Структурированный вывод LLM: почему он ломается в продакшене
Структурированный вывод LLM часто ломается в продакшене из-за битого JSON, дрейфа схем и сбоев вызова инструментов. Разберем проверки и ретраи.
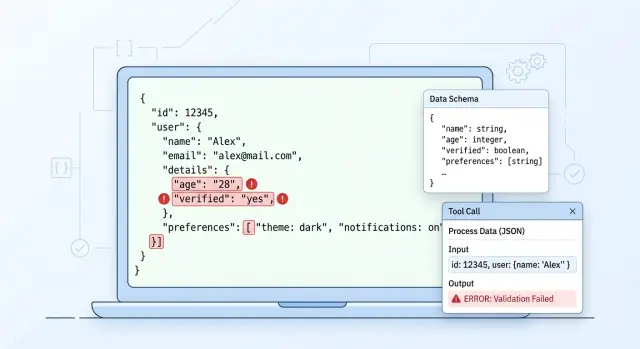
Что именно ломается в продакшене
В тестовой среде все часто выглядит прилично. Команда прогоняет десяток понятных примеров, парсер читает ответ, и кажется, что модель уже готова к релизу. Потом приходит живой ввод, и контракт между моделью, схемой и кодом начинает трещать.
Самая частая поломка выглядит почти смешно: модель пишет одну фразу перед JSON. Для человека это мелочь, а для парсера - уже ошибка. Вместо чистого объекта приходит короткое пояснение, потом открывающая скобка, и весь пайплайн встает на первом символе.
Дальше начинаются сбои тише и неприятнее. Поле, которое вчера было строкой, сегодня приезжает числом. order_id превращается из "00125" в 125, и система теряет ведущие нули. Массив может оборваться на середине ответа, если модель уперлась в лимит токенов, провайдер прервал генерацию или приложение слишком рано закрыло чтение.
Проблема в том, что такие ошибки долго не видны. Ответ проходит обычные тесты, а потом падает на редком вводе: пользователь вставил таблицу из письма, смешал русский и английский, прислал пустое поле или слишком длинный комментарий. Один нестандартный запрос ломает ветку, которую команда почти не проверяла.
Небольшой пример: сервис извлекает данные заявки и ждет JSON с полями customer_name, amount и currency. На простых примерах модель отвечает ровно. На реальной заявке она сначала пишет короткое пояснение, amount отдает строкой с пробелом, а currency пропускает, потому что не нашла ее явно в тексте. Смысл в ответе есть, но код уже не может безопасно его использовать.
Если команда маршрутизирует запросы между разными моделями через один API, разброс становится заметнее. Одна модель держит формат жестко, другая любит добавлять комментарий, третья чаще путает типы. Поэтому структурированный вывод ломается не в одной точке. Обычно проблема сразу на трех уровнях: синтаксис JSON, совпадение со схемой и смысл полей для бизнеса.
Где рвется цепочка ответа
Структурированный ответ редко ломается в одном месте. Обычно рвется вся цепочка: промпт, модель, парсер, транспорт и сервис, который читает результат. На тестах это незаметно, потому что запросы короткие, ответы аккуратные, а все участники цепочки ждут один и тот же формат.
Первая трещина часто появляется между инструкцией и схемой. Промпт просит у модели "краткое объяснение и список причин", а JSON Schema ждет строгое поле reason_codes как массив строк без лишнего текста. Модель старается выполнить промпт и пишет пояснение там, где парсер ждет только массив. Ответ почти правильный. Для продакшена этого уже достаточно, чтобы все сломалось.
Потом подключается постобработка. Команда просит модель вернуть JSON в markdown-блоке, а парсер вырезает ```json и чистит переносы строк. На этом шаге легко испортить экранирование: исчезает обратный слеш, кавычка закрывается раньше времени, строка с переводом строки превращается в невалидный JSON. В логах это выглядит как "модель вернула мусор", хотя ошибку внес уже ваш код.
Еще один частый сбой дает сам транспорт. Если сервер или прокси обрывает ответ по таймауту, вы получаете половину объекта: открытая фигурная скобка, незакрытый массив, недописанное поле. Это особенно заметно на длинных ответах и при маршрутизации через нескольких провайдеров. Если вы работаете через единый OpenAI-совместимый шлюз, вроде AI Router, стоит проверять таймауты, размер ответа и логи по каждому запросу, а не искать причину только в приложении.
Последний разрыв бывает уже после успешного парсинга. Один сервис начал отправлять customer_type, а следующий все еще ждет старое поле segment. JSON валиден, локальная схема проходит, но бизнес-логика дальше падает или молча берет значение по умолчанию. Это самые неприятные ошибки. Они не шумят сразу и портят данные тихо.
Поэтому цепочку лучше проверять по слоям: что именно просил промпт, что реально вернула модель, что изменил парсер, не обрезал ли ответ сервер и ту ли версию полей ждет следующий сервис. Если смотреть только на финальную ошибку парсинга, вы почти всегда чините не тот участок.
Какие ошибки JSON встречаются чаще всего
В продакшене JSON обычно ломается не из-за редких багов, а из-за мелочей. Человек читает ответ и думает, что все нормально. Парсер так не думает.
