Мультипровайдерный доступ к LLM без переписывания SDK
Мультипровайдерный доступ к LLM: как собрать единый эндпоинт, общую аутентификацию и резервирование без смены SDK и лишней логики в коде.
Где ломается работа с несколькими провайдерами
Проблемы начинаются не в момент выбора модели, а в момент интеграции. Пока команда работает с одним провайдером, жесткая привязка к одному base_url кажется мелочью. Потом появляется второй провайдер, резервный маршрут или локально размещенная модель, и сразу видно, что адреса, заголовки, имена моделей и правила обработки ошибок разбросаны по разным сервисам.
Чаще всего команда слишком рано привязывает код к одному API. SDK инициализируют прямо в бизнес-логике, base_url зашивают в конфиг каждого сервиса, а формат ответа принимают как общий стандарт. В итоге даже простая замена точки входа тянет за собой правки в нескольких репозиториях, новые переменные окружения и долгую проверку. Для продакшена это плохой обмен.
Следующая проблема - аутентификация. У каждого провайдера свои ключи, лимиты и правила. Один ключ быстро съедает batch-задача, и внезапно падает чат поддержки. Один провайдер считает лимит по токенам, другой по запросам в минуту, третий режет трафик по IP. Если нет общего слоя доступа, никто не видит картину целиком. Логи лежат в разных местах, а причина сбоя выглядит случайной.
Потом приходят сетевые ошибки. Один провайдер держит соединение слишком долго. Другой быстро отвечает 429. Третий отдает 5xx пачками в течение пары минут. Если приложение по-разному обрабатывает таймауты, повторные попытки и переход на запасной маршрут, начинаются странные эффекты: запрос зависает, пользователь жмет кнопку еще раз, система отправляет дубль, а стоимость растет без пользы.
На этом фоне команды почти всегда пишут одну и ту же обвязку заново. Кто-то добавляет retry, кто-то маскирует PII, кто-то считает стоимость, кто-то ведет аудит-логи. Логика везде похожа, но детали расходятся. Через пару месяцев мультипровайдерный доступ к LLM превращается в набор несовместимых правил вместо управляемой архитектуры.
Хороший пример - чат поддержки с двумя провайдерами. Основной маршрут работает быстро, запасной нужен только при 429 и 5xx. На бумаге все просто. На деле один сервис знает только один эндпоинт, второй использует другой формат ключей, третий вообще не умеет переключаться без нового релиза. В аварии это всплывает сразу: запросы висят, лимиты выбиты, а каждая команда чинит свой кусок отдельно.
Что должен делать единый шлюз
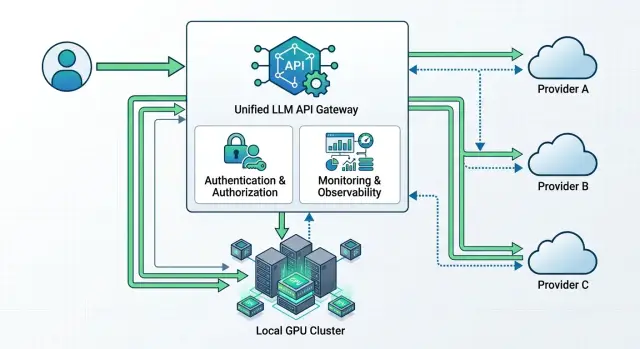
Единый шлюз убирает хаос, который появляется, когда один сервис ходит в OpenAI, второй в Anthropic, а третий в локальную модель через свой клиент. Внутренние приложения отправляют запросы в один эндпоинт LLM и получают один формат ответа. Код сверху становится заметно проще.
Обычно такой шлюз делают OpenAI-совместимым. Тогда команда меняет только base_url и токен, а SDK, промпты и большая часть интеграции остаются прежними. Это самый короткий путь к мультипровайдерной схеме: меньше правок, меньше неожиданных ошибок после релиза.
