Мультиарендность в AI-платформе без лишних сервисов
Мультиарендность в AI-платформе помогает разделить ключи, лимиты, логи и расходы между командами без отдельного набора сервисов.
Почему общий доступ быстро ломает порядок
В начале общий доступ кажется удобным. Один API-ключ, один лимит, один поток логов. Пока запросов мало, это почти не мешает.
Проблемы начинаются, когда платформой пользуются несколько команд. Поддержка держит прод-нагрузку, аналитики крутят пилот, разработчики гоняют тесты. Все идет через один ключ, и источник ошибки пропадает.
Если растет число 429 или таймаутов, никто не понимает, кто создал всплеск. Приходится писать в чаты, сверять время вручную и спорить о том, чьи запросы забили очередь. Один общий ключ отлично скрывает автора проблемы.
С лимитами еще хуже. Одна команда может ночью прогнать новые промпты и потратить чужой дневной запас токенов еще до утра. Для прод-сервиса это выглядит как случайный сбой, хотя причина проста: тесты и боевая нагрузка живут без границ.
С финансами та же история. В счете есть общая сумма, но нет ответа на простой вопрос: кто потратил бюджет - продуктовая команда, внутренний пилот или отдел, который просто экспериментировал. Дальше начинается ручная сверка по таблицам, а она почти всегда дает погрешность.
Логи тоже быстро превращаются в шум. В одном месте лежат прод, тесты, демо для руководства и разовые эксперименты. Когда случается инцидент, инженеры тратят время не на поиск причины, а на отделение полезных событий от мусора.
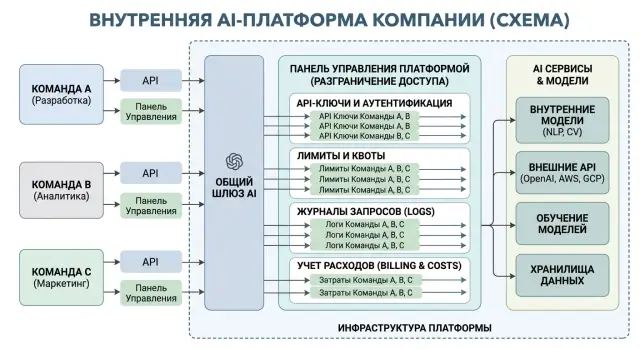
Это особенно заметно, если компания строит внутреннюю AI-платформу на одном шлюзе. Один OpenAI-совместимый endpoint и правда упрощает интеграцию. Но без границ между арендаторами эта простота ломает учет, контроль и разбор сбоев.
Поэтому мультиарендность нужна не ради красивой архитектуры. Она нужна, чтобы у каждой команды были свои ключи, свои лимиты, свои логи и понятный учет расходов.
Что стоит разделить с первого дня
Если у всех один API-ключ, порядок заканчивается в первый же споре о расходах. Начинать лучше не с витрины и не с дашбордов, а с базового разделения доступа и учета.
Ключи должны принадлежать не платформе вообще, а конкретной команде и конкретному сервису. Один ключ - для веб-приложения, другой - для фоновой обработки, третий - для тестов. Тогда сразу видно, кто создал нагрузку, кто уперся в лимит и какой сервис начал слать лишние запросы.
Даже если у вас один OpenAI-совместимый шлюз, внутри все равно нужна граница арендатора. Иначе любой удачный пилот быстро превращается в общий котел, где невозможно понять, кто сколько тратит и кто отвечает за всплеск трафика.
На старте обычно хватает простого набора. Дайте каждой команде и каждому сервису отдельные ключи. Поставьте лимиты не только на число запросов, но и на токены и деньги. В логах храните tenant_id, project_id и окружение, например prod или test. Собирайте ежедневный и месячный отчет по расходам. Из ролей оставьте минимум: владелец команды и админ платформы.
Лимиты лучше ставить сразу на трех уровнях. Лимит по числу запросов ловит шумные интеграции. Лимит по токенам защищает от слишком длинных промптов и ответов. Денежный лимит держит бюджет под контролем, потому что даже небольшой рост трафика на дорогой модели быстро превращается в заметную сумму.
С логами не нужно усложнять. Если в записи нет tenant_id, project_id и окружения, любая проверка превращается в ручной разбор. Команда должна видеть свои вызовы, админ - общую картину, а аудит - полную историю без поиска по разным местам.
С ролями тоже лучше без лишней схемы. Владелец команды выпускает ключи для своей команды, смотрит расходы и меняет лимиты в рамках бюджета. Админ платформы управляет общими правилами, моделями, маршрутами и доступом между арендаторами.
