Семантический кэш и точное совпадение: где больше экономии
Разбираем, когда точное совпадение дает больше экономии, а когда семантический кэш ловит больше повторов, но начинает возвращать чужие ответы.
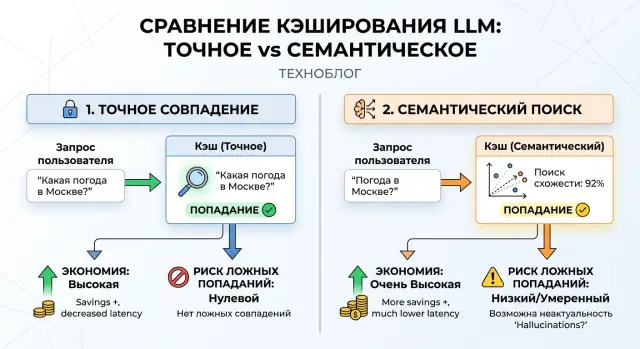
Где кэш решает проблему, а где создает новую
Кэш помогает, когда люди спрашивают об одном и том же, но формулируют вопрос по-разному. В поддержке это видно сразу: один клиент пишет "как вернуть товар", другой - "где оформить возврат", третий - "мне нужен возврат заказа". Смысл один, строки разные. Если каждый раз отправлять такой запрос в модель заново, вы тратите токены на повтор.
Проблема в том, что точное совпадение видит только полную копию строки. Такой кэш хорошо работает, если вопрос повторяют слово в слово: в шаблонных командах, коротких FAQ, одинаковых системных запросах и типовых промптах внутри продукта. Но стоит переставить слова или заменить одно из них синонимом, и попадания уже нет.
Семантический кэш закрывает этот пробел. Он ищет не ту же строку, а похожий смысл. Поэтому чаще находит повторы и чаще экономит токены. В поддержке, внутреннем поиске и базе знаний эффект бывает заметен уже в первые дни.
Но здесь появляется другая проблема. Похожие фразы не всегда означают одно и то же. "Как сменить тариф" и "как отключить тариф" звучат близко, но действие разное. Если кэш решит, что это один запрос, пользователь получит чужой ответ. На графике затрат все выглядит красиво. В продукте - нет.
Чаще всего вред начинается в двух случаях: когда запросы короткие и двусмысленные, и когда рядом лежат похожие намерения, а разница в ответе меняет действие пользователя. Тогда экономия быстро превращается в потерю доверия. Один неверный ответ в справке еще можно пережить. Ошибка в банке, телекоме или медсервисе обычно заканчивается жалобой, повторным обращением и ручной проверкой.
Хороший кэш должен не только отвечать быстрее, но и делать это безопасно. Если вопрос допускает только один точный ответ, лучше реже пропускать повторный вызов, чем уверенно вернуть ошибку. А если у вас поток однотипных перефразов, семантический кэш обычно окупается быстрее, чем точное совпадение.
Что дает точное совпадение
Точное совпадение - самый строгий и самый понятный вид кэша для LLM. Система берет запрос целиком, сравнивает его посимвольно или по хэшу, а потом ищет готовый ответ. Если строка полностью совпала, кэш сразу возвращает результат. Если нет, модель отвечает заново.
Главный плюс такого подхода в том, что он почти не подмешивает чужой ответ. Запрос "Покажи статус заказа 1542" не спутается с запросом "Покажи статус заказа 1543". Для поддержки, биллинга, внутренних форм и любых операций, где одно число меняет смысл, это большой плюс.
Но строгие правила быстро режут долю попаданий. Иногда все ломает мелочь: лишний пробел, другая дата, новый номер клиента или иной порядок полей в JSON. Смысл тот же, а для кэша это уже новый запрос. Поэтому точное совпадение редко дает чудеса в живом чате, где люди пишут по-разному, и хорошо работает там, где текст идет по шаблону.
