Фидбек пользователей для eval: как не копить скриншоты
Фидбек пользователей для eval помогает превратить кнопки «полезно» и «ошибка» в очередь задач: что собирать, как размечать и что проверять.
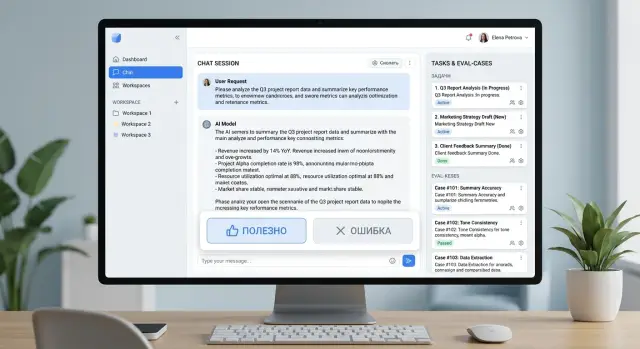
Почему одних кнопок мало
Кнопка "полезно" или "ошибка" дает сигнал, но не объясняет причину. Один пользователь жмет "ошибка", потому что ответ неверен по фактам. Другой - потому что бот написал слишком длинно. Третий просто не понял формулировку. Для команды это три разные проблемы, а в отчете они выглядят одинаково.
Если собирать обратную связь только в виде кликов, видно общее настроение, но не видно сам сбой. Исправлять в таком потоке почти нечего. Команда начинает спорить о догадках вместо того, чтобы разбирать конкретный случай.
Проблема становится заметнее, когда вместе с кликом не сохраняется контекст. Без промпта, версии системной инструкции, имени модели, параметров и точного текста ответа нельзя понять, что именно пошло не так. Даже небольшое изменение шаблона или правила выбора модели может дать другой результат. Через неделю никто уже не вспомнит, что именно видел пользователь.
Это особенно чувствуется там, где запросы идут через несколько моделей или провайдеров. Если команда меняет маршрут через шлюз вроде AI Router, один и тот же вопрос может обрабатываться по-разному в зависимости от правил, лимитов или выбранной модели. Клик без контекста в такой схеме почти ничего не дает.
Скриншоты тоже редко помогают. Они быстро разъезжаются по чатам, теряются в тредах и плохо ищутся. На скриншоте часто нет полного диалога, ID запроса и данных о том, какая модель ответила. Для спора в переписке этого еще хватает. Для очереди улучшений LLM - уже нет.
Есть и еще одна ловушка. Один и тот же сбой команда записывает под разными именами: "галлюцинация", "неверный факт", "бот придумал условие", "ответ не по базе". В итоге кажется, что случаев много и все они разные, хотя корень один. Статистика шумит, а приоритеты съезжают.
По каждому клику стоит хранить хотя бы пять вещей: текст запроса и 1-2 предыдущих сообщения, точный текст ответа, модель и версию промпта, время запроса, короткую причину из понятного списка и ID кейса, чтобы не плодить дубли. Тогда кнопка перестает быть жестом раздражения или одобрения. Она становится меткой на конкретном случае, который можно проверить, сгруппировать и потом добавить в набор кейсов для оценки.
Что записывать вместе с кликом
Один клик почти ничего не объясняет. Пользователь нажал "ошибка", но уже через день команда не помнит, что именно он видел на экране и почему ответ его не устроил. Поэтому сохраняйте не только оценку, а весь контекст, который позволит потом воспроизвести ситуацию.
Первое правило простое: пишите в лог полный запрос и полный ответ. Не только последнюю реплику, а весь диалог, который привел к клику. Ошибка часто рождается не в финальном сообщении, а на пару шагов раньше, когда модель неверно поняла цель, пропустила ограничение или увела разговор не туда.
Рядом с текстом нужен и технический след. Если один и тот же запрос в разное время уходит в разные модели, без этих данных вы не поймете, где сбой: в модели, у провайдера или в новой версии промпта. Если команда работает через AI Router, особенно полезно сохранять модель, провайдера и маршрут запроса рядом с самим кейсом.
