Локальный хостинг моделей: что держать в стране, а что нет
Локальный хостинг моделей помогает отделить рискованные сценарии от обычных: разберем, что держать в Казахстане, а что оставить на внешнем API.
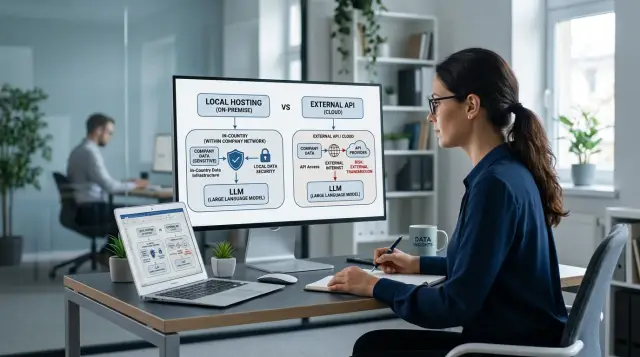
В чем здесь проблема
Проблема обычно начинается не с вопроса "какую модель выбрать". Сначала нужно понять, какие данные уходят в запрос, кто их увидит, где они сохранятся и что будет, если модель ошибется. Для одной задачи это просто лишняя правка. Для другой - жалоба клиента, штраф или внутреннее расследование.
В промпт почти всегда попадает больше, чем кажется. Команда видит короткий текст пользователя и думает, что риска нет. На деле вместе с ним часто уходят история диалога, фрагменты из CRM, результаты поиска по внутренним документам, служебные поля, имена файлов, номера договоров и куски переписки сотрудников.
Особенно часто это случается в чатах поддержки и сценариях, где система сама подтягивает контекст, чтобы ответ был точнее. Это удобно, но именно здесь в модель незаметно попадают чувствительные данные в LLM-сценариях: ИИН, адреса, диагнозы, суммы платежей, данные по счетам, внутренние комментарии оператора.
Цена ошибки тоже бывает разной. Если модель плохо перепишет маркетинговый текст, команда потеряет время. Если она неверно суммирует историю клиента банка или покажет оператору лишние данные, последствия уже другие: риск для человека, риск для компании и проблемы с хранением данных в Казахстане.
Поэтому единый подход почти никогда не работает. Один и тот же бизнес может спокойно отправлять наружу обезличенные тексты для черновиков, но держать внутри страны обработку обращений, медицинских выписок или банковских документов. Иногда даже в одном процессе часть запроса идет во внешний контур, а часть остается локально.
Перед выбором маршрута достаточно ответить на четыре вопроса:
- Какие поля реально уходят в модель вместе с промптом.
- Может ли ответ повлиять на клиента или на решение сотрудника.
- Нужно ли хранить данные внутри страны.
- Можно ли убрать или замаскировать персональные данные до отправки.
Когда команда начинает с этих вопросов, выбор между локальным контуром и внешним API становится проще. Тогда обсуждают не "лучшую модель" вообще, а цену ошибки в каждом конкретном сценарии.
Что стоит держать внутри страны
Локальный контур нужен там, где в запросе есть персональные данные, детали конкретного случая или внутренняя база знаний. В таких задачах риск связан не только с утечкой. Не меньше проблем потом создают аудит, правила хранения данных и разбор спорных ответов.
Локальный хостинг моделей особенно уместен для запросов с ФИО, ИИН, номерами счетов, адресами и любыми связками, по которым можно узнать человека. Сюда же относятся переписки поддержки, где клиент описывает жалобу, долг, диагноз, ошибочный платеж или блокировку доступа. Даже если оператору нужен только короткий черновик ответа, в промпт часто попадает слишком много лишнего.
Где локальный контур нужен почти всегда
Хорошее правило простое: если сотрудник не может без сомнений переслать этот текст во внешний сервис вручную, модели тоже не стоит отправлять его наружу.
Обычно внутри страны оставляют разбор обращений с личными данными и историей клиента, поиск по внутренним регламентам и служебным инструкциям, черновики ответов для операторов, юристов и врачей, а также классификацию обращений, по которой потом нужен аудит решения.
