Вызов инструментов через несколько провайдеров без сюрпризов
Вызов инструментов через несколько провайдеров часто ломается на схемах, типах и кодах ошибок. Разберём, что проверить до продакшена.
Почему один вызов ломается у разных провайдеров
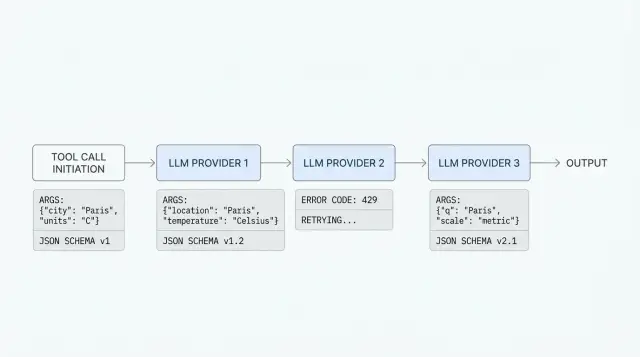
Один и тот же запрос с инструментом часто проходит у одного провайдера и срывается у другого, даже если оба заявляют совместимость с OpenAI API. Формат похож, но детали разные: как модель читает схему, как собирает аргументы, как провайдер возвращает ошибку и что попадает в лог.
В проде это видно сразу. Команда дает модели два инструмента, например find_customer и create_ticket, и ждет один аккуратный tool_call. У первого провайдера модель вызывает find_customer с валидным JSON. У второго кладет числа в строки, добавляет лишнее поле или отвечает обычным текстом вместо вызова функции. У третьего запрос падает еще раньше, потому что схема формально допустима для вашего SDK, но провайдер ждет другой формат.
Общая обертка помогает быстро стартовать, но часто скрывает место поломки. Если адаптер сводит все сбои к сообщению вроде "tool call failed", команда теряет самое важное: что именно модель увидела, какие аргументы вернула и на каком шаге возникла ошибка.
Чаще всего проблема сидит в четырех местах:
- в схеме инструмента, когда один провайдер терпит неточное описание параметров, а другой строго проверяет типы и обязательные поля
- в аргументах, когда модель возвращает JSON-строку, объект, пустой набор полей или лишние данные
- в обработке ошибок, когда где-то вы получаете честный
400, а где-то200с битым содержимым - в логах, если вы не сохраняете сырой запрос и сырой ответ
В реальных интеграциях поломки редко выглядят аккуратно. Модель может выбрать не тот инструмент, вызвать один и тот же инструмент дважды после ретрая, перепутать customer_id с client_id или передать null, хотя поле обязательно. Иногда все работает на десяти тестовых запросах, а затем сыпется на длинных диалогах, когда контекст раздувается и модель начинает экономить на точности аргументов.
Поэтому вызов инструментов через несколько провайдеров нельзя сводить к мысли "у всех один и тот же API". На бумаге совместимость есть. На практике поведение отличается в мелочах, и ломают систему именно они.
Если команда с первого дня пишет в лог схему инструмента, сырой tool_call, итоговый JSON после парсинга и код ошибки провайдера, разбор занимает десять минут. Без этого даже простой сбой легко съедает полдня.
Что различается в схемах инструментов
Один и тот же инструмент редко выглядит одинаково у всех провайдеров. Даже если команда шлет запросы через OpenAI-совместимый шлюз, различия все равно всплывают в описании tools, в правилах JSON Schema и в том, как модель возвращает выбор инструмента.
Где расходятся форматы
Чаще всего ломается не логика функции, а упаковка. У одного провайдера инструмент лежит в tools как объект с type: "function" и вложенным function. У другого те же данные ждут в полях name, description и input_schema без лишнего слоя.
Названия полей тоже не совпадают. Где-то схема аргументов называется parameters, где-то input_schema, а где-то поддерживается только урезанный вариант JSON Schema. Если обертка скрывает эти отличия, она может тихо отбросить часть правил, и модель начнет придумывать аргументы в свободной форме.
