Разделение prefill и decode для длинных документов
Разбираем, когда разделение prefill и decode снижает задержку на длинных документах, а когда добавляет лишние очереди, риски и расходы.
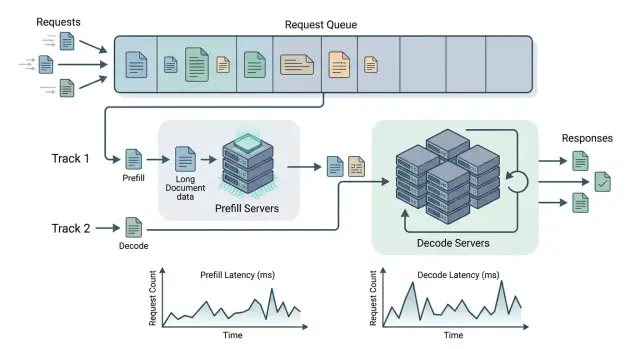
Почему длинные документы создают узкое место
Проблема начинается еще до генерации ответа. Когда модель получает длинный договор, инструкцию или большую переписку, она сначала должна обработать весь вход целиком. Этот этап называют prefill. Чем больше токенов во входе, тем дольше GPU занят только чтением и подготовкой внутреннего состояния модели.
В коротком чате это почти незаметно. Но на документе в 80 или 150 страниц разница уже большая: один такой запрос может занять ресурс дольше, чем десятки коротких вопросов от поддержки, поиска по базе знаний или обычного ассистента внутри продукта.
Из-за этого страдает не только сам длинный запрос. Если короткие и длинные задачи идут через одну очередь, тяжелый вход начинает тормозить всех. Даже при умеренном трафике задержки растут быстрее, чем ожидает команда. Иногда хватает нескольких крупных запросов подряд.
Самый неприятный эффект виден в TTFT, времени до первого токена. Пользователь еще не ждет длинный и красивый ответ. Он хочет понять, что система вообще начала отвечать. Но decode не стартует, пока ресурс занят prefill или пока очередь не дошла до этого запроса. Интерфейс молчит, хотя сама генерация потом может пройти быстро.
Это хорошо видно на внутреннем помощнике для юристов. Один сотрудник отправляет на разбор длинный договор, а в это же время другие задают короткие вопросы: "какой штраф указан в пункте 7?" или "сравни две версии абзаца". Если все это попадает в один GPU-пул, длинный документ сдвигает время ответа для всей команды.
Именно поэтому разделение prefill и decode выглядит разумно. Узкое место часто не в том, что модель долго пишет, а в том, что она слишком долго читает длинный контекст на общем ресурсе.
Что меняется при разделении prefill и decode
Когда один и тот же пул GPU и читает длинный вход, и генерирует ответ, длинные запросы мешают всем остальным. Большой договор или пачка инструкций занимают память и время там, где система уже могла бы отдавать токены пользователю.
После разделения нагрузка расходится по двум пулам. Prefill-ресурсы прогоняют длинный текст и готовят состояние модели, а decode-ресурсы заняты только пошаговой генерацией. Меняется не только схема запуска, но и поведение очередей.
У этих этапов разный профиль нагрузки. Prefill лучше переносит крупные куски входа и может выдержать небольшую паузу, если потом быстро обработает большой контекст. Decode, наоборот, чувствителен к любому сбою. Пользователь сразу замечает, если токены идут рвано или первый ответ появляется слишком поздно.
Из-за этого команда перестает смотреть на одну общую цифру задержки и начинает разбирать путь запроса по этапам: ожидание prefill, время prefill, передача состояния, ожидание decode и сама генерация. Такой разрез полезнее, чем просто "ответ за 9 секунд".
На практике это быстро меняет разговор внутри команды. Если выросло время до первого токена, уже можно понять причину: длинные входы забили prefill-пул или decode-ноды заняты другими сессиями. Без разделения обе проблемы сливаются в одну, и команда часто чинит не то место.
Пример простой. Юрист отправляет в LLM 120-страничный договор и просит найти спорные пункты. В общей очереди этот запрос легко задерживает короткие диалоги саппорта. При разделении отдельный пул обрабатывает весь документ, а генерация ответа идет на других ресурсах, которые не простаивают под длинным вводом.
