Поиск на русском и казахском: эмбеддинги и нормализация
Поиск на русском и казахском требует точного выбора эмбеддингов и правил нормализации, чтобы смешанные запросы приводили к нужным ответам.
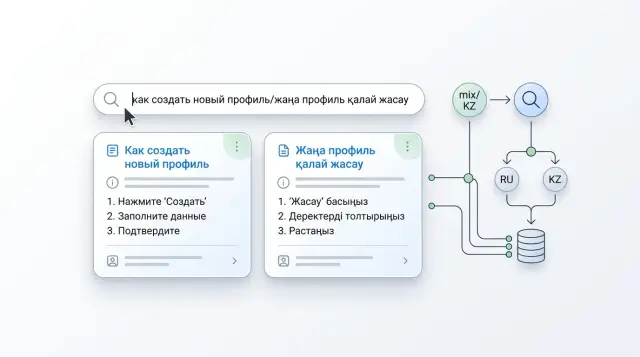
Почему смешанный запрос часто дает плохую выдачу
Проблема обычно начинается не в модели, а в самом вопросе. Люди пишут так, как говорят: часть фразы на русском, часть на казахском, плюс жаргон, опечатки и иногда транслит. Для человека это одна мысль. Для поиска это уже несколько сигналов, которые тянут выдачу в разные стороны.
Например, сотрудник спрашивает: "Как открыть счет для ИП, если клиент уже тіркелген?" Русская часть задает тему, казахское слово меняет контекст, а термин "ИП" добавляет предметную специфику. Если индекс и нормализация к этому не готовы, система цепляется за знакомые куски и теряет общий смысл.
Мешает и то, что одна и та же сущность часто живет в базе знаний в разных формах. В одном документе написано "лицевой счет", в другом - "жеке шот", а в третьем фигурирует только внутреннее название продукта. Если эти варианты не связаны в данных и редко встречаются в похожих контекстах, модель не всегда понимает, что речь об одном и том же.
Обычно сбой выглядит просто: поиск цепляет похожее слово, но не тот сценарий; русский термин находит русский документ, а казахская часть вопроса игнорируется; транслит вроде "schet ashu" выпадает из матчинга; разговорная форма уводит запрос в частые, но бесполезные ответы.
Это особенно заметно там, где люди не разделяют языки строго. В банке, поддержке или во внутреннем портале сотрудник может начать вопрос по-русски и закончить по-казахски, потому что так быстрее. В этот момент система видит не один запрос, а смесь токенов, написаний и смысловых намеков.
Без нормализации ситуация обычно становится хуже. Поисковый слой начинает поднимать документы по поверхностному сходству: по одинаковым корням, частым аббревиатурам и соседним формулировкам. Но пользователю нужен не набор похожих слов, а точный ответ на его задачу.
Слабая выдача при смешанных запросах редко означает, что сами эмбеддинги плохие. Чаще база знаний хранит синонимы раздельно, тексты пришли из разных источников, а предобработка не свела варианты написания к одной понятной форме.
Что проверить в базе знаний до выбора модели
Сначала разберите сам корпус, а не список моделей. Двуязычный поиск часто ломается не из-за эмбеддингов, а из-за того, как тексты лежат в базе. Если в одном документе русский есть только в заголовке, а казахский спрятан в таблице или сноске, модель получает слабый сигнал и возвращает странный результат.
Полезно быстро пройтись по документам и отметить, где языки смешаны сильнее всего. Чаще всего проблемы скрыты в заголовках и основном тексте на разных языках, коротких абзацах и подписях к таблицам, ячейках с терминами и кодами, а также в FAQ, где вопрос и ответ написаны по-разному. Такой просмотр занимает пару часов, но потом экономит много времени на тестах.
