Тестирование tool calling: что ломается вне happy path
Тестирование tool calling не сводится к happy path. В статье разберём пустые аргументы, лишние поля, неверные типы, таймауты и ретраи.
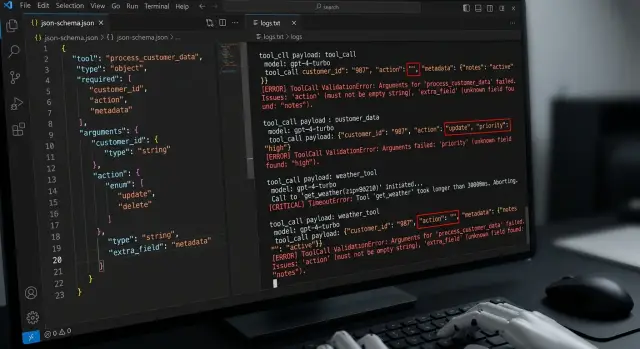
Почему happy path не спасает
Один удачный вызов почти ничего не доказывает. Он показывает лишь то, что модель, схема и инструмент совпали на удобном примере. В продакшене так бывает редко.
Tool calling часто ломается из-за простой ошибки: если демо прошло, значит дальше все будет работать так же. Но модель не выполняет код по жесткому сценарию. Каждый вызов она собирает заново. На редкой формулировке она легко теряет поле, путает тип или добавляет лишний аргумент.
Дальше мелкая ошибка тянет за собой следующую. Инструмент получает плохой JSON, возвращает сбой, а следующий ход диалога уже строится на испорченном состоянии. Пользователь видит догадку, лишний вопрос или странную паузу, хотя первая проблема была небольшой.
На демо обычно берут короткий запрос, чистые данные и быстрый инструмент. В реальной работе пользователь пишет с опечаткой, просит сразу две вещи, меняет формулировку по ходу, а внешний сервис отвечает медленно. Тот же сценарий ведет себя совсем иначе.
Это хорошо видно в командах, которые используют один OpenAI-совместимый API и просто меняют модель или провайдера. Формат вызова один и тот же, но поведение разное: одна модель аккуратно держит схему, другая иногда пропускает обязательное поле. Если не проверить это заранее, система ломается на мелочах вроде пустой строки в обязательном аргументе.
Happy path нужен. Но это только старт. Если вы не проверяете редкие входы, ошибки инструмента и поведение после сбоя, вы тестируете демо, а не рабочую систему.
Пустые аргументы и пропавшие поля
Чаще всего все ломается на пустых аргументах. Модель может вернуть null, пустую строку "" или пустой объект {}, и внешне это будет выглядеть как нормальный вызов.
Проверяйте эти случаи по отдельности. Для схемы и для кода это разные сигналы. {"order_id": null} может не пройти валидацию, {"order_id": ""} может пройти и сломать поиск, а {} показывает, как система ведет себя без обязательного поля вообще.
Для инструмента find_order полезен простой тест: сначала передайте пустое значение в order_id, потом уберите это поле совсем. В первом случае модель как будто понимает, что аргумент нужен, но не может его заполнить. Во втором она пропускает сам факт, что без order_id инструмент вызывать нельзя.
Сравнивайте поведение двух слоев отдельно. Валидатор должен ясно сказать, что не так во входных данных. Сам инструмент должен вести себя предсказуемо, даже если валидатор по ошибке что-то пропустил. Иначе в тестах команда видит одну ошибку, а в продакшене получает совсем другую.
Лучше сразу зафиксировать несколько простых правил. Если не хватает поля для безопасного поиска, система просит уточнение. Если действие что-то отправляет, списывает или меняет, вызов нужно останавливать сразу. Если значение пустое, ошибка должна быть явной, без догадок и значений по умолчанию. Если схема отклонила запрос, инструмент не должен запускаться вообще.
Это один из самых полезных наборов проверок. Он быстро показывает, где у вас настоящая защита, а где только ее видимость. Если пустой аргумент проходит слишком далеко по цепочке, потом баг приходится искать уже не в модели, а в бизнес-логике и логах.
