. 2025 г.·7 мин чтения
Своя GPU-инфраструктура: когда она выгоднее внешнего API
Своя GPU-инфраструктура оправдана не всегда. Разбираем пороги по трафику, задержке, данным и расходам, чтобы понять, когда API уже не подходит.
своя GPU-инфраструктурапорог трафика LLM
29 июл. 2025 г.·10 мин чтения
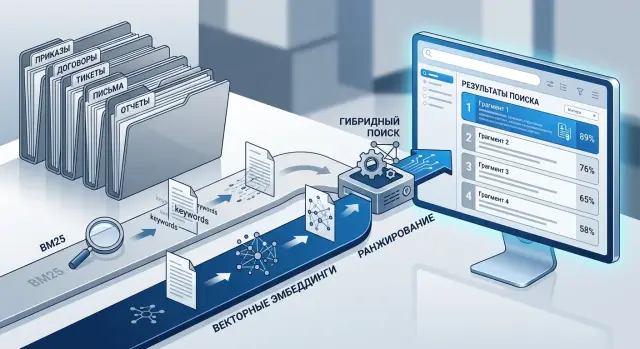
Гибридный поиск по документам: BM25 и эмбеддинги
Гибридный поиск по документам помогает точнее находить приказы, договоры и тикеты. Разберем схему BM25 и эмбеддингов, настройку и частые ошибки.
гибридный поиск по документамBM25 и эмбеддинги

23 июл. 2025 г.·6 мин чтения
Контролируемые сбои в LLM-инфраструктуре перед пиком
Контролируемые сбои в LLM-инфраструктуре помогают найти слабые места до пика спроса. Разберём проверки шлюза, провайдера, очередей и ретривера.
контролируемые сбои в LLM-инфраструктурепроверка LLM-шлюза
14 июл. 2025 г.·6 мин чтения
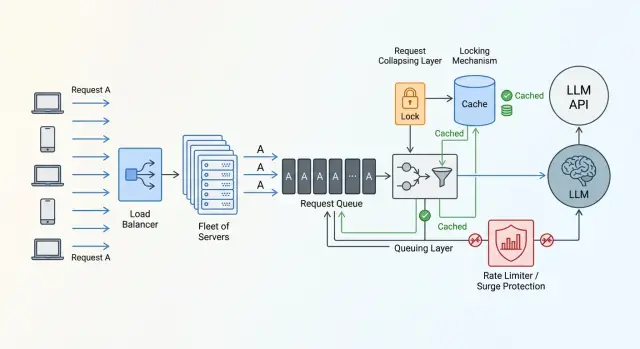
Шторм кэша при одинаковых промптах: как гасить пики API
Шторм кэша при одинаковых промптах бьет по лимитам и бюджету. Разберем схлопывание запросов, TTL, блокировки и быстрые проверки.
Шторм кэша при одинаковых промптахсхлопывание запросов

