Хранение данных в Казахстане для LLM без лишней сложности
Хранение данных в Казахстане для LLM: простая схема вызовов, логов и маскирования PII под местные требования без лишних слоев.
Где схема чаще всего дает сбой
Сбой обычно начинается не в модели, а раньше. Команда быстро собирает первый сценарий, подключает LLM к чату, CRM или внутреннему боту, и в модель уходит все подряд: имя клиента, ИИН, номер телефона, адрес, номер договора и весь диалог целиком. Так проще запустить пилот. Потом этот "временный" путь остается в продакшене.
Вторая проблема - логи. Разработчикам удобно писать полный текст запроса и ответа, потому что так легче разбирать ошибки. Через пару недель в журналах уже лежат целые разговоры с клиентами, часто без срока хранения и без понятного правила, кто может их читать. Если сотрудник поддержки, аналитик и админ видят одно и то же, контроля уже нет.
Ломается и сама схема событий. Один сервис пишет в базу, второй в APM, третий в SIEM, четвертый хранит отладочные файлы локально. Потом никто не может ответить на два простых вопроса: какой текст реально ушел в модель и кто потом открывал эти данные. Для требований по хранению данных в Казахстане это слабое место. Недостаточно держать одну базу внутри страны, если следы запроса разбросаны по разным системам.
Есть и более тихая ошибка: доступ к логам дают "на всякий случай" слишком многим людям. На практике такие данные должны видеть немногие, и каждый доступ должен оставлять понятный след. Если в компании нельзя быстро понять, кто читал журнал, когда и по какой задаче, схема уже трещит.
Обычно это выглядит так: в промпт попадает сырой текст из CRM без маскирования, полные диалоги лежат в логах неделями, у API и приложений разные журналы с разными сроками хранения, а доступ к ним есть у широкой группы сотрудников.
Пример простой. Клиент пишет в чат банка и присылает ИИН вместе с вопросом по кредиту. Бот берет весь текст, отправляет его в модель, потом сохраняет тот же текст в логах приложения и в журнале провайдера. Формально сервис работает. По факту персональные данные уже размножились в нескольких местах.
Нормальная схема проще, чем кажется: убрать лишние данные до вызова модели, хранить журналы в одном контуре, разделить доступ по ролям и фиксировать каждый просмотр. Если команда использует единый шлюз для LLM, например AI Router, эти правила все равно нужно продумать до запуска, а не после первого инцидента.
Что хранить в стране, а что не тянуть в логи
Самая частая ошибка проста: команда пишет в логи почти все подряд, а потом пытается почистить это задним числом. Для работы с данными в Казахстане такой подход плох. Сначала разделите данные по типам, потом решайте, что хранить, где хранить и как долго.
Обычно хватает четырех категорий. Первая - текст запроса и текст ответа. В них часто уже есть персональные или чувствительные данные. Вторая - метаданные: модель, время вызова, длина ответа, статус, цена, идентификатор сервиса. Третья - технические события: таймауты, ошибки, повторные попытки, маршрут вызова. Четвертая - секреты и вложения. Их как раз почти никогда не нужно тащить в логи.
Тексты запросов и ответов лучше хранить внутри страны, если в них может быть PII, номер договора, адрес, диагноз или другая чувствительная информация. Аудит-след тоже лучше оставлять внутри страны: кто отправил запрос, к какому сервису, когда, с каким результатом и по какому правилу доступа. Метаданные можно хранить дольше, но без содержимого текста. Для отчетов обычно хватает идентификаторов, счетчиков токенов и кодов ошибок. В технические логи не стоит писать API-токены, пароли, cookie, сырые файлы и полные заголовки запросов.
С вложениями правило жесткое: не сохраняйте сырые PDF, изображения, аудио и архивы в обычный лог. Если файл нужен для разбора инцидента, достаточно хеша, размера, MIME-типа и внутреннего ID. Этого хватает, чтобы понять, что произошло, и не тащить в систему лишний риск.
Срок хранения тоже задают по типу данных, а не одной цифрой на все. Текст запроса и ответа часто имеет смысл удалять быстро, например через 7-30 дней, если он нужен только для разбора качества. Технические события можно держать 30-90 дней. Аудит-логи обычно живут дольше, потому что по ним проверяют доступ и действия сотрудников. Маскированные агрегаты для аналитики можно хранить еще дольше, если это разрешает внутренняя политика.