Поиск по внутренним документам почти всегда лучше держать локально. Дело не только в секретности. Внутренние регламенты быстро меняются, а ошибка в ответе потом обходится дорого. Если модель ищет по локальному индексу и работает рядом с системой аудита, команде проще понять, на какой документ она опиралась и почему ответила именно так.
Черновики для операторов, юристов и врачей тоже разумно генерировать внутри страны. Это еще не финальное решение, но такие ответы влияют на деньги, жалобы и здоровье. Здесь важны маскирование PII, журнал запросов и понятная цепочка действий сотрудника.
Классификацию обращений тоже лучше не выносить наружу, если по ее результату запускается процесс с последствиями: эскалация, отказ, ручная проверка, смена приоритета. Когда спор доходит до внутреннего контроля или регулятора, нужен понятный след: какой текст пришел, какая модель сработала и какой класс она выдала.
Для таких сценариев часто хватает моделей с открытыми весами, если задача узкая и хорошо описана. Им не всегда нужно максимальное качество. Обычно важнее контроль, повторяемость и хранение данных в Казахстане.
Что можно оставить на внешнем API
Внешний API подходит для задач, где в запросе нет персональных данных, коммерческой тайны и внутренних документов. Если утечка промпта не создаст проблем для клиента, юристов и службы безопасности, локальный контур здесь часто не нужен.
Типичный пример - маркетинговые тексты без данных клиента. Описание акции, варианты слоганов, письма для широкой рассылки, посты для соцсетей и черновики лендинга можно генерировать снаружи, если в промпт не попадают CRM-выгрузки, сегменты с именами или внутренние планы кампаний.
То же относится к переводу общих материалов. Публичные FAQ, описания продукта, шаблонные ответы поддержки и инструкции для сотрудников удобно переводить через внешний API для ИИ, если текст не содержит номера договоров, диагнозы, финансовые детали или служебные пометки.
С кодом правило тоже довольно простое. Наружу можно отправлять черновики без закрытых фрагментов: SQL-запросы, тесты, регулярные выражения, примеры структуры сервиса. А вот куски с реальными ключами, внутренними адресами, схемой доступа и логикой антифрода лучше не выносить.
У внешнего API есть еще одно практическое преимущество: новые модели там появляются быстрее. Поэтому первые эксперименты, сравнение нескольких моделей и проверку качества на учебных примерах часто удобнее делать снаружи. Не всегда есть смысл поднимать каждую модель у себя ради короткого теста.
Для прототипов это тоже нормальный путь. Если вы собираете демо, проверяете идею или строите тестовый сценарий на синтетических данных, внешний контур обычно дешевле и быстрее. Нет смысла разворачивать локальный хостинг моделей ради недельного пилота без чувствительной нагрузки.
Граница проходит не по названию задачи, а по содержимому промпта. Один и тот же перевод можно безопасно отправить наружу, если это публичная инструкция, и нельзя, если в тексте есть данные пациента или условия крупного контракта.
Если команда работает через единый шлюз вроде AI Router, разделять такие сценарии проще. Безопасные черновые задачи можно направлять во внешний API, а клиентские и внутренние данные оставлять в локальном контуре. Это дает понятный баланс между скоростью и контролем.
Как принять решение по каждому сценарию
Начните не с модели, а с маршрута запроса. Возьмите один реальный сценарий и разложите его по шагам: что вводит пользователь, какие поля подтягивает система, что уходит в промпт, где сохраняется ответ, кто потом видит логи. Команды часто смотрят только на текст запроса и забывают про вложения, кеш, трассировку и историю в helpdesk.
Потом отметьте данные по слоям. Отдельно пометьте персональные данные, внутренние комментарии сотрудников, номера договоров, суммы, диагнозы, скоринговые признаки и любые служебные поля, по которым можно восстановить контекст. Если задача работает после маскирования имен, ИИН, телефонов и номеров счетов, ее не всегда нужно держать внутри страны. Если же ответ теряет смысл без исходных полей, локальный контур нужен не для галочки, а по делу.
