Выбор семейства моделей под новую функцию: дерево решений
Выбор семейства моделей для новой функции: разберем дерево решений по языку, формату ответа, задержке, бюджету и требованиям к данным.
Почему одна модель не подходит для всех функций
Одна и та же модель может хорошо писать ответ клиенту и плохо заполнять поля для системы. Это нормально. Задачи похожи только снаружи. Внутри у них разные требования.
Простой пример: функция "ответить на вопрос по заказу" переживет немного лишнего текста, если смысл точный и тон спокойный. А функция "извлечь номер договора и статус из письма" ломается даже из-за одной лишней строки. Если модель вместо чистого JSON добавит пояснение, сценарий остановится.
Разница не только в качестве, но и в цене ошибки. Лишний текст мешает автоматической обработке. Сломанный JSON рвет цепочку и отправляет задачу на ручную проверку. Медленный ответ раздражает пользователя и тормозит работу оператора.
Поэтому "лучшая модель" почти никогда не бывает лучшей для всего сразу. Одна семья моделей лучше держит формат. Другая дешевле на длинных запросах. Третья заметно лучше понимает русский, казахский или смешанные сообщения. Иногда модель отлично смотрится на демо, но сыпется в продакшене, где много коротких запросов, шумных данных и жесткий лимит по времени.
У каждой новой функции свой риск, значит и свой набор проверок. Для внутреннего поиска можно простить редкую неточность и взять более дешевый вариант. Для извлечения реквизитов, модерации или ответов в поддержке цена промаха выше. Там важны формат, стабильность и предсказуемость на сотнях похожих запросов подряд.
Выбор модели лучше начинать не с рейтингов, а с простого вопроса: что сломается первым, если модель ошибется. Такой подход особенно полезен, когда у команды есть доступ к нескольким семействам через один API. Тогда разницу видно не по общим словам, а по вашей функции, вашим данным и вашему лимиту по задержке.
С чего начать перед отбором моделей
Начинайте не с модели, а с одной простой задачи. Если функция делает сразу три вещи, сравнение быстро теряет смысл. Лучше описать один шаг пользователя и один результат, который вы ждете от модели.
Пример: пользователь пишет "проверь, можно ли вернуть товар". Нужен не длинный текст, а короткий ответ с решением и причиной. Уже здесь понятно, что важны точность формулировки, длина ответа и понятный формат.
Дальше зафиксируйте входные данные. Модель может читать только вопрос пользователя, а может получать еще историю переписки, фрагмент документа, карточку клиента или поля формы. Это сильно влияет на выбор. Одни модели лучше держат длинный контекст, другие хорошо работают на коротких запросах и стоят дешевле.
Полезно записать задачу в одну строку: что приходит на вход, что должно уйти на выход и сколько шагов между ними. Без этого выбор быстро превращается в спор по ощущениям.
Сразу задайте жесткие рамки. Какая максимальная длина ответа допустима? Сколько вызовов можно сделать на один запрос: один, два, пять? Если функция должна отвечать за 2-3 секунды, длинная цепочка из нескольких обращений к модели может не подойти, даже если качество выше.
Не откладывайте сбор примеров. До первого теста соберите хотя бы 20-30 реальных запросов, а не придуманные фразы со встречи. Нужны живые формулировки с ошибками, короткими фразами, лишними деталями и пустыми полями. Именно на таких данных быстро видно, где модель путается.
Хороший набор примеров обычно включает простой случай, пограничный, шумный и редкий. Тогда дерево решений для LLM строится на фактах, а не на красивом демо.
Как язык влияет на выбор
Язык быстро отсеивает часть моделей. То, что звучит гладко на русском, может путать факты на казахском или ломаться на смешанных запросах, где часть фразы написана по-русски, часть по-казахски, а термины оставлены на английском.
Поэтому лучше проверять не один общий набор примеров, а три отдельных потока: русский, казахский и смешанный. Для команд в Казахстане это обычная картина. Один клиент пишет: "Нужна выписка за март", другой - "Наурыз айы бойынша шот керек", третий смешивает оба языка в одном сообщении.
В тесты стоит добавить то, на чем модели ошибаются чаще всего:
- суммы, даты и номера договоров
- имена, фамилии и названия компаний
- адреса, филиалы и города
- разговорные сокращения и местный жаргон
Хороший пример проверки: "Списали 12 450 тенге 03.04, карта на имя Алия Нурпеисова, адрес отделения - Астана, ул. Сарайшык 7". Слабая модель может переписать текст гладко, но потерять сумму, перепутать имя или упростить адрес. Для рабочей функции это уже ошибка, даже если ответ звучит уверенно.