Самая скучная ошибка - лишняя запятая в конце объекта. Модель пишет {"status":"ok",} по привычке, потому что часто видит похожие примеры в коде. Для стандартного JSON такой ответ невалиден.
Не лучше и одинарные кавычки. Модель легко выдает {'status':'ok'} вместо {"status":"ok"}. Для Python-словаря это похоже на правду, для JSON - нет. Если команда смотрит ответ глазами, такую разницу часто пропускают.
Еще одна поломка связана со строками. Модель вставляет реальный перенос строки внутрь значения, например в комментарий или адрес. Визуально текст читается. Парсер видит сломанную строку и останавливается. Если нужен перенос, модель должна вернуть \n, а не разрывать строку прямо в значении.
Отдельно раздражает случай, когда модель оборачивает ответ в markdown и добавляет ```json. Для чата это удобно. Для API это мусор. Парсер ждет чистый объект, а получает форматирование вместе с полезными данными.
Иногда модель идет еще дальше и печатает два объекта подряд. Например, сначала черновик, потом исправленный вариант: {"amount":1000}{"amount":1200}. Бывает мягче: объект, а после него короткое пояснение текстом. Для системы это одна и та же проблема - ответ перестает быть одним валидным JSON-документом.
На практике такие ошибки всплывают в обычных задачах: классификация заявки, вызов инструмента, заполнение полей формы. Если ответ падает "иногда", почти всегда стоит сначала посмотреть сырой вывод модели, а не сразу винить схему или клиентский код.
Почему схема перестает совпадать с ответом
Схема редко ломается сразу и громко. Чаще она сползает понемногу, пока одна часть системы уже живет по новым правилам, а другая все еще ждет старый ответ. Так ответ по схеме и начинает сыпаться в продакшене.
Частая история: поле сначала считают необязательным, потому что модель "обычно" его присылает. Через пару спринтов это поле начинают использовать в бизнес-логике, и фактически оно уже обязательно. В схеме это не закрепили, тесты молчат, а потом часть ответов приходит без него и цепочка падает в самом неудобном месте.
То же происходит с enum. Сегодня статус равен approved, rejected или review. Завтра в промпте или постобработке появляется needs_info, но версию схемы никто не меняет. Для человека это мелочь. Для парсера - новый вариант, которого он не понимает.
С датами проблема еще скучнее, а потому опаснее. Один релиз отдает 2025-04-27, другой - 27.04.2025, третий добавляет время. Если команда не зафиксировала один формат, несовпадение всплывает только на реальных данных, когда сортировка, фильтр или импорт в CRM дают странный результат.
Еще один частый сбой - вложенный объект исчезает у части ответов. Например, раньше модель возвращала customer.contact.email, а потом для некоторых записей отдает только customer.name. Если код ждет полный объект без проверки на null или отсутствие поля, ошибка прилетает не в момент генерации, а сильно позже.
Отдельная причина дрейфа - код и схема живут в разных репозиториях. Одна команда обновила DTO, другая не подтянула JSON Schema, третья поменяла промпт. Формально все сделали небольшое изменение, а вместе получили несовместимость.
В системах с несколькими моделями и провайдерами это заметнее. Если команда гоняет один и тот же контракт через единый OpenAI-совместимый endpoint, различия быстро выходят наружу. В AI Router, например, можно прогонять те же SDK, код и промпты через разные модели, просто меняя base_url на api.airouter.kz. Это удобно для сравнения, но такие прогоны быстро показывают, где схема описана слишком оптимистично.
Хорошая схема не гадает, что модель "скорее всего" вернет. Она фиксирует обязательные поля, формат даты, допустимые значения и поведение для пустых вложенных объектов.
Где сбоит вызов инструментов
С вызовами инструментов модель часто ломается на простых вещах. Она выбирает не тот инструмент, если названия похожи или описания пересекаются. Если один инструмент ищет клиента, а другой проверяет его лимит, модель легко путает их, особенно когда запрос короткий и без контекста.
Не реже приходят неполные arguments. Модель передает customer_id, но забывает region или document_type. На тестах это легко пропустить: примеры обычно чистые, а пользователи в продакшене пишут короче, с опечатками и пропусками.
Отдельный сбой возникает, когда инструмент ждет объект, а модель отдает строку. Для человека "customer_id=123" выглядит почти нормально. Для сервиса это уже другой тип данных, и обработчик падает еще до бизнес-логики.
Иногда модель пытается усидеть на двух стульях и выдает обычный текст вместе с вызовом инструмента в одном ответе. Оркестратор ждет одно действие, а получает два. В итоге часть систем показывает текст пользователю, часть запускает инструмент, а часть делает и то и другое.
Даже при одном OpenAI-совместимом API это не исчезает. Если команда меняет модели или провайдеров через один шлюз, формат tool call может вести себя чуть по-разному при том же контракте. Мелкое отличие быстро превращается в сбой в цепочке.
