Холодный старт self-hosted модели: как убрать задержки
Холодный старт self-hosted модели дает лишние секунды на первом запросе дня. Разберем прогрев, пул копий и расписание без лишних затрат.
Почему первый запрос тормозит
Холодный старт self-hosted модели - это пауза перед первым ответом, когда модель еще не готова к работе. В этот момент система запускает процесс, загружает веса в память, занимает место на GPU и проверяет, что все поднялось без ошибок. Пока эти шаги не завершены, пользователь просто ждет.
Обычно такая задержка появляется утром, после ночного простоя или после долгого перерыва днем. Причина простая: держать тяжелую модель "горячей" круглые сутки дорого, поэтому неиспользуемые копии часто останавливают. Для команд, которые хостят open-weight модели на своей GPU-инфраструктуре ради хранения данных внутри страны, это обычный обмен между скоростью и расходами.
Сильнее всего пауза бьет по чатам. Человек пишет в 9:01, видит пустой экран 15-30 секунд и решает, что сервис сломан. В RAG-сценариях это выглядит еще хуже: поиск по базе проходит быстро, а ответ модели задерживается так, будто проблема именно в самой логике ответа. Во внутренних ботах для поддержки, HR или продаж такой старт портит впечатление с первой реплики.
Есть и второй эффект: люди редко ждут спокойно. Они нажимают кнопку еще раз, обновляют страницу или отправляют тот же вопрос повторно. Сервер получает лишние запросы, а команда потом ищет "нестабильность", хотя причина была в одном холодном запуске.
Иногда с этим ничего делать не нужно. Если сервис используют редко, первый запрос запускает фоновую задачу, а пользователи знают, что ответ придет не сразу, постоянный прогрев только зря расходует ресурсы. Но если человек оценивает сервис по первой секунде ответа, холодный старт уже нельзя считать мелочью. Одна утренняя пауза часто подрывает доверие сильнее, чем редкая ошибка в середине дня.
Из чего складывается пауза
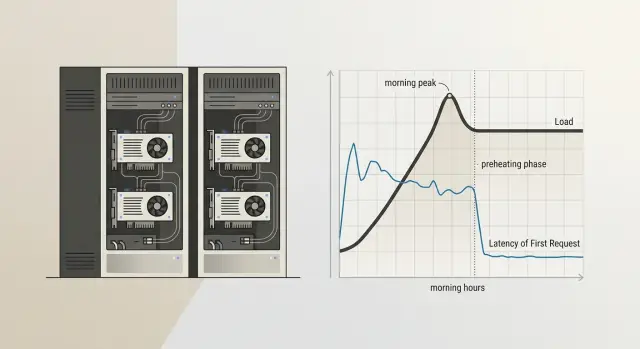
Задержка перед первым ответом почти никогда не возникает в одном месте. Обычно она собирается из нескольких этапов, и каждый добавляет свои секунды.
Сначала платформа поднимает сам процесс. Если модель работает в контейнере, система запускает контейнер, подключает окружение, проверяет зависимости и открывает доступ к устройствам. Уже здесь можно потерять заметное время, особенно если инстанс до этого спал или узел был занят другой задачей.
Потом сервер загружает веса модели в память. Для небольшой модели это терпимо. Для крупной - уже нет. Диски читают файлы, процесс раскладывает тензоры и переносит их туда, где модель будет работать. Если команда держит, например, Qwen 3 или Llama 4 на своей GPU-машине, именно загрузка весов часто съедает самую длинную часть ожидания.
Дальше GPU готовит память под запуск. Система выделяет буферы, резервирует VRAM, настраивает контекст и проверяет, хватает ли места под текущую модель и размер батча. Если на карте до этого работала другая задача, очистка и новая аллокация тоже занимают время. Бывает, что модель уже загружена, но первый запрос все равно ждет именно из-за этого шага.
И только потом начинается первый реальный прогон. Он почти всегда медленнее обычного. Фреймворк компилирует части графа, создает служебные кэши, прогревает kernels и заполняет структуры, которые ускорят следующие вызовы. Поэтому второй и третий запросы идут заметно ровнее.
Из-за этого задержка и кажется странной: снаружи это один долгий ответ, а внутри прошло несколько разных операций. Поэтому холодный старт нельзя лечить одной настройкой. Если процесс стартует быстро, а веса грузятся долго, спорить о кэшах бессмысленно. Если веса уже в памяти, но GPU каждый раз заново выделяет VRAM, искать проблему нужно в другом месте.
