Гибридный поиск по документам: BM25 и эмбеддинги
Гибридный поиск по документам помогает точнее находить приказы, договоры и тикеты. Разберем схему BM25 и эмбеддингов, настройку и частые ошибки.
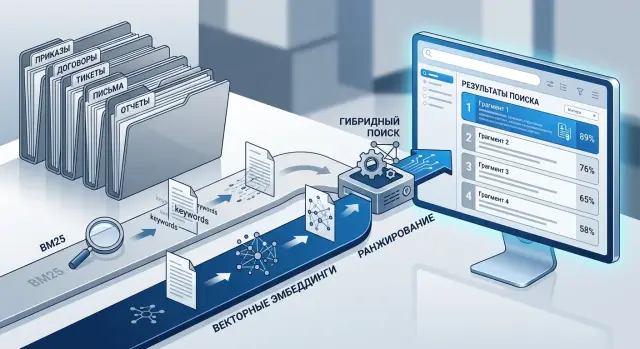
Почему один способ поиска теряет нужные документы
Проблема часто не в индексе, а в языке самих документов. Один и тот же смысл в компании записывают по-разному. Сотрудник ищет "отпуск за свой счет", в приказе стоит формулировка "без сохранения заработной платы", в договоре это спрятано внутри длинного условия, а в тикете кто-то пишет просто "unpaid leave" или "БС".
С приказами все упирается в сухой язык. Текст короткий, шаблонный, с датами, номерами и ссылками на внутренние правила. По точной фразе такой документ находится быстро. Но если человек формулирует запрос своими словами, поиск по совпадению слов часто проходит мимо.
С договорами другая проблема. Смысл там редко лежит на поверхности. Простая мысль легко прячется в абзаце на десять строк: сначала исключения, потом условия, потом ссылка на приложение. Если поиск смотрит только на слова, он цепляется за частые юридические обороты и тянет наверх не те фрагменты. Если он смотрит только на смысл, то иногда находит текст по теме, но не тот пункт, где указан нужный срок, штраф или обязанность.
С тикетами шум еще выше. Люди пишут быстро, с жаргоном, сокращениями и опечатками. Один сотрудник пишет "не грузит CRM", другой - "crm лагает", третий - "503 на карточке клиента". Для обычного поиска это почти разные миры. Для семантического поиска тоже не все просто: он может найти похожую жалобу, но перепутать инцидент с багом, вопрос с запросом на доступ, локальную проблему с массовой.
Поэтому один метод почти всегда что-то теряет:
- поиск по точным словам пропускает перефразировки, жаргон и сокращения;
- семантический поиск сглаживает формулировки, но иногда теряет важные детали;
- коротким документам не хватает контекста;
- длинным мешает лишний шум.
В реальной работе запрос редко звучит так же, как текст в базе. Особенно если в одном корпусе лежат приказы, договоры и тикеты. Поэтому гибридный поиск по документам обычно работает лучше: BM25 держит точность на терминах, номерах и формулировках, а эмбеддинги помогают там, где люди говорят другими словами.
Когда BM25 лучше, а когда нужны эмбеддинги
BM25 полезен там, где один символ меняет смысл. Если сотрудник ищет приказ № 47, статью 12.3, код ошибки E102 или точную формулировку вроде "служебная командировка", такой поиск почти всегда надежнее чисто смыслового.
Причина простая: BM25 смотрит на конкретные слова и на то, насколько они редки в корпусе. Чем точнее запрос совпадает с текстом, тем выше шанс, что нужный документ окажется сверху. Для приказов это особенно заметно, потому что в них много номеров, дат, должностей, названий подразделений и устойчивых формулировок.
Эмбеддинги полезны в другой ситуации. Они помогают, когда человек формулирует запрос не теми словами, которые есть в документе. В тикетах это происходит постоянно: один сотрудник пишет "зависает касса", другой - "терминал долго отвечает", третий - "продажа не пробивается". Смысл близкий, слова разные. BM25 такие связи часто теряет, а эмбеддинги их подхватывают.
С договорами почти всегда нужен смешанный подход. Там важны и точные слова, и близкий смысл. Юрист может искать "штраф за просрочку", а в тексте будет "неустойка при нарушении срока". При этом номер договора, пункт 5.4 и название контрагента нельзя терять. Одного сигнала здесь мало.
