Стриминг ответов или полный ответ: что выбрать для LLM
Стриминг ответов или полный ответ: сравнение для чата, поиска и агентных сценариев по UX, цене, задержке и сложности интеграции.
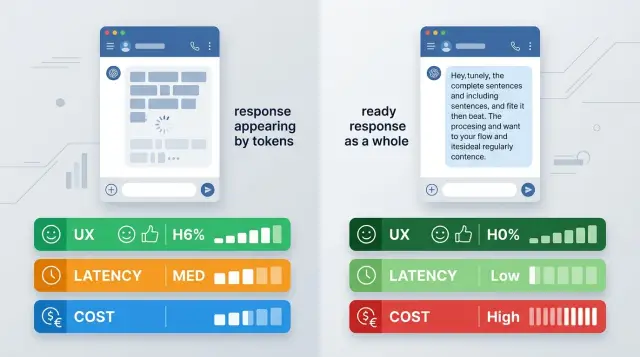
В чем выбор на самом деле
Спор о том, что лучше - стриминг или полный ответ, кажется чисто техническим. Для пользователя разница заметна сразу. Он либо видит первые слова почти мгновенно, либо ждет готовый ответ целиком и только потом понимает, что модель вообще начала работу.
Один и тот же запрос может ощущаться быстрым или медленным без всяких изменений в модели. Если генерация занимает 8 секунд, потоковая выдача покажет первый токен почти сразу и снимет часть раздражения. Полный ответ при тех же 8 секундах выглядит как пауза и тишина.
Но дело не только в ощущении скорости. Выбор режима меняет поведение всего продукта: как вы показываете прогресс, как обрабатываете обрывы соединения, что пишете в логи, как считаете задержку и что именно считаете завершенным ответом.
При стриминге текст может оборваться на середине фразы. Тогда интерфейсу нужно решить, что делать с этим куском: оставить, скрыть или запросить продолжение. При полном ответе таких развилок меньше, зато пользователь дольше смотрит на индикатор ожидания.
Для чата стриминг часто выглядит лучше, потому что человек видит движение и начинает читать раньше. Для поиска и RAG выбор не так очевиден. Если ответ короткий, со ссылками на источники и четкой структурой, готовый блок нередко удобнее. В агентных сценариях все сложнее: там есть вызовы инструментов, таймауты, промежуточные шаги и ошибки.
В OpenAI-совместимом API режим часто переключается одной настройкой. На практике вы меняете не одну опцию, а логику интерфейса и ожидания пользователя.
Как стриминг ощущается в чате
В чате люди сильнее всего замечают паузу до первого слова. Если интерфейс молчит 6 секунд, ответ кажется медленным, даже когда сам текст потом хороший. Если первые токены приходят через секунду, ждать уже легче.
Поэтому в чате стриминг обычно выигрывает именно по ощущению скорости. Пользователь видит, что система начала отвечать, и реже жмет "отправить" еще раз. Это кажется мелочью, но именно такие повторы создают дубли, лишние запросы и нервный UX.
Есть и еще один плюс: длинный ответ можно остановить в середине. Это удобно, когда модель ушла не туда, повторяется или говорит слишком общо. В обычном режиме человек ждет весь ответ целиком, а потом понимает, что время ушло зря.
Хороший пример - внутренний чат поддержки. Сотрудник задает вопрос про возврат платежа и уже через секунду видит начало ответа. Если первые строки явно не про тот случай, он останавливает генерацию и сразу уточняет запрос. Так диалог идет живее, а цена ошибки ниже.
Но потоковая выдача требует аккуратного интерфейса. Частичный текст часто выглядит неровно: обрывки фраз, незакрытые скобки, куски списка без конца. Если показать это грубо, чат кажется сломанным, хотя модель работает нормально.
Обычно хватает нескольких простых вещей: отдельного состояния "печатает", кнопки остановки для длинных ответов, плавного вывода без резких скачков и понятного финального статуса. Пользователь должен видеть, что ответ действительно завершен. Иначе он либо ждет лишнее, либо задает новый вопрос слишком рано.
Стриминг в чате почти всегда приятнее для человека. Он не делает ответ умнее, но делает ожидание короче и понятнее.
