Обновление знаний в RAG без полной переиндексации
Обновление знаний в RAG без полной переиндексации: как находить изменённые документы, пересчитывать нужные чанки и убирать старые ответы из выдачи.
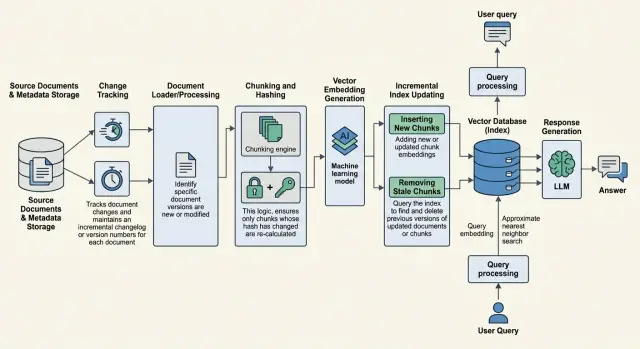
Почему старые ответы остаются в поиске
Проблема начинается не в момент генерации ответа, а раньше - в индексе. Вы обновляете документ, но старые чанки сами не исчезают. Поиск по-прежнему считает их подходящими, потому что они все еще похожи на вопрос пользователя по смыслу.
Именно так чаще всего ломается свежесть знаний в RAG. Новая версия документа уже загружена, а старая остается в векторной базе, кэше поиска или служебной таблице. В итоге система смотрит сразу в два слоя памяти: в актуальный и в устаревший.
Дата файла почти не помогает. Retriever редко принимает решение по полю updated_at. Он сравнивает запрос с текстом чанка, его эмбеддингом и метаданными, которые вы записали при индексации. Если у старого и нового документа одно имя, похожий заголовок и почти одинаковый текст, в выдачу попадают оба набора фрагментов.
Особенно неприятны точечные правки. Для человека замена фразы ответ клиенту в течение 3 дней на в течение 1 дня меняет смысл документа. Для индекса же 90% текста остались прежними. Старые и новые чанки выглядят почти одинаково, поэтому поиск легко возвращает их вместе.
Дальше обычно происходит один из двух сценариев. Либо старый чанк поднимается выше, потому что формулировка вопроса ближе к прошлой редакции. Либо обе версии попадают в один контекст, и модель собирает ответ из разных документов: цифру берет из старого текста, пояснение из нового. Пользователь получает уверенный, но уже неверный ответ.
Из-за этого ошибка выглядит особенно обидно. Команда уверена, что база знаний обновлена, а система продолжает ссылаться на старую политику, прошлый тариф или отмененный порядок. Для банка, медицины или внутреннего регламента это уже не мелкая неточность, а реальный риск.
Если не контролировать версии документов и не выключать старые чанки из поиска, система начинает смешивать прошлое и настоящее. Модель тут не "врет". Она просто отвечает по тому, что вы оставили в индексе.
Как отделить документ от его версии
Путаница обычно начинается с простой ошибки: каждая новая загрузка живет как отдельный документ без связи с прошлой. Тогда поиск видит и старый текст, и новый, а система не понимает, какой ответ считать актуальным.
Лучше сразу разделить две сущности: что это за документ и какая у него редакция. Документу нужен постоянный source_id. Он не должен меняться из-за нового имени файла, другой папки или повторной загрузки. Если это регламент отпусков, то он остается тем же источником, даже если юрист прислал его сначала как final_v3.docx, а потом как final_v4_really.docx.
Отдельно храните version_id. Это идентификатор конкретной редакции. У одного source_id может быть много версий. Такая схема быстро снимает половину проблем: можно понять, какая версия активна сейчас, какая ушла в архив и по какой версии модель отвечала неделю назад.
Каждый чанк тоже должен знать, откуда он появился. Не храните фрагменты сами по себе. Привязывайте их к source_id и version_id, чтобы система могла точно убрать старый кусок и оставить новый на его месте.
Если версия начала действовать с определенной даты, полезно хранить valid_from и valid_to. Тогда старая редакция не исчезает бесследно. Она остается в истории, но больше не участвует в обычном поиске. Для аудита это очень удобно.
Рабочий и архивный слой лучше держать отдельно. В рабочем слое лежат только актуальные чанки. В архивном - прошлые версии для проверки, отката и разбора спорных ответов. Если смешать все в одной коллекции и надеяться только на аккуратные фильтры, рано или поздно кто-то забудет один параметр, и старая норма снова всплывет в выдаче.