Ориентир простой. Приказы чаще выигрывают от точного совпадения слов, номеров и статей. Тикеты чаще выигрывают от поиска по смыслу. Договоры лучше ранжировать по двум сигналам сразу. Со справками и регламентами все зависит от того, как люди привыкли искать внутри компании.
Хорошая проверка - взять один и тот же запрос и посмотреть, что поднимают оба метода. Запрос "как оформить удаленную работу на 2 дня" может не совпасть с текстом приказа, где написано "временный дистанционный режим". Эмбеддинги это поймают. А запрос "приказ 184 от 15 марта" почти всегда лучше отдавать BM25.
На практике редко стоит выбирать что-то одно. Если в корпусе смешаны приказы, договоры и тикеты с разным стилем текста, BM25 держит точность на формулировках, а эмбеддинги закрывают перефразирование и разговорный язык. Вместе они дают ровнее результат.
Как подготовить корпус к индексации
Плохой поиск часто начинается не с модели, а с корпуса. Если в одном индексе лежат приказы, договоры и тикеты без структуры, система путает короткие служебные фразы с важными условиями договора и теряет нужный документ по номеру или дате.
Сначала разделите документы по типам. У приказа обычно строгий шаблон, у договора много повторяющихся формулировок, а тикет написан живым языком, с ошибками, сокращениями и кусками переписки. Уже одно это часто улучшает выдачу на первом этапе отбора.
Для каждого документа храните не только текст, но и понятные поля: номер, дату, автора или исполнителя, отдел, статус. Эти поля помогают и BM25, и фильтрам. Пользователь часто ищет не по смыслу, а по опоре: "договор 154 от марта", "тикет от ИТ-отдела", "приказ по филиалу". Если такие данные спрятаны внутри общего текста, поиск быстро становится шумным.
Отдельно уберите служебный мусор. Колонтитулы, повторяющиеся подписи, штампы согласования, длинные дисклеймеры и дубли страниц раздувают индекс. В итоге один и тот же шаблон начинает весить больше, чем реальное содержание. На договорах это особенно заметно: типовые блоки встречаются в сотнях файлов и мешают отличить один документ от другого.
Сокращения лучше привести к одному виду до индексации. Если в одних местах написано "дог.", в других "договор", а в тикетах встречается "д-р", поиск дробит совпадения. Выберите один стандарт и применяйте его везде. То же касается названий отделов, должностей и частых внутренних аббревиатур.
Основной текст и вложения тоже лучше не смешивать. Письмо, скан приложения, комментарий в тикете и текст самого договора решают разные задачи. Если сложить их в одно поле, короткий запрос может вернуть документ только потому, что нужное слово встретилось в приложении, а не в основном содержании. Проще держать отдельные поля: body_text, attachment_text, comments.
Пример простой: у договора есть номер, дата, контрагент и тело документа, а у вложения - свой текст и свой тип. Тогда поиск по номеру находит сам договор, а поиск по фразе из акта отдельно поднимает приложение. Потом проще настраивать веса.
Как резать документы на фрагменты
Слишком крупные фрагменты прячут ответ в лишнем тексте. Слишком мелкие ломают смысл. Нужен такой кусок, который можно понять без соседней страницы.
У договоров границы обычно уже есть в структуре. Делите их по разделам, пунктам и приложениям, а не по ровному числу символов. Пункт про штрафы лучше хранить отдельно от условий оплаты, даже если оба короткие. Тогда BM25 находит точные слова, а эмбеддинги подтягивают похожие формулировки.
С приказами схема другая. Один приказ часто смешивает тему, сроки, ответственных и приложения. Основной текст удобно делить по смысловым блокам, а каждое приложение хранить отдельным фрагментом. Если приложение состоит из таблицы, добавьте короткий контекст: номер приказа, тема и что это за приложение.
Тикеты на формальные документы не похожи, и резать их нужно иначе. Переписку лучше делить по ходу разговора: описание проблемы, уточнение, проверка, итоговое решение. Финальный ответ редко живет сам по себе. Если инженер пишет "причина в правах доступа", рядом нужна хотя бы короткая сводка, к какому сбою это относилось.