Польза особенно заметна в системах с повторяющимися сценариями. Например, команда отправляет в модель один и тот же системный промпт, одну и ту же структуру запроса и меняет только редко обновляемые блоки. Тогда hit rate может быть высоким, а экономия токенов - ощутимой. Если такие запросы идут через единый OpenAI-совместимый шлюз, например AI Router, поведение кэша проще проверить заранее и легче сравнивать результаты между моделями.
У этого подхода есть еще один плюс: его легко объяснить команде. Разработчики, аналитики и поддержка быстро понимают, почему был hit или miss. В логах тоже все прозрачно: строка совпала или нет.
Лучше всего точное совпадение работает там, где есть готовые шаблоны без свободного текста, частые повторы служебных запросов и ответы, в которых нельзя рисковать подменой смысла. Если нужен первый безопасный слой кэширования, этот вариант обычно выигрывает. Он не ловит все похожие запросы, зато ведет себя честно и предсказуемо. Для продакшена это часто важнее, чем еще несколько процентов экономии.
Что меняет семантический кэш
Семантический кэш работает не по точной строке. Он сначала переводит вопрос в вектор, а потом ищет в кэше не одинаковый текст, а близкий по смыслу. Поэтому он ловит перефразы, сокращения и простые синонимы, которые точное совпадение пропускает.
Для LLM это заметная разница. Один пользователь пишет "как сменить тариф", другой - "где поменять план". Текст разный, смысл почти один. Если стоит семантический кэш, система часто вернет готовый ответ и не отправит новый запрос в модель. На повторяющихся вопросах это заметно повышает число попаданий и лучше экономит токены.
Но вместе с экономией появляется новая точка риска - порог похожести. Именно он решает, когда запросы уже достаточно близки, чтобы вернуть старый ответ. Если порог высокий, кэш ведет себя осторожно: ошибок меньше, но и попаданий тоже меньше. Если порог ниже, экономия растет, но вместе с ней растет и риск ложных совпадений.
Проблема обычно не в самой идее, а в деталях. Система легко путает "как закрыть карту" и "как заблокировать карту", если смотрит только на смысловую близость фразы. Для человека разница очевидна. Для кэша без ограничений это уже зона ошибки.
Поэтому семантический кэш редко запускают как есть. Ему почти всегда нужны простые фильтры: язык, продукт, роль пользователя, а иногда версия документации или регион. Если команда ведет LLM-трафик через единый шлюз вроде AI Router, такие ограничения удобно держать рядом с маршрутизацией запросов и логами. Тогда кэш ищет похожий ответ не во всем массиве подряд, а в более узком и безопасном наборе.
Разница между двумя подходами простая. Точное совпадение ловит одинаковые запросы. Семантический кэш ловит одинаковое намерение. Именно это дает больше выгоды, и именно здесь начинаются ложные попадания.
Где каждый подход экономит больше
Экономия зависит от формы запросов. Если пользователи снова и снова пишут одну и ту же короткую фразу, точное совпадение почти всегда дает лучший результат. Оно работает быстро, стоит дешево и почти не возвращает чужие ответы.
Так бывает в простых сценариях: сброс пароля, статус заказа, часы работы, типовые команды в боте. Один ответ можно вернуть много раз без повторного вызова модели. Чем короче текст и чем меньше в нем переменных, тем выше экономия токенов.
Семантический кэш полезен там, где смысл один, а формулировки разные. В поддержке, FAQ и поиске по базе знаний люди редко задают вопрос одинаковыми словами. Один пишет "как вернуть товар", другой - "можно ли оформить возврат", третий - "что делать, если вещь не подошла". Для точного совпадения это три разных запроса, а для семантики - почти один.
На длинных промптах картина меняется. Если в запросе есть имя клиента, дата, сумма, номер договора или другие поля, точные совпадения случаются редко. Для обычного кэша это плохо с точки зрения hit rate, но часто лучше с точки зрения безопасности, потому что ответ зависит от деталей.