Обычно расходятся поддержка enum, default и nullable, отношение к additionalProperties, вложенные объекты и массивы, обязательные поля в required, а иногда даже длина и допустимые символы в имени функции.
JSON Schema тоже не стоит считать общей для всех. Многие модели уверенно работают с type, properties и required, но плохо понимают oneOf, anyOf, сложные ограничения по строкам или глубокую вложенность. Если схема описывает заказ так, будто ее писал юрист, модель обычно отвечает хуже, а провайдер иногда просто отрезает неподдерживаемые части.
Enum особенно коварен. Один провайдер строго заставит выбрать значение из списка, другой пропустит почти любой текст, а третий вернет ошибку, если значения в enum не совпадают по типу. С обязательными полями похожая история: часть систем валидирует их до вызова модели, часть только после, а часть вообще оставляет это на вашей стороне.
Что модель возвращает
Ответ при выборе инструмента тоже не общий. Один провайдер вернет tool_calls с именем функции и JSON-строкой в arguments, другой пришлет структурированный объект, где аргументы уже разобраны, а третий добавит обычный текст рядом с вызовом.
Из-за этого нельзя писать парсер по одному удачному примеру. Если у вас есть get_weather(city, units) и find_order(order_id), проверяйте не только успешный вызов, но и странные случаи: пустые аргументы, лишнее поле, значение вне enum, попытку вызвать сразу два инструмента. Именно на них видно, скрывает ли абстракция различия или честно их показывает.
Как провайдеры читают аргументы
Одна и та же схема не гарантирует одинаковый результат. Одна модель вернет {"count": 3}, а другая пришлет {"count": "3"}. Для кода это мелочь только на бумаге. На деле фильтр, калькулятор или поиск заказа могут уйти по разным веткам.
Путаница со строками, числами и boolean встречается чаще всего. string нередко используют слишком широко: дата, сумма, id клиента и обычный текст приезжают как один тип, хотя правила для них разные. number тоже не так прост: часть моделей превращает "00125" в 125 и ломает идентификатор, а часть округляет 12.00 до 12. С boolean история та же: вместо true и false модель может вернуть "true", "yes", 1 или вообще пустую строку.
С nullable-полями различия тоже заметны. Один провайдер спокойно принимает null, другой ждет, что поле просто исчезнет. С массивами похожая история: где-то [] значит "ничего нет", а где-то модель кладет null или одну строку вместо массива строк. Во вложенных объектах сбои копятся быстрее, потому что модель может пропустить обязательное поле внутри, а снаружи ответ все равно выглядит почти нормальным.
Отдельная проблема - форма ответа. Одни модели возвращают аргументы уже как JSON-объект, другие кладут JSON в строку, которую еще нужно распарсить. Иногда строка почти валидна, но внутри есть лишняя запятая, комментарий или числа в кавычках. Если обертка молча чинит такие ответы, команда потом долго ищет причину странного поведения.
Обычно больше всего пользы дает жесткая договоренность для полей, которые ломаются чаще других:
- даты храните в одном формате, например
"2025-04-27", и не давайте модели свободу писать"27/04"или"следующий понедельник" - суммы передавайте как строку с валютой или как число в минимальных единицах
- идентификаторы почти всегда лучше держать строкой, даже если они состоят только из цифр
- пустое значение выберите одно:
null,""или отсутствие поля
Хорошая абстракция не скрывает эти различия, а проверяет их на входе и на выходе. Если инструмент ожидает строгий JSON, валидируйте каждый аргумент после ответа модели и сохраняйте исходный ответ целиком. Иначе удобная обертка превращает обычную разницу между провайдерами в тихую ошибку в проде.
Как собрать общую обертку по шагам
Если команда шлет запросы через единый шлюз, легко решить, что совместимость уже закрыта. На практике общий endpoint убирает часть рутины, но не отменяет разницу в tool calling у LLM. Хорошая обертка не прячет эти различия, а держит их под контролем.