Обычно хватает пяти групп данных: сам диалог, маршрут запроса, контекст продукта, причина клика и служебные поля. В диалоге нужен текст запроса, история реплик и ответ модели. В маршруте - модель, провайдер, версия промпта и, если нужно, температура с системной инструкцией. В продуктовой части - экран, сценарий и роль пользователя, например "оператор поддержки" или "клиент банка". Отдельно нужны время, язык, номер диалога и идентификатор сессии.
Короткий тег причины сильно экономит время. Лучше дать 6-8 понятных вариантов вроде "фактическая ошибка", "не ответил на вопрос", "слишком длинно", "плохой тон", "не тот язык". Пользователь выбирает один вариант за секунду, а команда потом быстро собирает выборки по типам проблем.
Небольшой пример. Клиент банка спрашивает в чате, как перевыпустить карту. Он жмет "ошибка" не потому, что ответ грубый, а потому что модель дала инструкцию для другого продукта. Если у вас есть только клик и скриншот, спор пойдет по кругу. Если сохранены текст диалога, язык, роль пользователя, модель, провайдер и версия промпта, задача уже ясна: проверить маршрут, обновить инструкцию и добавить этот случай в eval-набор.
Если в запросах есть персональные данные, храните для анализа маскированную копию. Иначе полезный лог быстро превращается в риск.
Как разложить плохие ответы по типам
Один клик на "ошибка" почти ничего не объясняет. Если складывать все неудачные ответы в одну папку, команда видит только шум и спорит о причинах. Такой фидбек не помогает улучшать модель.
Разделяйте сбои по смыслу, а не по эмоции пользователя. Один и тот же ответ может раздражать по разным причинам, но чинить их придется по-разному.
- Фактическая ошибка. Модель сообщает неверный факт, сумму, дату, правило или статус.
- Промах по задаче. Факты могут быть верными, но ответ не решает запрос. Пользователь просил сравнение, а получил пересказ.
- Сбой формата. Смысл нормальный, но ответ пришел не в том виде: слишком длинный, без нужной структуры, не на том языке, со сломанным JSON.
- Рискованный ответ. Модель дает опасный совет, раскрывает лишние данные, выдумывает политику компании или подталкивает к действию, которое нельзя делать.
- Тон и подача. Ответ грубый, сухой, обвиняющий или слишком самоуверенный, хотя по сути может быть почти правильным.
Эти типы часто путают. Вежливый, но неверный ответ - это фактическая ошибка, а не проблема тона. Неприятный по стилю, но безопасный ответ - это тон, а не риск. Если смешать такие случаи, команда будет править формулировки там, где нужно чинить логику или данные.
Жалобы на скорость держите отдельно. Долгий ответ, таймаут или задержка первого токена раздражают не меньше плохого текста, но это другой поток работы. Такие случаи обычно идут к тем, кто отвечает за инфраструктуру, лимиты и выбор модели, а не к тем, кто правит промпт или eval-набор.
Простой пример быстро ставит все на место. Пользователь просит: "Дай короткий ответ в 3 пунктах и только по условиям возврата". Если модель придумала срок возврата, это фактическая ошибка. Если она ушла в доставку и скидки, это промах по задаче. Если выдала полотно текста вместо 3 пунктов, это сбой формата. Если советует обойти проверку личности, это рискованный ответ. Если отвечает резко, это проблема тона.
Хорошее правило простое: одна жалоба - одна основная причина. Если причин две, ставьте главную и добавляйте вторую как дополнительную метку. Иначе очередь улучшений быстро превращается в склад спорных случаев, где каждый читает один и тот же скриншот по-своему.
Как пройти путь от клика до очереди задач
Чтобы обратная связь не превратилась в папку со скриншотами, каждый клик нужно сразу оформлять как отдельный случай. Пользователь нажал "ошибка" - система выдала click_id, привязала его к сессии, сообщению, версии промпта, маршруту модели и времени. После этого кейс можно найти, проверить и сравнить с похожими.
Следующий шаг лучше не откладывать. В момент клика система должна создавать карточку случая, а не ждать, пока кто-то вручную опишет проблему в командном чате. Иначе половина деталей потеряется в тот же день.
В карточке обычно хватает самого диалога вокруг спорного ответа, технического контекста, короткой метки типа сбоя и полей для статуса, владельца и решения. Так у команды появляется не "жалоба", а рабочий объект. Один случай уходит на правку промпта, другой - на смену модели, третий - на чистку базы знаний. Если запрос проходит через AI Router, полезно сразу видеть, через какого провайдера и какую модель он прошел.