Каждый фрагмент лучше хранить не как голый текст, а вместе с метаданными: темой документа, типом, номером и датой, подразделением или автором, идентификатором раздела, пункта или приложения. Это помогает и поиску, и фильтрам. В корпоративном поиске часто ищут не просто "условия оплаты", а "условия оплаты в договоре поставки за 2024 год". Без метаданных такие запросы легко путаются.
Полезная проверка очень простая: дайте фрагмент коллеге без соседнего текста и спросите, может ли он ответить на типовой запрос. Если ответ понятен, размер нормальный. Если человеку не хватает абзаца до или после, вы разрезали слишком агрессивно.
Хороший ориентир - не число символов, а законченная мысль. Один цельный блок почти всегда работает лучше, чем два случайных куска по 800 знаков.
Как устроить гибридный поиск
Гибридный поиск лучше собирать как простую цепочку, а не как набор сложных правил. Один и тот же запрос может содержать и точные якоря, и смысловые намеки. Поэтому BM25 и эмбеддинги лучше запускать вместе.
Сначала нормализуйте запрос так, чтобы не ломать точные совпадения. Приведите к одному виду даты, номера документов и частые сокращения. Например, "договор 15/24 от 3 марта" и "договор №15-24 от 03.03.2024" лучше свести к одной форме. То же касается "ТЗ", "техзадание", "SLA", "уровень сервиса". Иначе BM25 увидит шум, а векторный поиск получит лишнюю неоднозначность.
Дальше схема обычно такая:
- Отправьте нормализованный запрос сразу в два индекса: BM25 для точных словоформ и векторный поиск для смысловой близости.
- Возьмите top-N из каждого списка. На старте часто хватает 30-50 фрагментов с каждой стороны.
- Объедините результаты по id фрагмента, чтобы один и тот же кусок текста не дублировался в выдаче.
- Приведите баллы к общей шкале. Сырые score у BM25 и векторов несопоставимы, поэтому их нужно нормализовать.
- Посчитайте общий балл простыми весами. Для договоров вес BM25 часто выше, для тикетов можно сильнее опереться на эмбеддинги.
На первом запуске не усложняйте формулу. Часто хватает такого правила:
общий_балл = 0.6 * bm25_norm + 0.4 * vector_norm
Это не универсальное соотношение, но для смешанного корпуса оно дает понятную стартовую точку. Если люди часто ищут по номеру приказа, дате, имени клиента или точной формулировке пункта, увеличивайте долю BM25. Если запросы звучат размыто, вроде "жалобы на долгую доставку" или "условия расторжения без штрафа", усиливайте векторную часть.
На одном примере это видно сразу. Запрос "договор по SLA для филиала Алматы" может вернуть нужный фрагмент даже тогда, когда в тексте нет аббревиатуры SLA, а есть "срок реакции" и "уровень обслуживания". Векторный поиск подтянет такой кусок по смыслу, а BM25 поможет не потерять фрагмент с точным названием филиала или номером приложения.
Пользователю обычно не нужен длинный список. Лучше показывать 5-10 сильных фрагментов, а не целые документы подряд. Так человек быстрее видит релевантный абзац, дату, номер и контекст. Для корпоративного поиска это почти всегда удобнее, чем выдача из десятков длинных PDF.
Пример на одном запросе
Запрос сотрудника звучит так: компенсация сверхурочных после увольнения. Если искать только по точным словам, часть ответа найдется быстро, но часть останется ниже в выдаче. Именно на таких запросах смешанный подход особенно заметен.
BM25 обычно сразу поднимет приказ, где рядом встречаются "сверхурочные", "компенсация" и "увольнение". Рядом может выйти трудовой договор или допсоглашение, если там прямо сказано, как компания считает переработки, в какие сроки платит и есть ли ограничения после расторжения договора. Для юриста или HR это хорошая основа, потому что точные совпадения часто ведут к официальной норме.
Но в реальном архиве часть нужной информации лежит не в приказах, а в переписке и внутренних тикетах. Там люди пишут иначе: "переработка", "доначисление", "не вошло в финальный расчет", "после увольнения не выплатили часы". Эмбеддинги обычно находят такие записи, даже если слова запроса не совпадают один в один. Они подтягивают живые случаи, где уже обсуждали похожую ситуацию и объясняли, как ее считать.