Смотрите не только на стиль. Проверяйте смысл: сохранила ли модель факт, число, имя, просьбу клиента и язык ответа. Если функция делает выжимку, проверьте, не исчезают ли детали. Если функция отвечает клиенту, следите за тоном. Текст должен быть простым, спокойным и без канцелярита.
На практике часто выигрывает не самая сильная модель из общего рейтинга, а та, что ровнее держит русский и казахский без потери фактов. Если у вас один шлюз для доступа к нескольким провайдерам, этот тест провести намного проще: можно прогнать один и тот же набор запросов по разным семействам и сразу увидеть, где ломается смысл, а не только стиль.
Какой формат ответа нужен функции
Семейство моделей часто выбирают не по качеству текста, а по тому, насколько стабильно модель держит нужный формат. Если функция должна запускать действие, записывать данные в CRM или строить карточку в интерфейсе, красивый ответ сам по себе не помогает.
Сначала зафиксируйте один основной тип вывода. Свободный текст подходит для объяснения, черновика письма или краткого ответа оператору. JSON нужен там, где ответ читает код. Таблица удобна для человека, когда он сравнивает варианты. Вызов инструмента нужен, если модель должна выбрать команду и передать аргументы.
Это быстрый фильтр. Две модели могут одинаково хорошо писать текст, но одна стабильно отдает JSON по схеме, а другая ломает поля уже на третьем примере.
Где формат ломается чаще всего
Проверяйте схему не только на обычных запросах. Дайте модели пустой ввод, очень длинный ввод и шумный текст с лишними символами, обрывками фраз и смешанными языками. Именно на таких примерах видно, умеет ли она держать структуру без ручной правки.
Отдельно прогоняйте длинный контекст и вложенные поля. Простая схема с двумя строками редко создает проблемы. А вот массив объектов, вложенные статусы, причины отказа и цитаты из диалога ломаются заметно чаще. Если функция читает длинную переписку и должна вернуть сложный JSON, круг подходящих моделей сразу сужается.
Хороший пример - функция в поддержке, где модель читает диалог клиента и должна вернуть категорию обращения, срочность, короткое резюме и флаг эскалации. Для человека свободный текст еще сработает. Для очереди заявок нужен строгий JSON, иначе интеграция начнет падать.
Сразу заложите повторный запрос. Если модель вернула текст вместо схемы, система может один раз отправить тот же контекст с жестким требованием исправить формат или прогнать ответ через простой этап валидации. Это обычная защита продакшена, а не временный костыль.
Где проходят границы по задержке и бюджету
При выборе модели сначала ставят не оценку качества, а два жестких лимита: время до первого токена и время до полного ответа. Без этих рамок тесты почти всегда уезжают в сторону самой сильной модели, даже если она слишком медленная или дорогая.
В онлайн-сценариях люди замечают паузу почти сразу. Если чат отвечает через 3-4 секунды, интерфейс уже кажется тяжелым. Для фоновых задач правило другое: пользователь не ждет у экрана, значит можно взять модель медленнее, если она дает лучшее качество или ниже цену на большом объеме.
Обычно ориентиры выглядят так:
- чат поддержки и поиск с ответом на экране: первый токен за 1-2 секунды, полный ответ за 5-8 секунд
- помощник внутри рабочего интерфейса: первый токен за 2-3 секунды, если ответ точнее и длиннее
- фоновая классификация, разбор документов, ночные отчеты: важнее цена и стабильность на потоке, а не скорость первого токена
Бюджет считают не по одному красивому примеру, а по тысяче реальных запросов. В расчет входят системный промпт, история диалога, найденные фрагменты из базы знаний, формат ответа и сами выходные токены. Если модель часто ошибается на структуре JSON и вы делаете повторный вызов, цена растет сразу.
Проще считать так: возьмите 1000 типовых запросов за неделю, добавьте среднюю длину контекста, долю повторных попыток и запас на длинные диалоги. После этого сравните не цену модели на бумаге, а стоимость функции в работе. Разница нередко доходит до 1,5-2 раз даже между близкими по тарифу семействами.
На практике полезно прогнать один и тот же набор запросов через несколько моделей и посмотреть две таблицы: задержка и итоговая цена на объем. Если команда работает через один OpenAI-совместимый шлюз, такой тест проще провести без смены SDK и кода. В этом смысле AI Router удобен как единая точка сравнения: можно менять base_url на api.airouter.kz и проверять несколько провайдеров в одном сценарии.
