Трансграничная передача данных в LLM: риски вне API
Трансграничная передача данных в LLM возникает не только в вызове модели, но и в логах, аналитике и вспомогательных сервисах. Разберем точки риска.
Почему риск начинается раньше вызова модели
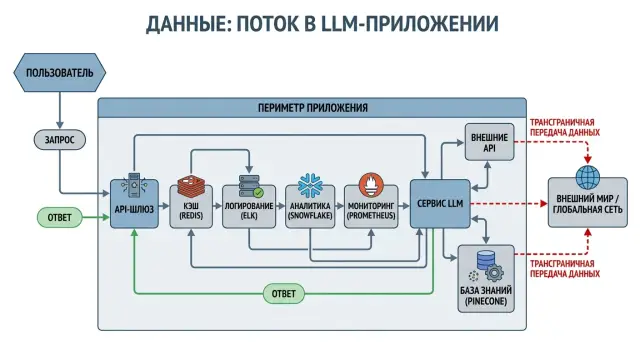
Команды часто рисуют путь данных слишком просто: приложение отправляет запрос в LLM, модель возвращает ответ. На такой схеме виден только основной вызов. В реальной системе между пользователем и моделью почти всегда есть еще несколько слоев.
Запрос проходит через шлюз или прокси, затем попадает в логи, мониторинг, трассировку, метрики и алерты. Если что-то ломается, тот же фрагмент текста может оказаться в дампе ошибки, тикете или сообщении дежурной команде. Поэтому риск появляется не в одной точке, а сразу в нескольких.
Каждый слой обычно сохраняет хотя бы часть запроса: prompt, system message, user ID, имя файла, кусок ответа, токены, IP-адрес, идентификатор сессии. Иногда и этого хватает, чтобы восстановить смысл переписки или собрать профиль пользователя.
Главная проблема в том, что эти копии живут отдельно друг от друга. Команда проверила провайдера модели, подписала договор и решила, что вопрос закрыт. Но APM хранит сырые тела запросов в другом регионе, аналитика уносит user properties за периметр, а инструмент поддержки сохраняет скриншот с ответом модели.
Такой сценарий встречается постоянно. Банк или ритейл-команда оставляет base_url на локальном LLM-шлюзе и считает, что данные остались внутри страны. При этом разработчики включают подробные логи, продуктовая команда смотрит события во внешней аналитике, а on-call получает алерт с фрагментом prompt в стороннем канале уведомлений. Основной вызов остался под контролем, но копии уже разошлись дальше.
Даже если сама модель или шлюз работают в Казахстане, этого мало. Нужно смотреть на весь маршрут данных: кто принимает запрос, кто пишет его в логи, кто считает метрики, кто отправляет ошибки и где все это хранится. Иначе аккуратный вызов модели не защитит от утечки через соседний сервис.
Какие данные уходят вместе с запросом
Когда приложение отправляет запрос в LLM, за периметр уходит не только вопрос пользователя. Обычно запрос собирается из нескольких слоев, и каждый из них может нести персональные данные, внутренние правила компании или технические метки.
Чаще всего наружу уходят текст промпта и история диалога, системные инструкции, поля из CRM или формы, файлы и служебные атрибуты вроде IP, user agent и trace id. На схеме это выглядит как один JSON. По смыслу это сразу несколько типов данных.
С текстом промпта все понятно, но история переписки часто опаснее одного сообщения. Пользователь мог раньше указать адрес, телефон, ИИН, детали платежа или номер заказа. Если приложение каждый раз пересылает весь контекст, оно снова и снова отправляет старые чувствительные фрагменты.
Системные инструкции тоже часто забывают проверить. Пользователь их не видит, но их видит провайдер модели и любой промежуточный шлюз. В таких инструкциях нередко лежат шаблоны ответов, правила эскалации, названия внутренних продуктов, сегменты клиентов и куски базы знаний. Это уже не персональные данные, но все равно данные компании.
Еще один частый источник риска - служебные поля. Например, чат-бот для банка берет вопрос клиента и незаметно добавляет номер договора, статус заявки и e-mail, чтобы модель ответила точнее. Для продукта это удобно. Для комплаенса это уже передача идентификаторов за пределы исходной системы.
С файлами риск выше. PDF, сканы удостоверений, снимки экрана, медицинские выписки и фотографии чеков содержат больше, чем кажется на первый взгляд. Даже если в модель уходит только распознанный текст, рядом часто остаются само вложение, превью картинки или результат OCR.