Хорошая схема выглядит скучно. И это плюс. Когда меняется один абзац в одном регламенте, вы точно знаете, какие чанки закрыть, какие пересчитать и что оставить в архиве.
Какие поля стоит хранить
Самый простой первый шаг - считать хеш новой версии и сравнивать его с прошлой. Но одного общего хеша на весь документ мало. Если вы храните только одну контрольную сумму, вы не отличите правку текста от смены метаданных. А это уже влияет и на стоимость обновления, и на объем работы.
На практике лучше держать две суммы отдельно: text_hash и metadata_hash. Тогда поведение пайплайна становится понятным. Если изменился только тег отдела, владелец или срок действия, достаточно обновить карточку документа и фильтры. Если изменился сам текст, нужно пересобрать затронутые чанки и убрать старые из поиска.
Обычно хватает такого набора полей: source_id, version_id, text_hash, metadata_hash, updated_at, is_active. Если хотите быстрее разбирать проблемы, добавьте автора изменения или идентификатор процесса, который внес правку.
Журнал изменений нужен не для красоты. Когда поиск внезапно начинает отвечать по старой редакции, вы сразу видите, кто загрузил новую версию, когда это произошло и прошел ли документ весь цикл обновления. Полезно хранить хотя бы три вещи: время, инициатора и тип изменения. Пометка metadata_only экономит лишний пересчет, а text_changed сразу отправляет документ в очередь на обновление.
Пример простой. В регламенте банка поменяли название департамента в карточке документа, но сам текст правил не трогали. В этом случае эмбеддинги пересчитывать не нужно. Если же в том же документе изменили лимит операции или срок ответа клиенту, текстовый хеш изменится, и старые чанки придется заменить.
Как обновлять только изменившиеся части
Полная переиндексация удобна только на старте. Потом она начинает мешать: занимает часы, тратит деньги на эмбеддинги и создает неприятный момент, когда в поиске живут сразу две версии одного текста. Гораздо спокойнее работает короткий цикл, который трогает только то, что реально изменилось.
Обычно процесс выглядит так. Система находит измененные документы по хешу, дате правки или номеру версии. Если файл не менялся, лучше вообще его не трогать. Для каждого измененного документа пайплайн заново режет текст на чанки, но только для новой версии. Затем строит эмбеддинги для новых фрагментов и сохраняет их как отдельный набор.
Старые чанки не стоит удалять сразу. Сначала новая версия должна доехать до индекса и пройти короткую проверку. Только после этого прошлую редакцию переводят в неактивное состояние, например через is_active = false или статус версии, который исключает ее из retrieval.
Порядок тут решает все. Если сначала скрыть старые чанки, а новые еще не записались, поиск на время ослепнет. Если сначала добавить новые, но забыть выключить старые, система начнет смешивать две редакции и давать странные ответы.
Надежнее делать обновление в два шага: сначала записать новую версию, потом атомарно переключить флаг активности. Так проще откатиться, если тест свежести покажет проблему.
Представьте, что в регламенте срок ответа изменили с 10 дней на 5. Пайплайн должен пересчитать чанки только для этого документа, создать новые эмбеддинги только для изменившихся кусков, отключить старые и проверить запрос вроде какой срок ответа по регламенту. Если поиск все еще иногда вытаскивает 10 дней, обновление нельзя считать законченным, даже если индекс технически собрался без ошибок.
Как выключать старые чанки без паузы в поиске
Старые чанки не исчезают сами. Если вы просто добавили новую версию документа в векторную базу, retriever часто будет видеть и старые, и новые фрагменты сразу. Модель получит смешанный контекст и ответит по устаревшему правилу.
Рабочий подход - сначала скрывать старые чанки логически, а физически удалять их позже. У каждого фрагмента полезно хранить doc_id, version_id, is_active, retired_at. Когда приходит новая версия, вы записываете новые чанки, проверяете их и только потом переводите прошлую редакцию в is_active = false.
Так вы избегаете паузы, когда старый контент уже убрали, а новый еще не попал в индекс. Для регламентов, тарифов и внутренних инструкций это особенно важно. Ошибка в одном абзаце легко ломает ответ целиком.
Фильтр важнее физического удаления
Поиск должен смотреть только на активную версию. Проще всего сделать это через фильтр is_active = true и, если нужно, через указатель на текущий version_id. Если такого фильтра нет, архивные чанки рано или поздно вернутся в выдачу, даже если их рейтинг немного ниже.
Старые чанки лучше не держать в общем retriever. Архив стоит вынести в отдельный namespace, отдельный индекс или хотя бы в другой класс поиска. Иначе кто-то забудет добавить фильтр в одном запросе, и устаревший текст снова попадет в контекст.