После этого соберите частые пары терминов из вашей предметной области. Это не переводной словарь ради словаря, а рабочий список синонимов и параллельных формулировок, которые реально встречаются в вопросах и документах. Для банка это могут быть пары вроде "ИП" - "жеке кәсіпкер", "лицевой счет" - "жеке шот", "перевыпуск карты" - разговорная формулировка из чатов. Если такого слоя нет, даже хорошая модель будет спотыкаться о разнобой в текстах.
Проверьте и структуру документов. Таблицы, сканы, PDF после OCR и старые CMS часто ломают текст сильнее, чем кажется. Одинаковая фраза в чистом HTML и в криво распознанном PDF - это уже два разных объекта для индекса. Если не убрать этот шум заранее, выбор модели мало что изменит.
Как выбрать эмбеддинги для двух языков
Для русско-казахского поиска обычная логика выбора часто не работает. Модель может хорошо понимать русский отдельно и казахский отдельно, но слабо связывать их в одном векторном пространстве. Тогда запрос вроде "как восстановить карту және комиссия бар ма" уводит поиск в сторону, хотя нужный ответ есть в базе.
Смотрите не на красивое описание модели, а на то, ставит ли она рядом документы на двух языках, если пользователь смешал их в одном вопросе. Для RAG это базовая вещь. Если связь между языками слабая, все ломается еще до ранжирования и генерации ответа.
Общие бенчмарки полезны только как первый фильтр. Финальный выбор лучше делать на своих данных: на реальных вопросах пользователей, с вашими названиями продуктов, сокращениями, ошибками в раскладке и местными терминами. Если в базе есть формулировки вроде "перевыпуск карты", "ЖСН" и смешанные служебные фразы, публичный рейтинг почти ничего не гарантирует.
Смотрите сразу на три показателя: долю верных попаданий в топ-5, цену индексирования и переиндексации, а также задержку при массовом поиске. Топ-5 часто важнее, чем топ-1. Пользователь все равно получает несколько кандидатов, а потом их дособирает reranker или LLM. Если одна модель дает 78% верных попаданий в топ-5, а другая 72%, разница уже заметна. Но если первая в три раза дороже и заметно медленнее, выбор уже не так очевиден.
На небольшой базе не нужно тестировать десять вариантов. Обычно хватает 2-3 кандидатов: одной сильной мультиязычной модели, одной более дешевой и одной с удобным вариантом размещения, если для вас важно хранение данных внутри Казахстана. Такой набор быстро показывает, где модель правда понимает смешанные запросы, а где просто хорошо выглядит на демо.
Тест лучше делать простым. Соберите 50-100 живых вопросов, где русский и казахский встречаются в одной фразе, и для каждого заранее отметьте правильные документы. Потом прогоните все модели по одному и тому же набору. На таком тесте быстро видно, какая модель держит смысл, а какая цепляется только за совпадение слов.
Если две модели дают почти одинаковое качество, разумнее брать ту, что дешевле и стабильнее по задержке. Для продакшена это обычно полезнее, чем минимальный прирост на бумаге.
Как нормализовать текст без лишних потерь
Если люди пишут вперемешку на русском и казахском, грубая нормализация часто ломает смысл раньше, чем эмбеддинги успевают помочь. В большинстве случаев хватает простых правил: привести текст к одному регистру, убрать мусор и не трогать то, что меняет значение запроса.
Первое, что стоит сделать, - выбрать один формат регистра для всех документов и запросов. Обычно достаточно нижнего регистра. Так вы убираете лишние различия между "Кредит", "кредит" и "КРЕДИТ", но не меняете смысл.
Дальше почистите то, что приехало из PDF, сканов и старых CMS. Лишние пробелы, переносы внутри слова, двойные табы, неразрывные пробелы и невидимые символы легко портят поиск. Из-за них одна и та же фраза превращается в две разные строки для индекса.
Что лучше не ломать
С казахским языком легко ошибиться на уровне символов. Пользователь может написать слово кириллицей, латиницей или смешать оба варианта в одном запросе. Но это не значит, что нужно без разбора заменять все похожие буквы. Если свести разные символы к одному виду слишком рано, вы потеряете различия между словами и ухудшите точность.