Лишние поля и сломанная схема
Лишние поля ломают tool calling тише, чем неверные типы. Запрос выглядит почти нормальным, инструмент иногда даже отвечает, но смысл уже съехал. Модель добавила debug, comment или user_context, а код это либо проглотил, либо передал дальше без проверки.
Поэтому важно проверять не только сам факт валидного JSON, но и строгую форму аргументов. Если схема разрешает все подряд, ошибка остается незаметной до тех пор, пока инструмент не начнет вести себя странно. Например, функция оформления заявки ждет amount и currency, а модель присылает еще discount_override. Если парсер молча пропускает поле, вы теряете контроль над тем, что именно модель пытается сделать.
Полезный тест здесь очень простой: возьмите корректный набор аргументов, добавьте одно-два мусорных поля и проверьте, что валидатор явно отклоняет payload, а не пытается его "починить". В логах стоит сохранять исходный payload целиком, до нормализации и обрезки. И отдельно отмечать, где именно произошел сбой: модель собрала неверные аргументы или парсер не удержал схему.
Логи здесь важнее, чем кажется. Если в журнале остается только очищенная версия аргументов, команда не увидит настоящую причину сбоя. Потом все выглядит так, будто инструмент просто вернул ошибку, хотя на деле модель добавила поле, которого вообще не должно было быть.
Есть два разных класса проблем. Первый - модель сгенерировала лишнее поле. Второй - слой валидации молча его принял. Чинятся они по-разному. В первом случае вы правите описание инструмента, примеры и системные инструкции. Во втором ужесточаете схему, запрещаете дополнительные свойства и не даете парсеру догадываться за модель.
Если после теста вы не можете ответить, что именно прислала модель и на каком шаге схема это остановила, проверка еще не готова.
Неверные типы и тихие преобразования
Самые неприятные ошибки появляются не там, где схема сразу отклоняет запрос, а там, где она "помогает" слишком рано. Модель прислала "limit": "10" вместо числа, код молча превратил строку в 10, и тест прошел. Потом другая модель вернула "0010", а следующий сервис прочитал это уже не как количество, а как код.
Такие случаи нужно ловить отдельно. Передавайте число строкой и строку числом, даже если библиотека умеет делать автокаст. Иначе вы проверяете не контракт инструмента, а снисходительность конкретного парсера.
Хорошо работают несколько простых плохих примеров:
"amount": "5000", если схема ждет integer"currency": 398, если поле должно быть строкой"mode": true, если поле принимает только"strict"или"soft"- массив вместо объекта, например
[{"id":1}]вместо{"id":1}
Отдельно проверьте bool вместо enum и массив вместо объекта. Эти ошибки часто проходят разные слои по-разному: один слой ругается, другой молча приводит тип, третий падает уже внутри бизнес-логики. Команда видит только общее tool failed и тратит время на разбор.
Не полагайтесь на автокаст, если вы явно не записали правило. Если поле можно приводить из строки в число, опишите это в одном месте и добавьте тест. Если нельзя, отклоняйте запрос сразу. Смешанный подход быстро ломает систему, особенно когда один и тот же вызов идет через разные модели или через шлюз к разным провайдерам. Одна модель вернет 42, другая "42", третья null.
Важно тестировать и текст ошибки. Для кода нужен точный ответ вроде field amount: expected integer, got string. Для модели нужен короткий и понятный ответ, чтобы она могла повторить вызов с верным типом. Если эти сообщения плавают от инструмента к инструменту, повторные попытки становятся случайными, а отладка занимает лишний час.
Долгие инструменты и ожидание ответа
Инструмент может зависать дольше, чем сама модель. Чаще тормозит не LLM, а внешний сервис: поиск в CRM, запрос в биллинг, проверка документа, расчет цены. Если это не проверить заранее, диалог будто замирает, и пользователь решает, что система сломалась.