Когда все LLM-вызовы идут через один шлюз, схема заметно упрощается. Внутри страны остаются тексты, PII и аудит-след, а в общие техлоги попадают только безопасные метаданные. Это сильно экономит время, когда служба безопасности просит показать, кто видел данные и где они лежат.
Из каких блоков собрать простую LLM-схему
Хорошая схема обычно состоит не из десятка сервисов, а из нескольких понятных блоков. Если разделить их сразу, хранение данных в Казахстане становится задачей архитектуры, а не ручных запретов для команды.
Базовые блоки
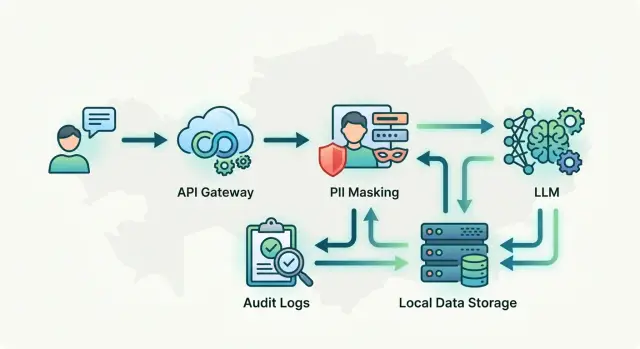
Первый блок - единая точка входа для всех вызовов к моделям. Это API-шлюз, через который проходят чат, суммаризация и внутренние помощники. Такой слой убирает хаос: команда не вшивает прямые вызовы к разным провайдерам в каждый сервис, а меняет правила маршрутизации в одном месте.
Второй блок - маскирование PII до отправки запроса в модель. Он должен стоять перед маршрутизатором, а не после него. Если клиент написал ИИН, номер телефона или адрес, система сначала скрывает эти поля и только потом отправляет текст дальше.
Третий блок - маршрутизатор моделей. Он решает, куда направить запрос: в локально размещенную модель или к внешнему провайдеру. Для чувствительных сценариев это удобно: один и тот же API может отправлять запросы с персональными данными во внутренний контур, а менее чувствительные задачи - наружу.
Четвертый блок - аудит-лог, отделенный от продуктовых логов. В продуктовых логах команда ищет ошибки интерфейса и задержки. В аудит-логе нужны другие события: кто вызвал модель, с каким ключом, какая роль была у запроса, какое правило сработало, была ли маскировка и куда ушел вызов.
Пятый блок - слой доступа. Правила доступа лучше хранить рядом с API-ключами, ролями и лимитами, а не разносить по коду разных приложений. Тогда можно быстро запретить одной группе сотрудников доступ к внешним моделям или включить ограничения для конкретного ключа.
Как это выглядит на практике
У многих команд уже есть код под OpenAI SDK. В таком случае проще поставить OpenAI-совместимый шлюз перед моделями и сменить только base_url. Это позволяет добавить маршрутизацию, маскирование, аудит и лимиты без переписывания всей логики приложения.
Еще один обязательный слой - разделение сред. Контур разработки и боевой контур не должны делить одни и те же ключи, логи и наборы данных. Иначе тестовый запрос с реальными данными быстро окажется там, где его не ждали.
В простом виде цепочка выглядит так: приложение -> шлюз -> маскирование -> выбор модели -> отдельный аудит-лог. Этого уже достаточно, чтобы не растаскивать контроль доступа и обработку чувствительных данных по всему стеку.
Как проходит запрос шаг за шагом
При требованиях к хранению данных в Казахстане важен не сам вызов модели, а порядок действий вокруг него. Если он простой и жесткий, команде легче пройти проверку, найти ошибку и не утащить лишние данные в модель или в логи.
Сначала приложение принимает запрос и сразу выдает ему request_id. Этот идентификатор связывает весь путь запроса: кто его отправил, какой сервис его обработал, какая модель ответила, какие проверки сработали и кто потом смотрел результат.