Как понять, что виноват именно cold start
Если утром первый запрос занимает 8-12 секунд, а следующие ответы приходят почти сразу, это очень похоже на холодный старт. Но похожую задержку дают и другие причины: очередь, сеть, авторизация, медленный диск, перенос весов на GPU.
Смотрите не на один неудачный вызов, а на повторяющийся рисунок. Если после простоя первый ответ стабильно хуже обычного потока, а потом задержка быстро падает, причина почти наверняка в запуске модели или прогреве окружения.
Что измерить
Разбейте общую задержку на этапы. Особенно полезно вынести отдельно время до первого токена. Если после простоя растет именно оно, значит, процесс, контейнер или сама модель не были готовы к работе.
Проверьте четыре вещи:
- сравните первый запрос после простоя и 5-10 обычных запросов подряд
- измерьте время до первого токена отдельно от полного времени ответа
- исключите очередь, сеть и авторизацию по отдельности
- записывайте, сколько сервис простаивал перед каждым тестом
Последний пункт часто пропускают. Без длительности простоя картина смазывается: пауза после 3 минут и после 2 часов дает разный эффект. Лучше сразу договориться о простом правиле и тестировать, например, после 15, 30 и 60 минут без трафика.
Хороший способ проверки - отправить один и тот же короткий промпт в одинаковых условиях. Сначала после часа тишины, потом еще раз через 10 секунд, потом серией из нескольких запросов. Если первый вызов медленный, второй резко быстрее, а очереди нет и сеть стабильна, источник найден.
Иногда виноват не запуск модели, а внешний слой. Авторизация может тормозить на первом запросе из-за обновления сессии. Сетевой прокси может держать "сонное" соединение. Очередь задач может копить фоновые джобы. Поэтому полезно смотреть тайминги по этапам, а не только на итоговую цифру.
В продакшене это обычно видно в логах. У первого запроса после простоя растет время инициализации воркера, загрузки весов или прогрева CUDA. У обычного потока эти этапы почти исчезают. Если след именно такой, лечить нужно запуск модели, а не промпт и не сеть.
Как настроить прогрев по шагам
Прогрев нужен не для галочки. Его задача проста: сделать так, чтобы первый живой запрос утром или после рестарта не ждал загрузку весов, инициализацию памяти и запуск нужных процессов.
Самая частая ошибка - греть модель запросом, который не похож на реальную работу. Фоновые вызовы идут, а первая задержка почти не меняется.
- Выберите короткий и дешевый запрос. Он должен проходить тот же путь, что и обычный: та же модель, те же параметры, тот же формат ответа. На практике часто хватает короткого промпта на 10-20 токенов с ответом вроде "ок".
- Запускайте прогрев сразу после деплоя и любого рестарта. Не ждите первого пользователя. Если контейнер пересобрался, нода перезапустилась или инстанс поднялся заново, отправьте прогревочный запрос автоматически.
- Добавьте расписание под рабочий ритм команды. Если сервисом пользуются с 9:00, начните прогрев за 10-15 минут до этого времени. Так вы тратите меньше ресурсов, чем при постоянном фоне, и убираете паузу именно тогда, когда она раздражает сильнее всего.
- Смотрите не на сам факт ответа, а на первую задержку. Если запрос вернулся, это еще не значит, что схема сработала. Сравните время первого реального ответа до прогрева и после него.
- Отключайте прогрев там, где он не дает разницы. Некоторые модели и так остаются в памяти, а некоторые сервисы получают запросы круглые сутки. В таком случае фоновые вызовы только тратят деньги и занимают очередь.
Хороший пример - внутренний чат поддержки, которым сотрудники пользуются с 9:00 до 18:00. После ночного простоя модель часто засыпает. Простое расписание на 8:45 и прогрев после каждого рестарта обычно решают проблему без постоянного пула готовых копий.
Когда нужен пул готовых копий
Пул готовых копий нужен тогда, когда прогрев одной реплики уже не спасает. Если утром в сервис прилетает не один запрос, а сразу пачка, первая горячая копия берет только одного пользователя, а остальные ждут запуск следующей. Так и появляется холодный старт, который вроде бы уже настроили, но он все равно бьет по первым минутам работы.
Одной горячей копии обычно хватает для редких запросов и внутренних инструментов на небольшую команду. Но если у вас есть утренний пик, смены операторов, массовый вход сотрудников в систему или запуск фоновых задач по расписанию, одной реплики мало. Тогда лучше держать минимум одну копию постоянно готовой, а вторую поднимать только в часы, когда всплеск повторяется почти каждый день.