Один и тот же вызов стоит прогнать хотя бы в трех режимах:
- 100 мс
- 5 с
- 30 с
На 100 мс почти все выглядит нормально. На 5 секундах уже видно, есть ли в интерфейсе живой статус, можно ли отменить запрос и не исчезает ли история диалога. На 30 секундах всплывают ошибки, которые легко пропустить в обычной проверке: таймаут, потерянный ответ, повторный запуск и пустой экран без объяснений.
Что должен видеть пользователь
Если инструмент ждет дольше пары секунд, интерфейс должен говорить об этом простыми словами. Подойдут короткие статусы вроде Проверяю данные или Жду ответ от сервиса. Не оставляйте диалог в подвешенном состоянии без статуса, иначе человек начнет отправлять тот же запрос снова.
Представьте чат, который проверяет наличие товара на складе. На 5 секунде пользователь еще готов подождать. На 30 секунде ему уже нужен выбор: ждать дальше, отменить запрос или получить понятное сообщение о том, что сервис не ответил вовремя.
Здесь важно проверить не только предел по времени, но и поведение вокруг него:
- что происходит при таймауте: ясная ошибка или тишина
- можно ли отменить вызов вручную
- делает ли система повторную попытку автоматически и сколько раз
- приходит ли поздний ответ в уже закрытый диалог
Автоповтор часто портит опыт сильнее, чем один честный таймаут. Если система молча запускает вторую попытку, пользователь не понимает, что происходит, а команда потом ищет причину странных дублей в логах. Лучше один явный статус и одно понятное правило ожидания, чем бесконечная загрузка.
Повторный вызов и идемпотентность
Модель может вызвать один и тот же инструмент дважды. Это бывает после таймаута, неясного ответа инструмента или простого сбоя в цепочке сообщений. Если в тестах есть только удачный проход, такой дефект легко уходит в продакшен.
Сценарий с дублем лучше проверять отдельно. Дайте модели шанс повторить вызов с теми же аргументами сразу, через несколько секунд и после частичного ответа. Потом смотрите, как система отличает нормальную попытку повтора от настоящего дубликата.
Чтение и запись стоит разделять с самого начала. Повторно запросить баланс, статус заявки или список документов обычно безопасно. Повторно создать заказ, отправить письмо или списать оплату уже опасно: пользователь получит два письма, две заявки или двойной платеж.
Обычно дубликат определяют не по тексту промпта, а по id операции. Этот id создает клиент или сервер и передает вместе с вызовом инструмента. Если система видит тот же id второй раз, она не запускает действие заново, а возвращает прошлый результат или текущий статус.
Но и этого мало. Проверьте спорный случай, когда id операции совпал, а аргументы уже другие. Такой запрос нельзя молча принимать. Система должна отклонить его, залогировать конфликт и не выполнять запись повторно.
Минимальный набор проверок выглядит так:
- один и тот же вызов приходит два раза подряд
- второй вызов приходит после таймаута
- первый вызов выполнился, но ответ до модели не дошел
- тот же id операции пришел с измененными аргументами
На практике это особенно важно для заказов, писем и платежей. Один сохраненный id операции часто спасает больше денег и нервов, чем длинный набор сложных тестов.
Как собрать тесты по шагам
Почти все провалы начинаются с простого: команда не фиксирует, что именно должен принимать и возвращать каждый инструмент. Сведите это в одну таблицу или файл. Для каждого инструмента запишите обязательные аргументы, типы, допустимые значения и побочный эффект. Если вызов создает заказ, заявку или запись в базе, отметьте это отдельно.
Дальше удобно идти по одному шаблону:
- Для каждого поля задайте нормальный ввод, пустой ввод и неверный ввод.
- Добавьте случай с лишним полем, даже если JSON schema уже включена.
- Проверьте таймауты инструментов: быстрый ответ, долгий ответ, обрыв по времени.
- Сделайте дубль одного и того же вызова и посмотрите, не создает ли система второй объект.
- Для каждого теста запишите точный ожидаемый итог.