Для LLM-шлюза вроде AI Router это еще и вопрос маршрутизации. Если запросы идут через один OpenAI-совместимый слой, проще увидеть, где не хватает мощности для длинного контекста, а где уже упирается decode. Тогда проблема выглядит не как абстрактное "модель тормозит", а как понятная карта узких мест.
Когда схема действительно помогает
Разделение prefill и decode полезно там, где модель заметно дольше читает, чем отвечает. Если пользователь задает один вопрос по договору на 150 страниц, большая часть времени уходит именно на вход. В такой ситуации разнос этапов по разным ресурсам часто дает реальный выигрыш.
Обычно это видно по TTFT. Пользователь еще не видит ни одного токена, а GPU уже занят обработкой большого контекста. Если трассировки показывают, что почти все время уходит в prefill, схема начинает иметь смысл.
Лучше всего она работает там, где вход длинный, а выход короткий. Например, сервис читает договор, отчет, анкету или медкарту, а потом отвечает в нескольких предложениях: нашелся ли нужный пункт, есть ли риск, каких данных не хватает, что не совпадает с шаблоном.
Есть несколько типичных признаков, что схема подойдет:
- документы большие, а ответы короткие;
- длина входа сильно меняется от запроса к запросу;
- пользователи часто загружают договоры, отчеты, анкеты или медкарты;
- проблема видна именно в TTFT, а не в общей длине ответа;
- мониторинг показывает, что prefill нагружен сильнее decode.
Сильный разброс по размеру входа особенно важен. Если один запрос приходит с 3 тысячами токенов, а следующий с 120 тысячами, общий пул начинает вести себя неровно. Короткие запросы ждут рядом с длинными, и задержка растет даже там, где это не нужно. Выделенный ресурс под prefill сглаживает эту очередь.
Хороший пример - тот же помощник юриста. Утром он получает короткие вопросы по шаблонам, а днем сотрудники массово загружают сканы договоров и длинные приложения. Без разделения один тяжелый пакет документов легко тормозит всех. С разделением prefill берет на себя чтение и подготовку контекста, а decode спокойно отдает короткие ответы без лишней паузы.
В системах с маршрутизацией это особенно заметно. Тяжелый prefill можно отправлять на более подходящий ресурс, а decode держать на группе с низкой задержкой. Такой подход полезен там, где важна предсказуемость: пользователь прощает короткий ответ, но плохо переносит долгую тишину перед первым токеном.
Если метрики не показывают явного перекоса на prefill, схема вряд ли окупится. Но когда сервис в основном читает длинные документы и выдает короткий вывод, эффект обычно виден быстро.
Когда она только добавляет сложность
Разделение prefill и decode не дает пользы само по себе. Если почти все запросы короткие, вы просто строите более сложную схему без заметного выигрыша. В системе становится больше точек отказа, больше очередей и больше причин для странных задержек.
Частая ошибка выглядит так: команда замечает редкие длинные документы и заранее перестраивает весь инференс-контур. Но если 90% трафика идет с коротким контекстом, отдельный пул под prefill будет простаивать. Появятся новые правила маршрутизации, отдельные лимиты, новые алерты и лишняя отладка, а время ответа почти не изменится.
Еще один плохой сценарий - когда система упирается не во вход, а в decode. Такое бывает, если документ не очень длинный, а ответ должен быть развернутым: сводка на страницу, подробное объяснение или длинный JSON. Тогда дорогая часть запроса начинается после prefill. Вы ускоряете меньший кусок пайплайна, а пользователь все равно ждет почти столько же.
Ровный трафик тоже меняет картину. Если нет резких всплесков, общий пул часто справляется лучше, чем два специализированных. Он проще в управлении и обычно загружается ровнее. Отдельные пулы легко дают обратный эффект: один недогружен, второй перегрет.
Самая плохая идея - внедрять такую схему без метрик по этапам. Если команда не меряет TTFT, длительность prefill, скорость decode, длину очереди и задержку между пулами, спор быстро превращается в гадание.
Тогда легко принять сетевой переход за оптимизацию. На практике дополнительный хоп между пулами, сериализация состояния и повторная проверка лимитов могут съесть весь выигрыш. Иногда это всего лишь десятки миллисекунд на запрос, но на стабильном потоке они быстро накапливаются.