Простой ориентир: если очередь появляется уже на первых 2-3 одновременных запросах после паузы, пора собирать пул. Это особенно заметно у тяжелых open-weight моделей, которые долго занимают GPU-память и плохо переносят резкие всплески.
Обычно о необходимости пула говорят такие признаки:
- первый пользователь отвечает быстро, а второй и третий резко медленнее
- задержка растет только в начале рабочего дня
- GPU простаивает полдня, но утром не успевает принять всплеск
- после перезапуска или ночного простоя сервис долго приходит в норму
Не держите одинаковый минимум реплик весь день. Это дорогая привычка. Гораздо разумнее менять число готовых копий по часам: одна ночью, две утром, снова одна днем, если трафик падает. Такой график обычно дает почти тот же отклик, что и постоянный запас, но без лишних затрат на GPU.
Еще одна частая ошибка - сажать тяжелые и легкие модели на один и тот же GPU без запаса по памяти. Большая модель может занять почти всю VRAM, и тогда легкая реплика либо не стартует вовремя, либо начнет вытеснять соседей. Проще разнести их по разным GPU или хотя бы не смешивать в одном пуле модели с очень разным размером.
Если команда работает на своей GPU-инфраструктуре и держит несколько open-weight моделей, смотреть нужно не только на задержку, но и на память. Пул ломается не тогда, когда кончаются идеи, а когда реплика не помещается в VRAM в нужный момент.
Как собрать расписание без гадания
Расписание прогрева лучше строить по логам, а не по ощущениям команды. Интуиция здесь часто подводит: всем кажется, что наплыв начинается в 9:00, а по факту первый плотный поток идет в 8:37 и длится всего 18 минут.
Возьмите логи хотя бы за 2-4 недели. Если трафик зависит от отчетных дат, зарплатных дней или рассылок, смотрите более длинный период. Нужны не только средние значения, но и форма нагрузки по часам: когда модель простаивает, когда просыпается и когда запросы растут резко.
Полезно отметить несколько точек:
- первый запрос после долгого простоя
- часы, где пауза между запросами самая длинная
- короткие пики, где очередь растет за 5-15 минут
- разницу между буднями и выходными
- дни после релизов или рассылок
Дальше стройте прогрев не на момент пика, а чуть раньше. Если трафик обычно растет к 9:00, грейте модель в 8:45 или 8:50. Если сделать это в 9:00, пользователи уже поймают первую задержку. Если греть слишком рано, вы просто потратите GPU-время без пользы.
Один общий график на всю неделю редко работает хорошо. У многих сервисов в будни есть утренний старт, а в выходные трафик позже и слабее. Поэтому лучше держать два расписания: отдельно для рабочих дней и отдельно для субботы с воскресеньем. Иногда нужен и третий вариант, если понедельник заметно отличается от остальных дней.
Простой пример: внутренний помощник для поддержки почти молчит ночью, оживает в 8:40, потом получает второй всплеск после обеда. Значит, разумно поставить короткий прогрев перед началом смены и еще один перед дневным пиком, а не держать копию горячей весь день.
И последнее: расписание нельзя считать готовым навсегда. После релиза, смены промпта, подключения нового канала или роста числа пользователей трафик меняется быстро. Раз в пару недель сверяйте план с логами. Если первая задержка снова поползла вверх, график уже устарел.
Простой пример на одном сервисе
У службы поддержки утро часто ломает всю картину. Ночью модель почти не используют, а в 9:00 операторы и клиенты приходят сразу. Если команда запускает LLM на своих GPU, первый ответ легко уходит в 15-20 секунд, хотя дальше все работает заметно быстрее.
Команда не стала держать лишние копии весь день. Для их графика это просто дорого. Вместо этого они посмотрели историю запросов и увидели понятный ритм: резкий всплеск утром, потом спокойнее после обеда.
Схема получилась простой:
- в 8:45 система отправляет короткий служебный запрос и прогревает одну копию
- с 9:00 до 11:00 сервис держит вторую горячую копию, чтобы очередь не росла
- после обеда сервис возвращается к одной копии, когда поток падает
Сам запрос для прогрева очень короткий. Что-то вроде: "Ответь одним словом: ок". Этого хватает, чтобы загрузить веса, занять память GPU и проверить, что модель отвечает без ошибки. Длинный тестовый диалог тут не нужен.