Дальше система проверяет, кто именно сделал запрос. Роль пользователя, сервисный ключ, лимиты по частоте и доступные модели лучше проверять до любого внешнего вызова. Если сотруднику можно работать только с обезличенным текстом, это правило должно сработать сразу.
Потом текст проходит через слой очистки. На этом этапе система ищет PII: ФИО, телефон, ИИН, адрес, номер договора, реквизиты карты. Найденные поля она маскирует или заменяет токенами вроде [CLIENT_NAME] и [PHONE]. Для модели этого обычно достаточно. Смысл запроса сохраняется, а личные данные не уходят дальше.
Только после этого очищенный текст отправляют в выбранную модель. В простом варианте приложение вызывает один внутренний шлюз, а он уже решает, какую модель использовать. Это удобно, потому что правила маскирования, лимиты и аудит живут в одном месте.
Когда модель возвращает ответ, система сохраняет не только текст. Она записывает метки безопасности, имя модели, время ответа, статус запроса и служебные события аудита. В логи лучше класть очищенную версию текста, а не исходник. Полный текст, если он вообще нужен, стоит хранить отдельно и под более жестким доступом.
Для обычного сотрудника это выглядит просто: он видит ответ и замаскированные поля. Руководитель или сотрудник комплаенса с нужной ролью может открыть полную версию, если для этого есть основание. Это действие тоже должно попасть в аудит.
Минимальный рабочий маршрут такой:
- Приложение принимает запрос и присваивает
request_id. - Модуль доступа проверяет роль, ключ и лимиты.
- Слой защиты находит и маскирует PII.
- Шлюз отправляет очищенный текст в модель.
- Система сохраняет ответ, метки и аудит-события.
Если пропустить хотя бы один шаг, проблемы обычно появляются быстро. Чаще всего команды либо логируют исходный текст без маскирования, либо показывают полную версию слишком широкому кругу сотрудников.
Как маскировать данные до модели
Если в запросе есть персональные данные, модель не должна видеть их в исходном виде. Самый простой рабочий подход такой: сначала убрать чувствительные поля, потом отправить в LLM уже очищенный текст.
Обычно начинают с того, что встречается почти в каждом бизнес-потоке: имя, ИИН, телефон, адрес, номер карты. Этого уже достаточно, чтобы заметно снизить риск утечки и не тянуть лишнее в промпт.
Вместо реальных значений подставляйте понятные маркеры: [CLIENT_NAME], [IIN], [PHONE], [ADDRESS], [CARD]. Модель почти всегда может нормально ответить и без оригинальных данных, если смысл запроса сохранен.
Например, фразу "Клиент Айжан Сарсенова с ИИН 990101300123 просит сменить адрес доставки на Алматы, Абая 10" лучше превратить в "Клиент [CLIENT_NAME] с ИИН [IIN] просит сменить адрес доставки на [ADDRESS]". Для классификации, краткого ответа, маршрутизации заявки или черновика письма этого обычно хватает.
Таблицу замен храните отдельно от промптов и логов. Лучше держать ее в защищенном хранилище с коротким сроком жизни записи, жестким доступом и понятным аудитом. Если компании нужно хранить чувствительные данные внутри страны, именно это хранилище и журнал операций обычно оставляют в локальном контуре в первую очередь.
Возвращать исходные данные нужно только там, где без них нельзя. Оператору контакт-центра можно показать готовый ответ уже с подстановкой имени клиента, а вот промежуточные сервисы, модель и общие логи могут работать только с маркерами. Чем меньше систем видят оригинал, тем лучше.
Есть и частый промах: команда маскирует данные так агрессивно, что запрос теряет смысл. Если убрать все подряд, модель начнет путаться. Проверяйте это на реальных примерах. Адрес можно скрыть целиком, но иногда полезно оставить город. Номер карты почти всегда стоит убирать полностью, а тип продукта или статус клиента лучше сохранить.
На практике это выглядит как отдельный шаг перед вызовом модели: сервис находит PII, заменяет значения, пишет карту замен в закрытое хранилище и только потом отправляет текст дальше. Если используется шлюз вроде AI Router, логику маскирования все равно лучше выполнять до отправки запроса в API, а обратную подстановку делать только во внутренней доверенной зоне.