Начните с самого простого контракта для инструмента. Не добавляйте вложенные объекты, массивы в массивах и длинные необязательные поля, пока без них можно обойтись. Чем проще схема, тем реже модель путает имена аргументов и тем легче понять, где сломался вызов.
Дальше задайте один внутренний порядок работы.
- Опишите каждый инструмент в короткой JSON-схеме с понятными типами и обязательными полями. Если инструменту нужен
city, не называйте это поле тоlocation, тоquery, тоtext. - Проверьте аргументы до отправки в модель. Если схема требует число, не пускайте строку. Если поле обязательно, остановите запрос сразу и верните понятную ошибку своему коду, а не провайдеру.
- Приведите ответы моделей к одному внутреннему формату. Например, храните у себя
tool_name,arguments,call_id,finish_reason, даже если провайдер назвал эти поля иначе или положил их на другой уровень JSON. - Сохраняйте сырой запрос и сырой ответ. Иначе через день никто не вспомнит, модель не увидела инструмент, сломала JSON или провайдер вернул свой формат ошибки.
- Вынесите маппинг ошибок в отдельный слой. Один провайдер вернет 400 за лишнее поле, другой ответит 422, третий пришлет текст без структуры. Ваше приложение должно видеть не зоопарк ответов, а свои коды вроде
INVALID_TOOL_SCHEMA,BAD_ARGUMENTSилиPROVIDER_TIMEOUT.
Такой подход экономит время на разборе сбоев. Допустим, модель вызвала get_customer и передала customerId: "abc", хотя вы ждете число. Если валидация стоит сразу после ответа, ошибка появится в одном месте. Если ее нет, вы получите чужой 400 и начнете гадать, кто виноват: схема, модель, SDK или сам провайдер.
Полезная привычка тут простая: сначала сделайте обертку скучной и строгой. Уже потом добавляйте удобство, ретраи и редкие поля.
Простой сценарий с двумя инструментами
Возьмем чат-бота поддержки интернет-магазина. Он умеет делать две вещи: найти заказ по номеру и создать заявку, если клиенту нужна помощь. Снаружи это выглядит просто, но именно на таком случае чаще всего видно, где провайдеры ведут себя по-разному.
Инструменты можно описать так:
[
{
"name": "find_order",
"description": "Найти заказ по номеру",
"parameters": {
"type": "object",
"properties": {
"order_id": { "type": "string" }
},
"required": ["order_id"]
}
},
{
"name": "create_ticket",
"description": "Создать заявку в поддержку",
"parameters": {
"type": "object",
"properties": {
"order_id": { "type": "string" },
"reason": { "type": "string" },
"urgent": { "type": "boolean" }
},
"required": ["order_id", "reason"]
}
}
]
Пользователь пишет: "Где мой заказ 45128? Если он потерялся, создайте заявку". Один провайдер может вернуть аккуратный вызов find_order с JSON вроде {"order_id":"45128"}. Приложение ищет заказ, видит проблему с доставкой и на следующем шаге получает второй корректный вызов: {"order_id":"45128","reason":"задержка доставки","urgent":true}.
Теперь неприятный вариант. Другой провайдер на том же промпте вернет почти то же самое, но сломает типы: {"order_id":45128,"reason":"задержка доставки","urgent":"true"}. Для человека разница мелкая. Для кода это уже два риска: номер заказа стал числом, а флаг срочности стал строкой.
Даже если команда ходит через единый OpenAI-совместимый шлюз, такие различия все равно нужно ловить в приложении. Шлюз упрощает доступ к моделям, но не отменяет проверку аргументов перед вызовом внутренних систем.