Через неделю команда сравнила цифры. До настройки первый утренний ответ иногда уходил за 18 секунд. После прогрева и второй горячей копии в пик большинство первых ответов укладывалось в 2-4 секунды. Пользователи почти перестали жаловаться на паузу, а операторы не ждали, пока ассистент "проснется".
Расход GPU, конечно, вырос. Но не так сильно, как боялись. Дополнительная копия работала только два часа утром, а не весь день. Поэтому команда смотрела не на абстрактную экономию, а на два понятных числа: сколько часов GPU добавило расписание и сколько секунд оно сняло с первой задержки.
Где команды ошибаются чаще всего
Самая частая ошибка проста: команда включает прогрев тогда, когда пользователи уже начали отправлять запросы. Если люди приходят в 9:00, а джоба стартует в 9:00, первая волна все равно ловит паузу. Лучше смотреть на реальные часы трафика и запускать прогрев заранее, часто за 10-20 минут до пика.
Вторая ошибка стоит денег. Команда прогревает все модели одинаково, как будто у них один размер, один стек и одна скорость загрузки. Но маленькая модель и тяжелая self-hosted модель ведут себя по-разному: одной хватает короткого запроса, другой нужно загрузить веса, адаптеры, шаблон промпта и часть кэша.
Еще один частый промах - слишком тяжелый тестовый промпт. Команда хочет "наверняка прогреть" модель и отправляет длинный запрос на тысячи токенов. В итоге она сама создает лишнюю нагрузку, забивает очередь и портит картину в метриках. Для прогрева обычно хватает короткого и стабильного запроса, который поднимает процесс, загружает токенизатор и проверяет базовый путь ответа.
Проблемы часто возвращаются после рестартов. Нода перезагрузилась, драйвер обновился, оркестратор пересобрал поды, контейнер переехал на другой GPU - и утренний прогрев уже не помогает. Если команда смотрит только на старт дня, она пропускает задержки, которые появляются в середине смены.
Обычно стоит проверить вот что:
- когда именно стартует прогрев относительно живого трафика
- какие модели действительно получают отдельный сценарий прогрева
- насколько тяжелый тестовый запрос
- что происходит после рестарта ноды или контейнера
- какие хвосты видно в p95 и p99
Среднее время ответа почти всегда успокаивает зря. Если девять запросов отвечают за 2 секунды, а десятый за 25, среднее выглядит терпимо, а пользователь все равно злится. Смотрите отдельно на первую задержку, хвосты и поведение после перезапуска.
Это особенно заметно в командах с несколькими маршрутами моделей. Даже если внешний доступ идет через единый шлюз, ошибки в прогреве self-hosted копий никуда не исчезают. Их видно только там, где команда измеряет не "среднее по больнице", а первый ответ в реальном сценарии.
Быстрая проверка перед запуском
Часто команда смотрит на задержку сразу после ручного теста и думает, что все в порядке. Потом проходит час простоя, приходит первый живой запрос, и ответ уезжает в 8-20 секунд. Такой сбой легко пропустить, если проверять только "теплое" состояние.
Перед запуском полезно провести короткий тест, который показывает реальную первую задержку, а не красивую цифру со стенда.
Что проверить за 15 минут
- остановите трафик на тестовую копию и измерьте первый запрос после 30, 60 и 120 минут простоя
- повторите тот же тест после деплоя и после аварийного рестарта, когда контейнер или процесс поднимается с нуля
- возьмите промпт обычного размера, а не короткую строку на 20 слов
- проверьте маршрут запроса: балансировщик или оркестратор должен отправить первый запрос на уже прогретую копию, а не на свежий инстанс
- сравните цену горячих копий с нужной задержкой
Простой пример: сервис поддержки держит модель без нагрузки ночью. Утром оператор открывает чат, отправляет длинный запрос с историей переписки и получает ответ через 14 секунд. Команда включает прогрев каждые 45 минут, оставляет одну готовую копию с 8:00 до 11:00 и получает первые ответы за 2-3 секунды. Разницу видно сразу, и ее легко объяснить бизнесу в деньгах.
Отдельно проверьте, что метрики не смешивают первый запрос с остальными. Если средняя задержка красивая, а первый запрос после простоя все еще долгий, пользователю от этой средней пользы мало.
Если после такой проверки первая задержка все еще выше цели, не спешите увеличивать железо. Сначала убедитесь, что расписание прогрева совпадает с реальным трафиком и что пул готовых копий включается в нужные часы, а не просто работает формально.