Такой каркас выглядит скучно, но экономит недели. Когда через месяц появится вопрос "почему счет вырос на 38%", ответ уже будет в системе, а не в таблице, которую кто-то заполнял ночью.
Как выбрать границы арендатора
Плохая граница арендатора ломает учет почти сразу. Ключи начинают гулять между людьми, тестовые запросы попадают в прод, а счет за модели приходит один на всех.
Обычно верхним уровнем лучше делать команду. Это проще, чем строить арендатора вокруг отдельного человека или всей компании сразу. Команда и так отвечает за бюджет, доступы, сроки и поддержку своего AI-сценария. Если маркетинг, антифрод и контакт-центр работают через одну платформу, у каждой команды должны быть свои лимиты, журналы и набор ключей.
Внутри команды добавьте проект. Он отделяет один продукт от другого без лишней бюрократии. У одной команды может быть чат для операторов, RAG-поиск по документам и внутренний помощник для аналитиков. Если держать все это в одном проекте, картина по расходам и ошибкам быстро размажется.
Рабочая схема обычно выглядит так: команда - верхний уровень учета и доступа, проект - уровень продукта или сценария, среда - разделение на prod, test и sandbox, сервисный аккаунт - отдельная сущность для каждого бота, пайплайна или интеграции. Общие правила оставляйте только там, где речь о безопасности.
Сервисные аккаунты почти всегда обязательны. Бот, ETL-пайплайн, cron-задача или внутренний агент не должны ходить в LLM API по личному ключу разработчика. Иначе увольнение одного человека или обычная ротация доступа ломает половину процессов, а аудит превращается в ручной разбор.
Prod, test и sandbox тоже стоит разделять явно. Даже если модель одна и та же, режимы работы разные. В prod нужны строгие лимиты, полный аудит и стабильные настройки. В test можно держать более мягкие ограничения. В sandbox люди пробуют новые промпты и маршруты без риска для боевой среды.
Общие правила стоит оставлять только для безопасности и соответствия требованиям. Например, маскирование PII, аудит-логи, метки AI-контента и базовые rate limits можно задавать на уровне всей платформы. Остальное лучше отдавать командам. Такой подход особенно удобен, когда у вас один общий шлюз, а границы доступа, логов и расходов нужно держать отдельно.
Как внедрить схему по шагам
Мультиарендность проще внедрить в одном шлюзе, чем поддерживать набор отдельных прокси, логгеров и скриптов. Если у вас уже есть один OpenAI-совместимый вход для всех LLM-запросов, дальше все упирается в дисциплину: кто вызывает модель, под каким ключом, с каким лимитом и как это потом проверить.
Начните не с кода, а с таблицы. В ней обычно хватает пяти полей: команда, проект, владелец, сервис и бюджет. Владелец нужен не для формальности. Когда расходы резко растут или сервис уходит в цикл ретраев, вы сразу понимаете, кому писать.
После этого выдайте отдельный API-ключ на каждый сервис, а не на отдел целиком и не на человека. Чат поддержки, внутренний copilot и batch-обработка документов должны ходить под разными ключами, даже если ими владеет одна команда. Так вы быстрее находите источник всплеска по токенам и не отключаете все сразу из-за одного сбоя.
Дальше задайте два типа лимитов: на день и на месяц. Дневной лимит ловит поломки и бесконечные повторы запросов. Месячный держит бюджет в рамках плана. На старте лучше поставить лимиты чуть ниже ожидаемого объема и неделю посмотреть, где оценка была слишком оптимистичной.
Чтобы потом не разбирать логи вручную, добавляйте в каждый запрос теги команды и проекта. Подойдет простая схема вроде team=search и project=faq-bot. Если шлюз умеет rate limits и аудит по ключу, этого уже достаточно для нормального разделения без набора дополнительных сервисов.
В первую неделю сверяйте расходы и логи каждый день. Смотрите не только на общую сумму, но и на детали: какой сервис дал больше всего токенов, где выросло число ошибок и повторов, какие запросы ушли без тега проекта, не делят ли два сервиса один и тот же ключ, совпадает ли владелец сервиса с тем, кто получает отчет.
Обычно схема ломается не из-за архитектуры, а из-за мелочей. Один общий ключ для двух интеграций, пропущенный тег или слишком высокий лимит быстро портят учет. Если поймать это в первую неделю, дальше все работает заметно спокойнее.
Пример для трех команд
В банке одна внутренняя AI-платформа часто кормит сразу несколько задач. Допустим, на ней работают чат-бот для клиентов, антифрод и контакт-центр. Если все три команды ходят в модели через общий ключ и общий бюджет, порядок заканчивается быстро: никто не понимает, кто выбрал лимит, чьи запросы тормозят и откуда вырос счет.