В первом случае все понятно: валидируете JSON, вызываете инструмент и пишете результат в лог. Во втором приложение не должно молча отправлять сломанные данные дальше. Порядок простой:
- проверить имя инструмента и схему аргументов
- приводить безопасные типы только по явным правилам
- отклонять опасные или двусмысленные значения
- возвращать модели понятную ошибку или просить уточнение
order_id часто можно привести к строке без риска. А вот urgent: "true" лучше не угадывать, если от этого зависит приоритет очереди или уведомление сотрудника. В таком случае приложение может вернуть модели сообщение вроде: "Поле urgent должно быть boolean" и попросить повторить вызов инструмента.
Вывод простой: общая обертка удобна, но она должна быть строгой на входе. Иначе один провайдер даст рабочий JSON, а другой тихо протащит ошибку в CRM или тикет-систему.
Где команды чаще ошибаются
Первая ошибка проста: команда видит OpenAI-совместимый API и думает, что поведение тоже будет одинаковым. На деле совпадает форма запроса, а не все детали исполнения. Один провайдер молча пропустит лишнее поле, другой вернет ошибку. Один вернет аккуратный tool_calls, другой пришлет аргументы в виде строки с мелкой поломкой JSON.
Это часто всплывает там, где уже есть единый шлюз. Например, AI Router дает один OpenAI-совместимый endpoint, так что можно оставить прежние SDK, код и промпты. Но различия между провайдерами никуда не исчезают, поэтому схемы, аргументы и ответы все равно нужно проверять явно.
Вторая частая ошибка - слишком рано прятать provider-specific поля в общей обертке. Команда оставляет только имя инструмента и аргументы, а все остальное отрезает как "шум". Потом теряются настройки строгой схемы, режим выбора инструмента, формат возврата аргументов и другие детали, без которых поведение уже не повторяется.
Обычно лучше держать два слоя. Первый - общий контракт для имени инструмента, схемы и трассировки. Второй - отдельные поля провайдера, которые вы пока не нормализовали. И обязательно сохранять сырой ответ до постобработки и фиксировать, какой адаптер менял запрос и ответ.
Третья ошибка бьет по отладке. Команды склеивают все сбои в один код вроде TOOL_CALL_FAILED. После этого невозможно быстро понять, где сломалось: модель не собрала JSON, провайдер отверг схему, ваш backend не принял аргументы или сам инструмент упал по таймауту.
Еще одна ловушка - доверять модели проверку обязательных аргументов. Модель может забыть customer_id, подставить строку вместо числа или придумать значение enum, которого нет в вашей системе. Проверять это должен ваш код до вызова инструмента, а не после странного ответа от backend.
Обычный пример: инструмент get_invoice ждет customer_id и month. Один провайдер передаст оба поля. Другой решит, что customer_id можно "понять из контекста", и пропустит его. Если backend не валидирует запрос, вы получите неясную ошибку 500 и потратите час на поиск причины.
И последняя частая ошибка - запуск в прод без тестового набора вызовов. Нужны хотя бы фиксированные кейсы для нормального запроса, пропущенного обязательного поля, лишнего поля, неверного типа и длинного аргумента. Такой набор стоит гонять при каждом изменении схемы, SDK и провайдера.
Как разбирать сбои без гадания
Если один и тот же tool calling у LLM то проходит, то ломается у разных провайдеров, проблема почти всегда не в "магии модели", а в плохом разборе причин. Смешивать все ошибки в одну папку "не сработало" - верный способ неделями чинить не то.
Сначала разделяйте сбои на три типа. Ошибки схемы появляются, когда описание инструмента или формат аргументов не совпали с тем, что ждет провайдер или ваш валидатор. Ошибки модели выглядят иначе: схема формально верная, но модель выбрала не тот инструмент, пропустила обязательное поле или подставила странное значение. Сетевые сбои проще всего узнать по таймаутам, 429, 5xx и обрывам соединения.
Это разделение нужно не для отчетов, а для действий. Ошибку схемы не лечат повторной отправкой. Ошибку модели редко чинит обычный retry, зато помогает более жесткая схема, явные примеры и отдельная проверка обязательных полей. Сетевой сбой обычно требует retry, backoff или переключения на другого провайдера.