Если команда уже использует единый шлюз вроде AI Router для работы с разными моделями, внутреннее разделение стоит вводить только после замеров. Иначе поддержка станет запутаннее: сложнее разбирать инциденты, искать узкое место и объяснять команде, где именно пропало время.
Когда контекст короткий, decode доминирует, а трафик предсказуем, простой контур обычно выигрывает.
Как внедрить схему по шагам
Сначала снимите базовую картину. Без нее сравнивать будет не с чем. Замерьте TTFT, скорость генерации в токенах в секунду и реальную длину входа. Смотрите не только на среднее, но и на p95: длинные документы чаще всего портят именно хвост задержки.
Потом разложите трафик по простым диапазонам контекста. Не нужно сразу вводить десяток классов. Обычно хватает трех корзин: короткие запросы, средние и длинные. Если у вас много договоров, отчетов или переписки на десятки страниц, граница для длинных входов станет видна довольно быстро.
После этого поднимите два небольших пула. Один занимается prefill, то есть чтением длинного входа и сборкой состояния. Второй обрабатывает decode, где важна ровная выдача токенов. На старте не переводите весь трафик. Возьмите только часть длинных запросов, чтобы увидеть разницу и не утонуть в отладке.
Правило маршрутизации должно быть простым. Например: короткий вход идет по старому пути, длинный отправляется в отдельный prefill-пул, decode всегда остается в своем пуле, а при ошибке запрос возвращается на обычный маршрут. Такое правило легко проверить и легко откатить.
Если у вас уже есть единый OpenAI-совместимый шлюз, логику лучше держать в одном месте, а не дублировать по сервисам. Это снижает число расхождений между командами и упрощает тесты.
Дальше проверьте поведение в двух режимах: на пике и в тихие часы. В пик схема часто улучшает TTFT для длинных документов. В спокойное время она, наоборот, может стоить дороже из-за простаивающего пула и лишних переключений.
Считать только среднюю задержку мало. Сравните стоимость на тысячу запросов, загрузку GPU, долю таймаутов и p95 по TTFT. Иногда первый токен приходит быстрее, но общий счет растет на 15-20%, а поддержка становится заметно сложнее.
Нормальный тест выглядит скучно, и это хороший признак. Если после недели замеров выигрыш виден только в лаборатории, а не в живом трафике, схему лучше не тащить в прод.
Простой сценарий с длинным договором
Представим банк, который загружает договор на 120 страниц и просит модель проверить его по 12 пунктам: где есть риск штрафов, как прописано расторжение, кто меняет тарифы, какие сроки уведомления и где формулировки слишком расплывчаты. Для человека это обычная юридическая проверка. Для LLM это тяжелый запрос с длинным контекстом.
Самый долгий кусок здесь не ответ, а чтение документа. На этапе prefill модель прогоняет через себя весь текст договора и собирает внутреннее состояние. Это занимает заметное время и сильнее нагружает GPU, чем короткая генерация результата.
Потом начинается decode. Модель уже не читает договор заново, а пишет вывод: 12 пунктов с пометками риска и короткими пояснениями. Ответ может занять одну-две страницы. То есть вход огромный, а выход сравнительно небольшой.
Если такие договоры идут через тот же ресурс, что и обычные запросы, очередь быстро портится. Один тяжелый prefill может задержать короткие задачи: суммаризацию письма, разбор чата с клиентом, классификацию заявки. Пользователь получает медленный ответ там, где текст был маленьким и задача простой.
Здесь разделение prefill и decode действительно может помочь. Договор уходит на ресурс, который рассчитан на длинное чтение, а генерация ответа идет на другом ресурсе, где важна низкая задержка. В едином LLM-шлюзе это особенно полезно, когда рядом живут и длинные документы, и обычные чат-запросы. Один договор перестает держать в заложниках весь поток.
Но у схемы есть цена. Если такие документы приходят редко, например несколько раз в неделю, хлопот может оказаться больше, чем пользы. Придется держать отдельные пулы ресурсов, следить за передачей состояния между этапами, настраивать ретраи, метрики и отладку. Для редких задач часто проще ограничить очередь для длинных запросов или вынести их на отдельный маршрут.
Вывод у этого сценария простой: чем чаще в системе появляются очень длинные документы, тем больше смысла в отдельном ресурсе для prefill. Если поток редкий, схема красиво смотрится на диаграмме, но быстро надоедает в поддержке.