Нормальный шлюз делает несколько вещей сразу. Он принимает единый формат запросов для чата, стриминга и tools, приводит различия провайдеров к одной схеме, выбирает маршрут по набору правил, собирает логи по задержке, сбоям и расходу, а еще применяет таймауты, повторные попытки и ограничения по частоте. Если нужно, в этом же месте живут маскирование PII и аудит.
Центр такой схемы - таблица маршрутов. В ней обычно хранят алиас модели, список провайдеров, порядок выбора, запасной маршрут и ограничения по бюджету. Например, маршрут support-chat сначала идет к более сильной модели, а при росте задержки или ошибке 429 быстро уходит на второй вариант без изменений в приложении.
Общий формат запросов решает много мелких, но неприятных проблем. У одного провайдера поле называется так, у другого иначе, у третьего по-своему работает streaming или tools. Шлюз сглаживает эти различия, чтобы команде не приходилось помнить отдельные правила каждого API.
Без логов такой слой почти бесполезен. Нужны данные по задержке, доле ошибок, токенам и стоимости по каждому маршруту. Тогда команда быстро видит, что тормозит не весь сервис, а конкретный провайдер или отдельная модель.
Таймауты и повторные попытки тоже лучше задавать по сценариям. Чат поддержки обычно ждет 2-4 секунды, пакетная обработка может ждать дольше. Повторять стоит сетевые ошибки, 429 и часть 5xx. Запросы с tools, которые вызывают внешние действия, лучше не дублировать без защиты от повторного запуска.
На практике такой слой часто выносят в отдельный API-шлюз. По этой схеме работает и AI Router: приложение видит один OpenAI-совместимый эндпоинт, а маршрутизация, учет расхода и ограничения собраны в одном месте.
Как собрать схему без переписывания SDK
Мультипровайдерная схема работает спокойно только тогда, когда приложение видит один и тот же контракт запроса. Если сегодня один сервис шлет OpenAI Chat Completions, а второй говорит с другим провайдером в своем формате, резервирование быстро превращается в набор костылей.
Начните с одного внутреннего контракта. На практике удобнее всего взять OpenAI-совместимый формат: одинаковые поля запроса, одинаковая схема ответа, одинаковая обработка ошибок. Тогда команда не переписывает клиент под каждого нового провайдера и не чинит парсер после каждой замены модели.
Дальше порядок простой:
- Выберите один эндпоинт и один формат запросов для всех сервисов. Приложение должно знать только этот интерфейс.
- Уберите
base_urlи API-токен из кода в конфиг или переменные окружения. Тогда вы сможете менять маршрут без релиза. - Поставьте перед провайдерами слой маршрутизации. Он решает, куда отправить запрос: по модели, цене, задержке, требованиям к хранению данных или доступности.
- Задайте короткие таймауты и понятные retry-правила. Один зависший провайдер не должен держать пользовательский запрос 30 секунд.
- Прогоните тест, в котором SDK, промпты и разбор ответа остаются прежними. Если пришлось менять код клиента, схема еще не готова.
Хорошее правило звучит так: приложение не выбирает провайдера напрямую. Это делает шлюз. Само приложение отправляет один и тот же запрос и получает один и тот же тип ответа. Если основной провайдер не ответил за 2-3 секунды, шлюз переводит трафик на запасной маршрут по заранее заданным правилам.
Именно поэтому base_url лучше хранить в одном месте. Для команды это мелочь, но она экономит часы. Если компания уже использует OpenAI SDK, ей часто достаточно сменить адрес API и токен на OpenAI-совместимый шлюз вроде AI Router с эндпоинтом api.airouter.kz, а вызовы и промпты оставить как есть.
Проверьте это на маленьком сценарии: один чат-запрос, один SDK и два провайдера за шлюзом. Если ответы приходят в одной схеме, таймауты срабатывают предсказуемо, а приложение не замечает смены маршрута, основа собрана правильно.