Хорошая выдача в таком случае выглядит связно: сверху идет приказ с нормой по оплате сверхурочных, рядом договор или приложение с условиями расчета, затем тикет бухгалтерии с похожим кейсом и ответ HR с исключением, если часть часов не согласовали заранее.
Пользователь видит не один документ, а связанный набор. Сначала правило, потом условия, потом реальный случай. Это заметно снижает риск, что человек возьмет красивую формулировку из приказа и пропустит оговорку в договоре или практику расчета из тикетов.
Если поиск собран аккуратно, сотрудник не прыгает между папками и системами. Он открывает 3-4 результата и быстро понимает, что положено по документам, где бывают исключения и как такой случай уже решали внутри компании.
Как настроить веса и проверить результат
Веса лучше подбирать не на одном удачном примере, а на живых запросах. Соберите хотя бы 30-50 запросов для каждого типа документов: отдельно для приказов, договоров и тикетов. У каждого запроса сразу зафиксируйте, какой фрагмент вы считаете правильным ответом.
Этого уже достаточно, чтобы поиск перестал выглядеть как "магия". Вы сразу увидите, где система ловит точные слова, а где важнее смысл запроса.
Для приказов обычно полезно дать перевес BM25. В таких текстах много номеров, дат, названий подразделений и точных формулировок вроде "ввести в действие" или "утвердить график". Нормальная стартовая точка - 0.7 для BM25 и 0.3 для эмбеддингов.
С тикетами картина часто обратная. Люди пишут коротко, с ошибками, сленгом и разными способами описывают одну и ту же проблему. Здесь можно начать с 0.4 для BM25 и 0.6 для эмбеддингов, а потом смотреть на выдачу.
Договоры обычно оказываются между этими крайностями. В них есть и точные термины, и длинные перефразированные куски. Поэтому разумно начать почти с равного баланса и потом сдвигать вес в ту сторону, где больше промахов.
Смотрите не на абстрактное "качество", а на несколько простых признаков:
- попал ли нужный фрагмент в первые 3 результата;
- попал ли он хотя бы в первые 10;
- не лезут ли наверх документы другого типа;
- не дублируются ли почти одинаковые куски одного текста.
Первые 3 результата показывают, удобно ли людям работать с поиском. Первые 10 показывают, умеет ли система вообще находить правильный материал, даже если ранжирование еще слабое.
Меняйте один параметр за раз. Если вы одновременно подняли вес эмбеддингов, сменили размер фрагмента и включили новую нормализацию score, вы не поймете, что именно помогло. Достаточно вести простую таблицу: версия настроек, доля попаданий в топ-3, доля попаданий в топ-10, короткий комментарий по ошибкам.
Нормальный признак хорошей настройки такой: по запросу "приказ о переносе смен на май" наверху лежит нужный приказ с точной формулировкой, а по запросу "касса виснет после возврата" поиск поднимает похожие тикеты, даже если слова в них не совпадают один в один.
Частые ошибки
Проблемы в гибридном поиске обычно связаны не с моделью, а с тем, как команда готовит корпус и смешивает сигналы. На демо все выглядит убедительно, а в работе система теряет нужные пункты, номера и ответы с близким смыслом.
Самая частая ошибка - хранить весь договор или длинный приказ одним куском. Тогда BM25 находит документ по редкому слову, но не может поднять нужный фрагмент. Эмбеддинги тоже слабеют: один большой блок смешивает предмет договора, штрафы, сроки и приложения. Пользователь ищет "изменение срока оплаты", а получает начало документа на 40 страниц.
Сильно портит результат и сырой OCR-текст. Если в скане вместо "договор" получилось "доrоgор", поиск ломается сразу в двух местах. Точный поиск не видит термин, а смысловой получает шумный текст и строит слабые векторы. Перед индексацией такой текст нужно чистить: убирать мусорные переносы, битые символы, повторяющиеся колонтитулы и номера страниц.
Еще одна ошибка - одинаково ранжировать запросы разного типа. Номер договора, ИИН, код заявки и фраза вроде "почему клиенту не пришел акт" не должны идти по одной схеме. Иначе точное совпадение иногда проигрывает документу, который просто похож по теме.