Когда полный ответ удобнее
Полный ответ выигрывает там, где важнее итог, а не ощущение скорости. Пользователь нажал кнопку, подождал пару секунд и получил готовый блок текста без мерцания и перестройки карточки.
Это особенно удобно в интерфейсах, где ответ потом читают, копируют или отправляют дальше. Карточка не меняется на глазах, строки не уезжают, и человеку не приходится перечитывать один и тот же абзац, пока модель дописывает конец.
Для команды такой режим тоже проще. Ответ легче сохранить в историю, привязать к событию в аналитике и положить в аудит-лог как один законченный объект. Проще сравнивать версии промпта, считать длину ответа и искать сбои.
После полной генерации удобнее запускать все, что идет следом: проверку по правилам, маскирование персональных данных, нормализацию JSON, добавление заголовков, очистку лишнего текста. При стриминге это тоже возможно, но код быстро становится сложнее, а вероятность ошибок растет.
Полный ответ особенно уместен, когда нужен строгий формат вывода, когда результат сохраняется в CRM, тикет или отчет, когда перед показом нужна дополнительная проверка и когда сбой лучше показать одним понятным статусом.
Последний случай часто недооценивают. Если запрос оборвался в середине стрима, пользователь видит полфразы и думает, что система сломалась странным образом. Если полный ответ не собрался, интерфейс честно показывает: "Не удалось подготовить ответ". Это не так эффектно, зато проще в поддержке.
Для поиска, справок и внутренних помощников такой режим часто выглядит аккуратнее. Он не дает яркого эффекта печати, но в рабочих сценариях это нередко лучший выбор.
Что меняется в поиске и RAG
В RAG узкое место часто не в генерации, а в поиске. Сначала нужно найти документы, отфильтровать шум, иногда еще и переранжировать фрагменты. Если включить стриминг слишком рано, пользователь увидит вежливое, но пустое начало вроде "Сейчас отвечу на ваш вопрос", а полезная часть появится только через пару секунд. По ощущению это хуже, чем честное ожидание.
Особенно это заметно в базе знаний, где ответ держится на цитатах. Человек спрашивает про срок возврата, система 2-3 секунды ищет нужный регламент, а интерфейс уже печатает общий текст без фактов. Потом модель меняет формулировку, вставляет другой документ, и доверие падает.
Часто лучше работает другой шаблон: короткий итог отдать целиком, а найденные фрагменты и ссылки на документы показать отдельным блоком сразу после него. Тогда ответ не "плывет" на глазах, а источники выглядят как опора, а не как догадка, которую модель дописала по ходу.
С цитатами и номерами документов лучше договориться заранее. Обычно выбирают один из двух путей: либо сначала полностью завершить поиск и зафиксировать набор источников, а потом запускать генерацию со ссылками; либо начать текст без цитат, а блок с источниками добавить только после финального ранжирования.
Смешивать оба режима рискованно. Если модель в первом абзаце ссылается на документ 12, а после переранжирования главным становится документ 7, интерфейс выглядит ненадежно.
В поиске полезно думать не только про задержку первого токена, но и про честность ответа. Если retrieval занимает долго, простой индикатор вроде "Ищу по базе знаний" или "Проверяю документы" часто лучше раннего стриминга. Пользователь понимает, что система занята делом, а не тянет время пустыми словами.
Правило здесь простое: когда поиск дольше генерации, не спешите печатать текст. Сначала найдите опору, потом отвечайте.
Что происходит в агентных сценариях
В агенте ответ редко рождается по прямой. Модель может сначала решить, что ей нужен поиск по базе знаний, потом обратиться к CRM, а после этого полностью поменять план. Поэтому стриминг и полный ответ дают здесь совсем другой эффект, чем в обычном чате.
Если показывать текст сразу, пользователь часто видит черновик, а не ответ, который уже проверен инструментами. Агент может начать с фразы "Похоже, платеж не прошел", а через секунду после обращения к биллингу выяснить, что платеж прошел, но чек не дошел. Для поддержки это плохой сценарий. Первую версию пользователь запоминает лучше, чем исправление.