Как устроить общую аутентификацию
При мультипровайдерной работе приложение не должно знать секреты каждого провайдера. Ему нужен один внутренний ключ или service token, с которым оно ходит только в ваш шлюз. Дальше шлюз сам решает, какой внешний ключ взять для OpenAI, Anthropic, Google или другой модели.
Это сильно упрощает поддержку. Разработчики держат в коде одну схему авторизации, а не набор разных токенов, заголовков и правил обновления. Если завтра вы меняете провайдера или добавляете резервный маршрут, приложение не трогаете.
Внешние секреты храните отдельно от кода. Подойдет secret manager, KMS или хотя бы защищенное хранилище переменных среды с доступом по ролям. Секреты не должны жить в репозитории, в CI-логах и в конфиге, который без разбора уезжает на все серверы.
Разделяйте доступ по средам и по командам. У production, staging и dev должны быть разные внутренние ключи и разные лимиты. Если команда аналитики тестирует промпты, ей не нужен тот же доступ, что и сервису, который отвечает клиентам в проде.
Практичная схема выглядит так: сервис получает один внутренний API-ключ, шлюз по нему определяет отправителя запроса, подставляет внешний секрет нужного провайдера, а лимиты и права задает на уровне внутреннего ключа. При этом сами провайдерские ключи живут вне приложения.
Ротация секретов тоже должна проходить без правок в коде. Вы меняете секрет в хранилище, шлюз подхватывает новую версию, а сервис продолжает слать запросы в тот же единый эндпоинт. Это особенно удобно, когда провайдер просит срочно перевыпустить ключ после инцидента или когда часть трафика нужно перевести на другой аккаунт.
Не экономьте на аудит-логах. Лог должен отвечать на четыре вопроса: кто отправил запрос, куда он ушел, какой внутренний ключ использовался и чем все закончилось. В AI Router этот подход уже поддерживается на уровне ключа: есть аудит-логи и rate limits, поэтому банку, SaaS-команде или внутренней платформе не приходится собирать картину из нескольких кабинетов разных вендоров.
Как настроить резервирование без сюрпризов
Резервирование ломается не в момент сбоя, а раньше, когда команда считает любую ошибку поводом сразу уйти на другого провайдера. Так делать не стоит. Для каждого маршрута нужен понятный порядок: основной провайдер и запасной. Если чат работает на одной модели у двух провайдеров, зафиксируйте это заранее и не меняйте маршрут на лету без причины.
Сначала разделите ошибки по типам. Общий HTTP-статус сам по себе мало что говорит. 429 обычно означает перегрузку или лимит, timeout говорит о сети или задержке, 5xx указывает на сбой у провайдера. А вот 401, 403, ошибка в формате запроса или блокировка по policy не должны запускать резервный маршрут. Если сам запрос неверный, второй провайдер чаще всего вернет ту же проблему.
Для большинства сценариев хватает простых правил:
- timeout выше порога - одна повторная попытка, затем переход на запасной маршрут
429и5xx- быстрый переход на запасной маршрут- ошибки аутентификации, policy и валидации - не переключать, а возвращать понятную ошибку клиенту
- пустой или битый ответ - считать сбоем провайдера и включать запасной маршрут
После переключения клиент не должен замечать, что ответ пришел из другого места. Для этого шлюз приводит ответы к одной схеме: одинаковые поля, единый формат usage, одна структура ошибок и те же названия ролей и сообщений. Иначе старый SDK формально продолжит работать, но приложение начнет ломаться на парсинге, подсчете токенов или обработке tool calls.
Полезно задать и пороги по времени. Если основной провайдер отвечает за 2 секунды, а запасной за 12, слепое переключение может ухудшить продукт сильнее, чем короткая пауза. На практике лучше работают простые условия: переход после двух сбоев подряд за короткий интервал или после явного роста задержки выше вашей нормы.
Потом проверьте схему под нагрузкой. Одного ручного запроса с отключенным провайдером мало. Нужен тест, где часть запросов получает timeout, часть - 429, а часть - битый JSON. Если при этом приложение получает тот же формат ответа и не теряет сессию, резервирование настроено нормально.