Нормальная мультиарендность выглядит проще, чем многие ожидают. Команды пользуются одним шлюзом и одним набором SDK, но платформа видит их как разных арендаторов. У каждого арендатора свои ключи, лимиты, правила маршрутизации и журнал запросов.
Для такого банка настройка может быть простой. Чат-бот получает отдельный ключ, дневной лимит и предсказуемый набор моделей. Его задача - отвечать стабильно весь день. Антифрод работает через свой контур с жестким порогом по задержке. Если ответ модели выходит за предел, платформа режет запрос или отправляет его только в быстрые модели. Контакт-центр живет в отдельном тестовом арендаторе и может пробовать новые модели и промпты без риска для боевой нагрузки чат-бота и антифрода.
Разделение логов здесь не менее важно, чем разделение доступа. Чат-боту обычно хватает журналов по ошибкам, токенам и времени ответа. Антифроду почти всегда нужен более подробный след: какой маршрут выбрала платформа, сколько длился каждый шаг, какой лимит сработал. Контакт-центр чаще смотрит на качество ответов по новым сценариям, а не только на задержку.
Финансам не нужен сложный разбор в конце месяца. Если каждый запрос несет tenant_id, cost center и имя команды, расход собирается сам. Отчет выглядит понятно: столько ушло на клиентский чат, столько - на антифрод, столько - на эксперименты контакт-центра. Если команда контакт-центра за неделю прогонит дорогую модель на тысяче диалогов, это не потеряется в общем счете банка.
Практический эффект очень земной. Чат-бот не падает из-за чужих тестов. Антифрод не ждет в общей очереди. Финансы видят расход по подразделениям в тот же день, а не после ручной сверки по логам и счетам.
Как считать расходы без ручной сверки
Ручная сверка почти всегда ломается в двух местах: один и тот же запрос проходит через ретрай, а часть трафика уходит во внешние модели, пока другая часть идет на свои GPU. Если в журнале нет общей схемы учета, финансы видят одну цифру, команда - другую.
База для расчета простая. Каждый вызов должен получать tenant_id, project_id, model_id, provider_id, тип размещения, число входных и выходных токенов, статус запроса и стоимость. Тогда расходы можно собирать по факту: отдельно по команде, отдельно по проекту и без ручного разбора логов.
Что считать отдельными строками
Успешный ответ, ошибка и ретрай не должны жить в одной куче. Иначе одна неудачная серия запросов раздует отчет.
Рабочее правило обычно такое: успешный запрос попадает в usage и в cost, ошибка без ответа модели - только в technical log, ретрай получает свой request_id и ссылку на исходный вызов, а списание считается только по тому событию, где провайдер действительно взял оплату.
Это особенно важно, если команда гоняет трафик через единый шлюз. Например, внешний вызов к Anthropic и запрос к собственной хостируемой модели должны считаться по одной схеме, но с разным источником стоимости. Для внешних моделей цена приходит из биллинга провайдера. Для своих моделей ее считают по внутренней ставке: GPU, хранение, сеть и поддержка.
Как показывать отчет
Дневной отчет нужен для поиска всплесков. Недельный помогает увидеть, какая команда начала тратить больше после релиза. Месячный нужен для бюджета и счета.
Обычно хватает трех срезов: по команде, по проекту и по модели. Если расходы выросли, отчет должен сразу отвечать на два вопроса: кто потратил и на что именно.
Последний шаг - сверка с фактическим биллингом. Раз в день или раз в месяц сравнивайте внутренний отчет с инвойсом провайдера и со своими затратами на хостинг. Если расхождение выше согласованного порога, ищите причину сразу: дубли, неверные цены, пропущенные ретраи или токены кеша, которые система посчитала не так, как провайдер.
Какие логи действительно нужны
При мультиарендности журнал нужен не для архива, а для обычной работы команды. Если в записи нет tenant_id и project_id, через несколько дней уже трудно понять, кто сжег токены, какой сервис дал всплеск задержки и где искать ошибку.
Хороший журнал отвечает на три простых вопроса: что отправили, кто отправил и сколько это стоило по времени и токенам. Для этого в каждую запись стоит класть request_id, model, tenant_id и project_id. Этого уже хватает, чтобы связать один вызов модели с конкретной командой, продуктом и инцидентом.
Что должно быть в каждой записи
Минимальный набор полей небольшой: request_id для поиска одного запроса по всей цепочке, tenant_id и project_id для разделения команд и продуктов, model для понимания, какая модель дала ответ, время ответа и число токенов для контроля задержки и расходов, а также идентификатор ключа, автора ключа и того, кто его использовал.