Ошибки, которые ломают схему
Чаще всего команда ломает все еще на уровне наблюдаемости. Она складывает prefill и decode в один график общей задержки и получает красивую среднюю цифру. Проблема в том, что такой график прячет причину: prefill уже забит длинным контекстом, а decode почти не страдает, или наоборот.
Если метрики смешаны, вы не видите, где именно растет очередь и что портит ответ пользователю. Достаточно держать хотя бы четыре сигнала отдельно: очередь до prefill, время prefill, скорость decode и p95 с p99 раздельно для коротких и длинных запросов.
Среднее почти всегда успокаивает зря. Пользователь замечает не среднюю задержку, а редкий ответ, который завис на 18 секунд.
Вторая частая ошибка - отправлять в новый пул все длинные запросы без понятного порога. Длина сама по себе еще не означает, что запросу нужно разделение. Вход на 9 тысяч токенов может спокойно пройти через общий пул, а договор на 60 тысяч с тяжелым системным префиксом уже надолго забьет prefill. Если порог выбрали на глаз, вы просто перегоняете лишний трафик в новую ветку.
Еще одна проблема - слишком маленький выделенный пул. Команда убирает очередь из общего пула и тут же создает новую, только в другом месте. На бумаге архитектура выглядит умнее. Под реальной нагрузкой длинные документы просто выстраиваются в другую линию, а p95 становится хуже.
Часто забывают и про кэш промптов. Это дорогая ошибка. Если у вас повторяются системные инструкции, шаблоны ответа, юридические дисклеймеры или первые страницы типового договора, кэш иногда дает больше пользы, чем отдельный пул. И поддерживать его проще.
Хороший пример - обработка длинного договора. Если каждый запрос заново прогоняет один и тот же префикс с правилами, классификаторами и служебным текстом, prefill тратит время впустую. В этот момент команда может думать, что ей нужна новая схема маршрутизации, хотя сначала стоило убрать повтор.
Плохой признак легко узнать: система стала сложнее, а причина задержки все еще не ясна. Если вы не видите prefill и decode по отдельности, не считаете p95 и p99 и не проверили кэш, разделение быстро превращается в дорогую настройку с лишней очередью.
Быстрая проверка перед запуском
Эту схему стоит включать по цифрам, а не по ощущению. Если команда не понимает, где именно уходит время, разделение prefill и decode быстро становится еще одним слоем поддержки, который трудно объяснить и еще труднее чинить.
Перед запуском полезно проверить несколько вещей. Сначала посмотрите, какая доля задержки уходит в prefill. Если там сидит больше половины общего времени, смысл теста есть. Если основная боль уже в decode, выигрыш будет скромным.
Потом сравните длину входа и выхода. Когда средний ответ в несколько раз короче исходного документа, отдельные ресурсы под prefill часто дают заметный эффект. После этого оцените разброс длины запросов. Если один запрос несет 3-5 тысяч токенов, а другой 30-50 тысяч, общий пул почти всегда работает неровно. Разница хотя бы в 5-10 раз уже повод проверить раздельную схему.
Следить нужно не за одной метрикой, а хотя бы за тремя: TTFT, пропускной способностью и длиной очереди. Если TTFT падает, но очередь на decode растет, значит вы просто передвинули узкое место. И еще до запуска нужен простой откат на один пул. Переключение должно занимать минуты, а не отдельный спринт.
Хороший признак выглядит так: пользователи отправляют длинные договоры, отчеты или переписки, модель читает большой вход, а отвечает коротко и по делу. В этом режиме prefill нагружает систему сильнее, чем генерация ответа. Тогда разделение может заметно сократить время до первого токена и сделать очередь ровнее.
Плохой признак тоже легко узнать. Если документы похожи по длине, ответы почти такие же длинные, а команда пока смотрит только на среднюю задержку, схема даст мало пользы. Она добавит новые правила маршрутизации, новые очереди и больше точек отказа.
Для команд, которые уже ведут продовые LLM-сценарии через единый API-шлюз, проверка обычно сводится к журналам запросов и паре нагрузочных прогонов. Этого хватает, чтобы понять простую вещь: вы действительно лечите prefill или просто усложняете архитектуру приложения.