Пример: чат поддержки с двумя провайдерами
Чат поддержки удобно строить так, чтобы само приложение знало только один эндпоинт. Веб-чат, мобильное приложение и CRM шлют запросы в одну точку, а дальше шлюз сам выбирает модель и провайдера по простым правилам. Для команды это и есть нормальный мультипровайдерный доступ к LLM: один API вместо набора разных интеграций.
Представим сервис доставки. Большая часть обращений скучная, но массовая: статус заказа, перенос времени, возврат, смена адреса. Такие запросы нет смысла отправлять в дорогую модель. Их обрабатывает быстрая модель у первого провайдера, которая отвечает за 1-2 секунды и держит низкую цену на типовом потоке.
Если клиент пишет длиннее обычного, просит разобрать спорную ситуацию или первый провайдер начинает тормозить, запрос уходит ко второму. Приложение этого не замечает. Оно по-прежнему обращается к тому же OpenAI-совместимому эндпоинту, а логика резервирования живет внутри шлюза.
Маршрут обычно выглядит предсказуемо: короткие FAQ и статусные вопросы идут в быструю модель, таймауты и 5xx сразу переводят запрос на запасного провайдера, а пики нагрузки во время акции частично уходят на второй канал. Если в сообщении есть ИИН, телефон, адрес или номер договора, такой текст лучше отправлять в локально размещенную модель внутри своего контура.
Этот последний пункт часто решает больше проблем, чем кажется. Когда оператор просит проверить данные клиента, не стоит без необходимости выносить такой текст во внешний сервис. Если компании нужна data residency в Казахстане, разумнее держать чувствительные запросы внутри страны. У AI Router для этого есть 20+ open-weight моделей на собственной GPU-инфраструктуре, и их можно использовать через тот же OpenAI-совместимый API.
После запуска команда поддержки и инженеры смотрят уже не на догадки, а на факты. В логе по каждому запросу видно, какой провайдер ответил, какая модель сработала, сколько занял ответ и во что он обошелся. Через неделю легко заметить простую вещь: типовые вопросы можно держать на быстрой дешевой модели, а запасной провайдер нужен не на каждый запрос, а только на сбои и перегрузку.
Ошибки, которые чаще всего ломают схему
Мультипровайдерная схема чаще ломается не из-за самих моделей, а из-за мелких решений в маршрутизации. Снаружи все выглядит просто: один эндпоинт, один SDK, один токен. На практике сбой обычно прячется в правилах переключения, правах доступа и логах.
Первая частая ошибка - переключать провайдера после любой 429. Такой ответ не всегда значит, что провайдер недоступен. Иногда вы уткнулись в лимит по конкретному ключу, модели или типу запроса. Если без разбора пересылать трафик дальше, система начнет метаться между провайдерами, а задержка вырастет. Лучше разделять причины: где сработал rate limit, где кончилась квота, а где у провайдера и правда сбой.
Вторая ошибка - держать доступ разных команд в одном токене. Тогда support-бот, внутренний copilot и тестовый стенд делят общий лимит и общую историю. Потом одна команда ловит 429, а виноватой кажется другая. Нормальная схема проще: отдельные ключи, отдельные лимиты, отдельные логи.
Много проблем дает и сравнение моделей только по названию. Одна и та же модель у разных провайдеров может отличаться по версии, длине контекста, качеству stream-ответа, поддержке tool calls и даже формату ошибок. Если тестировать только короткий текстовый запрос, схема кажется рабочей. В продакшене ломается первый же сценарий с функциями или длинным диалогом.
Минимум, который стоит проверить, - обычный ответ без стриминга, stream по токенам, tool calls с реальной схемой и длинный запрос с вашим типичным контекстом. Этого уже хватает, чтобы поймать большую часть неприятных расхождений до релиза.