Последний пункт часто пропускают. Один разработчик создал ключ для интеграции, другой положил его в сервис, третий запустил тесты ночью. Если журнал хранит только сам ключ или его хеш, видно слишком мало. Если он хранит автора ключа и фактического пользователя, картина сразу яснее.
Отдельно следите за тем, что попадает в запись. Сырой текст запроса, почта, телефон, ИИН или номер карты не должны уходить в журнал как есть. Сначала маскируйте PII, потом сохраняйте очищенную запись. Для компаний в Казахстане это обычная рабочая практика, особенно если аудит логов потом смотрят безопасники или юристы.
Еще одна частая проблема возникает, когда prod и test лежат в одном потоке. Тестовые прогоны шумят, ломают картину по задержке и мешают считать расходы по живым сервисам. Разделяйте эти журналы сразу, хотя бы по разным индексам или по явному полю environment.
Если у вас один OpenAI-совместимый шлюз, такого набора логов обычно хватает почти для всех спорных случаев без отдельного зоопарка сервисов. Инженер находит request_id, видит модель, арендатора, проект, токены, задержку и автора ключа. Этого достаточно, чтобы быстро понять, что случилось и кому писать.
Где чаще всего ошибаются
Первая ошибка почти всегда одна и та же: компания выдает один API-ключ всем командам. Сначала это кажется удобным. Потом никто не понимает, кто сжег бюджет за ночь, чей промпт уронил лимит и где искать запрос с персональными данными.
Один общий ключ ломает сразу три вещи: учет, доступ и разбор инцидентов. Если команда поддержки тестирует новый сценарий, а продуктовая команда в это время гоняет batch-задачи, в логах все смешивается. Через неделю спор уже идет не про архитектуру, а про то, кто виноват в счете.
Вторая частая ошибка - один общий лимит на всю компанию без квот по командам. Тогда самая активная команда съедает весь дневной или месячный запас, а остальные получают 429 в самый неудобный момент. Для внутренней AI-платформы это особенно неприятно: бот для сотрудников может остановиться из-за экспериментов в другом отделе.
Не меньше проблем дает отсутствие простых меток. Если запросы не помечены по окружению и проекту, dev и prod быстро превращаются в одну кучу. Потом тестовый трафик попадает в боевые отчеты, а расходы по пилоту выглядят как расходы продакшена. Базового набора обычно достаточно: tenant, team, project, environment, cost_center.
Еще одна типичная ошибка - считать только успешные ответы модели. Картина получается аккуратной, но ложной. В расходах и нагрузке нужно видеть все: ошибки, таймауты, отмененные запросы, срабатывания rate limit, отказы из-за политики безопасности. Иначе команда видит одну цифру в дашборде, а в инвойсе получает другую.
Бывает и более тихая проблема: тестовым ключам дают слишком широкие права. Разработчик берет ключ для стенда, а этим же ключом можно вызвать дорогую модель, читать общие логи или обходить лимиты проекта. Так появляются случайные траты и лишний доступ.
Если свести все к минимуму, правила простые: отдельный ключ для каждой команды и сервиса, квоты по командам, обязательные метки project и environment, учет всех запросов, а не только успешных, и урезанные права для тестовых ключей.
Короткая проверка перед запуском
Перед запуском полезно пройтись по нескольким простым пунктам. Если хотя бы один не сходится, через несколько дней начнутся споры о том, кто выбрал лимит, чей сервис слал запросы ночью и почему расходы не бьются с отчетом.
У каждой команды должен быть владелец. Не группа в чате, а конкретный человек, который подтверждает доступы, лимиты и новые сервисы. У каждого сервиса нужен свой API-ключ. Если mobile backend, batch-job и внутренний бот ходят под одним ключом, вы теряете контроль в тот же день.
Каждый ключ должен упираться в свой лимит, отдельно для prod, staging и dev. Иначе тестовый стенд легко съест бюджет продакшена. В логах должны быть как минимум три метки: команда, проект и окружение. Без этого вы увидите только поток запросов, но не поймете, кому он принадлежит.
Отчет по расходам должен сходиться с внешним биллингом. Если вы используете общий шлюз, внутренняя разбивка по командам должна совпадать с ежемесячным инвойсом и цифрами по провайдерам.
Есть и простой тест. Попросите три команды отправить по одному запросу из dev и prod, а затем проверьте: создались ли отдельные записи в логах, списались ли расходы на нужный проект и сработал ли лимит там, где вы его ожидали.