Что делать дальше
Не раскатывайте разделение prefill и decode на весь поток сразу. Возьмите один тип длинных документов, где вход более-менее стабилен: договоры на 80-150 страниц, тендерные пакеты или длинные медицинские выписки. Запустите A/B-тест на части трафика и сравните обычный маршрут с раздельной схемой на одинаковых промптах.
Смотрите не только на среднюю задержку. На длинных документах среднее часто обманывает: один быстрый прогон скрывает медленный prefill в часы пик. Разбейте замеры по модели, длине входа, полной стоимости запроса и времени до первого токена. Отдельно отметьте ошибки маршрутизации, повторные prefill и случаи, когда decode ждет свободный ресурс дольше, чем вы экономите.
Полезно собрать простую таблицу: модель и провайдер, длина входа в токенах, время prefill и decode, цена полного ответа и доля запросов, где схема дала выигрыш. Через несколько дней станет видно, где длинный контекст действительно окупает усложнение архитектуры, а где нет. Обычно граница проходит не по отрасли, а по длине документов и числу повторных запросов к одному и тому же тексту.
Если документы нельзя хранить вне страны, второй вопрос откладывать не стоит: нужен ли локальный хостинг моделей с открытыми весами. Для банков, госсектора и части healthcare это обычное требование. В таком случае стоит сравнивать не только облачные маршруты, но и локальный контур для open-weight моделей.
Если команда проверяет несколько маршрутов сразу, не стоит плодить отдельные интеграции под каждого провайдера. Если у вас уже есть стек под OpenAI API, AI Router может упростить такой тест: достаточно сменить base_url на api.airouter.kz и отправлять те же SDK, код и промпты через один OpenAI-совместимый эндпоинт. Для экспериментов это удобно: меньше времени уходит на обвязку, а логи и аудит проще смотреть в одном месте.
Нормальный итог этого этапа выглядит прозаично, и это хорошо. У вас есть порог по длине входа, список моделей для prefill и decode и понятный ответ, где схема экономит секунды и деньги, а где только усложняет систему.
Часто задаваемые вопросы
Когда разделение prefill и decode реально дает пользу?
Разделяйте этапы, когда сервис читает очень длинный вход, а отвечает коротко. Обычно это договоры, отчеты, анкеты и медкарты, где TTFT растет из-за чтения контекста, а не из-за самой генерации.
Как понять, что тормозит именно prefill?
Посмотрите трассировки по этапам. Если большая часть времени уходит до первого токена, а prefill загружен сильнее decode, проблема почти наверняка во входе.
Есть ли смысл в такой схеме, если запросы в основном короткие?
Чаще всего нет. Если почти весь трафик короткий и предсказуемый, общий пул проще, дешевле и стабильнее.
Что делать, если длинные документы приходят редко?
В таком случае сначала сделайте отдельный маршрут или ограничьте очередь для тяжелых запросов. Держать постоянный отдельный пул ради нескольких документов в неделю обычно невыгодно.
Какие метрики нужно снять перед запуском?
Смотрите на TTFT, p95 и p99, длину входа в токенах, длительность prefill, скорость decode и длину очередей. Среднее значение само по себе мало что показывает, потому что длинные документы портят хвост задержки.
Поможет ли схема, если ответ у модели тоже длинный?
Скорее всего, выигрыш будет небольшим. Если модель потом долго пишет сводку, большой JSON или длинное объяснение, decode сам становится узким местом.
Как внедрить разделение без лишнего риска?
Запускайте ее на части трафика и оставьте быстрый откат на старый путь. Обычно хватает простого правила: длинные входы идут через отдельный prefill-пул, остальные остаются на обычном маршруте.
Какие ошибки чаще всего ломают эту схему?
Чаще всего команды смешивают метрики prefill и decode в один график и не видят причину задержки. Еще вредят порог длины "на глаз", слишком маленький выделенный пул и лишний сетевой переход между этапами.
Может ли prompt cache дать больше пользы, чем разделение пулов?
Да, нередко. Если у вас повторяются системные инструкции, шаблоны ответа или одинаковые части документа, кэш убирает лишний prefill проще, чем новая архитектура.
Как единый шлюз вроде AI Router помогает проверить эту идею?
Когда трафик идет через один OpenAI-совместимый слой, команде проще сравнить маршруты и увидеть, где упирается prefill, а где decode. В AI Router можно оставить те же SDK, код и промпты, сменив только base_url, а логи и аудит смотреть в одном месте.