Проблема не только в UX. Частичный вывод сложнее проверять по правилам и сложнее маскировать в нем PII. Если агент печатает токен за токеном, он может успеть показать номер договора, часть телефона или внутренний статус заявки до того, как фильтр сработает. В банке, телекоме и медицине такой риск обычно не нужен.
Поэтому на практике часто лучше стримить не сам ответ, а ход работы: "Ищу данные по заявке", "Проверяю статус в CRM", "Сверяю ответ с базой знаний", "Готовлю итог". Пользователь видит, что система не зависла, но не получает сырой текст, который агент потом перепишет.
Итоговый ответ безопаснее отдавать целиком после всех проверок. Тогда команда успевает прогнать маскирование PII, проверку правил, форматирование и логирование. Для компаний, которым важны аудит-логи и хранение данных внутри страны, такой порядок обычно проще поддерживать и объяснять службе безопасности.
Если вы работаете через OpenAI-совместимый API, смешанный режим часто оказывается самым спокойным вариантом: статусы шагов идут потоком, а финальный ответ приходит одной порцией.
Как режим влияет на стоимость
Если смотреть на выбор режима через деньги, спор обычно не про цену токена. У одной и той же модели тариф чаще всего одинаковый и для стриминга, и для полного ответа. Разница появляется вокруг запроса: сколько раз пользователь нажал "повторить", сколько ответов оборвали на середине, сколько событий система записала в логи.
Стриминг иногда дешевле в живом чате по простой причине. Пользователь видит первые слова почти сразу и реже отправляет тот же вопрос еще раз, решив, что система зависла. Если у вас большая очередь и заметная задержка первого токена, это быстро превращается в лишние дубли, а дубли - в лишние входные и выходные токены.
Но у стриминга есть и обратная сторона. Ранний вывод чаще провоцирует отмены и перезапуски. Человек видит не тот тон, не тот язык или просто теряет терпение на середине ответа, жмет stop и отправляет новый запрос. Для счета это неприятно: часть токенов уже сгенерирована, а новый запрос тоже нужно оплатить.
Полный ответ проще контролировать на стороне продукта. Его легче кэшировать, переиспользовать в похожих сценариях и отдавать повторно без нового вызова модели. Это особенно заметно в поиске, FAQ и внутренних помощниках, где похожие вопросы повторяются десятками.
Полезно считать стоимость не в одном числе, а хотя бы в четырех слоях: токены, отмены и ретраи, кэш-попадания и повторное использование, а также логирование и сетевые события на своей стороне.
Поэтому дешевый режим нельзя выбрать по прайсу модели. Его видно только в реальном трафике. Если в продукте много нетерпеливых пользователей, стриминг часто снижает число повторов. Если у вас много одинаковых запросов и строгий контроль расходов, полный ответ нередко выигрывает.
Где интеграция становится сложнее
Полный ответ обычно живет по простой схеме request-response: отправили запрос, дождались JSON, показали текст. Со стримингом проблемы начинаются в деталях. Даже если у вас уже есть интеграция OpenAI-совместимого API, клиенту мало просто прочитать поле content.
Первая проблема - обрывы. Пользователь уже увидел половину ответа, а соединение закрылось из-за сети, таймаута прокси или переключения мобильного интернета. В этот момент сервер, клиент и система логирования часто "видят" разные версии одного и того же диалога. Если команда заранее не решила, что считать завершенным ответом, быстро появляются дубли, пустые хвосты и жалобы в духе "бот оборвал мысль".
Клиентской части тоже нужно больше логики. Приложение должно собирать куски текста в буфер, обновлять интерфейс без мигания и отдельно ловить явный признак завершения потока. Если такого признака нет или клиент его пропустил, пользователь может увидеть аккуратный, но незаконченный ответ. На мобильных клиентах это случается чаще, чем кажется.
Команде заранее нужно решить, как хранить частично полученный текст при разрыве, когда считать ответ финальным, что именно писать в логи и как повторять запрос без двойной отправки пользователю.
Логи при стриминге почти всегда сложнее. Если хранить только итоговую версию, вы теряете картину сбоя. Если хранить все потоковые события, растет объем данных и сложнее разбирать инциденты. На практике часто сохраняют и поток, и финальную сборку с отдельным статусом завершения.