Последний пункт часто делают плохо. Фраза должно обработаться с ошибкой почти бесполезна. Лучше записывать конкретно: инструмент не вызывается, модель просит уточнение, система отдает ошибку валидации, повторный запрос не создает дубль, пользователю показывается понятное сообщение.
Потом прогоните один и тот же набор на нескольких моделях. Это быстро показывает разницу в поведении. Одна модель вернет пустую строку, другая превратит число в строку, третья добавит лишний аргумент. Если у вас один OpenAI-совместимый endpoint, такой прогон легко автоматизировать без переписывания клиента.
Небольшой пример. Есть инструмент create_ticket с полями title и priority. Минимальный набор тестов для него такой: оба поля переданы, title пустой, priority отсутствует, priority пришел числом, модель добавила поле department, инструмент ответил слишком поздно, один и тот же вызов ушел два раза. После такого набора сразу видно, где хватает обычной проверки входа, а где уже нужна идемпотентность.
Простой сценарий из практики
Ассистент бронирует встречу через calendar.create. Пользователь пишет: Запиши клиента Айгуль на встречу. Модель видит имя, но точную дату не получает. Вместо уточняющего вопроса она все равно вызывает инструмент и передает только client_name.
Дальше ломается уже не один шаг, а сразу несколько. Сервис календаря отвечает медленно, например через 8-10 секунд. Пока ответ не пришел, модель решает, что вызов потерялся, и отправляет второй запрос. Если система не проверяет дубли, команда получает две попытки бронирования вместо одной.
Такой тест полезнее, чем кажется. Он проверяет не только JSON schema, но и поведение цепочки целиком: модель, инструмент, ретраи и логику после ошибки.
В хорошем сценарии система делает четыре вещи. Она отклоняет вызов без даты, без мягкого угадывания. Не создает встречу по неполному набору полей. Распознает повторный вызов как дубль по request_id или другому стабильному идентификатору. И просит пользователя уточнить дату, а не молча пробует еще раз.
Если хотя бы один из этих пунктов не работает, ошибка быстро уходит в продакшен. Пользователь видит странный диалог, оператор потом ищет дубль в календаре, а команда тратит время на разбор логов.
Для tool calling это очень показательный кейс. Он выглядит простым, но ловит сразу несколько типичных сбоев: пропавший обязательный аргумент, таймауты инструмента и отсутствие идемпотентности.
Хороший ожидаемый результат звучит скучно, и это нормально. Ассистент должен ответить примерно так: Уточните дату встречи для Айгуль. Один понятный вопрос лучше, чем две случайно созданные записи в календаре.
Что команды часто упускают
Чаще всего команды проверяют только один приятный случай: модель вернула валидный JSON, инструмент принял аргументы, ответ пришел быстро. Для демо этого хватает. Для продакшена - почти никогда.
Из-за этого тесты выглядят "зелеными", пока не приходит первый странный ответ. Модель может прислать пустой объект, добавить поле, которого нет в схеме, или передать строку вместо числа. Если тесты смотрят только на факт успешного вызова, такие сбои проходят мимо.
Еще одна частая ошибка - сохранять уже нормализованный ответ и не хранить сырой вывод модели. Тогда команда видит только то, что осталось после парсера, ретрая или кастомного маппинга. Разобрать причину потом трудно: модель ошиблась, код молча почистил данные или шлюз переписал формат.
Это особенно заметно в системах, где запросы идут через несколько моделей и провайдеров. Если у вас один OpenAI-совместимый endpoint, как в AI Router, лучше хранить отдельно сырой ответ, audit log и итог после нормализации. Иначе два разных сбоя будут выглядеть одинаково.
Часто смешивают и два класса ошибок. Ошибка схемы означает, что инструмент вообще нельзя запускать: аргументы неполные, тип неверный, обязательное поле пропало. Ошибка бизнес-логики другая: схема валидна, но сам запрос плохой, например сумма перевода больше лимита или товар уже закончился.
Еще один пробел - команды не проверяют, что система делает после неудачного вызова. Она просит модель повторить запрос? Возвращает человеку понятную ошибку? Повторяет тот же вызов второй раз? Именно здесь появляются лишние списания, дубликаты заявок и запутанные логи.