После обновления обязательно очистите кэш. Это частая ловушка: индекс уже свежий, а пользователь все равно получает старый ответ из response cache, кэша reranker или промежуточного слоя приложения. Лучше привязывать кэш хотя бы к doc_id и version_id, а при замене документа сбрасывать записи для этой сущности.
Физическое удаление разумнее запускать отдельно, например ночью или раз в неделю. Сразу стирать архив рискованно: иногда команде нужен откат, аудит или проверка, что новая версия не сломала поиск.
Когда нужен новый эмбеддинг
Эмбеддинги не нужно пересчитывать для всего корпуса при каждой правке. Если документ изменился точечно, пересчитывайте только те чанки, где поменялся смысл. Это экономит время и не ломает поиск там, где ничего не происходило.
Здесь помогает одно простое правило: держите границы чанков стабильными, где это возможно. Если сегодня абзац попал в один фрагмент, а завтра из-за мелкой вставки разъехались все границы ниже по документу, вам придется пересчитать слишком много данных. При стабильной нарезке меняются только нужные части, а соседние чанки остаются на месте.
Мелкая правка не всегда требует нового эмбеддинга. Если вы исправили опечатку, обновили номер приказа или слегка переписали формулировку без смены смысла, старый вектор часто можно оставить. Но если документ меняет ответ на вопрос пользователя, чанк уже другой по смыслу, и его нужно пересчитать.
Хорошее практическое правило выглядит так. Стиль, орфография и форматирование обычно не требуют нового эмбеддинга. Новый срок, лимит, тариф, факт или правило - требуют. Если вы вставили новый абзац внутрь раздела, пересчитывайте этот фрагмент, но не трогайте соседние без причины. Если переписана структура документа, изменились заголовки и сам смысл разделов, проще и чище пересобрать весь документ.
Команды часто перестраховываются и на всякий случай пересчитывают несколько соседних чанков вокруг места правки. Обычно это лишнее. Если соседний фрагмент сохранил тот же текст и тот же смысл, не трогайте его.
После обновления смотрите не только на точность, но и на recall. Новый чанк может получиться слишком узким, и поиск перестанет находить его по старым формулировкам запроса. Такое случается после агрессивной нарезки. Если пользователи перестали находить нужный ответ привычным вопросом, проблема часто не в модели, а в способе обновления фрагментов.
Пример с одним измененным регламентом
Возьмем регламент банка по хранению клиентских обращений. В новой редакции поменяли только раздел 4: срок хранения вырос с 30 до 90 дней. Остальные разделы, где описаны роли сотрудников, формат журнала и порядок согласования, остались без изменений.
Если обновлять знания по всему документу целиком, система часто пересчитает все чанки подряд. Это лишняя работа. В таком случае достаточно сравнить старую и новую версии по чанкам и обновить только тот кусок, где действительно поменялся текст.
Допустим, документ разбит на 6 чанков. После сравнения видно, что фрагменты 1, 2, 3, 5 и 6 не изменились. Поменялся только чанк 4, потому что в нем появился новый срок хранения. Значит, новый эмбеддинг нужен только для него. Старая версия этого чанка должна выйти из активной выдачи.
Тут важно не просто добавить новый фрагмент. Если оставить старую редакцию без статуса неактивности, поиск продолжит иногда поднимать оба варианта. Тогда модель увидит конфликт: в одном куске 30 дней, в другом 90. Ответ будет случайным, и это хуже, чем медленный индекс.
На практике помогает простая привязка: у каждого чанка есть document_id, section_id и version_id. В обычном поиске участвуют только записи с активной версией, а предыдущая закрыта по дате или флагу. Тогда старая редакция не участвует в retrieval, но остается в истории для аудита.
Проверка тоже простая. До обновления вопрос Сколько дней хранить клиентские обращения? возвращал старый чанк 4 и ответ 30 дней. После частичного обновления тот же вопрос должен вернуть новый чанк 4 и ответ 90 дней.
Заодно стоит проверить соседние вопросы. Например, Кто согласует удаление архива? должен по-прежнему доставать чанк 5 без изменений. Это хороший сигнал: вы убрали устаревший ответ, но не тронули стабильные части документа.
Ошибки, которые чаще всего ломают свежесть
Свежесть базы знаний чаще ломают не модели, а мелкие ошибки в пайплайне. Документ уже обновили, новые чанки уже посчитали, а поиск все равно тянет старую редакцию и собирает ответ из двух версий сразу.