Многие забывают про синонимы и внутренний язык компании. Один отдел пишет "юридический блок", другой - "правовой департамент", третий использует код вроде "ДП-07". Для людей это одно и то же. Для индекса без словаря соответствий - три разные сущности.
Проверка качества тоже часто обманывает. Команда берет десять аккуратных запросов, где все слова написаны правильно, и решает, что поиск уже хорош. В жизни сотрудники ищут иначе: сокращают названия отделов, путают номера приказов, вставляют в запрос кусок письма, используют разговорную формулировку из тикета. Если тестировать только "красивые" запросы, настоящие провалы останутся незаметными. Лучше брать логи реальных обращений и отдельно смотреть точные запросы, смысловые и смешанные. Тогда быстро видно, где нужен другой вес, где не хватает словаря, а где индекс портит плохой OCR.
Короткий чек-лист перед запуском
Перед запуском полезно проверить не одну красивую демо-выдачу, а обычные рабочие запросы. Приказы, договоры и тикеты говорят на разном языке: в договоре важны номер и дата, в тикете люди пишут своими словами, а в приказе часто повторяются шаблонные формулировки.
- Разделите документы по типам. Иногда хватает отдельных полей, а иногда лучше делать отдельные индексы для договоров, приказов и тикетов.
- Сохраните метаданные рядом с текстом. Дата, номер, статус и подразделение часто решают больше, чем сам текст.
- Соберите не меньше 30 живых запросов. Нужны реальные фразы вроде "договор 45/23", "отпускной приказ март", "тикет по сбою оплаты".
- Включите лог запросов и кликов. Без него поиск трудно улучшать.
- Заранее решите формат ответа. В одних сценариях лучше показывать фрагмент, в других - весь документ, а иногда нужны оба варианта.
Есть и простой тест на здравый смысл. Если сотрудник ищет "договор по аренде склада, подписан весной", система должна вернуть не просто похожий текст, а документ, который можно быстро проверить по дате, статусу и номеру. Если этих полей нет в выдаче, человек все равно пойдет искать вручную.
Для первого релиза не нужна идеальная схема. Нужна понятная база, на которой можно измерять ошибки и постепенно править веса BM25 и эмбеддингов по реальным действиям пользователей.
Что делать после запуска
Запуск индекса ничего не завершает. Даже хороший поиск начинает ошибаться, когда люди пишут так, как привыкли, а не так, как вы ожидали в тестах. В живой работе быстро всплывают "допсог", "служебка", номер договора без пробелов или тикет, наполовину состоящий из сленга.
Сохраняйте запросы, после которых человек не открыл ни одного документа или сразу вернулся к поиску. Это самый честный сигнал. Полезно раз в неделю разбирать хотя бы 20-30 таких примеров вручную, а не смотреть только на средние метрики.
Обычно промахи видны в нескольких местах: люди используют сокращение, которого нет в словаре; нужный документ порезан на слишком мелкие или слишком длинные фрагменты; BM25 слишком сильно тянет точные слова из другого типа документа; эмбеддинги находят похожий по смыслу текст, но не тот приказ, договор или тикет.
Словарь сокращений и типовых формулировок лучше пополнять постоянно. В компаниях редко пишут одинаково: "дополнительное соглашение", "допсог" и "ДС" могут значить одно и то же, а "не закрывается тикет" и "заявка висит" часто ведут к одному классу обращений. Если такие пары не учесть, поиск будет терять хорошие документы просто из-за языка.
Раз в квартал полезно пересматривать размеры фрагментов и веса между BM25 и эмбеддингами. Корпус меняется. Сегодня у вас много коротких приказов, через три месяца добавятся длинные переписки из тикетной системы, и прежние настройки начнут шуметь. Это не большая переделка, а обычная гигиена поиска.
Если поверх поиска работает LLM, удобно держать маршрутизацию моделей и аудит в одном слое. Например, AI Router на airouter.kz дает один OpenAI-совместимый эндпоинт, аудит-логи, rate-limits и маскирование PII, а команде не приходится переписывать интеграцию при смене модели.
И не превращайте поиск в чат слишком рано. Чат умеет красиво скрывать промахи: ответ звучит уверенно, хотя система подняла не тот фрагмент. Сначала добейтесь стабильных попаданий по частым запросам хотя бы в верхних результатах, и только потом добавляйте генерацию ответа поверх выдачи.