Если хотя бы один пункт не проходит, не открывайте общий доступ. День задержки перед запуском почти всегда дешевле, чем неделя ручной сверки логов, лимитов и счетов.
Что делать дальше
Не раскатывайте схему на всю компанию за один раз. Лучше взять две-три команды с разными сценариями, например внутренний поиск, поддержку и аналитику. Так вы быстрее увидите, где ломается учет, и не утонете в согласованиях.
Первый порядок нужен не в отчетах, а в доступе. Если у нескольких команд один и тот же токен и одинаковые теги, вы не поймете, кто тратит бюджет, кто уперся в лимит и где искать проблему в логах. Начните с отдельных API-ключей, одного понятного идентификатора арендатора и обязательных тегов для каждого запроса.
Дальше двигайтесь по простой очередности. Сначала раздайте каждой команде свой ключ и зафиксируйте, кто за него отвечает. Потом добавьте теги, без которых запрос не проходит: tenant_id, проект, среда, владелец бюджета. После этого включите лимиты по командам, чтобы одна ошибка не съедала общий бюджет. Затем соберите отчеты по расходам хотя бы по дням и моделям. В конце проверьте, что логи позволяют найти конкретный запрос без ручной сверки в пяти системах.
Если этого нет, красивые дашборды не помогут. Сначала разделение API-ключей, потом лимиты по командам, потом учет расходов.
Отдельно оставьте запас на рост. Новые команды обычно появляются раньше, чем вы ждете. Новые модели тоже. Поэтому не привязывайте арендатора к одному провайдеру, одной модели или одному способу биллинга. Арендатор должен пережить текущий стек.
Если нужен один OpenAI-совместимый шлюз, где уже есть аудит-логи, rate limits на уровне ключа, хранение данных внутри Казахстана и ежемесячный B2B-инвойсинг в тенге, в эту схему естественно вписывается AI Router. Это не отменяет разделение арендаторов, но убирает часть обвязки, которую иначе пришлось бы собирать самим.
Нормальный результат через несколько недель выглядит просто: в любой день вы можете сказать, какая команда сколько потратила, какие у нее лимиты и по какому запросу случился сбой.
Часто задаваемые вопросы
Когда уже нельзя жить с одним общим API-ключом?
Общий ключ терпит только короткий пилот с одной командой и без прод-нагрузки. Как только появляется вторая команда, отдельный бюджет или ночные тесты, сразу вводите арендаторов и разные ключи по сервисам.
Что нужно разделить в первый день?
На старте разделите команды, проекты и среды. Для каждого сервиса выпустите свой ключ, назначьте владельца и задайте лимиты на запросы, токены и деньги.
Как выбрать границу арендатора?
Обычно верхний уровень — команда, ниже — проект, потом среда prod, test или sandbox, а затем сервисный аккаунт. Такая схема не грузит людей лишней бюрократией и дает ясный учет по продуктам и сервисам.
Нужен ли отдельный ключ на каждого разработчика?
Нет, для сервисов берите сервисные ключи, а не личные. Личный ключ удобно выдать для отладки на короткий срок, но прод и фоновые задачи должны ходить под отдельными аккаунтами.
Какие лимиты ставить в начале?
Сразу ставьте два горизонта: дневной и месячный. Дневной лимит быстро ловит цикл ретраев и шумные тесты, а месячный держит бюджет в рамках плана.
Что писать в логах каждого запроса?
Минимум такой: tenant_id, project_id, environment, request_id, модель, число токенов, время ответа и идентификатор ключа. С этим набором вы быстро находите виновника всплеска, считаете расход и отделяете test от prod.
Как учитывать ошибки и ретраи, чтобы не раздуть расходы?
Не смешивайте их в одну строку учета. Успешный вызов отправляйте в usage и cost, ошибку без ответа модели храните в техлоге, а ретрай связывайте с исходным request_id и списывайте только там, где провайдер взял оплату.
Зачем отдельно делить prod, test и sandbox?
Разводите среды явно, даже если модель одна и та же. В prod держите строгие лимиты и полный аудит, в test давайте мягче режим, а sandbox оставьте для новых промптов и маршрутов без риска для боевой нагрузки.
Как проверить схему перед запуском?
Начните с простой сверки. Отправьте по одному запросу из двух-трех команд в dev и prod, затем проверьте логи, расход, теги и срабатывание лимитов по каждому сервису.
Реально ли сделать мультиарендность на одном OpenAI-совместимом шлюзе?
Да, если шлюз умеет работать с разными ключами, лимитами, аудитом и тегами на уровне запроса. Один вход упрощает интеграцию, но порядок все равно держат арендаторы, сервисные аккаунты и нормальный учет.