Есть и еще один слой - сеть между клиентом и моделью. Мобильные SDK, корпоративные прокси и балансировщики иногда буферизуют события, режут длинные соединения или меняют поведение SSE. Поэтому потоковая выдача нередко выглядит хорошо в локальной среде и странно ведет себя в проде.
Если вы сравниваете режимы через единый OpenAI-совместимый шлюз вроде AI Router, удобно проверять не только модель, но и весь путь ответа до экрана пользователя. Это полезнее, чем мерить задержку на одном бэкенде и гадать, где именно появляется сбой.
Как выбрать режим под свой сценарий
Режим лучше выбирать не по привычке команды, а по замерам. Смотрите как минимум на две цифры: время до первого токена и время до готового ответа. Для чата первая метрика часто важнее, потому что человек чувствует отклик почти сразу. Для поиска, отчета или длинного ответа важнее вторая, потому что пользователь ждет цельный результат.
Еще один хороший сигнал - поведение людей. Если они часто прерывают ответ на середине, быстро уточняют вопрос или жмут "сгенерировать заново", стриминг обычно оправдан. Если же они почти всегда дочитывают ответ до конца и им нужен аккуратный итог без мерцания текста, полный ответ может быть проще и спокойнее.
Не проверяйте режимы на одном сценарии и не переносите выводы на все остальные. В чате стриминг почти всегда ощущается живее. В поиске и RAG он полезен только если вы умеете показывать ранний черновик и не ломаете доверие к источникам. В агентных сценариях рисков еще больше: если модель вызывает инструменты, делает несколько шагов и может откатить план, ранний показ текста иногда только путает пользователя.
До запуска стоит ответить на несколько простых вопросов. Что увидит человек, если модель зависла после первых токенов? Можно ли показывать частичный ответ и как его помечать? Когда интерфейс должен молча дождаться финала? Кто и как повторит запрос после таймаута?
На пилоте полезно оставить переключатель режима. Это снижает риск, особенно если вы работаете через OpenAI-совместимый API и можете менять поведение без переделки всего клиента. В AI Router такой тест удобен еще и тем, что можно прогонять один и тот же сценарий через разные модели и провайдеров, не меняя SDK, код и промпты.
Если нужен короткий ориентир, он такой: чат чаще выигрывает от стриминга, поиск требует проверки на доверие и читаемость, а цепочки с инструментами лучше сначала запускать с полным ответом и добавлять стриминг только после замеров.
Пример: помощник для колл-центра банка
Оператору банка важна не только скорость модели, но и момент, когда текст уже можно безопасно показать на экране. Если помощник собирает длинную подсказку из истории звонка, правил банка и заметок по клиенту, стриминг дает приятный эффект: первые фразы появляются почти сразу, и оператор не сидит перед пустым окном 6-8 секунд.
Это особенно удобно, когда клиент задает длинный вопрос. Например, просит объяснить причину комиссии или порядок перевыпуска карты. Помощник может печатать ответ по мере генерации, а оператор уже понимает ход мысли модели и быстрее подхватывает разговор.
Но как только в ответе есть сумма, дата платежа, остаток лимита или статус блокировки, лучше подождать полный ответ. Один промежуточный фрагмент с неверной цифрой создает лишний риск. В банке это не мелочь, а повод для жалобы и повторного звонка.
В поиске по базе знаний ранняя печать тоже не всегда полезна. Сначала системе нужно найти верный фрагмент регламента или тарифа. Если показать полуответ раньше времени, оператор может прочитать красивую, но неточную формулировку. Проще сначала отдать найденную выдержку, а уже потом готовый текст для клиента.
На шагах с CRM удобнее показывать не сам ответ, а состояние процесса: "Открываю карточку клиента", "Проверяю активные продукты", "Создаю задачу на обратный звонок", "Записываю комментарий в историю".
После этого помощник выдает итог целиком: задача создана, срок указан, комментарий сохранен. В таком сценарии смешанный режим обычно работает лучше всего: длинные объяснения можно стримить, а проверяемые данные и результат действий показывать только после полной проверки.