Часто задаваемые вопросы
Почему одного BM25 часто не хватает?
Потому что люди и документы говорят по-разному. BM25 хорошо ловит точные слова, номера, даты и статьи, но часто пропускает перефразировки, жаргон и сокращения.
Эмбеддинги закрывают эту дыру, но иногда теряют точный пункт, код ошибки или номер приказа. В рабочем корпусе эти два сигнала обычно дополняют друг друга.
В каких случаях BM25 работает лучше всего?
Берите BM25 первым, когда запрос держится на точном совпадении. Это номер приказа, статья, код ошибки, ИИН, дата или устойчивая формулировка вроде «служебная командировка».
В таких случаях даже один символ может менять смысл, и поиск по словам обычно ранжирует лучше, чем чистый поиск по смыслу.
Когда стоит сильнее опираться на эмбеддинги?
Эмбеддинги полезны там, где сотрудники пишут своими словами. Один человек пишет «касса виснет», другой — «терминал долго отвечает», третий — «не пробивается продажа».
Если смысл близкий, а слова разные, векторный поиск часто находит нужные тикеты и фрагменты быстрее обычного совпадения слов.
Нужно ли разделять приказы, договоры и тикеты по типам?
Да, это часто помогает уже на старте. У приказов, договоров и тикетов разный язык, разная длина и разный шум, поэтому один общий индекс быстрее начинает путать шаблонные фразы с полезным текстом.
Минимум храните тип документа в отдельном поле. Если корпус большой и сильно разнородный, имеет смысл разнести типы по разным индексам или хотя бы по разным схемам ранжирования.
Какие поля и метаданные лучше хранить рядом с текстом?
Не прячьте все в один общий текст. Сохраняйте номер, дату, статус, автора, отдел, контрагента и тип документа в отдельных полях.
Так вы сможете фильтровать выдачу и точнее ранжировать результаты. Запрос вроде «договор 154 от марта» система обработает заметно лучше, если номер и дата лежат отдельно от тела документа.
Как правильно делить документы на фрагменты?
Режьте не по числу символов, а по законченной мысли. Для договоров обычно подходят разделы, пункты и приложения. Для приказов — смысловые блоки и отдельные приложения. Для тикетов — этапы разговора: описание, уточнение, решение.
Простой тест такой: дайте фрагмент коллеге без соседнего текста. Если он понимает, о чем речь, размер нормальный. Если нет, фрагмент слишком короткий.
Как на практике собрать гибридный поиск?
Обычно хватает простой схемы. Нормализуйте запрос, отправьте его и в BM25, и в векторный индекс, возьмите top-N из обоих списков, объедините по id и потом посчитайте общий балл.
На старте берите простую формулу, например 0.6 для BM25 и 0.4 для векторов. Дальше меняйте веса по типам документов и по живым запросам, а не по одному красивому примеру.
Какие веса между BM25 и эмбеддингами взять на старте?
Для приказов можно начать с перевеса BM25, например 0.7 на 0.3. Для тикетов часто лучше работает обратная пропорция, потому что там больше разговорного языка, ошибок и сокращений.
Для договоров разумно стартовать почти с равного баланса. Потом смотрите, где система ошибается: если теряет номера и пункты, добавляйте вес BM25; если не ловит перефразировки, усиливайте векторную часть.
Как понять, что поиск настроен нормально?
Соберите набор реальных запросов и сразу отметьте правильные фрагменты. Уже 30–50 запросов на каждый тип документов дадут полезную картину.
Смотрите, попадает ли нужный фрагмент в топ-3 и хотя бы в топ-10. Еще проверьте, не лезут ли наверх документы другого типа и не дублируются ли почти одинаковые куски одного текста.
Что обычно портит результат уже после запуска?
Чаще всего поиск ломают не модели, а корпус. Длинные документы индексируют одним куском, OCR оставляет битые символы, повторяющиеся колонтитулы раздувают вес шаблонов, а словарь сокращений никто не ведет.
После запуска сохраняйте запросы без кликов и случаи, когда человек сразу возвращается к поиску. По ним быстро видно, где не хватает словаря, где фрагменты слишком мелкие или длинные и где ранжирование путает типы документов.