Если службе ИБ, аудиту или регулятору нужен след по каждому вызову, закладывайте это сразу. Нужен не общий лог за день, а запись на уровне запроса: кто отправил данные, к какой модели, с какой версией промпта, что было замаскировано и какой ответ вернулся. Без этого спорные случаи потом разбирают часами.
Как выбрать маршрут
На практике почти все сценарии сводятся к трем вариантам:
- Локально, если запрос содержит исходные персональные или служебные данные, а журнал действий обязателен.
- С маскированием, если модели нужен смысл текста, но не сами идентификаторы и реквизиты.
- Наружу, если данные уже обезличены или задача вообще не связана с клиентскими записями.
Цена ошибки часто помогает быстрее, чем таблица с GPU. Если утечка одного запроса грозит проверкой, штрафом, ручным разбором инцидента и потерей доверия, своя инфраструктура может оказаться дешевле. Если максимум риска - неидеальная формулировка в черновике письма, внешний API обычно разумнее.
На практике один и тот же продукт почти всегда делят. Классификация обращений, черновики ответов и перевод нередко уходят наружу после маскирования. Разбор внутренних документов, поиск по клиентскому делу и ответы, где модель видит полную запись, остаются внутри страны. Если у команды есть единый OpenAI-совместимый шлюз, правила маршрутизации проще закрепить в одном месте, а не разносить по коду каждого сервиса.
Пример: банк делит задачи между двумя контурами
В розничном банке поток обращений быстро смешивает простые и рискованные задачи. Один клиент просит объяснить комиссию, другой спорит со списанием, третий пишет о блокировке счета. В части таких диалогов есть ИИН, остатки, история операций и внутренние пометки банка. Эти запросы банк оставляет во внутреннем контуре и прогоняет через локально размещенную модель с открытыми весами.
Во внутреннем контуре модель делает понятную работу: классифицирует обращение, вытягивает факты из текста, готовит черновик ответа оператору и краткую сводку по кейсу. Полные данные не уходят за пределы страны, а журнал запросов банк хранит у себя. Обычно там остаются маскированный ввод, версия промпта, ответ модели, время обработки и действие сотрудника. Если клиент подаст жалобу, служба контроля быстро поднимет всю цепочку решений.
Внешний API банк использует для задач с низким риском. Например, система сначала убирает имя клиента, ИИН, номер счета, суммы и даты операций, а потом отправляет наружу обезличенный шаблон письма. В ответ банк получает более ровный стиль, короткую выжимку или несколько вариантов формулировки. Это удобно для массовых уведомлений, писем по типовым ситуациям и переписывания текста в более понятный язык.
Как банк сравнивает два контура
Чтобы не спорить на уровне впечатлений, команда берет один и тот же набор обращений и прогоняет его через обе схемы. Обычно смотрят на точность фактов, долю опасных ошибок и выдуманных деталей, среднюю задержку и задержку в пике, цену на тысячу запросов и то, сколько правок оператор вносит после модели.
После такого теста картина быстро проясняется. Локальный контур часто выигрывает там, где важны контроль, аудит и хранение данных в Казахстане. Внешний API нередко дает более сильный текст на обезличенных задачах и может обходиться дешевле для редких сложных запросов.
Банку не нужно переносить внутрь страны все подряд. Разумнее разделить потоки: чувствительные данные в LLM оставлять внутри, а безопасные текстовые операции отдавать наружу. Тогда локальный хостинг моделей перестает быть дорогой идеей "на всякий случай" и становится обычной частью архитектуры.
Где локальный контур оправдан, а где нет
Локальный контур окупается не сам по себе, а за счет профиля нагрузки. Если команда гоняет один и тот же тип запросов весь день, расходы и задержку проще считать заранее. Это особенно заметно там, где модель делает короткую и повторяемую работу: классифицирует обращения, вытаскивает поля из документов, проверяет текст по правилам, возвращает JSON по строгой схеме.