Похожие жалобы стоит склеивать в один кластер. Не по словам пользователя, а по сути проблемы. Если люди разными фразами жалуются на то, что бот путает тарифы или выдумывает лимиты, это один и тот же класс ошибки. Без кластеров очередь быстро засоряется дублями, и частые сбои выглядят как набор случайных мелочей.
Приоритет лучше считать по двум осям: как часто это случается и чем это грозит. Редкий, но опасный ответ про платежи, персональные данные или юридические условия должен подниматься выше, чем два десятка жалоб на сухой тон. Простая шкала тут работает лучше сложной формулы: частота, риск для бизнеса, риск для клиента и стоимость исправления.
После этого кластер попадает в очередь улучшений уже как задача. У задачи должен быть владелец, срок и гипотеза исправления. Например: проверить retrieval, разделить правила выбора модели по типу запроса или добавить отказ на неизвестные лимиты. Если гипотезы нет, карточку лучше пометить как "нужно еще 10 примеров", чем отправлять ее в общий список без понятного следующего шага.
Так клик перестает быть реакцией на раздражение и становится единицей работы, которую можно измерить, исправить и проверить повторно.
Как собрать eval-набор из живого фидбека
Живой фидбек приносит пользу только тогда, когда по каждому случаю понятна причина сбоя. Если пользователь нажал "ошибка", но команда не может объяснить, что именно не так, такой пример лучше оставить в сыром архиве. В eval-набор стоит брать случаи, где есть ясный дефект: модель выдумала факт, не задала уточняющий вопрос, нарушила формат или пропустила ограничение.
Каждый кейс лучше хранить не как скриншот, а как короткую запись с полями. Тогда набор можно прогонять снова после смены модели, промпта или маршрута. Обычно хватает запроса пользователя, ответа модели, метки "полезно" или "ошибка", короткой причины и ожидаемого ответа или правила проверки.
Ожидаемый ответ не всегда должен быть длинным эталоном. Часто достаточно простого правила: "не придумывать тариф", "сначала запросить номер заказа", "ответить в 3 пунктах", "не раскрывать персональные данные". Такие правила проще поддерживать, чем идеальные образцы на все случаи.
Полезно держать рядом удачные и неудачные примеры по одной теме. Если в похожих запросах один ответ прошел, а другой нет, команда быстрее поймет, где проблема. Очень часто сбой сидит не в самой модели, а в маршруте запроса, системном промпте или в том, что в контекст попал лишний кусок данных.
Набор должен жить по простым правилам. После смены модели его нужно прогонять заново целиком. Это особенно важно, если команда тестирует несколько моделей через единый API-шлюз: небольшие отличия в стиле ответа легко превращаются в реальные ошибки в проверках.
Старые кейсы лучше убирать без долгих споров. Если продукт поменял политику, форма ответа стала другой или баг уже исчез, пример больше не отражает текущую систему. Архивируйте его и двигайтесь дальше. Иначе набор разрастается, а сигнал становится слабее.
Хороший eval-набор не обязан быть большим. Лучше 40 понятных кейсов с ясной причиной и проверкой, чем 400 скриншотов, по которым никто не может принять решение.
Пример: чат поддержки банка
Клиент пишет в чат мобильного банка: "Какой лимит перевода в приложении?" Он имеет в виду лимит в сутки. Модель отвечает уверенно, но путает периоды и выдает месячный лимит вместо дневного.
Клиент жмет "ошибка" и выбирает тег "факт". Если сбор настроен нормально, в запись попадает не только сам клик, но и вопрос, ответ модели, версия промпта, модель, источник ответа и время запроса. Один такой пакет уже можно разбирать, а не пересылать друг другу скриншот.
Дальше оператор или аналитик быстро видит, где сбой. Иногда модель сама домыслила ответ. Но в поддержке банка проблема чаще прячется в источнике: старая статья базы знаний, неясная формулировка или таблица, где дневной и месячный лимит стоят рядом и выглядят почти одинаково.