Технические поля тоже нельзя считать безобидными. IP, user agent, session id и trace id сами по себе могут не назвать человека по имени, но помогают связать запрос с конкретным устройством, сотрудником или клиентской сессией. Когда такие метки совпадают в логах и аналитике, полная цепочка собирается довольно быстро.
Поэтому проверять нужно не один prompt, а весь пакет запроса. Если команда использует шлюз вроде AI Router, стоит отдельно посмотреть, какие поля он проксирует дальше, что попадает в аудит-логи и где включено маскирование PII до отправки.
Как логи становятся отдельным каналом передачи
Команды часто смотрят только на вызов модели и пропускают более тихий маршрут - служебные журналы. Даже если модель или API-шлюз находятся внутри Казахстана, данные могут уйти за периметр через логирование, трассировку и архивы.
Самый частый сценарий простой. Разработчик включает режим отладки, и приложение пишет в лог сырой prompt, ответ модели, user_id, email или номер договора. Для разбора ошибок это удобно. Для безопасности это уже отдельная копия данных, которая живет по своим правилам.
Дальше проблема растет на уровне инфраструктуры. Шлюз сохраняет тело запроса при ошибке 4xx или 5xx, чтобы потом разобрать сбой. APM и distributed tracing автоматически забирают части payload, headers и метаданные сессии. Один запрос к LLM оставляет след не в одном месте, а сразу в нескольких.
Обычно цепочка выглядит так: приложение пишет полный prompt в логи, шлюз сохраняет request body при ошибке, APM копирует фрагменты payload, команда выгружает логи во внешнее хранилище или SIEM, а резервные копии держат эти записи месяцами. Каждая точка в этой цепочке создает еще один маршрут передачи.
На практике это выглядит буднично. Банк тестирует внутреннего помощника для операторов. Сама модель вызывается через локальный шлюз, но логи приложения уходят во внешний сервис мониторинга, где хранится текст обращений клиентов. Передача данных случилась не в инференсе, а в обслуживающем контуре.
С аудит-логами часто возникает путаница. Аудит нужен, но ему редко требуется сырой пользовательский текст. Во многих случаях хватает хеша, длины запроса, времени, статуса и идентификатора маршрута. Если платформа разделяет аудит и технические логи и умеет маскировать PII, риск заметно ниже.
Правило здесь простое: считайте лог такой же передачей данных, как и сам API-вызов. Если запись не нужна для расследования инцидента, не храните ее. Если нужна, режьте поля, маскируйте PII и ставьте короткий срок хранения.
Как аналитика выносит данные за периметр
Многие команды закрывают риск на уровне API и успокаиваются слишком рано. На деле данные часто уезжают через аналитику, которая стоит рядом с приложением и получает почти тот же текст, что и модель.
Типичный пример - продуктовые события со свойствами вроде prompt_text, response_text, user_email или account_name. Аналитикам так проще строить отчеты и смотреть, где пользователь бросил диалог. Но в этот момент передача данных уже состоялась, даже если сам вызов модели остался внутри страны.
BI-системы добавляют свой риск. Команда выгружает туда логи запросов, чтобы считать конверсию, среднюю длину диалога или долю ошибок. Если регион у хранилища настроен по умолчанию вне Казахстана, за границу уходит не агрегат, а полный набор строк с текстами, идентификаторами и служебными полями.
Инструменты записи сессий создают еще один тихий канал. Они могут сохранять ввод в форме еще до нажатия кнопки "Отправить". Если чат, поиск или форма обращения не маскируют поля, сервис видит все: вопрос клиента, номер договора, адрес, жалобу, внутренний код заказа.
Системы оценки качества тоже легко начинают хранить лишнее. Команда хочет сравнить ответы моделей и складывает примеры диалогов в отдельный сервис разметки или дашборд. Через месяц там уже лежат сотни реальных разговоров с персональными данными, хотя для метрик хватило бы обезличенного фрагмента.
Даже аккуратные команды на этом срезаются. Можно вести трафик через шлюз с хранением данных в Казахстане, маскированием PII и аудит-логами, а потом одним событием в облачную аналитику отправить исходный текст запроса. Периметр ломается не в модели, а в обвязке вокруг нее.