Если запрос связан с персональными данными или деньгами, точное совпадение обычно надежнее. Вопросы "почему списали 12 500 тенге" и "почему списали 15 200 тенге" похожи по форме, но ответ у них может быть разный. Семантический кэш здесь легко подмешает неверный ответ.
Сравнивать подходы лучше по четырем метрикам: процент попаданий в кэш, средняя экономия токенов на запрос, доля ложных попаданий и цена ошибки для бизнеса. На практике часто выходит так: точное совпадение дает меньше попаданий, но почти без риска; семантический кэш дает больше повторного использования в поддержке и FAQ, но требует строгого порога похожести и проверки на чувствительные поля.
Если ошибка дорогая, лучше потерять часть экономии. Если ответы типовые и общий смысл важнее точных деталей, семантический кэш обычно окупается быстрее.
Когда лучше смешать оба варианта
Один способ редко закрывает все случаи. Смешанная схема почти всегда дает лучший баланс: точное совпадение ловит одинаковые запросы почти без риска, а семантический кэш добирает перефразированные вопросы и экономит там, где люди спрашивают одно и то же разными словами.
Порядок здесь важен. Сначала ищите точное совпадение. Это быстрее, дешевле и почти не дает ложных попаданий. Если его нет, можно проверять похожие запросы, но только внутри того же сценария. Ответ из FAQ не должен подтягиваться в платежный диалог только потому, что фразы похожи.
Рабочее правило простое: держите отдельные зоны кэша для FAQ, оплаты, доставки и внутренних подсказок; не пускайте в семантический слой запросы, где есть имя клиента, сумма, номер заказа, баланс, дата или текущий статус; ставьте короткое время жизни для ответов, которые часто меняются; и всегда оставляйте путь к свежей генерации, если уверенность низкая или контекст спорный.
На практике это выглядит просто. В чате поддержки вопросы "Как оплатить счет?" и "Где найти реквизиты для оплаты?" часто можно закрыть одним и тем же ответом из кэша. Смысл у них один, формулировки разные. Но запрос "Почему вчера списали 12 500 тенге?" нельзя отдавать из похожего ответа. Здесь одна цифра меняет все, и ошибка будет заметна сразу.
Семантический кэш особенно хорошо работает на повторяющихся объяснениях: правила возврата, условия тарифа, шаги подключения, базовые инструкции для сотрудников. Точное совпадение лучше держит команды, шаблонные промпты и системные запросы, где важен каждый символ.
Если сомневаетесь, сужайте область применения с самого начала. Пусть семантический слой обслуживает только безопасные и общие вопросы. Все, что зависит от текущих данных, лучше отправлять на свежую генерацию или сразу в бизнес-логику. Такой порядок обычно дает экономию без неприятных сюрпризов.
Пример на чате поддержки
В чате поддержки разница между двумя видами кэша видна почти сразу. Люди редко повторяют вопрос слово в слово, но часто спрашивают об одном и том же разными фразами.
Если один клиент пишет "как вернуть товар", а через минуту другой - "можно оформить возврат", точное совпадение не сработает. Строки разные. Семантический кэш, наоборот, скорее всего посчитает смысл одинаковым и вернет готовый ответ. На частых FAQ это дает заметную экономию токенов.
С возвратами такой подход обычно работает хорошо, если ответ общий: срок возврата, список документов, способ отправки. В таких случаях семантический кэш снимает много повторных вызовов, а пользователь не замечает разницы.
Проблемы начинаются там, где похожие слова ведут в разные процессы. "Обмен" и "возврат" часто выглядят близко для модели, но бизнес-смысл у них разный. При обмене могут быть другие сроки, другой склад, другая логика доставки и доплаты. Если кэш склеит эти сценарии, чат ответит уверенно, но неверно.
Запрос "где мой заказ" еще опаснее. Его нельзя отдавать из семантического кэша как обычный FAQ, потому что человеку нужен свежий статус. Посылка могла уже приехать, застрять на сортировке или перейти в курьерскую доставку за последние полчаса. Даже хороший старый ответ здесь быстро устаревает.