Где команды ошибаются
Частая ошибка проста: команда включает стриминг везде, потому что он выглядит быстрее. Но красивый эффект печати еще не значит, что пользователь решил задачу раньше. Если ответ требует поиска, проверки данных или вызова инструмента, ранние токены могут дать только ложное ощущение скорости.
Это особенно заметно в сценариях, где модель сначала пишет общий текст, а потом получает результат от инструмента и переписывает ответ. Пользователь успевает прочитать одну версию, затем видит другую. Для чата это раздражает. Для операторских интерфейсов еще хуже: сотрудник уже начал действовать по черновику.
Поэтому поток полезно делить. Вступление, статус шага или короткое сообщение о ходе работы можно стримить. Факты, суммы, найденные документы и рекомендации после вызова инструмента лучше отдавать уже в финальном виде.
Еще одна частая проблема - отмена запроса. Пользователь закрыл вкладку, нажал "стоп" или приложение потеряло соединение, а сервер все равно продолжает генерацию. В итоге растут счета, забиваются логи и искажается картина нагрузки. Отмену нужно обрабатывать и на клиенте, и на бэкенде, а не просто скрывать индикатор печати.
Есть и более тихая ошибка: команда смотрит только на задержку первого токена. Этот показатель полезен, но сам по себе мало что говорит. Если модель начала писать через 400 мс, а полезный результат пришел через 9 секунд после двух вызовов инструмента, пользователь запомнит не первый токен, а общее ожидание.
Наконец, многие забывают сохранять итоговую версию ответа. При стриминге это случается часто: куски текста ушли на экран, а финальный вариант никто не зафиксировал. Для банков, телекома и других регулируемых сфер это плохая идея. Если нужен аудит, разбор жалоб или контроль качества, храните именно завершенный ответ, а не только поток токенов.
Быстрая проверка перед запуском
Такие режимы часто выбирают по ощущению. Для запуска этого мало. Нужны простые проверки, иначе команда видит красивое демо, а пользователи получают рваный текст, таймауты и странные логи.
Смотрите не на одну задержку, а на две. Первая - время до первого токена. Она показывает, как быстро интерфейс оживает. Вторая - время до полезного ответа. Для чата это момент, когда пользователь уже понял смысл. Для поиска - строка, после которой можно принять решение, а не просто читать вводные слова.
Перед релизом проверьте хотя бы пять вещей:
- Вы отдельно меряете задержку первого токена и полный путь до полезного ответа.
- Клиент умеет переживать обрыв соединения и повторное подключение без дублей в окне чата.
- Команда заранее решила, что делать с частичным текстом и что именно сохранять в логи.
- Для чувствительных данных включено маскирование, и PII не уходит в сырые логи.
- Ошибки видны сразу: таймаут модели, обрыв стрима, пустой финальный ответ, повтор токенов.
Частичный текст почти всегда ломает аналитику, если это не продумать заранее. Оператор банка может увидеть черновик ответа, который меняется в последней фразе. Если лог сохранил только середину стрима, разбор инцидента превращается в гадание.
Отдельно проверьте сценарий с чувствительными данными. Если трафик идет через шлюз вроде AI Router, маскирование PII и аудит-логи лучше настроить до первого боевого запроса, а не после разговора со службой безопасности.
Хороший тест очень простой: дайте десяти людям один и тот же сценарий, замерьте обе задержки и посмотрите, где они реально ждут, а где уже могут работать.
Что делать дальше
Хватит спорить на уровне ощущений. Возьмите один и тот же сценарий, одну модель и прогоните его в двух режимах: со стримингом и с полным ответом. Только так видно, что лучше именно для вашего продукта, а не для абстрактного демо.
Смотрите не только на задержку первого токена и общее время ответа. Режим часто ломается не там, где его обычно меряют. В стриминге пользователь чаще жмет "стоп", а интерфейс получает повторы или обрывки текста. В полном ответе проще скрыть промежуточный шум, но дольше ждать и сложнее показать, что система вообще работает.