Если аналитике действительно нужен контент, ей редко нужен весь диалог. Короткий обезличенный фрагмент, хэш, тег сценария или счетчик ошибок почти всегда решают ту же задачу без вывоза сырых данных.
О каких сервисах забывают
Проверка обычно заканчивается на модели и основном шлюзе. Но данные уходят и в соседние сервисы, которые на архитектурной схеме выглядят второстепенными. Именно там часто прячется самый неприятный риск.
Модерация контента - частый пример. Приложение сначала отправляет пользовательский текст в отдельный сервис проверки, а уже потом в модель. Для пользователя это один запрос. Для данных это два канала передачи.
То же касается перевода и OCR. Когда человек загружает скан паспорта, счета или договора, OCR получает не короткий фрагмент, а весь документ. Если система потом еще и переводит текст перед анализом, документ проходит через еще один сервис.
Векторная база тоже не так нейтральна, как кажется. Во многих конфигурациях рядом с эмбеддингами лежат исходные фрагменты текста, метаданные, названия файлов, ID клиента и иногда сырые куски переписки для отладки поиска. Если база или ее резервные копии находятся вне страны, это уже отдельный маршрут данных.
Кеш часто забывают первым. Чтобы ускорить ответы и снизить расходы, команды сохраняют промпты и ответы на часы или дни. Это удобно, но кеш держит те же данные, что и модель: запросы пользователей, фрагменты документов, ответы с чувствительной информацией. Если кеш подключен как внешний managed-сервис, у него свои правила хранения, свои бэкапы и свои журналы.
Служба поддержки добавляет еще один канал. Пользователи присылают скриншоты ошибок, а на них видны чат, номер заявки, имя клиента и иногда часть документа. Затем эти изображения попадают в help desk, корпоративную почту, внутренний мессенджер или подрядчику на разбор инцидента.
Один и тот же проект может выглядеть безопасно на верхнем уровне и при этом передавать данные через OCR, кеш, help desk и сервис модерации. Формально основной API под контролем. Фактически реальные данные пересекают границу в нескольких местах.
Как это выглядит в обычном проекте
Банк запускает внутренний чат для сотрудников колл-центра и бэк-офиса. Сотрудник вставляет вопрос клиента, номер заявки и кусок внутреннего регламента, а модель помогает собрать черновик ответа за 20-30 секунд.
На схеме все спокойно: prompt идет через OpenAI-совместимый шлюз, команда включает аудит, rate limits и маскирование PII, а затем отправляет запрос в модель. Кажется, что маршрут данных понятен и контролируется.
Проблемы начинаются вокруг самого вызова. Разработчики подключают логирование запросов, чтобы разбирать ошибки. Рядом ставят APM, чтобы видеть задержку, размер ответа и процент сбоев. Если настройки оставили по умолчанию, в этих системах быстро оказываются не только технические метрики, но и фрагменты промпта, текст ответа, идентификатор сотрудника, номер обращения и части персональных данных.
Через неделю продуктовая команда просит отчет: о чем чаще всего спрашивают сотрудники, где чат ошибается, какие темы надо дообучить. Аналитики выгружают примеры вопросов в отдельный сервис, где строят дашборды и подборки реальных диалогов. Формально это уже не вызов модели, а аналитика. По сути это еще одна копия тех же данных.
Потом подключается служба поддержки. Сотрудник жалуется, что чат дал странный ответ по кредитной заявке. Он создает тикет и прикладывает скриншот окна чата. На скриншоте видны имя клиента, номер договора, сумма и ответ модели. Тикет живет в другой системе, у другого подрядчика и с другим сроком хранения.
В итоге данные пересекают границу не один раз, а несколько: при отправке запроса в модель, при записи сырых логов в сервис наблюдаемости, при выгрузке примеров в аналитику и при создании тикета со скриншотом или копией диалога.
Обычно это не выглядит как явное нарушение. Чаще все складывается из удобных мелочей: включили подробные логи, отправили события в привычный дашборд, попросили support сохранить кейс для разбора. Но для аудита разницы нет. Данные ушли, размножились и попали в несколько контуров, которые команда сначала даже не считала частью LLM-приложения.
Как проверить маршрут данных
Проверку лучше начинать не с модели, а с первой точки, где пользователь вводит текст. Если смотреть только на API-вызов, реальный маршрут почти всегда кажется короче, чем есть на самом деле.