На практике помогает простая разметка сценариев до кэша. Сложная схема на старте не нужна. Достаточно отделить безопасные вопросы от тех, где ответ зависит от текущих данных. Вопросы про возврат можно пускать в семантический кэш, если ответ общий. Обмен лучше держать отдельно от возврата. Статус заказа не стоит отдавать из семантического кэша без проверки свежих данных. Личный кабинет и платежи безопаснее кэшировать только по точному совпадению или не кэшировать вовсе.
Такой фильтр часто дает лучший результат, чем попытка найти один универсальный порог похожести. Для типовых правил семантика экономит больше. Для живых статусов и соседних, но разных сценариев, безопаснее точное совпадение или прямой запрос в систему заказа.
В поддержке кэш хорошо работает не там, где вопросы просто похожи, а там, где похожий вопрос действительно допускает один и тот же ответ.
Как проверить схему шаг за шагом
Начинать лучше не с теории, а с живых логов. Возьмите 200-500 реальных запросов из поддержки, поиска или внутреннего помощника и не правьте их вручную. Опечатки, короткие фразы и странные формулировки как раз показывают, как кэш ведет себя в работе, а не на аккуратном демо.
Потом разметьте запросы, где небольшой фрагмент меняет весь смысл. Чаще всего это дата, число, имя, артикул, город и отрицание. Фразы "доставка сегодня" и "доставка не сегодня" выглядят почти одинаково, но ответ им нужен разный. Именно на таких примерах семантический кэш ошибается чаще всего.
После этого разделите выборку на три группы: точные дубли, перефразы и похожие, но рискованные запросы, где детали меняют ответ. Уже этого хватает, чтобы быстро увидеть, где точное совпадение даст чистую экономию, а где можно пробовать поиск по смыслу.
На одной и той же выборке прогоните несколько порогов похожести. Не стоит брать один порог и верить ему на слово. Например, сравните 0.85, 0.90 и 0.95. Разница между ними часто заметна не только в процентах экономии, но и в числе неверных ответов.
Смотрите сразу на три вещи: сколько токенов вы сэкономили, как изменилась задержка и сколько ложных попаданий получили. Если экономия выросла на 12%, а неверных ответов стало вдвое больше, такой выигрыш обычно не стоит риска. Особенно это заметно в сценариях с заказами, оплатой, медициной и персональными данными.
Хорошая практика простая: сначала включайте кэш только для безопасных типов запросов. Подходят FAQ, повторяющиеся вопросы по правилам и короткие справочные ответы. Не стоит с первого дня кэшировать споры по платежам, юридические формулировки и запросы, где пользователь пишет про конкретного человека или договор.
Если после теста вы видите много дублей, ставьте точное совпадение первым слоем. Если перефразов много, а ложных попаданий мало, добавляйте семантический кэш вторым слоем и держите строгий порог. Рабочая схема обычно видна уже на первой выборке, без длинного пилота.
Где начинаются неверные ответы
Ошибки начинаются в тот момент, когда кэш видит похожие слова, но не замечает разницу в смысле. Самый частый сбой связан с отрицанием. Фразы "мне не списали деньги" и "мне списали деньги" очень близки по форме, но это две разные ситуации. Если семантический кэш считает их одинаковыми, пользователь получает чужой сценарий решения.
Вторая ловушка - смешивать общую справку с личным статусом клиента. Вопрос "как работает возврат" можно кэшировать довольно смело. Вопрос "где мой возврат" уже требует данных по конкретному человеку, дате и операции. Если отдать сюда ответ из общего кэша, он будет звучать правдоподобно, но пользы от него не будет.
Проблемы быстро растут там, где меняются даты, цены и лимиты. Запросы про тариф, комиссию, остаток, срок доставки или лимит по счету нельзя складывать в один и тот же кэш без дополнительных меток. Иначе ответ, который был верным вчера, сегодня уже ошибается. Точное совпадение в таких случаях обычно безопаснее, потому что оно реже возвращает старый или чужой ответ.