Минимальный набор логов небольшой: имя инструмента, аргументы до и после нормализации, provider id, request id и результат валидации с текстом ошибки. Без этого разбор идет вслепую.
Особенно важно показывать не просто факт провала, а точное место. Сообщение вроде "invalid arguments" почти бесполезно. Сообщение "field: customer_id, expected: integer, got: "12A"" уже можно отдать разработчику или сразу вернуть в цепочку исправления.
Хорошая практика - сохранять неудачные вызовы как отдельные примеры для регрессии. Не только сырой ответ модели, но и весь контекст: описание инструмента, промпт, ответ провайдера, нормализованные аргументы и итог проверки. Тогда после правки обертки вы прогоняете старые падения и сразу видите, стало ли лучше.
Маленький пример: модель вызвала get_balance, передала account="00125", а ваш валидатор ждет число. Если это ошибка схемы, вы меняете тип или нормализацию строки в число. Если другой провайдер в том же сценарии вообще выбрал search_customer, это уже ошибка модели. Если оба варианта иногда падают на таймауте, проблема в сети, а не в аргументах.
Когда запросы идут через шлюз вроде AI Router, полезно добавлять в логи не только внутренний id, но и id провайдера, куда ушел вызов. Иначе два внешне одинаковых сбоя будут выглядеть как один, хотя причина у них разная. На практике это экономит много часов.
Короткий список проверок перед запуском
Перед релизом полезнее не писать еще десятки тестов на все случаи, а прогнать несколько неприятных сценариев руками и в автотестах. Именно на них чаще всего ломается вызов инструментов через несколько провайдеров, даже если запросы выглядят совместимыми.
Один и тот же инструмент должен называться одинаково везде, без тихих расхождений вроде get_user, getUser и fetch_user. Для модели это уже разные функции. Если у вас есть маршрутизация через общий шлюз, ошибка в имени не исчезнет, а просто всплывет позже и запутает разбор.
Перед запуском проверьте пять вещей:
- сверьте имена инструментов, значения
enumи описания аргументов у всех провайдеров, которые пойдут в прод - пройдите обязательные поля и значения по умолчанию
- убедитесь, что система переживает пустой tool call
- проверьте реакцию на лишнее поле и неверный тип
- посмотрите, можно ли по логам восстановить всю цепочку от входного prompt до финального ответа модели
Небольшой пример: инструмент check_order ждет order_id как строку. Один провайдер молча пропускает число 12345, другой возвращает ошибку схемы, третий отдает tool call с пустыми аргументами. Если приложение заранее нормализует тип, ловит пустой вызов и пишет в лог исходный payload, сбой чинится за 10 минут, а не за полдня.
Отдельно стоит проверить, что логи не теряют контекст между ретраями. Иначе вы увидите только финальную ошибку, но не поймете, модель сломала схему, прокси обрезал поле или ваш код неверно собрал аргументы.
Что сделать дальше
После теории не стоит сразу писать "универсальный" слой на все случаи. Сначала возьмите 2-3 провайдера, которых вы правда планируете использовать, и прогоните через них один и тот же набор тестов. Иначе очень быстро получится код, который выглядит аккуратно, но ломается на первом реальном tool calling у LLM.
Хороший стартовый набор простой: один инструмент без обязательных полей, один с вложенным объектом в аргументах и один сценарий, где модель должна отказаться от вызова. Этого уже хватает, чтобы увидеть разницу в схемах аргументов функций, именах полей, порядке сообщений и тексте ошибок. Часто проблема не в самой функции, а в том, как провайдер ожидает описать JSON Schema или как возвращает невалидные аргументы.
Полезно собрать короткую таблицу и держать ее рядом с кодом, а не в заметках. Обычно в ней хватает пяти колонок: как провайдер принимает описание инструмента, как модель возвращает аргументы, что приходит при невалидном JSON, как выглядит отказ от вызова инструмента и какие поля вы обязаны нормализовать у себя.