12 июл. 2025 г.·7 мин чтения
Извлечение атрибутов из прайс-листов без ручной чистки
Извлечение атрибутов из прайс-листов помогает свести к одному виду единицы, бренды и фасовки, даже если поставщики присылают Excel, PDF и CSV вразнобой.
извлечение атрибутов из прайс-листовнормализация единиц измерения
09 июл. 2025 г.·10 мин чтения
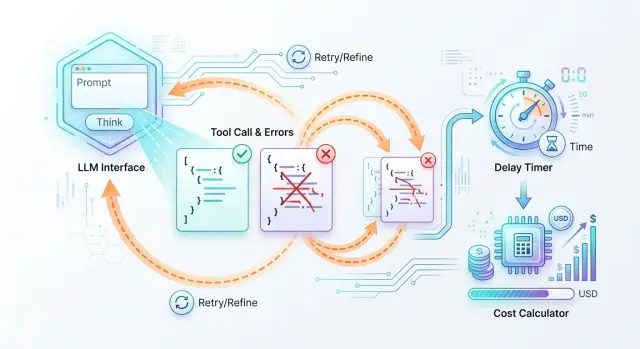
Стоимость вызова инструментов: из чего складывается цена
Стоимость вызова инструментов зависит не только от токенов: разберем выбор модели, ошибки схемы, ретраи, задержки и цену простоя процесса.
стоимость вызова инструментоввыбор модели для вызова функций
09 июл. 2025 г.·9 мин чтения
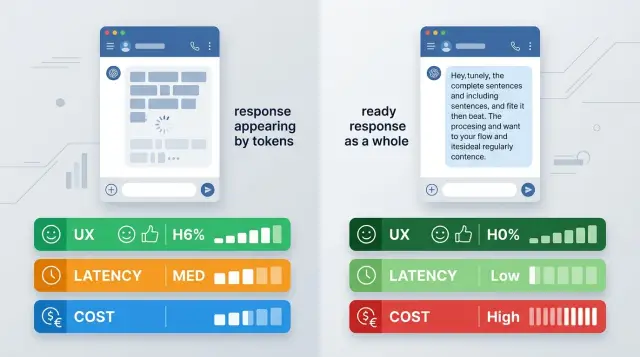
Стриминг ответов или полный ответ: что выбрать для LLM
Стриминг ответов или полный ответ: сравнение для чата, поиска и агентных сценариев по UX, цене, задержке и сложности интеграции.
стриминг ответов или полный ответпотоковая выдача LLM
05 июл. 2025 г.·11 мин чтения
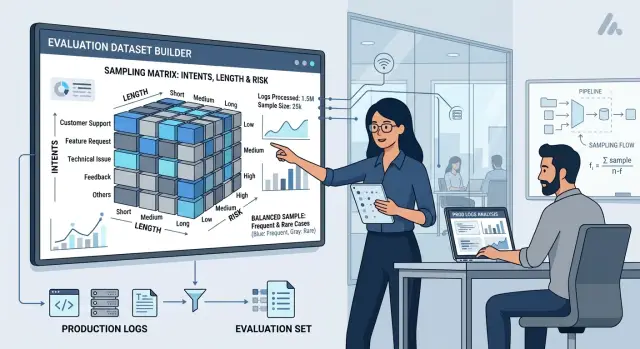
Сэмплирование продакшен-кейсов для eval без смещения
Покажем, как сделать сэмплирование продакшен-кейсов для eval по интентам, длине и риску, чтобы метрики отражали реальную нагрузку, а не удобный срез.
сэмплирование продакшен-кейсов для evalстратификация интентов
01 июл. 2025 г.·10 мин чтения
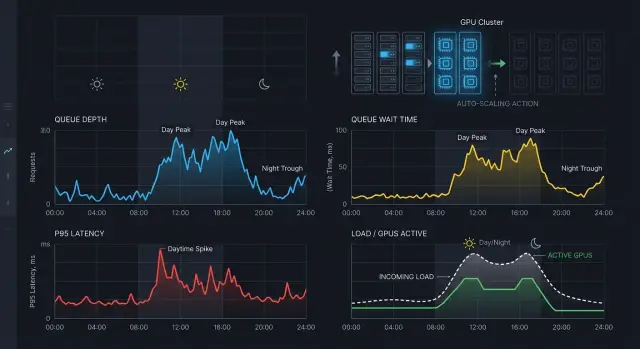
Автоскейлинг инференса: сигналы из очереди и задержки
Автоскейлинг инференса стоит строить на длине очереди, времени ожидания и задержке p95, чтобы днем держать SLA, а ночью не гонять лишние GPU.
автоскейлинг инференсаглубина очереди

29 июн. 2025 г.·9 мин чтения
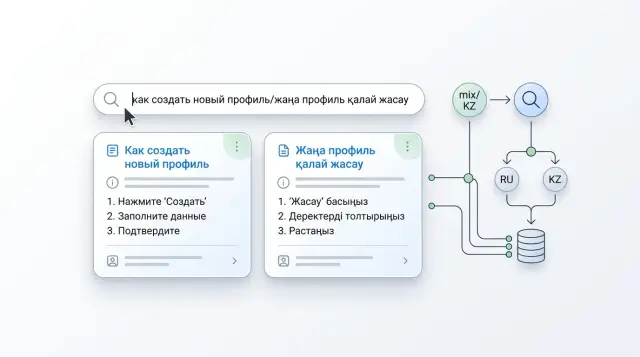
Транслитерация в поиске: как учесть три варианта термина
Транслитерация в поиске помогает находить статьи, даже если термин пишут по-русски, латиницей или с ошибкой. Разберем словарь, индекс и проверки.
транслитерация в поискепоиск по базе знаний
27 июн. 2025 г.·9 мин чтения
Поиск на русском и казахском: эмбеддинги и нормализация
Поиск на русском и казахском требует точного выбора эмбеддингов и правил нормализации, чтобы смешанные запросы приводили к нужным ответам.
поиск на русском и казахскомэмбеддинги для смешанных запросов