Еще одна частая ошибка - не обновлять кэш после смены правил. Компания изменила тариф, лимит или текст политики, а старый ответ продолжает жить в кэше неделями. Пользователь видит уверенный, связный текст и считает его официальным. Исправлять такой след потом долго, особенно в поддержке и финансах.
Ранние сигналы вреда обычно простые: после ответа бота растет число уточняющих вопросов, люди перефразируют один и тот же запрос по нескольку раз, операторы чаще правят ответ вручную, а жалоб становится больше, хотя расход токенов падает.
Экономия сама по себе ничего не доказывает. Если команда смотрит только на снижение затрат, она пропустит момент, когда ложные попадания начинают бить по качеству. Поэтому лучше считать сразу две цифры: сколько токенов удалось сэкономить и сколько ответов потом пришлось исправлять человеку. Если вторая цифра ползет вверх, порог похожести уже слишком низкий или правила кэширования выбраны неудачно.
Быстрая проверка перед запуском
Перед запуском полезно провести короткую проверку на бумаге и в тестовом трафике. Она занимает пару часов, зато часто спасает от самой дорогой ошибки: система начинает отвечать быстро и дешево, но иногда подставляет чужой смысл.
Сначала отметьте случаи, где кэш нельзя использовать вообще. Обычно это запросы с персональными данными, свежими ценами, статусом заказа, балансом, лимитами, юридическими условиями и любыми ответами, которые зависят от текущего состояния базы. Если ответ может измениться через минуту, кэш там опасен.
Потом зафиксируйте допустимую долю ложных попаданий. Для внутреннего поиска по старой документации команда может принять 1-2% спорных совпадений. Для поддержки банка или клиники даже 0.1% уже много. Это число лучше записать заранее, иначе после запуска спор пойдет по ощущениям.
Дальше нужен короткий чек. Выпишите сценарии, где кэш запрещен. Задайте порог ложных попаданий для каждого типа запросов. Убедитесь, что в логах виден источник ответа. Добавьте в тесты редкие и кривые формулировки. И отдельно проверьте, что система умеет спокойно уходить в свежую генерацию, если кэш не должен сработать.
Логи должны показывать не просто факт ответа, а его путь. Иначе вы увидите жалобу пользователя, но не поймете, откуда взялся текст: из точного совпадения, из семантического кэша или из нового запроса к модели. Простая метка вроде "exact", "semantic" и "fresh" сильно упрощает разбор.
Отдельно стоит проверить неудобные формулировки. Люди редко спрашивают одинаково. Один напишет "как вернуть товар", другой - "мне не подошло, хочу отменить покупку", третий добавит опечатки и лишние детали. Именно на таких запросах семантический кэш иногда выдает уверенный, но чужой ответ.
И еще один важный тест: что произойдет, если кэш не должен сработать. Система должна без драмы запросить новую генерацию, без ручного флага и без вмешательства инженера. Если fallback ломается, экономия быстро превращается в очередь инцидентов.
Хороший признак готовности простой: вы можете открыть любой спорный ответ в логах и за минуту понять, почему он появился и должен ли был появиться.
Что делать дальше
Не раскатывайте кэш сразу на весь продукт. Возьмите один поток, где запросы часто повторяются и где ошибку легко заметить. Обычно это FAQ в поддержке, короткие справочные ответы или внутренний помощник с узким набором задач.
Проверьте точное совпадение и семантический кэш на одной и той же выборке. Нужны те же запросы, та же модель, те же системные инструкции и одинаковые пороги успеха. Иначе сравнение быстро превратится в спор о впечатлениях, а не о цифрах.
Полезно сразу закрепить несколько правил. Считайте hit rate отдельно для точного и семантического кэша. Смотрите не только на экономию токенов, но и на долю неверных ответов. Записывайте, какой запрос попал в кэш и почему. Храните порог похожести и TTL в конфиге, а не в чьей-то памяти.