В этом случае команда находит ошибку в источнике и правит текст. Формулировку делают прямой: отдельно лимит в день, отдельно лимит в месяц. Если лимит зависит от типа клиента или статуса проверки, это тоже пишут явно, без сносок и двусмысленных строк.
Потом кейс не теряют. Его добавляют в eval-набор как отдельный тест: вопрос про лимит перевода в приложении, ожидаемый смысл ответа, допустимые формулировки и явный запрет путать сутки и месяц. После релиза этот тест идет в регрессионную проверку вместе с похожими вопросами про комиссии, сроки и ограничения.
Польза здесь очень практичная. Пользовательский клик указывает на реальную боль, тег "факт" сразу сужает поиск причины, исправление попадает и в источник, и в набор кейсов для оценки, а та же ошибка не возвращается незаметно через неделю.
Именно так живой фидбек перестает быть складом скриншотов. Он становится очередью задач с понятным владельцем, проверкой после правки и памятью команды о том, что уже ломалось раньше.
Где команды чаще всего ошибаются
Первая частая ошибка проста: после клика на "неполезно" команда просит написать длинный комментарий. Почти никто этого не делает. Человек хотел закрыть задачу за 20 секунд, а ему предлагают мини-опрос. В итоге у вас много минусов и почти нет объяснений. Обычно лучше работают короткие причины в один клик и поле для комментария по желанию.
Вторая ошибка делает сырой фидбек почти бесполезным. Все плохие ответы складывают в одну папку, чат или таблицу без тегов. Через неделю там уже нельзя быстро понять, где модель придумала факт, где не поняла вопрос, а где ответ был верным, но звучал грубо или слишком общо. Без простой разметки вы не строите очередь задач, а храните цифровой склад жалоб.
Еще один промах встречается почти у всех: команда бросается чинить редкий, но громкий случай раньше частых повторов. Один скриншот от руководителя легко выбивает весь спринт. При этом десятки похожих сбоев у обычных пользователей остаются в стороне, потому что никто не свел их в повторяющийся паттерн. Для приоритета полезнее смотреть не на самый яркий пример, а на частоту повторов, долю затронутых сессий и цену ошибки для бизнеса.
С этим связана и другая проблема: команды смотрят на общее число кликов, а не на повторы. Сто минусов не всегда означают сто разных проблем. Иногда это один и тот же запрос, который много раз прогнали в тестовой среде, или один раздраженный пользователь, который ставит минус каждому ответу. Повторы по одному типу сбоя дают больше пользы, чем голая сумма реакций.
Часто жалобу еще и не связывают с релизом модели, новым промптом или сменой маршрута. Тогда команда видит рост негатива, но не понимает, что именно его вызвало. Если вы работаете через AI Router и можете быстро менять маршрут между моделями и провайдерами, привязка к версии особенно важна: один и тот же сценарий может ломаться только на одной модели, а на остальных работать нормально.
Плохой процесс почти всегда выглядит одинаково: мало контекста, нет тегов, приоритеты строят по эмоциям, а не по повторам, и никто не видит связь между жалобой и изменением в системе.
Быстрый чек-лист перед запуском
Перед запуском хватит пяти проверок:
- У ошибок есть короткие теги, и их немного. Обычно достаточно 3-7 вариантов.
- Лог хранит не только клик, но и запрос, ответ, модель, версию промпта, время, язык, ID сессии и базовые метаданные.
- Похожие случаи склеиваются, а не превращаются в десятки одинаковых тикетов.
- Eval-набор обновляется по расписанию, а не от случая к случаю.
- За процесс отвечает конкретный человек, а не "все понемногу".
Этого уже достаточно, чтобы фидбек начал работать как нормальный вход в разработку. Команда видит не просто недовольство пользователей, а повторяемые сбои с понятным контекстом.
Есть простой тест. Возьмите любой вчерашний клик "ошибка" и попробуйте ответить на три вопроса: что именно пошло не так, насколько часто это повторяется и кто возьмет это в работу. Если хотя бы на один вопрос ответа нет, запуск еще сырой.
Что сделать дальше
Начните с одного сценария, а не со всего продукта сразу. Возьмите поток, где люди часто видят ответ модели и где ошибка заметна сразу. Например, ответы в чате поддержки по тарифам, доставке или статусу заявки. Включите кнопки "полезно" и "ошибка" на неделю и не пытайтесь в первый день собрать идеальную схему.