Рабочий компромисс обычно такой:
- хранить исходный текст без изменений;
- рядом держать нормализованную версию для индекса;
- отдельно добавлять мягкие правила для частых смешений кириллицы и латиницы;
- проверять спорные замены на живых запросах.
Например, запрос "карта ашу для ИП" уже смешанный. Если система еще и исказит казахские буквы или склеит куски текста после PDF, она найдет не тот раздел базы знаний. Если же просто очистить мусор, выровнять регистр и аккуратно обработать похожие символы, шанс на нормальную выдачу заметно выше.
Со служебными словами тоже не стоит спешить. В русских и казахских запросах короткие слова иногда несут важный смысл: показывают связь между объектами, вопрос, отрицание или условие. Если удалить их без проверки, поиск начнет путать "без комиссии" и "с комиссией", "для ИП" и "для ТОО".
Исходный текст всегда лучше хранить рядом с нормализованным. Это помогает в трех ситуациях: показать пользователю чистый фрагмент ответа, быстро разбирать ошибки поиска и спокойно менять правила нормализации без потери данных. Для русско-казахской базы знаний это обычная страховка от тихих поломок.
Как настроить поиск по шагам
Сначала соберите не "идеальные" примеры, а живые вопросы людей. Лучше всего подходят логи поиска, обращения в поддержку и чаты операторов. Для первого прогона достаточно 100-200 запросов, где русский и казахский встречаются в разных формах: полностью на одном языке, вперемешку в одной фразе, с опечатками, сокращениями и разговорными словами.
Потом сделайте простой эталонный набор. У каждого вопроса должен быть один документ, который вы считаете правильным ответом. Если в базе знаний банка клиент пишет "карточка бұғатталды как снять", команда должна заранее решить, что верным ответом считается инструкция по разблокировке карты, а не общий раздел про безопасность.
Дальше полезен простой порядок работы:
- Запустите базовый поиск без новых правил и сохраните выдачу.
- Для каждого запроса отметьте, попал ли правильный документ в первые 3 и в первые 10 результатов.
- Добавьте одно правило нормализации, например приведение регистра или замену разных апострофов в казахских словах.
- Повторите поиск на том же наборе вопросов.
- Сравните, что изменилось в топ-3 и топ-10.
Такой подход кажется медленным, но он экономит время. Если сразу включить транслитерацию, стемминг, удаление стоп-слов и еще несколько эвристик, потом уже трудно понять, что помогло, а что испортило поиск. На практике чаще вредят не слабые эмбеддинги, а слишком агрессивная нормализация.
Смотрите не только на число попаданий, но и на характер ошибок. Иногда нужный документ остается в топ-10, но падает со 2 места на 9. Для пользователя это уже почти промах. Поэтому качество лучше оценивать в двух срезах: что человек видит сразу и что система в принципе нашла.
Если после одного изменения качество выросло только на русских запросах, а на смешанных стало хуже, правило лучше откатить. Нормализация должна убирать шум, а не стирать язык. Когда команда идет маленькими шагами, уже через несколько итераций становится ясно, где проблема: в тексте документов, в эмбеддингах или в обработке запроса.
Пример из базы знаний банка
Клиент пишет в поиск: "Как открыть карту для ИП және қандай құжат керек". Для человека запрос понятен сразу: нужна инструкция по карте для предпринимателя и список документов. Для поиска это уже более сложная задача, потому что одна часть фразы на русском, другая на казахском.
Проблема быстро всплывает, если база знаний собрана неравномерно. Одни статьи лежат на русском, другие на казахском, а названия и формулировки не совпадают. В одном тексте пишут "ИП", в другом "жеке кәсіпкер", в третьем просто "предприниматель".
Из-за этого старый поиск дробит смысл запроса. Он находит либо материалы про открытие карты, либо статьи про документы. Пользователь получает две неполные подсказки вместо одной нужной инструкции.