Эти правила лучше держать и в коде, и в метриках команды. Если разработчик поменял порог похожести с 0.92 на 0.84, это должно быть видно сразу. Иначе через месяц никто не поймет, почему кэш для LLM стал дешевле на бумаге, но хуже в работе.
Если команда прогоняет несколько моделей через единый OpenAI-совместимый шлюз, важно сохранить одинаковую схему вызова для всех тестов. С AI Router это удобно: можно менять маршрут до модели, не переписывая интеграцию и не смешивая результаты из-за разных настроек вызова. Так сравнение получается чище.
После пилота расширяйте кэш только там, где промахи редки и понятны. Если ложные попадания появляются из-за дат, сумм, статусов заказа или разных версий политики, не стоит надеяться, что все исправит другой порог. Для таких запросов обычно безопаснее точное совпадение или жесткие фильтры перед семантическим слоем.
Нормальный следующий шаг выглядит скучно, и это хорошо: один поток, одна выборка, один набор метрик, потом аккуратное расширение. Так экономия токенов не ломает ответы, за которые отвечает команда.
Часто задаваемые вопросы
Когда точного совпадения уже достаточно?
Точное совпадение подходит там, где текст идет по шаблону и одна мелкая деталь меняет смысл. Это хороший выбор для статуса заказа, биллинга, системных промптов и служебных команд, где безопаснее пропустить часть повторов, чем вернуть чужой ответ.
Где семантический кэш экономит больше всего?
Семантический кэш дает больше пользы, когда люди спрашивают об одном и том же разными словами. Чаще всего это поддержка, FAQ, база знаний и внутренний поиск, где перефразов много, а ответ остается общим.
Почему семантический кэш иногда подмешивает неверный ответ?
Он смотрит на близость смысла, а не на точную строку. Из-за этого система может склеить соседние намерения вроде «сменить тариф» и «отключить тариф» и вернуть уверенный, но неверный ответ.
Какие запросы лучше не отдавать в семантический кэш?
Не пускайте туда запросы с суммами, датами, балансом, статусом заказа, номером договора и персональными данными. Если ответ зависит от текущего состояния базы или от одного числа, лучше делать свежий вызов или держать только точное совпадение.
Какой порядок кэша обычно работает лучше?
Сначала проверяйте точное совпадение, потому что оно быстрее и почти не путает ответы. Если его нет, ищите похожий запрос только внутри того же сценария и только для безопасных вопросов.
Как выбрать порог похожести без гадания?
Не ставьте один порог наугад. Возьмите живые логи, прогоните несколько значений и посмотрите, где экономия растет без скачка ложных попаданий; на практике команды часто сравнивают уровни вроде 0.85, 0.90 и 0.95.
Какие метрики реально показывают пользу кэша?
Смотрите не только на hit rate. Нужны еще средняя экономия токенов, задержка, доля ложных попаданий и цена ошибки для бизнеса, потому что дешевый ответ не приносит пользы, если оператор потом все исправляет вручную.
Нужен ли TTL для ответов из кэша?
Да, и срок жизни лучше задавать по типу ответа. Правила возврата могут жить дольше, а тарифы, лимиты и статусы лучше обновлять быстро, иначе кэш начнет отдавать устаревший текст.
Как быстро проверить схему на реальных данных?
Возьмите 200–500 реальных запросов без ручной чистки и разделите их на точные дубли, перефразы и рискованные случаи, где детали меняют ответ. Потом сравните, сколько токенов вы сэкономили и сколько ответов люди признали неверными.
Можно ли использовать семантический кэш в банке или медсервисе?
Да, но только на узких и безопасных сценариях. В банке, телекоме и медсервисе лучше держать семантический кэш для общих правил и справки, а запросы про деньги, лимиты, статусы и личные данные вести через точное совпадение или свежую генерацию.