Если модель проходит по качеству, но не укладывается в задержку или бюджет, не отбрасывайте ее сразу. Часто лучше работает связка: более дешевая модель обрабатывает основной поток, а более сильная подключается только для сложных случаев или повторной проверки.
Что проверить по данным до первого теста
Первый фильтр для модели - не качество ответа, а состав данных, которые вы ей отправите. Если не разобрать это заранее, команда быстро упрется в лишние риски: персональные данные уйдут во внешний контур, логи окажутся не там, где вы ожидали, а пилот придется переделывать.
Сначала разметьте сам запрос. Посмотрите, где у вас есть PII, коммерческая тайна, договоры, номера счетов, адреса, диагнозы, записи разговоров или вложения от клиента. Опасные данные часто лежат не в основном тексте, а в истории чата, системном промпте, названии файла и служебных полях.
Потом решите, что именно модель должна видеть в чистом виде. Если номер телефона не влияет на ответ, замаскируйте его до отправки. Если функция работает с обращениями пациентов или банковскими заявками, полезно сразу разделить данные на три группы: что можно отправлять без изменений, что нужно маскировать и что нельзя отправлять во внешний контур вообще.
Проверьте и путь данных после запроса. Где система хранит логи, файлы, ответы модели и временные кэши? Кто может их читать? Как долго они живут? На пилоте это часто упускают, а потом выясняется, что безопасен только сам вызов API, а не соседние сервисы.
Если ваш контур требует хранение данных внутри страны, это нужно проверить до первого теста, а не после удачного демо. Для компаний в Казахстане важны не только модель и цена, но и место обработки, хранения и журналирования. В таких случаях команды часто выбирают шлюз или хостинг, где можно держать данные внутри страны и при этом сохранить привычный OpenAI-совместимый поток работы. У AI Router этот сценарий закрывается на уровне API-шлюза: есть хранение данных внутри Казахстана, маскирование PII, аудит-логи и лимиты на уровне ключа.
В конце зафиксируйте правила письменно: какие метки контента вы ставите, какие аудит-логи собираете и какие лимиты по ключам нужны для команд и сервисов. На это уходит час. Экономия потом измеряется неделями.
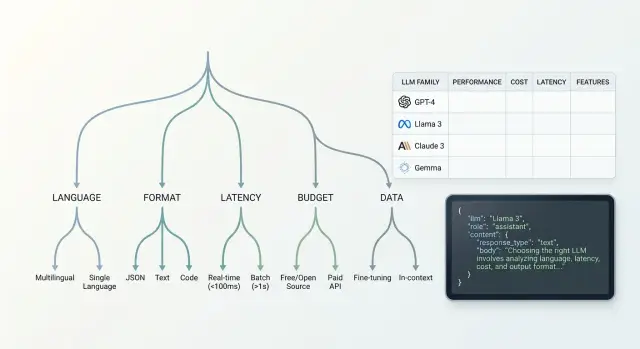
Как собрать дерево решений шаг за шагом
Рабочее дерево удобно строить как серию отсечек. Так выбор идет быстрее: вы убираете неподходящие ветки сразу и не тратите время на дорогие прогоны.
Сначала проверьте язык и качество текста на своих примерах. Возьмите 20-30 реальных запросов для новой функции и посмотрите, как модели пишут на нужном языке, держат терминологию и понимают смешанные сообщения. Если функция работает с клиентской перепиской, оценивайте не только гладкость ответа, но и смысл, тон и точность фактов. Семейства, которые путаются уже здесь, дальше можно не вести.
Потом проверьте формат ответа. Если функция должна вернуть JSON, набор полей или строгую схему, тестируйте именно это. Модель может писать хороший текст и при этом ломать структуру на каждом десятом запросе. Для дерева решений это отдельная развилка: свободный текст, предсказуемый JSON и агентный вывод требуют разных семейств.
Следующий фильтр - задержка и цена. Смотрите на диапазон, а не на один удачный запуск. Если ответ нужен за 2-3 секунды, длинно рассуждающие модели часто отпадут, даже если они сильнее на сложных задачах. Если функция массовая, считайте стоимость на тысяче типовых запросов, а не на одной демо-задаче.
После этого проверьте требования к данным. Где можно хранить промпты и логи, нужна ли маскировка PII, можно ли отправлять данные за пределы страны. Для команд в Казахстане это часто не формальность, а жесткое ограничение.
В финале оставьте 2-3 семейства и прогоните их на одном и том же наборе тестов. Фиксируйте четыре вещи: качество ответа, долю валидной схемы, среднюю задержку и цену. Победитель обычно виден без долгих споров.