Сначала нарисуйте полную цепочку на одной схеме: форма или чат, backend, шлюз, очередь, сервис вызова модели, логирование, аналитика, хранилище, резервная копия, архив. Если команда использует AI Router или другой совместимый шлюз, на схеме должен быть не только сам эндпоинт, но и все слои вокруг него, включая аудит-логи, маскирование PII и внешние инструменты наблюдаемости.
Дальше пройдитесь по каждому узлу и ответьте на несколько простых вопросов:
- Видит ли сервис сырой payload целиком или только метаданные.
- В какой стране и в каком регионе он хранит данные.
- Пишет ли он что-то в логи, алерты, дампы и резервные копии.
- Кто внутри команды и у подрядчиков может это читать.
- Можно ли отключить запись сырых запросов или сократить срок хранения.
После этого возьмите один реальный сценарий и пройдите его вручную. Например, сотрудник отправляет в чат номер договора и короткое описание проблемы. Этот текст может пройти через веб-сервер, попасть в трассировку, сохраниться в аналитике как "пример запроса", уйти в алерт при ошибке и остаться в архиве после ротации логов. Сам вызов модели в такой цепочке - только одна точка риска.
Последний шаг часто пропускают: проверьте доступы. Даже если данные лежат в Казахстане, риск остается, когда сырые логи без явной причины читают подрядчики, support или аналитики. Хорошая схема заканчивается не моделью, а списком мест, где данные больше не нужны и где их можно просто не хранить.
Ошибки, которые повторяются чаще всего
Самая частая ошибка - проверить только провайдера модели и успокоиться. Если у него понятные условия, кажется, что вопрос закрыт. Но передача данных часто происходит позже: в логах приложения, в системе ошибок, в продуктовой аналитике, в резервных копиях и в тестовых стендах.
Вторая типичная ошибка - оставить в продакшене подробное логирование. Разработчики включают его на время запуска и забывают выключить. В итоге в логи уходит полный prompt, ответ модели, user ID, номер телефона, адрес или номер заявки.
Третья ошибка связана с аналитикой. Команде удобно видеть, на каких запросах пользователи бросают диалог, где падает качество и какие сценарии дают длинный ответ. Ради этого в события отправляют текст сообщений целиком. Для продукта это удобно, для персональных данных - плохая практика.
Еще одна ловушка - считать бэкапы и тестовые среды чем-то второстепенным. На деле именно туда часто попадают самые полные копии данных. Тестовый контур наполняют выгрузкой из продакшена, чтобы быстрее проверить новый сценарий, а потом этот стенд живет месяцами без нормального контроля доступа.
Многие также путают обезличивание с простым хешем. Если вы хешируете e-mail или телефон без соли, это не делает данные безопасными автоматически. Даже с солью хеш не всегда решает задачу, если рядом остаются имя клиента, текст обращения и время события.
Тревожные признаки обычно видны быстро: в логах лежит полный текст запросов и ответов, аналитика хранит user properties с e-mail, телефоном или ИИН, тестовая база собрана из продакшен-данных, а резервные копии уезжают в облако без отдельной проверки маршрута. Такие ошибки редко связаны со злым умыслом. Обычно это спешка и привычка делать "как всегда".
Что делать после аудита
Аудит полезен только тогда, когда после него меняют схему работы. Если карта потоков показала, что данные уходят не только через API модели, сокращайте маршрут до минимума. Чем меньше систем видят полный текст запроса, тем ниже риск и тем проще контроль.
Первый шаг - убрать лишние копии текста. Часто полный prompt уходит сразу в несколько мест: в логи приложения, APM, аналитику, help desk и хранилище для отладки. Для большинства задач это не нужно. Одному сервису хватает статуса ответа, другому - длины запроса, третьему - обезличенного идентификатора сессии.
Второй шаг - маскировать персональные данные до записи в логи и до отправки во внешние инструменты. Если приложение сначала пишет сырой текст, а потом чистит копию, данные уже ушли в лишний канал. Маскирование должно стоять на входе.
Третий шаг - вынести самые чувствительные сценарии в локальный контур. Это особенно важно для банков, медицины, госсервисов и любых процессов, где в промптах быстро появляются персональные данные и служебные поля. Если поток нельзя обезличить без потери смысла, его лучше держать ближе к источнику данных и на инфраструктуре с хранением внутри Казахстана.