Как вести аудит-логи и контроль доступа
Аудит нужен не для галочки. Он нужен, чтобы за несколько минут понять, кто отправил запрос, какой промпт сработал, какую модель вызвали и что произошло после ответа. Если этого нет, любая проверка превращается в ручной поиск по кускам логов.
Минимальный след для каждого вызова лучше держать одинаковым во всех сервисах. Обычно хватает нескольких полей: кто вызвал модель, когда ушел запрос и когда пришел ответ, какая версия промпта использовалась, какая модель и какой провайдер обработали запрос, каким был размер запроса и ответа, чем закончился вызов и сколько он стоил.
Этого уже хватает для нормального аудита без лишнего шума. Если команда часто меняет промпты, лучше явно версионировать их. Запись вида prompt_version=v12 полезнее, чем длинный текст в логе, по которому потом никто не понимает, какой вариант ушел в продакшн.
Отдельно храните след для действий с самими логами. Одно дело - вызов модели. Другое - чтение журнала, экспорт CSV, просмотр переписки, смена лимита по ключу. Эти события тоже должны оставлять запись: кто открыл, что выгрузил, за какой период, с какого IP и по какой роли. Утечка часто происходит не через модель, а через слишком удобный доступ к журналам.
С доступом лучше не спорить с практикой: роли работают, общие учетки ломают контроль. Разработчику нужен один набор прав, аналитику поддержки другой, службе ИБ третий. Давайте людям доступ по задаче, а не ко всей системе сразу. Если сотрудник уходит из команды, вы просто закрываете его учетку и не ищете, где еще использовался общий пароль.
Лимиты на уровне ключа тоже сильно помогают. Для каждого сервиса или команды задайте свой предел по запросам, токенам и бюджету. Тогда один неудачный релиз не съест весь месячный лимит и не забьет очередь для остальных.
Если нужен единый контур для таких правил, AI Router подходит под этот сценарий: у него один OpenAI-совместимый эндпоинт, помесячный B2B-инвойсинг в тенге и средства для локального контроля вроде аудит-логов, маскирования PII и лимитов на уровне ключа. Но даже с таким шлюзом архитектуру доступа и сроки хранения все равно нужно задавать внутри компании.
Простой пример для контакт-центра
В контакт-центре оператор получает жалобу: клиент пишет, что с его счета списали деньги, а в тексте есть ИИН, телефон и номер договора. В сыром виде такой запрос не стоит отправлять в модель. Сначала форма или промежуточный сервис скрывает чувствительные поля и подставляет метки вроде [ИИН скрыт] и [номер договора скрыт]. Смысл жалобы при этом остается понятным.
Дальше система отправляет в LLM уже очищенный текст и короткую инструкцию: дать сжатый ответ на 3-4 предложения, сохранить спокойный тон и не обещать того, что оператор не может выполнить. Модель не видит личные данные, но все равно помогает по делу: кратко пересказывает суть жалобы, предлагает черновик ответа и держит нужный тон.
Для хранения данных в Казахстане в таком сценарии обычно достаточно оставить внутри страны сырой текст обращения, исходные журналы, данные клиента и историю доступа. Если запрос идет во внешнюю модель, наружу уходит только очищенная версия без PII.
В аудит-лог не нужно писать весь диалог. Лучше сохранить только то, что пригодится для проверки: ID обращения, кто открыл карточку клиента, когда ушел запрос к модели, какие поля сервис скрыл и кто утвердил итоговый ответ.
Супервизор потом видит понятную цепочку действий. Например, оператор Айжан открыла диалог в 14:03, система скрыла ИИН, телефон и номер договора, модель вернула черновик ответа, а оператор отправил финальный текст в 14:05. Этого достаточно для разбора спорных случаев, аудита и контроля доступа.
Частые ошибки
Чаще всего команда начинает не с границ данных, а со сложной маршрутизации. Появляется оркестратор с ветвлениями, повторными попытками и выбором модели, а логи, роли и правила хранения откладывают на потом. Потом выясняется, что запросы уже идут в продакшн, а ответить на вопрос "кто, когда и какие данные отправил" никто не может.