Обычно причина одна из нескольких. Команда пересчитала эмбеддинги, но не обновила version_id, is_active или фильтр по актуальной редакции. Старые чанки выключают слишком поздно, и какое-то время поиск видит обе версии. При каждом импорте система создает новые doc_id и chunk_id, поэтому теряет связь между старым и новым документом. Иногда из-за одной правки запускают пересчет всего индекса, тратят часы и получают лишний риск ошибок. А еще часто забывают очистить кэш поиска, кэш ответов или старые снапшоты индекса.
На практике это выглядит очень неприятно. Вы обновили регламент отпуска, где срок согласования сократили с 5 дней до 2, векторная база уже хранит новый текст, но кэш ответа все еще держит вчерашний результат, а фильтр по версии не работает. Пользователь задает вопрос и получает старое число, хотя документ уже исправили.
Самая частая ошибка - ломать идентификаторы. Если doc_id меняется при каждом импорте, система не понимает, что это тот же документ в новой редакции. Старые чанки не снимаются с публикации и копятся рядом с новыми. Поэтому лучше держать постоянный doc_id для сущности документа и отдельный version_id для каждой редакции.
Полная переиндексация из-за одной правки тоже мешает свежести. Пока вы гоняете весь корпус, одна часть индекса уже новая, другая еще старая, а очередь обновлений только растет. Если изменился один раздел, обычно достаточно пересчитать только затронутые чанки и соседние куски лишь в том случае, если действительно сдвинулись границы разбиения.
С кэшем команды часто ошибаются дважды: либо не чистят его совсем, либо сбрасывают вообще все. Лучше делать точечный сброс по документу, версии или набору запросов. Иначе вы либо держите устаревшие ответы, либо теряете скорость без причины.
Проверка перед выкладкой
Перед релизом мало убедиться, что индекс собрался без ошибок. Намного важнее проверить, не остались ли в поиске старые куски текста. Именно здесь чаще всего и всплывает проблема: новая версия уже загружена, а ответ все еще тянет цитату из прошлой редакции.
Проверка может быть совсем короткой. У документа должен быть постоянный document_id, у версии - свой номер, дата или хеш, поисковый слой должен отдавать только актуальные чанки, а кэш должен учитывать версию документа или корректно инвалидироваться. Отдельно нужен небольшой тестовый набор вопросов, на которых старая цитата всплывает сразу: сроки, лимиты, ставки, названия полей, шаги процесса.
Если хотя бы один из этих пунктов не выполнен, релиз лучше задержать на час, чем потом весь день разбираться, почему продакшен отвечает по старой инструкции.
Представьте, что в регламенте по возвратам срок изменили с 14 до 30 дней. После инкрементального обновления задайте прямой вопрос: Сколько дней дается на возврат? Если ответ или цитата все еще содержат 14 дней, проблема почти всегда в одном из трех мест: старая версия не деактивировалась, фильтр по версии не сработал или кэш вернул прежний результат.
Полезно проверять и метаданные вручную. У найденных чанков должны совпадать document_id, текущий version_hash и флаг актуальности. Старые чанки можно хранить для аудита, но поиск не должен видеть их без явного запроса.
Если команда сравнивает несколько моделей, лучше держать retrieval-контур неизменным и менять только генерацию. В такой схеме удобно использовать единый OpenAI-совместимый шлюз вроде AI Router на airouter.kz: можно оставить те же SDK, код и промпты, а сравнение моделей получается чище. Заодно проще контролировать аудит-логи и правила кэша на одном слое.
Что делать после первого запуска
После первого запуска не трогайте весь корпус документов. Возьмите один источник, где изменения заметны сразу: регламенты, внутреннюю справку или каталог договоров. Так вы быстрее поймете, работает ли инкрементальная переиндексация, и не утонете в шуме.
Метрики стоит снимать с первого дня. Иначе через неделю вы увидите, что система вроде обновляется, но не поймете, где именно она ломается. На старте достаточно четырех показателей: сколько минут проходит от изменения документа до новой выдачи, как часто поиск поднимает старую версию чанка, сколько стоит одно частичное обновление и сколько документов система пропустила или обработала дважды.
Если у вас уже есть тестовый набор вопросов, прогоняйте его после каждого обновления. Одна и та же схема может хорошо работать на новых документах и все еще тянуть старые ответы из кэша, индекса или промежуточной таблицы версий.
Контроль свежести лучше встроить в обычный релизный цикл. Когда команда выкатывает новый парсер, меняет чанкинг или правит правила удаления, релиз должен включать короткий тест: изменили документ, дождались обновления, убедились, что старая версия больше не попадает в поиск.