Пример для новой функции в поддержке
Представим чат магазина. Покупатель пишет на русском или казахском: спрашивает, где заказ, просит вернуть деньги или жалуется на ошибку в доставке. Функция должна ответить коротко и сразу вернуть JSON с темой обращения, чтобы система направила диалог в нужный сценарий.
При таких условиях дерево решений быстро сужает выбор. Если оператору нужен ответ меньше чем за 2 секунды, крупные медленные модели обычно отпадают первыми. Для линии поддержки это нормальный компромисс: чуть меньше глубины, зато диалог не зависает и очередь не растет.
Дальше смотрят на несколько проверок. Модель должна уверенно понимать и русский, и казахский в коротких живых фразах, а не только в чистых тестовых примерах. Она должна возвращать чистый JSON без лишнего текста до или после скобок. Еще важно, чтобы она не путала тему обращения, если в одном сообщении есть и эмоции, и факт, например задержка доставки плюс просьба о компенсации. И, конечно, она должна укладываться в бюджет, когда таких сообщений тысячи в день.
Последний фильтр здесь часто самый жесткий - работа с персональными данными. В сообщениях поддержки почти всегда есть номер заказа, телефон, иногда адрес. Если отправлять это в модель как есть, команда быстро упрется в требования по данным. Поэтому разумнее сначала скрыть PII, а уже потом просить модель составить ответ и выдать поле topic.
Для команд в Казахстане такой сценарий нередко ведет к быстрому семейству моделей через локальный шлюз. Это позволяет сохранить привычный OpenAI-совместимый вызов и отдельно решить вопросы хранения данных, аудита и маскировки. Но общий вывод тот же для любого стека: в таком кейсе обычно побеждает не самая умная модель, а самая стабильная и быстрая.
Частые ошибки при выборе
Чаще всего команды ошибаются не в сравнении самих моделей, а в постановке рамок. Если не зафиксировать предел по цене, почти всегда побеждает самая сильная модель, а через неделю счет ломает экономику функции. Для новой возможности лучше сразу задать потолок: сколько стоит один успешный ответ, сколько можно тратить в день и где допустим запас.
Другая частая ошибка - тест на нескольких аккуратных примерах. На них почти любая модель выглядит убедительно. Проблемы начинаются на живом потоке: русский с английскими вставками, опечатки, пустые поля, копипаст из Excel, длинные номера заказов, текст без знаков препинания. Если этого нет в наборе для проверки, выводы будут слишком оптимистичными.
Отдельно стоит ловить сбои, которые не видны в красивом демо. Модель может вернуть сломанный JSON, обрезать ответ на середине или не уложиться в лимит по времени. Для функции, которая передает результат другой системе, это часто важнее, чем разница в качестве на пару баллов. Считайте не только точность, но и долю валидных ответов, таймауты и число повторных запросов.
Ошибки с данными обычно всплывают позже всех и поэтому обходятся дороже. Если функция обрабатывает заявки клиентов, медицинские данные или внутренние документы, вопросы логов нельзя откладывать на потом. Нужно заранее решить, где лежат промпты, кто видит аудит-логи, как маскируются PII и можно ли вообще отправлять данные внешнему провайдеру.
Для команд в Казахстане это особенно важно. Требования по хранению данных внутри страны и меткам AI-контента лучше проверить до пилота, а не после первой жалобы службы безопасности. Если вы используете API-шлюз вроде AI Router, часть этих ограничений можно закрыть на инфраструктурном уровне. Но порядок действий в любом случае один: сначала рамки по данным и надежности, потом сравнение качества.
Короткая проверка перед запуском
Перед релизом полезно остановиться на 15 минут и прогнать модель через короткий список. Это дешевле, чем потом чинить плохой JSON, ловить таймауты или объяснять службе безопасности, почему в логах остались персональные данные.
Для выбора модели мало общего впечатления от демо. Нужен набор живых запросов: 20-50 примеров из той функции, которую вы запускаете, и рядом ожидаемые ответы. Если функция работает в поддержке, берите реальные обращения пользователей с разной длиной, ошибками в тексте и смешением русского, казахского и английского.
Проверьте пять вещей:
- есть тестовый набор реальных запросов и понятный эталон ответа
- зафиксированы пределы по задержке, цене на запрос и длине контекста
- есть отдельный тест на формат: JSON, таблица или корректный вызов инструмента
- принято решение по PII, логам и месту хранения данных
- подготовлен запасной маршрут, если основная модель недоступна или стала слишком медленной
Эта проверка особенно нужна там, где ошибка видна сразу. Если функция должна вернуть структуру для CRM, один лишний комментарий от модели уже ломает интеграцию. Если функция читает длинную переписку, короткое окно контекста даст обрывки смысла, даже если на простых примерах все выглядело нормально.