Такая таблица быстро показывает, где у вас общий контракт, а где честнее оставить отдельную ветку. Одна абстракция полезна только до тех пор, пока не скрывает важные отличия.
Потом закрепите правила нормализации прямо в коде команды. Не в голове и не в wiki, а в тестах и в одном слое адаптеров. Например, договоритесь, что перед вызовом любого инструмента вы всегда делаете три вещи: приводите аргументы к одному формату, валидируете обязательные поля и сохраняете сырой ответ провайдера для разбора сбоев.
Если вам нужен один OpenAI-совместимый вход для разных моделей, это лучше проверять заранее на своем трафике. В случае AI Router удобно то, что можно сменить только base_url на api.airouter.kz и продолжить работать с привычными SDK. Но перед запуском все равно стоит посмотреть, как через шлюз проходят tool calls у разных провайдеров, что видно в аудит-логах и где срабатывают rate limits на уровне ключа.
Если после статьи сделать только одно практическое действие, пусть это будет общий тестовый прогон на одинаковых промптах и одинаковых инструментах. Тогда вызов инструментов через несколько провайдеров перестает быть лотереей и становится предсказуемой частью системы.
Часто задаваемые вопросы
Почему один и тот же вызов инструмента проходит не у всех провайдеров?
Потому что совпадает только общая форма API, а детали у всех разные. Один провайдер строже проверяет схему, другой иначе упаковывает tool_call, третий возвращает 200 с битым содержимым, и ваш код получает совсем другой сценарий.
Что логировать в первую очередь, чтобы быстро найти поломку?
Сохраняйте схему инструмента, сырой запрос, сырой ответ, tool_call до парсинга и результат валидации после парсинга. Без этих данных команда гадает, где сбой: в схеме, в модели, в адаптере или в провайдере.
Какие части схемы инструментов чаще всего вызывают проблемы?
Чаще всего ломаются required, типы полей, enum, nullable и лишние поля. Если хотите меньше сюрпризов, начните с простых type, properties и required, а сложные конструкции вроде oneOf и глубокой вложенности добавляйте только когда без них нельзя.
Как описывать инструмент, чтобы модель реже путала аргументы?
Делайте схему короткой и однозначной. Если поле называется order_id, не меняйте его на id или customer_order, и не давайте модели свободу угадывать формат дат, сумм и идентификаторов.
Что делать, если модель вернула число вместо строки или строку вместо boolean?
Не чините такие ответы молча. Валидируйте каждый аргумент после ответа модели и приводите типы только по явным правилам, например 45128 в строку для order_id, если это безопасно.
Если я хожу через OpenAI-совместимый шлюз, валидация уже не нужна?
Нет, не снимает. Единый endpoint убирает разницу в подключении, но не делает поведение моделей одинаковым, поэтому приложение все равно должно проверять схему, аргументы и коды ошибок.
Как поступать с невалидным JSON в arguments?
Сначала зафиксируйте сырой ответ и покажите точную ошибку парсинга. Потом решите, можно ли попросить модель повторить вызов или лучше отклонить ответ сразу, если JSON двусмысленный или опасный для вашего backend.
Когда имеет смысл делать retry, а когда нет?
Повторный запрос помогает в основном при таймаутах, 429 и временных 5xx. Если провайдер отверг схему или модель стабильно путает аргументы, retry только тратит время и деньги, тут нужно менять схему, промпт или слой валидации.
Как проверить tool calling перед запуском в прод?
Прогоните одни и те же промпты на одних и тех же инструментах у всех провайдеров, которых вы правда пустите в прод. Обязательно проверьте нормальный вызов, пустые аргументы, лишнее поле, неверный тип и длинный диалог, где контекст уже вырос.
Как устроить общую обертку и не спрятать важные отличия?
Держите два слоя. Внутри приложения храните общий формат вроде tool_name, arguments, call_id и свой код ошибки, а рядом оставляйте provider-specific поля и сырой ответ, чтобы не потерять важные детали при разборе сбоев.