21 июн. 2025 г.·8 мин чтения
Перепроверка ответа второй моделью: где она реально нужна
Перепроверка ответа второй моделью помогает там, где ошибка стоит дорого: в выплатах, договорах и медтекстах. Разберем, когда она окупает задержку.
перепроверка ответа второй модельюпроверяющая модель
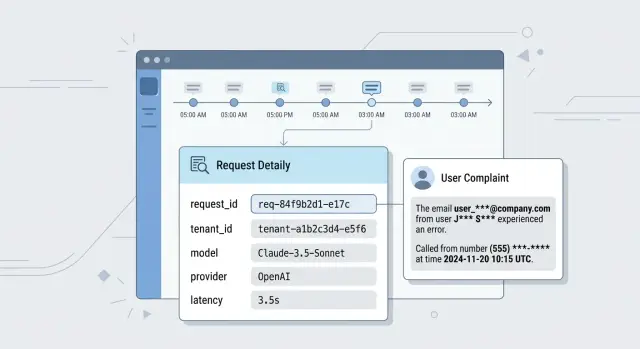
20 июн. 2025 г.·9 мин чтения
Как использовать аудит-логи для разбора инцидентов за 5 минут
Как использовать аудит-логи для разбора инцидентов: разберем, какие вопросы лог обязан закрывать за 5 минут после жалобы пользователя.
как использовать аудит-логи для разбора инцидентоваудит-логи LLM
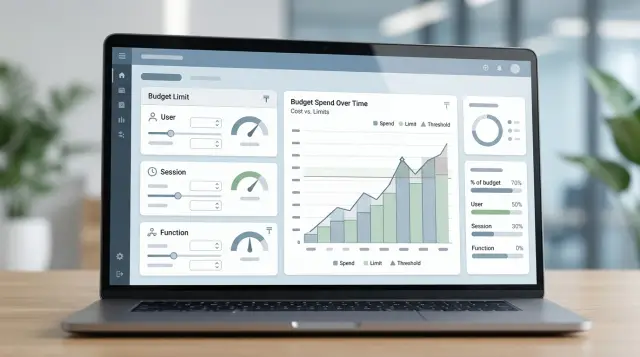
20 июн. 2025 г.·9 мин чтения
Лимиты бюджета для LLM-фич без ручного контроля
Лимиты бюджета для LLM-фич помогают держать расход под контролем: задайте пороги на пользователя, сессию и функцию и не ловите сюрпризы в счете.
лимиты бюджета для LLM-фичконтроль расходов LLM

18 июн. 2025 г.·8 мин чтения
Несогласие разметчиков: как наладить рубрики и арбитраж
Несогласие разметчиков тормозит обучение модели и портит датасет. Разберем, как писать рубрики, вести арбитраж и вовремя пересматривать правила оценки.
несогласие разметчиковрубрики для разметки
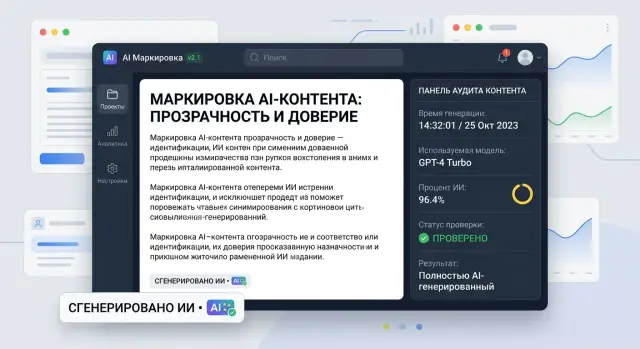
16 июн. 2025 г.·6 мин чтения
Метки AI-контента в продукте: где ставить и что хранить
Метки AI-контента в продукте помогают честно показать источник текста, сохранить следы генерации и не перегрузить экран лишними деталями.
метки AI-контента в продуктемаркировка AI-контента
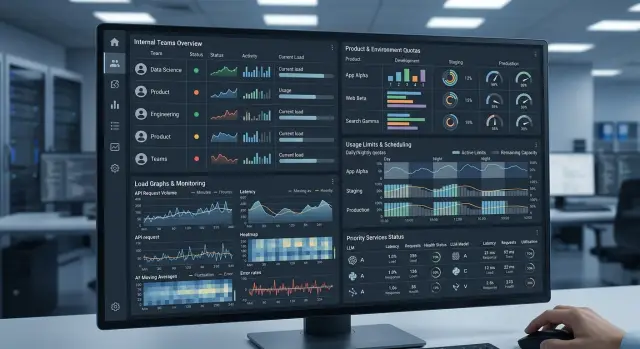
16 июн. 2025 г.·6 мин чтения
Лимиты LLM между командами: схема квот без простоев
Лимиты LLM между командами: как раздать квоты по продуктам, средам и часам суток, чтобы прод не простаивал, а тесты и батчи не съедали общий пул.
лимиты LLM между командамиквоты по продуктам

15 июн. 2025 г.·8 мин чтения
Критерии качества AI-функции: договор Product и ML
Критерии качества AI-функции помогают заранее согласовать порог пользы, стоп-сценарии и откат, чтобы не спорить о результате после релиза.
критерии качества AI-функциипорог пользы AI
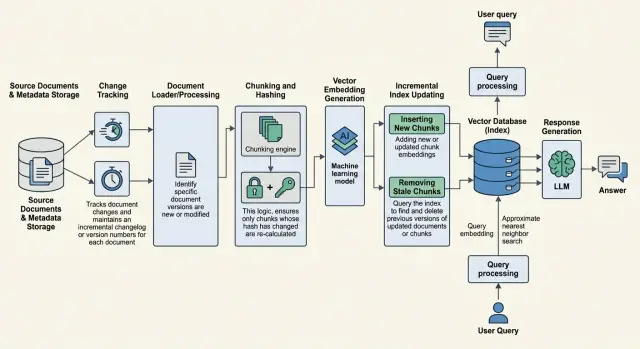
15 июн. 2025 г.·7 мин чтения
Обновление знаний в RAG без полной переиндексации
Обновление знаний в RAG без полной переиндексации: как находить изменённые документы, пересчитывать нужные чанки и убирать старые ответы из выдачи.
обновление знаний в RAGинкрементальная переиндексация