Еще одна ошибка выглядит скучно, но бьет больнее других: в лог не пишут фактический маршрут запроса. Потом никто не может ответить, какой провайдер обработал запрос, почему сработал fallback, сколько занял ответ и где выросла цена. В логах должны быть хотя бы провайдер, модель, причина выбора маршрута, код ответа и задержка. Без этого резервирование превращается в гадание.
Проверка перед запуском
Перед продом лучше поймать скучные поломки, чем потом искать их в ночных логах. Для мультипровайдерной схемы это обычно не одна большая ошибка, а несколько мелких: другой эндпоинт в stage, сломанный stream, лишняя задержка при переключении или непонятные расходы.
Если у вас OpenAI-совместимый шлюз, удобно держать один формат запросов для всех сред. Меняться должны секреты, лимиты и набор доступных моделей, а не код клиента и не base_url в каждом сервисе.
Быстрая проверка занимает около 15 минут. Прогоните один и тот же запрос через dev, stage и prod. Сравните не только текст ответа, но и заголовки, таймауты и коды ошибок. Отдельно проверьте три режима: обычный ответ, stream и вызов tools. Очень часто базовый чат работает, а stream обрывается на прокси или tools теряют схему аргументов.
После этого имитируйте отказ провайдера и измерьте время переключения. Если ваш предел для пользовательского запроса 3 секунды, переход на резерв не должен съедать почти весь этот бюджет. Затем откройте логи и убедитесь, что там видны модель, провайдер, среда, маршрут запроса и итоговый статус. Иначе разбор инцидента снова превратится в догадки.
В конце посмотрите отчет по расходам. Он должен разделять сервисы, команды и среды, чтобы тестовый трафик не смешивался с боевым. Если вы используете и внешних провайдеров, и локально размещенные модели, полезно видеть оба варианта в одном биллинге и в одной истории маршрутов.
Хороший короткий тест выглядит просто. Один сервис отправляет 20-30 одинаковых запросов, потом вы вручную отключаете основного провайдера и смотрите, что меняется: время ответа, формат данных, доля ошибок и стоимость. Пользователю не важно, какой провайдер ответил. Ему важно, что чат не завис, stream не оборвался, а tool не вызвался повторно.
Что делать дальше
Не переводите сразу все LLM-сценарии на новую схему. Возьмите один сервис с понятной нагрузкой, например чат поддержки, и подключите к нему двух провайдеров через один эндпоинт. Так команда быстро увидит, где ломаются таймауты, лимиты и формат ответов.
До разделения трафика снимите базовую картину. Замерьте среднюю задержку и p95, посчитайте цену одного запроса и цену 1000 токенов по реальному профилю, сохраните долю ошибок по типам и отдельно отметьте, какие запросы требуют строгого хранения данных, а какие можно отправлять во внешний контур. Эти цифры лучше собирать хотя бы несколько дней. Иначе потом будет трудно понять, стало лучше или просто изменился профиль нагрузки.
Через неделю сравните две вещи: где пользователи ждут дольше и где вы платите больше за ту же задачу. Если одна модель пишет чуть лучше, но отвечает в два раза медленнее, это уже влияет на продукт, а не только на вкус инженеров.
Отдельно проверьте правила по данным и журналам. Где хранятся промпты и ответы, кто видит аудит-логи, как маскируется PII, сколько времени вы держите логи и можно ли использовать внешний хостинг для каждого сценария. Для банка, телекома, ритейла или госсектора это часто влияет на архитектуру сильнее, чем цена модели.
Если вы работаете в Казахстане, удобно брать шлюз, который уже закрывает местные требования. У AI Router на airouter.kz есть один OpenAI-совместимый API, маршрутизация между внешними провайдерами и 20+ локально размещенными open-weight моделями, хранение данных внутри страны, маскирование PII, аудит-логи и rate limits на уровне ключа. Для B2B-команд это еще и упрощает расчеты: инвойсинг идет ежемесячно в тенге, без наценки на API.