Дальше нужны простые и понятные правила:
- какие системы вообще могут получать полный текст;
- какие поля всегда маскируются;
- сколько дней хранятся логи, трассировки и дампы;
- кто может читать сырые данные;
- какие сервисы нельзя подключать без нового ревью.
Полезно разделить потоки по чувствительности. FAQ-бот для сайта и внутренний помощник оператора - это не один и тот же режим работы. Такое разделение снижает стоимость и убирает лишние ограничения там, где они не нужны.
Если команде нужен единый шлюз для работы с разными моделями, стоит смотреть не только на совместимость API, но и на то, где хранятся данные, как устроены аудит-логи и есть ли маскирование PII. Для части компаний это сразу упрощает контроль маршрута. В этом смысле AI Router может быть одним из практичных вариантов для локального контура в Казахстане, особенно если важны единый OpenAI-совместимый эндпоинт, хранение данных внутри страны и помесячный B2B-инвойсинг в тенге.
Хороший результат аудита выглядит просто: команда может быстро ответить, какие поля уходят наружу, кто их видит и как долго они хранятся. Если на эти три вопроса нет ясного ответа, риск остается, даже когда сам вызов модели кажется безопасным.
Часто задаваемые вопросы
Почему риск начинается еще до ответа модели?
Потому что текст почти никогда не идет прямо в модель и обратно. Его видят шлюз, логи, трассировка, алерты, аналитика и иногда help desk. Даже если сам инференс остается внутри страны, копии запроса могут уйти дальше через обслуживающие сервисы.
Какие данные обычно уходят вместе с запросом в LLM?
Чаще всего наружу уходят сам prompt, история чата, системные инструкции, ID пользователя, номер заявки, e-mail, IP, session id и trace id. Отдельно проверьте файлы и OCR: один PDF или скан обычно несет больше чувствительных данных, чем короткий текстовый запрос.
Опасно ли хранить полный prompt в логах?
Да, если вы пишете в лог сырые запросы и ответы. Лог становится еще одной копией данных со своим сроком хранения, доступами и резервными копиями. Для разбора сбоев обычно хватает статуса, времени, длины запроса и ID маршрута без полного текста.
Нужен ли аналитике весь текст диалога?
Почти никогда. Аналитике обычно хватает тега сценария, длины диалога, кода ошибки или короткого обезличенного фрагмента. Если отправлять полный текст сообщений в продуктовые события, вы сами создаете новый канал передачи данных.
О каких сервисах команды забывают чаще всего?
Чаще всего забывают про OCR, модерацию, перевод, векторные базы, кеш, APM, SIEM и тикетные системы. Пользователь видит один чат, а данные в это время проходят через несколько отдельных контуров с разными правилами хранения.
Достаточно ли локального шлюза, чтобы данные не уходили за границу?
Нет, этого мало. Локальный шлюз закрывает только часть маршрута. Если приложение шлет сырые события во внешнюю аналитику или хранит полные логи в другом регионе, данные все равно покидают нужный контур.
Как быстро проверить реальный маршрут данных?
Начните с одного реального сценария и пройдите его от формы ввода до архива логов. Посмотрите, кто видит payload целиком, что пишет в логи, где лежат бэкапы и у кого есть доступ. Такая проверка быстро показывает лишние копии текста.
Нужно ли хранить сырой текст в аудит-логах?
Нет, аудит-логу редко нужен сырой текст обращения. Ему обычно хватает времени, статуса, длины запроса, хеша и ID сервиса. Если платформа умеет отделять аудит от технических логов и маскировать PII на входе, риск заметно ниже.
Чем опасны тестовые стенды и резервные копии?
Потому что туда часто попадает самая полная копия продакшен-данных, а контроль там слабее. Команды берут выгрузку из боевой среды для удобства, потом стенд живет месяцами, а бэкапы уезжают в облако без отдельной проверки маршрута.
Что стоит исправить первым после аудита?
Сначала уберите лишние копии текста из логов, аналитики и тикетов. Затем включите маскирование PII до записи и сократите сроки хранения. Если сценарий нельзя обезличить без потери смысла, держите его в локальном контуре, где данные хранятся внутри Казахстана. Для такой схемы удобно использовать единый шлюз вроде AI Router, если вам нужны локальное хранение, аудит и совместимость с текущими SDK.