Минимум, который стоит проверить:
- отдельно логировать сырой ответ модели и результат нормализации
- различать ошибку схемы и ошибку бизнес-логики
- тестировать поведение после сбоя, а не только сам сбой
- проверять, не делает ли система повторный вызов без контроля
Быстрая проверка перед релизом
Перед релизом полезно прогнать короткий набор тестов, который ловит дорогие сбои до продакшена. Если инструмент один раз получил пустой аргумент и цепочка пошла дальше, пользователь увидит не ошибку схемы, а сломанное действие: повторный платеж, пустой поиск или зависший ответ.
Проблемы почти всегда скучные. Модель присылает null, пустую строку, лишнее поле или строку там, где JSON schema ждет число. На демо такие случаи часто не видны. В рабочем потоке они всплывают сразу.
- Для каждого обязательного аргумента дайте минимум три плохих значения:
null,""и неверный тип. Еслиamountдолжно быть числом, передайте строку. Еслиcityдолжно быть строкой, передайте массив. - Проверьте лишние поля отдельно. Система должна остановить запрос с понятной ошибкой или удалить такие поля до вызова инструмента по заранее описанному правилу.
- Задайте лимит ожидания для медленных инструментов. Когда время вышло, пользователь должен получить ясный текст: что не сработало и что можно сделать дальше.
- Для опасных операций добавьте защиту от дубля. Повторный вызов списания, отправки письма или создания заявки не должен выполнять действие второй раз.
- Убедитесь, что логи собирают весь ход вызова: исходный запрос, выбранный инструмент, сырые аргументы, результат валидации, ответ инструмента и текст, который увидел пользователь.
Если команда использует несколько моделей, этот прогон нужен для каждой связки. Формат вызова один, а мелкие ошибки у моделей разные. В среде вроде AI Router это особенно заметно: один OpenAI-совместимый эндпоинт упрощает интеграцию, но не отменяет проверку поведения каждой модели. Такой прогон занимает минуты. Разбор инцидента после релиза обычно длится намного дольше.
Что делать дальше
После первых тестов не пытайтесь покрыть все сразу. Лучше собрать короткий регрессионный набор из 8-12 кейсов и гонять его после каждого изменения модели, системного промпта и JSON schema. Этого обычно хватает, чтобы поймать большую часть поломок до релиза.
В такой набор стоит включить не только удачный ответ. Нужны кейсы с пустыми аргументами, пропавшим обязательным полем, лишним полем, неверным типом, таймаутом инструмента и повторным вызовом одного и того же действия. Если инструмент может списывать деньги, менять статус заказа или отправлять сообщение, отдельно проверьте идемпотентность.
Рабочий минимум выглядит так:
- один набор регрессионных тестов для каждого критичного инструмента
- прогон после смены модели, промпта и схемы
- отдельная проверка таймаутов, ретраев и дублей
- контроль логов и маскирования PII
- один ответственный за схему и правила вызова
Если команда сравнивает несколько моделей, нет смысла менять SDK и разводить отдельные интеграции ради каждого прогона. Проще держать один OpenAI-совместимый путь ко всем моделям и менять только маршрут. Для команд в Казахстане и Центральной Азии это можно собрать через AI Router на api.airouter.kz: код и SDK остаются теми же, а сравнивать поведение моделей в одинаковых условиях заметно проще.
С логами лучше договориться заранее, а не после инцидента. Решите, где вы храните запросы и ответы, кто имеет доступ к сырым аргументам инструмента, сколько живут логи и как маскируются персональные данные. Если в аргументы могут попасть ИИН, телефоны, адреса или медицинские данные, правило маскирования должно работать по умолчанию.
И последнее: у схемы, тестов и правил ретрая должен быть владелец. Один человек или одна команда. Иначе схема меняется, тесты отстают, а повторный вызов начинает вести себя по-разному в соседних сервисах. На практике именно это ломает продакшен сильнее, чем сама модель.