Для команд в Казахстане и Центральной Азии к этому списку часто добавляется вопрос хранения данных внутри страны. Такой выбор лучше делать до запуска. Иначе потом приходится переделывать всю схему под требования безопасности.
Что делать после первого отбора
После первого отбора не раскатывайте модель на всю функцию. Возьмите один узкий сценарий, где легко проверить результат. Например, для поддержки это может быть только ответ на вопрос о статусе заказа, а не весь поток обращений сразу.
Такой пилот быстро показывает слабые места. Вы увидите, где модель ломает формат, где путает язык ответа, а где просто выходит слишком дорогой.
Сразу оставьте две модели: основную и запасную. Основная работает в обычном режиме, запасная нужна на случай скачка цены, сбоев у провайдера или просадки качества. Это простая страховка, которая потом экономит много времени.
Раз в неделю смотрите не только на среднюю оценку команды. Нужны цифры по одним и тем же метрикам:
- стоимость одного успешного ответа или 1000 вызовов
- доля ошибок формата
- средняя задержка и хвост по медленным ответам
- число жалоб пользователей или ручных исправлений
Если одна модель пишет чуть лучше, но ломает JSON в 8% случаев, она часто проигрывает более стабильному варианту. Для продакшена это важнее, чем красивый результат на нескольких удачных примерах.
Когда вы сравниваете провайдеров, удобно держать один OpenAI-совместимый эндпоинт. Тогда команда меняет модель или base_url, а SDK, код и промпты остаются прежними. Для таких проверок AI Router подходит как единая точка доступа: можно быстро переключать модели и провайдеров без новой интеграции под каждого из них.
Если функция работает с обращениями клиентов, проверку данных лучше делать до пилота на реальных запросах. Заранее проверьте хранение данных внутри страны, маскирование PII и аудит-логи. Иначе хороший тест на бумаге быстро упрется в требования безопасности и комплаенса.
Хороший итог первого отбора выглядит довольно приземленно: один сценарий, две модели, понятные метрики и ясное правило, когда система переключается на запасной вариант.
Часто задаваемые вопросы
Почему одна модель редко подходит для всех функций?
Потому что у задач разная цена ошибки. В чате лишняя фраза обычно не мешает, а в интеграции один комментарий вместо чистого JSON уже ломает сценарий.
С чего начать выбор семейства моделей?
Начните с одной узкой функции, а не с общей идеи. Зафиксируйте, что приходит на вход, что должно выйти на выходе, какой формат нужен и сколько секунд у вас есть на ответ.
Сколько реальных примеров нужно собрать до первого теста?
Обычно хватает 20–30 живых запросов, чтобы увидеть первые сбои. Берите не придуманные примеры, а реальные фразы с ошибками, пустыми полями, короткими сообщениями и лишними деталями.
Нужно ли отдельно проверять русский, казахский и смешанные сообщения?
Да, если пользователи пишут на русском, казахском и вперемешку. Модель может звучать гладко на одном языке и терять факты, даты или имена на другом.
Когда функции нужен JSON, а когда обычный текст?
Если ответ читает код, берите JSON или вызов инструмента. Если текст читает человек и ему нужно объяснение, подойдет свободный ответ, но и там лучше заранее ограничить длину и тон.
Какие рамки по скорости лучше задать сразу?
Для чата и интерфейса ставьте жесткий предел по времени до первого токена и до полного ответа еще до сравнения моделей. Если пользователь ждет у экрана, медленная модель быстро начинает раздражать, даже когда пишет лучше.
Как честно посчитать бюджет на модель?
Считайте не цену модели на бумаге, а цену одного успешного ответа на потоке. Добавьте системный промпт, историю, длинные запросы и повторные вызовы, если модель иногда ломает формат.
Что проверить по PII и хранению данных до пилота?
Сначала разберите, какие данные вы вообще отправляете в модель. Номера телефонов, счета, адреса, диагнозы и служебные поля лучше проверить заранее, замаскировать лишнее и отдельно решить, где будут жить логи и кэши.
Нужна ли запасная модель после первого отбора?
Да, это простая страховка. Основная модель закрывает обычный поток, а запасная спасает, когда растет задержка, падает качество или провайдер временно недоступен.
Зачем сравнивать модели через один API-шлюз?
Да, так проще сравнить модели на одном и том же наборе запросов без лишней работы. Если у вас один OpenAI-совместимый эндпоинт, команда может менять base_url и проверять разные семейства без переписывания SDK, кода и промптов.