В такой ситуации поиск обычно становится лучше не после одной умной настройки, а после двух понятных изменений: команда приводит тексты к одному виду и меняет модель эмбеддингов на мультиязычную.
Нормализация часто дает быстрый эффект. Команда приводит текст к одному регистру, убирает лишние символы и разнобой в написании, добавляет синонимы вроде "ИП", "предприниматель" и "жеке кәсіпкер", а также сохраняет важные банковские термины без грубого упрощения.
После этого запрос и документы становятся ближе по форме. Поиск уже не спотыкается о смесь двух языков и разные варианты одного термина.
Дальше многое решает модель эмбеддингов. Если банк использует отдельные модели или слабую модель для одного языка, векторный поиск тянет вверх тексты только по совпавшей части вопроса. Мультиязычная модель лучше держит общий смысл и связывает русские и казахские фразы в одном пространстве.
На практике нужная статья поднимается выше, если в одном чанке есть шаги по открытию карты и блок с документами. Даже когда документы вынесены в отдельный материал, хороший поиск чаще ставит рядом обе инструкции, а не одну случайную статью.
Для банка это вполне прикладной эффект. Клиенту не нужно переформулировать вопрос, а поддержка получает меньше одинаковых обращений по самым частым операциям.
Где команды чаще ошибаются
Поиск на русском и казахском редко ломается из-за одной плохой модели. Обычно причина в цепочке мелких решений. Команда пытается исправить все сразу, а потом уже нельзя понять, что именно испортило выдачу.
Что ломает результат
Первая частая ошибка - смешать перевод, транслитерацию и нормализацию в одном шаге. Например, запрос "карта бойынша лимит" можно перевести, потом упростить форму слов, потом еще заменить латиницу на кириллицу. После этого система работает уже не с исходным вопросом, а с его неточной копией. Лучше разделять этапы: отдельно чистка текста, отдельно работа с вариантами написания, отдельно перевод, если он вообще нужен.
Вторая ошибка - слишком мелкий чанкинг. Если резать документ на куски по 100-150 символов, смысл распадается. В русско-казахской базе знаний это особенно заметно: термин может быть на одном языке, а объяснение на другом. Пользователь спрашивает смешанно, а поиск видит обрывки. Обычно полезнее брать куски, в которых сохраняется одна законченная мысль, а не просто фиксированная длина.
Еще одна ошибка - проверять качество только на своих вопросах. Внутренняя команда знает структуру базы, правильные слова и даже названия разделов. Реальные пользователи пишут иначе: сокращают, смешивают языки, ошибаются в раскладке, вставляют номера продуктов и аббревиатуры. Если в тесте нет таких запросов, вы оцениваете удобный сценарий, а не живую работу.
Отдельно страдают цифры, аббревиатуры и названия продуктов. Поиск может хорошо понимать "лимит по карте", но проваливаться на "лимит по Gold", "IBAN", "KZT", "3DS" или внутреннем названии тарифа. Для банка, телекома или SaaS это обычный тип запроса. Такие токены лучше собирать в словарь вариантов и проверять отдельно.
Ошибка в эксперименте
Самая дорогая ошибка - менять эмбеддинги, чанкинг и reranker одновременно. После этого графики могут стать лучше или хуже, но выводов из них почти нет. Меняйте одну вещь за раз и держите один и тот же набор тестовых вопросов. Тогда видно, что дало прирост: новая модель, размер куска или ранжирование.
Командам обычно мешает не сложность самих языков, а отсутствие дисциплины в эксперименте. На смешанных запросах это становится заметно очень быстро.
Быстрая проверка перед запуском
Перед пилотом соберите небольшой, но честный тестовый набор. Часто хватает 20-30 запросов на русском, 20-30 на казахском и еще 20-30 смешанных. Этого достаточно, чтобы быстро увидеть, где система путается.
Берите не вычищенные примеры, а живые формулировки из чатов, тикетов и писем. Пользователь редко пишет идеально. Он может спросить "лимит по карте в тенге", "кредитті мерзімінен бұрын жабу" или смешать оба языка в одной фразе.