Когда локальный контур дает смысл
Локальный хостинг моделей обычно оправдан, если поток запросов идет постоянно, ответы короткие и укладываются в строгий формат, качество можно проверять по понятным метрикам, а команде важно хранение данных в Казахстане.
Для таких задач модели с открытыми весами часто закрывают потребность без лишних затрат. Если модель должна найти ИИН в документе, убрать персональные данные или разложить письмо по категориям, не нужен самый сильный внешний API. Нужны предсказуемость, низкая задержка и понятная цена на объем.
Локальный контур хорошо работает и там, где запросы похожи друг на друга. Ошибки заметнее, промпты проще настраивать, а GPU-нагрузку легче планировать по часам. Иногда этого уже достаточно, и дообучение не требуется. Команды часто думают о нем слишком рано, хотя сначала стоит проверить базовую модель на хорошем наборе примеров.
Когда лучше не тащить все внутрь страны
Редкие, сложные и длинные задачи часто дешевле оставить снаружи. Если аналитик раз в день отправляет большой пакет документов, просит длинное сравнение или ждет аккуратное рассуждение по десяткам страниц, свои GPU быстро упираются в память и время ответа. Большой контекст дорого обходится даже на собственной инфраструктуре.
Здесь помогает простой тест. Если задача случается редко, а качество ответа важнее, чем полный контроль над контуром, внешний API часто дает лучший результат за меньшие деньги. Вы платите за фактическое использование, а не держите запас вычислений ради редкого пика.
Хорошая граница обычно такая: типовые операции и чувствительные данные держать локально, а редкую сложную аналитику отправлять наружу. Это полезнее, чем пытаться перенести внутрь страны вообще все.
Ошибки при переносе моделей внутрь страны
Локальный хостинг моделей часто начинают слишком широко. Команда переносит сразу все: чат поддержки, поиск по базе знаний, внутренние документы, черновики писем, аналитику звонков. На старте это выглядит аккуратно, но потом расходы растут, а выгода оказывается меньше ожиданий. Гораздо разумнее сначала разделить сценарии по риску и оставить внутри страны только те, где есть персональные данные, финансовая история, медицинские данные или требования по хранению данных в Казахстане.
Еще одна частая ошибка - смотреть только на цену токена и забывать про ежедневную работу вокруг модели. Даже если сами модели с открытыми весами бесплатны по лицензии, их нужно запускать, обновлять, мониторить и страховать от сбоев. Нужны GPU, запас по нагрузке, человек на дежурстве, понятные логи и маршрут на случай отказа. Иначе дешевый токен быстро превращается в дорогой сервис.
Ошибочно считать и то, что внутренний контур автоматически безопасен. Это не так. Если команда отправляет в модель номера счетов, ИИН, телефоны, диагнозы или тексты договоров без маскирования, риск никуда не исчезает. Данные могут попасть в логи, отладочные дампы, тестовые наборы и чужие чаты. Даже внутри страны лучше скрывать PII до отправки и возвращать исходные поля только там, где это действительно нужно бизнес-процессу.
Проблемы начинаются и там, где никто не задал простые правила доступа. Кто может работать с моделью? Какие команды видят какие данные? Какие ответы нужно маркировать как AI-контент? Как долго хранятся логи? Если на эти вопросы нет явных ответов, внутренний контур быстро превращается в серую зону. Для таких систем нужны роли, отдельные ключи, аудит-логи и лимиты на уровне команды или сервиса.
Многие тестируют локальную модель на удобных примерах и получают ложное чувство контроля. На демо все выглядит хорошо: короткий запрос, чистый текст, одна задача. В реальной очереди все иначе. Приходят сканы с плохим распознаванием, длинные переписки, смесь русского, казахского и английского, ночные пики нагрузки и нестандартные промпты.
Хороший тест всегда должен быть ближе к боевой нагрузке, чем к презентации. Если банк или ритейлер берет анонимизированную реальную выборку за неделю, он быстро видит, где локальный контур оправдан, а где внешний API пока надежнее и дешевле.