Вторая ошибка проще и опаснее: полные диалоги складывают туда же, где лежат техлоги. Разработчикам так удобнее, но для контроля это плохая идея. Техлог нужен для времени ответа, статуса, модели и стоимости запроса. Полная переписка, номера документов, телефоны и адреса там не нужны. Если все лежит в одном месте, доступ к отладке быстро превращается в доступ к чувствительным данным.
С маскированием тоже часто опаздывают. Команда сначала отправляет текст в модель, а уже потом чистит ответ и логи. В этот момент поздно: персональные данные уже ушли дальше по цепочке. ИИН, номер карты, телефон, адрес и ФИО нужно искать и скрывать до вызова модели.
Похожая история с доступом. Один API-ключ на всю команду выглядит безобидно, пока не случается спорный запрос, перерасход или утечка. Потом уже нельзя отделить тесты одного разработчика от продовых вызовов сервиса. На практике лучше выдавать отдельные ключи по сервисам и средам, а лимиты и аудит вести на уровне каждого ключа.
Если схема уже собрана неудачно, это видно быстро:
- в логах есть полные тексты диалогов;
- никто не знает, какой сервис отправил конкретный запрос;
- маскирование стоит после вызова модели;
- тестовый и боевой трафик идут под одним ключом;
- в ответах клиенту нет пометки, что текст сгенерировал ИИ.
Про маркировку AI-контента часто вспоминают в самом конце, хотя это не мелочь. Если банк, ритейл или контакт-центр публикует такой текст без пометки в выходном канале, проблема уже не техническая. Ее потом не закрыть хорошей схемой логов.
Даже если команда работает через OpenAI-совместимый шлюз и меняет только base_url, эти ошибки никуда не исчезают. Простая схема почти всегда лучше: маскирование перед вызовом, раздельные логи, отдельные ключи и понятная маркировка на выходе.
Короткий список перед запуском
Перед включением реального трафика проверьте не только модель, но и путь данных. Сбой чаще случается не в ответе LLM, а в том, что запрос потом нельзя отследить, удалить или объяснить на аудите.
Вот минимальный набор проверок:
- У каждого вызова есть свой
request_id, а рядом хранится владелец - сервис, команда или сотрудник, от имени которого ушел запрос. - Персональные данные маскируются до отправки в модель. Имена, телефоны, ИИН, адреса и номера договоров заменяются токенами, а расшифровка хранится отдельно внутри страны.
- Для аудит-логов заранее задан срок хранения и понятная структура: кто вызвал систему, когда это произошло, какой маршрут выбрали, какое правило маскирования сработало и был ли ответ показан пользователю.
- Роли и лимиты включены до запуска. Отдельно проверяется журнал доступа: кто смотрел логи и кто менял правила.
- Команда умеет удалить данные по регламенту без ручной импровизации: найти запись по
request_id, удалить связанные данные в рабочих хранилищах и оставить только тот след, который требует закон и внутренний контроль.
Если используется локальный или гибридный шлюз, часть этой схемы собрать проще. Например, в AI Router можно оставить данные внутри Казахстана, а вызовы вести через один совместимый эндпоинт без переписывания существующих SDK. Но сам порядок работы с данными, доступами и логами все равно должен быть прописан заранее.
Хороший тест очень простой. Возьмите один реальный сценарий, например запрос из контакт-центра, и пройдите его вручную от входа до удаления. Если на любом шаге команда отвечает "разберемся потом", запускать рано.
Что делать дальше
Начните не с новой платформы, а с одной схемы. Возьмите текущий путь запроса и нарисуйте его целиком: где приложение принимает ввод, где данные очищаются, куда уходит LLM-вызов, что пишется в логи, кто видит ответ и где хранятся следы работы. Обычно уже на этом этапе видно лишнее: дубли логов, прямые вызовы в разные модели и поля с персональными данными, которые никто не собирался сохранять.
Потом выберите один пилотный сценарий. Не весь продукт сразу, а один поток, который легко измерить на реальных логах. Для банка это может быть черновик ответа оператору, для ритейла - разбор обращения в поддержку, для SaaS - краткое резюме тикета. Один сценарий проще проверить на задержку, стоимость, ошибки маскирования и правила доступа.