Дальше порядок простой: сначала пустите через новый слой 5% запросов, потом переведите один класс задач целиком, и только после этого добавляйте третьего провайдера или более сложные правила маршрутизации. Подход скучный, но обычно именно он экономит недели отладки и лишние счета.
Часто задаваемые вопросы
Нужно ли переписывать код, если у нас уже есть OpenAI SDK?
Обычно нет. Если шлюз поддерживает OpenAI-совместимый формат, вы чаще всего меняете только base_url и токен, а вызовы SDK и промпты оставляете как есть.
Потом проверьте stream, tools и разбор ошибок. Именно там чаще всего всплывают отличия.
Что реально меняется в интеграции при переходе на единый шлюз?
Сервис должен знать один адрес API и один внутренний токен. Выносите base_url и секреты в конфиг, а выбор провайдера отдайте шлюзу.
Так вы сможете менять маршрут без релиза и без правок в нескольких репозиториях.
Какой формат API лучше взять как общий для всех провайдеров?
Берите один внутренний контракт для всех сервисов. Проще всего взять OpenAI-совместимую схему, потому что под нее уже есть знакомые SDK и понятный формат ответа.
Дальше держите одинаковые поля запроса, одинаковую структуру ошибок и единый usage. Иначе резервирование быстро ломается на парсинге.
Как настроить резервирование, чтобы не плодить дубли запросов?
Ставьте короткий таймаут, одну повторную попытку для сетевой ошибки и быстрый переход на запасной маршрут для 429 и части 5xx. Для вызовов tools добавьте защиту от повторного запуска, иначе получите дубль действия.
Хорошее правило простое: клиент отправляет один запрос, а шлюз сам решает, когда и куда переключиться.
В каких случаях не стоит сразу уходить на запасного провайдера?
Не переключайте маршрут при 401, 403, ошибке валидации и policy-блокировке. Если сам запрос неверный или доступ сломан, второй провайдер обычно вернет ту же проблему.
Резерв имеет смысл при таймауте, 429, части 5xx и битом ответе со стороны провайдера.
Как правильно хранить и менять токены провайдеров?
Приложение должно хранить только внутренний ключ для доступа к шлюзу. Внешние секреты провайдеров держите в secret manager или другом закрытом хранилище и не кладите их в код и CI-логи.
Ротацию тоже делайте на стороне шлюза. Тогда сервис продолжит работать без правок и без нового релиза.
Как разделить доступ между продом, тестом и разными командами?
Разделяйте ключи по средам и по сервисам. У prod, stage и dev должны быть разные лимиты и отдельные журналы, чтобы тестовый трафик не мешал боевому.
Тот же подход нужен и для команд. Чат поддержки, внутренний copilot и эксперименты аналитиков не должны делить один общий токен.
Какие логи нужны, чтобы потом понять причину сбоя и рост расходов?
Пишите в журнал, кто отправил запрос, какой маршрут выбрал шлюз, какой провайдер и модель ответили, сколько занял ответ и чем все закончилось. Этого уже хватает для разбора большинства сбоев.
Если еще добавить токены и стоимость, команда быстро увидит, где растет цена и где тормозит конкретный маршрут.
Когда есть смысл отправлять запросы в локальную модель, а не во внешний сервис?
Локальная модель нужна там, где текст содержит чувствительные данные или правила требуют хранить данные внутри страны. Для чата поддержки это часто ИИН, телефон, адрес, номер договора и похожие поля.
В такой схеме общий шлюз особенно удобен: приложение шлет тот же запрос, а шлюз сам отправляет чувствительный трафик во внутренний контур.
С чего лучше начать, если не хочется рисковать всем продом сразу?
Начните с одного сценария с понятной нагрузкой, например с чата поддержки. Пустите через шлюз малую долю трафика, сравните задержку, ошибки и цену, а потом расширяйте схему.
Если нужен готовый слой под Казахстан, AI Router уже дает один совместимый API, маршрутизацию, аудит-логи, PII masking и локальные модели без смены SDK.