Быстрая проверка перед запуском
Перед первым реальным трафиком полезно пройтись по пяти точкам. Локальный контур сам по себе не решает вопрос безопасности, если команда не описала маршрут данных, не измерила цифры и не договорилась, кто отвечает за результат.
Сбои редко начинаются в модели. Обычно проблема появляется раньше: в лишнем поле с ИИН, в логах, которые ушли не туда, или в промпте, который меняли три человека без общего владельца.
- Сначала разделите сценарии по уровню риска. Поиск по базе знаний, черновики писем и внутренняя классификация текстов часто безопаснее. Диалоги с клиентами, платежные данные, медицинские данные, договоры и жалобы лучше сразу пометить как сценарии для локального контура.
- Затем зафиксируйте, какие поля вы скрываете до запроса в модель. Имя, телефон, ИИН, номер счета, адрес, номер договора и свободный текст с личными деталями нельзя оставлять на потом.
- После этого решите, где хранятся промпты, ответы, ошибки и аудит-логи. Если есть требование хранить данные в Казахстане, проверьте не только основную систему, но и мониторинг, повторы запросов, отладочные таблицы и экспорт в аналитику.
- Дальше сравните локальную модель и внешний API на одном наборе запросов. Смотрите на задержку, цену одного ответа и долю ошибок. Для первого теста обычно хватает 100-200 реальных запросов без ручной подгонки.
- И наконец, назначьте владельца. Один человек или маленькая группа должны отвечать за версию модели, промпты, правила fallback и разбор инцидентов. Если владельца нет, правки быстро расползутся по чатам.
Простой тест хорошо отрезвляет. Представьте, что завтра банк запускает ассистента для операторов колл-центра. Если команда не может за 10 минут показать список риск-сценариев, правила маскирования, место хранения логов, цифры по задержке и имя владельца, запускать систему на живых клиентах еще рано.
Что делать дальше
Не переносите сразу все запросы во внутренний контур. Начните с одного процесса, где риск данных понятен, а результат легко проверить. Подойдет, например, разбор обращений клиентов, внутренняя суммаризация документов или поиск по базе знаний сотрудников.
Такой старт быстро показывает, нужен ли вам локальный хостинг моделей именно в вашем случае. Если команда за пару недель видит меньше ручной работы, приемлемую задержку и понятные расходы, зону применения можно расширять. Если нет, вы потеряете немного времени и денег.
Сразу разделите маршруты. Запросы с персональными данными, банковской тайной, медицинскими сведениями или внутренними документами отправляйте в локальный контур. Более простые задачи, где риск ниже, можно оставить на внешнем API: черновики текстов, перевод общих материалов, классификацию открытых отзывов, помощь разработчикам с несекретным кодом.
Без общих метрик это быстро превращается в спор мнений. Считайте одно и то же для обоих контуров: качество ответа, цену на 1000 запросов, среднюю задержку, долю ошибок и объем ручных правок после модели. Полезно смотреть и на то, сколько запросов пришлось отправить повторно и как часто пользователи принимают ответ без доработки.
Хороший пилот обычно выглядит просто: выбрать один процесс с понятным владельцем, подготовить небольшой набор реальных запросов под внутренним контролем, прогнать их через локальную модель и внешний API по одним правилам, сравнить результат по качеству, цене и задержке, а затем зафиксировать, какие данные можно выпускать наружу, а какие нет.
Если команде неудобно поддерживать отдельные интеграции для внешних провайдеров и локально размещенных моделей, можно сравнить это с подходом через единый API. Например, AI Router дает один OpenAI-совместимый эндпоинт для маршрутизации запросов к внешним моделям и для команд, которым нужен локальный контур на собственной инфраструктуре. Это упрощает пилот: кода меняется меньше, а разницу между маршрутами видно быстрее. Если для вас важны хранение данных внутри страны, маскирование PII, аудит-логи и лимиты на уровне ключа, такой вариант особенно удобен.
Смысл всего шага простой: не спорить о стратегии в общих словах, а собрать свои цифры на своих данных. После короткого пилота обычно уже ясно, что стоит держать внутри страны постоянно, а что дешевле и проще оставить снаружи.