Рабочий порядок обычно такой:
- Нарисовать текущий путь запроса на одной схеме.
- Отметить, какие данные должны остаться в стране, а какие можно вообще не хранить.
- Свести все LLM-вызовы к одному API, чтобы политика логов, маскирование PII и лимиты работали одинаково.
- Прогнать пилот на реальных логах и проверить не только качество ответа, но и то, что именно осталось в аудите.
Один общий шлюз почти всегда упрощает жизнь. Когда одна команда ходит в OpenAI напрямую, другая в Anthropic, а третья в локально поднятую модель, исключения быстро копятся. Потом кто-то забывает выключить сырые логи, кто-то пишет PII в трассировку, а кто-то живет без нормального аудита. Один вход для всех LLM-вызовов убирает большую часть этой путаницы.
Если нужен совместимый API-шлюз без привязки к одному провайдеру, можно посмотреть на AI Router с хостом airouter.kz. Он позволяет менять только base_url, поддерживает один OpenAI-совместимый эндпоинт и подходит командам, которым важно держать данные и аудит внутри Казахстана. Для пилота это часто проще, чем собирать свой контур из нескольких разрозненных сервисов.
Через неделю после запуска пилота откройте аудит-логи и проверьте три вещи: не утекла ли PII, кто реально имел доступ и можно ли по логам восстановить путь одного запроса без догадок.
Часто задаваемые вопросы
Зачем менять схему, если пилот уже работает?
Потому что рабочий пилот часто уже тащит лишние данные в модель и в логи. Если вы не исправите путь запроса сразу, потом получите дубли данных, широкий доступ к журналам и долгий разбор любого инцидента.
Что лучше хранить внутри Казахстана в первую очередь?
Держите внутри страны сырой текст с PII, таблицу подстановок после маскирования и аудит-след. Метаданные вроде времени вызова, модели, статуса и числа токенов можно хранить отдельно, если они не раскрывают личные данные.
Нужно ли сохранять полный текст запросов и ответов?
Нет, полный текст нужен редко. Для отладки и отчетов обычно хватает request_id, версии промпта, модели, статуса и счетчиков токенов. Если текст все же нужен, храните очищенную версию и удаляйте ее быстро.
Когда маскировать персональные данные?
Сначала, до вызова модели. Сервис должен найти ИИН, телефон, адрес, номер договора и другие поля, заменить их маркерами и только потом отправить текст дальше. Если вы чистите данные после запроса, вы уже опоздали.
Какие данные нельзя отправлять в обычные техлоги?
Не пишите в техлоги API-токены, пароли, cookie, полные заголовки, сырые файлы и полный текст переписки. Техлог должен помогать разбирать ошибки, а не собирать у себя все чувствительные данные.
Что обязательно писать в аудит-лог?
Для проверки хватает простого набора: кто отправил запрос, когда, через какой сервис, какую модель вызвали, что сработало в маскировании, чем закончился вызов и кто потом открыл результат. Если человек смотрел лог или выгружал данные, аудит тоже должен это показать.
Можно ли использовать внешние модели, если данные нужно хранить в стране?
Да, но наружу должен уходить только очищенный текст. Сырой запрос, данные клиента и журнал доступа лучше оставить во внутреннем контуре, а шлюз должен решать, какие сценарии можно отправлять внешнему провайдеру.
Зачем выдавать отдельные API-ключи по сервисам и средам?
Разные ключи дают нормальный контроль. Вы сразу видите, какой сервис отправил запрос, кто потратил бюджет и где случился сбой. Один общий ключ быстро ломает аудит и мешает отделить тесты от боевого трафика.
Какой срок хранения данных выбрать?
Обычно текст запросов и ответов держат недолго, если он нужен только для контроля качества. Технические события живут дольше, а аудит-логи часто хранят еще дольше, потому что по ним проверяют доступ и действия сотрудников. Срок задавайте по типу данных, а не одной цифрой на все.
С чего начать перед запуском LLM-сценария?
Начните с одного сценария и пройдите его вручную от входа до удаления данных. Проверьте, где появляется request_id, где срабатывает маскирование, что именно попадает в логи, кто видит полный текст и можете ли вы быстро удалить запись по регламенту.