Для быстрой проверки хватит четырех метрик: время до первого видимого символа, время до финального ответа, доля отмен генерации и число ошибок или странных повторов в UI и логах.
Если у вас уже есть OpenAI-совместимая интеграция, проверить оба режима обычно проще, чем кажется. Через AI Router и api.airouter.kz можно сменить base_url и прогнать те же SDK, код и промпты без переделки клиента. Это удобно, когда команда хочет сравнить стриминг и полный ответ на одинаковых условиях.
После теста зафиксируйте одно короткое правило, а не десять исключений. Для чата обычно побеждает стриминг, потому что он делает паузу короче на вид. Для поиска и RAG чаще удобнее полный ответ, если важны цельность и аккуратная работа с источниками. В агентных шагах лучше разделять режимы: наружу можно стримить статусы, а внутренние вызовы инструментов и проверки держать в полном ответе.
Если правило не помещается в одно предложение, значит сценарий еще не сужен.
Часто задаваемые вопросы
Что лучше для обычного чата: стриминг или полный ответ?
Для обычного чата чаще берут стриминг. Пользователь видит первые слова раньше, меньше нервничает и реже отправляет тот же вопрос снова.
Это особенно полезно для длинных ответов, которые можно остановить на середине, если модель ушла не туда.
Когда полный ответ удобнее стриминга?
Полный ответ удобнее там, где важен готовый и ровный результат. Текст не дергается на экране, его проще копировать, сохранять в историю и передавать дальше.
Такой режим часто берут для CRM, тикетов, отчетов и любых ответов со строгим форматом.
Что выбрать для поиска и RAG?
В поиске и RAG не спешите включать ранний вывод текста. Сначала система должна найти документы и выбрать опору для ответа, иначе пользователь увидит пустое вступление без фактов.
Если поиск идет дольше генерации, честный статус вроде «ищу по базе знаний» обычно лучше, чем сырой текст.
Можно ли смешивать оба режима в одном продукте?
Да, смешанный режим часто работает лучше всего. Показывайте поток статусов шага, а финальный ответ отдавайте целиком после проверок.
Такой подход особенно полезен в агентных сценариях, где модель зовет инструменты, меняет план и может исправить ранний черновик.
Стриминг всегда дешевле?
Не обязательно. Цена токенов у одной модели обычно не меняется, но поведение людей меняет итоговый счет.
Стриминг может снизить число повторных запросов, если люди часто жмут отправку еще раз. Полный ответ может выйти дешевле, если у вас много одинаковых вопросов и хороший кэш.
Что делать, если стрим оборвался на середине ответа?
Сразу решите, что делать с частичным текстом. Либо честно помечайте его как незавершенный, либо скрывайте и предлагайте повтор.
На стороне сервера и клиента фиксируйте один финальный статус, чтобы не плодить дубли в истории и логах.
Как показывать прогресс в агентном сценарии?
В агенте лучше стримить ход работы, а не сам черновик ответа. Пользователь должен видеть, что система ищет данные, проверяет CRM или сверяет базу знаний.
Итоговый текст безопаснее показать после всех шагов. Так вы не запутаете человека ранней версией, которую агент потом перепишет.
Какой режим безопаснее для чувствительных данных?
Для чувствительных данных чаще выбирают полный финальный ответ. Так команда успевает замаскировать PII, прогнать проверки и сохранить нормальный аудит-лог.
В банке, телекоме и медицине сырой стрим несет лишний риск: модель может показать номер, дату или статус раньше фильтра.
Какие метрики смотреть при выборе режима?
Смотрите минимум на две задержки: время до первого токена и время до полезного ответа. Первая метрика важна для чата, вторая — для поиска, отчетов и сценариев с инструментами.
Еще полезно смотреть на отмены, повторы запросов, ошибки в UI и долю незавершенных ответов.
Можно быстро проверить оба режима без переписывания клиента?
Если у вас уже есть OpenAI-совместимая интеграция, тест обычно простой. Меняете base_url, гоняете тот же сценарий в двух режимах и сравниваете задержку, отмены и поведение интерфейса.
Через AI Router удобно прогонять одинаковые SDK, код и промпты без переделки клиента. Это помогает сравнить режимы на равных условиях.