С чего начать дальше
Не пытайтесь чинить весь парк моделей сразу. Возьмите одну модель, у которой утром чаще всего проседает первый ответ. Обычно этого хватает, чтобы быстро понять, где вы теряете время и деньги.
Хороший первый кандидат - модель с явным пиком в начале рабочего дня. Если сотрудники начинают слать запросы с 9:00 до 10:00, а первый ответ в это окно идет заметно дольше обычного, у вас уже есть понятная точка для проверки.
Начните с простого плана:
- добавьте легкий прогрев за 10-15 минут до ожидаемого пика
- держите минимум одну горячую копию для этой модели
- измеряйте первую задержку отдельно от средней по дню
- посмотрите, сколько GPU-времени съедает такой режим
Не усложняйте схему в первый же день. Один прогрев по расписанию и одна готовая копия уже дают достаточно данных. Если эффект слабый, тогда есть смысл менять частоту прогрева, размер пула или окно активности.
Через неделю сравните две вещи: как изменилась задержка на самом первом запросе утром и насколько вырос расход GPU. Если первая задержка упала, например, с 18 секунд до 3-4, а расход вырос умеренно, настройка себя оправдала. Если GPU уходит слишком много, сдвиньте расписание ближе к реальному пику или сократите время, когда горячая копия простаивает.
Если команде нужен единый OpenAI-совместимый endpoint для работы с разными моделями, при этом важны хостинг open-weight моделей в Казахстане, аудит-логи и хранение данных внутри страны, можно посмотреть в сторону AI Router. У сервиса airouter.kz один совместимый API-шлюз для 500+ моделей от 68+ провайдеров и собственный хостинг 20+ open-weight моделей, поэтому такой вариант может упростить схему без смены SDK и промптов.
Дальше все довольно приземленно: выберите одну проблемную модель, прогрейте ее перед утренним пиком и через неделю смотрите на цифры. Именно так обычно и убирают самую заметную паузу без лишних трат.
Часто задаваемые вопросы
Что такое холодный старт модели?
Холодный старт — это пауза перед первым ответом, пока сервис поднимает процесс, загружает веса модели в память и готовит GPU. Из-за этого первый запрос после простоя часто идет заметно дольше остальных.
Когда холодный старт можно не трогать?
Если сервисом пользуются редко, а люди готовы подождать, постоянный прогрев обычно не нужен. В таком случае лучше принять паузу на первом запросе, чем зря держать GPU занятым весь день.
Как понять, что тормозит именно холодный старт?
Смотрите на повторяющийся рисунок, а не на один медленный запрос. Если после 30–60 минут тишины первый ответ стабильно долгий, а следующий почти сразу нормальный, проблема почти наверняка в запуске модели или прогреве окружения.
Что измерять в первую очередь?
Сначала измерьте время до первого токена и сравните его для первого и второго запроса. Потом отдельно проверьте сеть, авторизацию и очередь, чтобы не искать причину не там, где она возникла.
Каким должен быть запрос для прогрева?
Берите короткий и дешевый промпт, который проходит тот же путь, что и обычный запрос. Часто хватает фразы вроде Ответь одним словом: ок, если она запускает ту же модель, те же параметры и тот же формат ответа.
Когда одного прогрева уже недостаточно?
Его мало, когда утром приходит не один человек, а сразу несколько. Если первая готовая копия отвечает быстро только одному пользователю, а второй и третий ждут запуск новой реплики, пора держать небольшой пул.
Сколько горячих копий держать утром?
Начните с одной готовой копии и проверьте, появляется ли очередь на первых одновременных запросах. Если она растет уже на 2–3 запросах после простоя, добавьте вторую копию только на часы утреннего пика, а не на весь день.
Как настроить расписание прогрева без гадания?
Опирайтесь на логи за несколько недель, а не на ощущения команды. Прогрев лучше ставить за 10–15 минут до реального всплеска, иначе пользователи все равно поймают первую паузу.
Почему нельзя смотреть только на среднюю задержку?
Среднее скрывает неприятные хвосты. Девять быстрых ответов легко маскируют один долгий старт, хотя именно его пользователь запомнит как сбой сервиса.
Что делать, если после рестарта задержка вернулась?
Проверьте, что сервис отправляет прогрев сразу после рестарта, а балансировщик ведет первый живой запрос на уже готовую копию. Если пауза осталась, смотрите логи запуска контейнера, загрузки весов и выделения VRAM — обычно проблема сидит в одном из этих этапов.