Отдельно полезно сравнить полный и частичный пересчет в цифрах. Если каждый день меняется 2-3% базы, полная переиндексация часто просто сжигает бюджет. Смотрите не только на цену эмбеддингов, но и на длину очереди, время готовности индекса и количество лишних операций удаления.
Для команд в Казахстане есть еще один практичный вопрос: где лежат исходные документы, индекс, логи, маскирование PII и служебные таблицы версий. RAG-контур нередко выглядит локальным только на схеме, а часть данных при этом уходит за пределы страны. Это лучше проверить заранее, а не после запуска.
Хороший результат выглядит просто: свежий документ быстро попадает в поиск, старый чанк не всплывает в выдаче, стоимость обновления остается предсказуемой. Когда это стабильно работает на одном источнике, можно подключать следующий.
Часто задаваемые вопросы
Почему после обновления документа RAG все еще отвечает по старой версии?
Чаще всего в индексе живут обе редакции сразу. Поиск находит старые чанки почти так же уверенно, как новые, и модель собирает ответ из двух версий.
Храните документ и его редакцию отдельно. Сначала загрузите новую версию, проверьте ее, потом выключите старую через is_active = false или фильтр по текущему version_id.
Чем отличаются `source_id` и `version_id`?
source_id описывает сам документ и не меняется от новой загрузки, имени файла или папки. version_id описывает конкретную редакцию этого документа.
Такая схема помогает понять, какая версия активна сейчас, что ушло в архив и по какой редакции система отвечала раньше.
Какие поля стоит хранить у документа и чанка?
Обычно хватает source_id, version_id, text_hash, metadata_hash, updated_at и is_active. Для чанков добавьте привязку к документу и версии, чтобы быстро отключать старые фрагменты.
Если хотите проще разбирать сбои, храните еще инициатора изменения и тип правки, например metadata_only или text_changed.
Когда хватит частичного обновления, а когда надо пересобрать весь документ?
Если поменялся смысл ответа, пересчитывайте только затронутые чанки. Так вы не тратите лишние деньги на эмбеддинги и не трогаете стабильные части корпуса.
Весь документ имеет смысл пересобрать, когда уехала структура, сменились заголовки или границы чанков разъехались так сильно, что точечное обновление уже не дает чистый результат.
Как убрать старые чанки без остановки поиска?
Сначала запишите новую версию в индекс и убедитесь, что поиск ее видит. Потом одним переключением переведите прошлую редакцию в неактивный статус.
Так поиск не ослепнет на время обновления и не начнет смешивать старые и новые куски. Физическое удаление лучше делать позже, отдельно от рабочего трафика.
Нужно ли пересчитывать эмбеддинг после мелкой правки?
Не всегда. Если вы поправили опечатку, форматирование или номер приказа без смены смысла, старый вектор часто можно оставить.
Когда меняется срок, лимит, тариф, правило или любой факт, по которому пользователь задает вопрос, считайте новый эмбеддинг для этого чанка.
Что делать с кэшем после обновления документа?
Сбрасывайте кэш точечно, а не целиком. Привязывайте записи к doc_id и version_id, чтобы после замены документа убрать только затронутые ответы и результаты поиска.
Если оставить старый кэш, пользователь увидит вчерашний ответ даже при свежем индексе. Если чистить все подряд, вы потеряете скорость без пользы.
Как быстро проверить, что свежая версия реально попала в поиск?
Задайте прямой вопрос по измененному месту документа и проверьте не только ответ, но и найденный чанк. У него должны совпадать текущие document_id, version_id или version_hash, а старый фрагмент не должен попадать в retrieval.
Отдельно прогоните соседние вопросы, где текст не менялся. Если они работают как раньше, обновление прошло чисто.
Почему полная переиндексация часто делает хуже?
Она создает долгую очередь, тратит бюджет на весь корпус и повышает риск смешать старые и новые данные в одном индексе. При одной правке в одном регламенте такой подход дает больше шума, чем пользы.
Инкрементальное обновление спокойнее: вы меняете только то, что реально изменилось, и проще контролируете свежесть.
С чего начать, если инкрементального обновления у нас еще нет?
Начните с одного источника, где ошибка видна сразу, например с регламентов или внутренней справки. Введите постоянный source_id, отдельный version_id, фильтр по активной версии и тестовый набор вопросов на сроки, лимиты и правила.
Потом измеряйте время от правки документа до новой выдачи, долю старых чанков в поиске и стоимость частичного обновления. Когда схема стабильно работает на одном наборе, расширяйте ее дальше.