У каждого запроса должен быть заранее отмечен правильный результат: нужный документ, раздел или конкретный фрагмент. Без этого команда быстро начинает спорить по ощущениям. Если ответов может быть несколько, зафиксируйте один основной и один допустимый запасной.
Правила нормализации тоже стоит проверить до запуска. Они должны быть понятны и повторяемы, без ручных правок под каждый промах. Если вы приводите текст к одному регистру, убираете двойные пробелы, чистите мусорные символы и одинаково обрабатываете сокращения, это должен уметь повторить любой инженер в команде.
Перед запуском удобно проверить несколько вещей:
- есть три группы запросов: русские, казахские и смешанные;
- у каждого запроса указан ожидаемый документ или фрагмент;
- правила нормализации записаны в одном месте;
- качество считается по трем группам отдельно;
- промахи из логов попадают в следующий тестовый набор.
Не сводите все к одной средней цифре. Общий Recall@5 или MRR может выглядеть нормально, даже если смешанные запросы проваливаются. Метрики лучше смотреть по каждой группе отдельно. Если русский дает 82%, казахский 79%, а смешанные запросы только 54%, проблема уже видна.
После первых реальных запросов не выбрасывайте промахи. Наоборот, они полезнее всего. Если пользователи ищут "справка о доходах жүктеу" и система ведет не туда, такой пример должен сразу попасть в следующий набор для проверки.
Хороший запуск выглядит скучно: понятный тест, простые правила, автоматический сбор ошибок. Если этого нет, поиск начнет ломаться не в демо, а в рабочем чате.
Что делать после пилота
После пилота не стоит сразу подключать все документы и все команды. Сначала лучше выбрать один живой сценарий, где ошибка поиска стоит дорого по времени: клиентский FAQ, базу поддержки или внутренние регламенты для сотрудников.
Один сценарий проще измерять. Если сотрудник банка вводит запрос вроде "лимит по карте қалай өсіремін", система должна стабильно находить нужный материал и на русском, и на казахском. Добейтесь этого на узком наборе данных, а потом расширяйте охват.
Самая полезная привычка после пилота - вести список промахов. Не общий чат с жалобами, а короткий рабочий журнал, который команда смотрит раз в неделю. Обычно в нем хватает пяти полей: исходный запрос, что нашлось в топе, что ожидал пользователь, причина ошибки и что поменяли после разбора.
Через 2-3 недели такой список почти всегда показывает повторяющиеся сбои. Обычно это смешение языков в одном вопросе, разные формы одного термина, лишняя чистка текста или слабое покрытие казахских формулировок в базе.
Перед масштабированием зафиксируйте одну схему нормализации. Если сегодня вы удаляете пунктуацию и приводите текст к одному регистру, а завтра начинаете по-разному обрабатывать русские и казахские документы, качество быстро станет неровным.
Лучше выбрать одну понятную версию правил и присвоить ей номер. Например: сохраняем казахские буквы, убираем лишние пробелы, выравниваем регистр, не ломаем аббревиатуры и не переводим термины вручную без причины. Если позже правила меняются, команда должна понимать, какие коллекции уже переиндексированы, а какие еще нет.
После этого смотрите не только на среднюю метрику, но и на поведение системы в реальных запросах. Если 85% вопросов проходят хорошо, а оставшиеся 15% бьют по самым частым сценариям поддержки, пилот рано считать удачным.
Если команда параллельно сравнивает несколько LLM для RAG-ответов и при этом хочет хранить данные в Казахстане, можно отдельно использовать AI Router как единый OpenAI-совместимый API-слой для таких тестов. Он не исправит плохую нормализацию или слабые эмбеддинги, но упрощает сравнение моделей через один эндпоинт и помогает не переписывать интеграцию под каждого провайдера.