Такой короткий запуск быстро показывает, работает ли процесс в вашей команде. Если клики идут, но никто не может понять, что именно сломалось, проблема не в кнопках. Проблема в том, что рядом с кликом не хватает контекста и общих правил разбора.
Сразу договоритесь о простом наборе тегов причин. Их не должно быть много. Обычно хватает 5-7: фактическая ошибка, пропуск шага, плохой тон, устаревшие данные, лишний отказ. Рядом задайте правило приоритета. Повторяющийся сбой с высоким риском должен попадать в работу раньше, чем редкая странность, даже если она выглядит громко.
Дальше держите простой ритм: семь дней собираете клики по одному сценарию, раз в неделю переносите повторы в eval-набор, а в задачу кладете не скриншот, а полный кейс - запрос, ответ, причину и ожидаемый результат. Считать стоит не общий шум, а повторы одного и того же сбоя.
Если вы уже ведете запросы через AI Router, имеет смысл сразу хранить рядом с кейсом модель, провайдера и маршрут запроса. Это помогает быстрее понять, сломался промпт, конкретная модель или правило выбора маршрута. В командах, где есть требования к аудит-логам, маскированию персональных данных и хранению данных внутри страны, такой контекст особенно полезен: разбор идет быстрее и безопаснее.
Ориентир простой: не гонитесь за числом кликов. Семь одинаковых промахов по одному сценарию важнее, чем тридцать несвязанных жалоб. Из повторов рождается очередь улучшений. Из шума - папка со скриншотами, к которой никто не возвращается.
На следующей неделе оставьте тот же процесс, уберите один лишний тег и добавьте один новый тест в eval-набор. Если это получается регулярно, система уже работает.
Часто задаваемые вопросы
Почему одних кнопок «полезно» и «ошибка» недостаточно?
Потому что клик показывает реакцию, но не причину. Один человек ставит "ошибка" из-за неверного факта, другой — из-за слишком длинного ответа, третий — из-за плохой формулировки. Без контекста команда видит только шум и спорит о догадках.
Что стоит записывать вместе с кликом пользователя?
Сохраняйте сам запрос, 1–2 предыдущих сообщения, точный ответ модели, модель и версию промпта, время, язык, ID сессии и короткую причину жалобы. Этого уже хватает, чтобы воспроизвести случай и понять, что чинить.
Сколько тегов причин лучше дать пользователю?
Обычно хватает 5–7 тегов. Если вариантов слишком много, люди путаются и жмут наугад; если слишком мало, разные сбои слипаются в одну кучу.
Как быстро разложить плохие ответы по типам?
Делите их по смыслу: неверный факт, промах по задаче, сбой формата, рискованный ответ и проблема тона. Тогда команда не будет править стиль там, где сломались данные или логика.
Хватит ли скриншотов для разбора ошибок?
Нет, скриншоты почти всегда теряют детали. На них часто нет полного диалога, ID запроса, версии промпта и маршрута модели, а без этого сложно повторить и проверить ошибку.
Как понять, какую жалобу брать в работу первой?
Сначала смотрите на две вещи: как часто сбой повторяется и чем он грозит. Опасный ответ про платежи, персональные данные или правила сервиса стоит поднять выше, даже если таких случаев пока мало.
Как превращать живой фидбек в eval-набор?
Берите случаи с ясной причиной сбоя и понятной проверкой. Если модель придумала факт или нарушила формат, добавьте запрос, ответ, метку причины и короткое правило вроде «не путать дневной и месячный лимит».
Нужно ли смешивать жалобы на качество ответа и на скорость?
Лучше держать их отдельно. Медленный ответ, таймаут и задержка первого токена раздражают не меньше, но их чинят через лимиты, инфраструктуру и выбор модели, а не через промпт.
Что делать с персональными данными в логах?
Если в запросах есть персональные данные, храните для анализа маскированную копию. Так команда сможет разбирать кейсы без лишнего риска и без утечки чувствительной информации.
С чего начать, если процесса пока нет?
Начните с одного заметного сценария, например с чата поддержки, и неделю собирайте клики с полным контекстом. Потом сгруппируйте повторы, выберите частые сбои и добавьте хотя бы несколько случаев в eval-набор.