Рабочий следующий шаг обычно звучит скучно, но дает лучший результат: одна схема текста, один список ошибок, один живой сценарий под еженедельный разбор. Так поиск перестает быть демо и становится нормальным рабочим инструментом.
Часто задаваемые вопросы
Почему смешанный запрос на русском и казахском часто ломает выдачу?
Потому что поиск видит не одну мысль, а смесь сигналов. Русские слова тянут к одним документам, казахские — к другим, а аббревиатуры, транслит и опечатки еще сильнее размывают смысл.
В итоге система цепляется за знакомые куски фразы и пропускает нужный сценарий. Обычно проблема сидит не в одной модели, а в данных и предобработке.
С чего начать: с выбора модели или с проверки базы знаний?
Сначала разберите корпус документов. Если тексты лежат в базе в разном виде, модель не спасет поиск.
Проверьте, где языки смешаны, как оформлены таблицы, что сделал OCR, и есть ли в базе разные названия одной сущности. Уже потом сравнивайте эмбеддинги.
Что проверить в документах до теста эмбеддингов?
Чаще всего сбои сидят в заголовках, таблицах, FAQ, сканах и старых PDF. Там один язык может оказаться в заголовке, а второй — в подписи, ячейке или сноске.
Еще проверьте, как база хранит синонимы. Если "ИП", "предприниматель" и "жеке кәсіпкер" живут отдельно и редко встречаются рядом, поиск будет путаться.
Сколько моделей эмбеддингов реально стоит тестировать?
На старте хватает 2–3 вариантов. Возьмите одну сильную мультиязычную модель, одну более дешевую и одну модель с удобным размещением, если вам важно хранить данные в Казахстане.
Большой список только растянет тест. Намного полезнее прогнать небольшой набор кандидатов на живых запросах команды и пользователей.
Какие метрики важнее всего при выборе эмбеддингов?
Смотрите на долю верных попаданий в топ-5, цену индексирования и задержку. Для RAG топ-5 часто важнее топ-1, потому что потом документы еще отбирает reranker или LLM.
Если две модели дают почти одинаковое качество, обычно выгоднее взять ту, что дешевле и стабильнее по времени ответа.
Как нормализовать текст и не испортить смысл?
Не трогайте все подряд. Обычно хватает нижнего регистра, чистки мусорных символов, исправления сломанных пробелов и аккуратной обработки частых смешений кириллицы и латиницы.
Исходный текст храните отдельно от нормализованного. Так вы не потеряете данные и сможете спокойно менять правила без переезда всей базы вслепую.
Нужно ли переводить всю базу на один язык?
Нет, не нужно. Полный перевод часто добавляет ошибки и стирает реальные формулировки пользователей.
Лучше связать частые пары терминов и сохранить обе формы в индексе. Такой подход обычно работает точнее, чем попытка свести все документы к одному языку.
Какой чанкинг лучше для русско-казахской базы знаний?
Слишком мелкие куски вредят. Если вы режете текст на 100–150 символов, термин может остаться в одном чанке, а объяснение — в другом.
Берите куски, где держится одна законченная мысль. Для двуязычной базы это особенно важно, потому что смысл часто распределен между двумя языками в одном фрагменте.
Как поставить эксперимент так, чтобы потом можно было сделать выводы?
Меняйте одну вещь за раз. Если вы одновременно обновите эмбеддинги, чанкинг и правила нормализации, потом не поймете, что дало эффект, а что сломало поиск.
Соберите один тестовый набор из живых запросов и гоняйте через него все версии. Так команда быстро увидит, где помогает модель, а где мешает обработка текста.
Что делать после пилота, чтобы поиск не развалился в продакшене?
После пилота выберите один живой сценарий и ведите журнал промахов. Записывайте исходный запрос, что попало в топ, какой ответ ждал пользователь и что команда поменяла.
Через пару недель вы увидите повторяющиеся сбои: слабые синонимы, лишнюю чистку текста, плохое покрытие казахских формулировок. На этом этапе полезно зафиксировать одну схему нормализации и не менять ее хаотично.