Обычно помогают простые ограничения. Названия инструментов должны отличаться по смыслу, а не только по формулировке. Типы и обязательные поля нужно проверять до вызова. Режим ответа лучше делать один: либо текст, либо tool call. После ошибки модели стоит возвращать точную причину, а не общий invalid arguments. И еще один практичный шаг: блокируйте повтор одного и того же вызова с теми же параметрами. Если инструмент вернул ошибку, модель нередко повторяет тот же вызов без изменений, и система тратит токены на бесполезный цикл.
Как проверять ответ по шагам
Структурированный вывод редко ломается в одном месте. Обычно ошибка появляется раньше, а замечают ее позже, когда приложение уже попробовало распарсить, починить и использовать ответ сразу. Поэтому порядок проверок лучше сделать жестким и одинаковым для всех запросов.
Подход простой:
- Сохраните сырой payload и метаданные запроса.
- Попробуйте строгий парсинг без автопочинки.
- Если парсинг не прошел, исправляйте только по явным правилам.
- Если JSON разобрался, отдельно проверьте схему и типы.
- Только после этого запускайте бизнес-проверки.
Сырой ответ нужно сохранять до любой чистки. Не обрезайте пробелы, не удаляйте markdown, не переписывайте кавычки. Если оставить только "исправленную" версию, вы потеряете источник сбоя и не поймете, что именно вернула модель.
Строгий парсинг нужен не ради строгости. Он показывает реальную частоту ошибок JSON: лишняя запятая, текст до объекта, массив вместо объекта, строка вместо числа. Если сразу включить умный repair, вы скроете поломку и начнете лечить симптомы.
Автопочинка тоже должна быть узкой. Можно снять внешние тройные кавычки или вытащить JSON из code block. Но не стоит гадать, какое поле модель "наверное имела в виду". Чем свободнее repair, тем больше тихих ошибок в продакшене.
Проверку схемы и типов лучше разделять. Схема отвечает на вопрос: такие поля вообще допустимы? Проверка типов отвечает на другой: price - это число, а не строка "1000"? Такое разделение сильно упрощает логи и повторные попытки.
Бизнес-проверки идут последними. Схема может пропустить заказ с отрицательной суммой, датой в прошлом или пустым списком товаров. Для JSON это валидный объект. Для продукта - нет.
Логируйте не просто факт отказа, а точную причину: parse_error, schema_error, type_error, business_rule_error. Рядом храните сырой payload. Тогда команда видит, что именно надо править: промпт, схему, retry-логику или код обработки.
Как настраивать повторные попытки
Одинаковые ретраи для всех сбоев быстро превращают ошибку в цикл. Если ответ сломался из-за пропущенной кавычки, модели не нужно заново решать всю задачу. Если JSON проходит парсинг, но не проходит схему, ей нужно исправить конкретное поле, а не переписывать весь объект.
Для синтаксической ошибки лучше работает короткая команда вроде: "Исправь только JSON. Не меняй поля, не добавляй текст вне объекта". Для ошибки схемы запрос должен быть уже точным: "Поле amount должно быть числом, сейчас пришла строка 12 000". Для ошибки вызова инструмента полезно вернуть сжатое сообщение из самого инструмента, чтобы модель увидела, какого параметра не хватает. А вот временные сбои вроде таймаута, 429 или короткого сетевого обрыва должен обрабатывать оркестратор, а не сама модель.
Пределы лучше ставить заранее. Обычно хватает 2-3 попыток на формат и одной дополнительной попытки после сбоя инструмента. Не менее важен общий лимит по времени. Если цепочка тянется дольше 5-10 секунд, пользователь уже видит задержку, а качество ответа редко растет настолько, чтобы это оправдать.
Перед любым внешним действием ставьте idempotency key. Иначе повторный вызов после таймаута создаст два платежа, два заказа или две записи в CRM. Это частая ошибка: команда чинит JSON, но забывает, что инструмент уже мог отработать один раз.
Хорошее правило простое: сначала чините формат, потом схему, и только потом повторяйте вызов инструмента.
Пример на простом сценарии
У банка есть чат-бот, который принимает заявку на кредит. Модель должна вернуть 4 поля: имя, ИИН, сумму и дату заявки. На вид все хорошо, потому что ответ приходит в JSON.
{
"name": "Алия Садыкова",
"iin": "",
"amount": "500000 тенге, желательно на 12 месяцев",
"date": "2026-04-27"
}
Проблема в том, что такой ответ только выглядит пригодным. JSON формально валиден, но схема уже сломана. Поле amount должно быть числом, а не строкой с пояснением. Поле iin пустое, хотя CRM ждет строку из 12 цифр. Если система проверяет только синтаксис JSON, ошибка уедет дальше по цепочке и всплывет уже на вызове CRM.
Обычно это заканчивается просто: бот пытается создать заявку, CRM отклоняет запрос, а пользователь получает странный ответ или молчание. Хуже, когда система теряет уже собранные данные и начинает опрос заново. Для клиента банка это раздражает очень быстро.
В таком сценарии проверка должна идти по порядку: сначала парсим JSON, потом сверяем типы по схеме, затем проверяем бизнес-правила - ИИН из 12 цифр, сумма числом и в допустимом диапазоне, дата в одном формате. И только после этого вызываем CRM.
Если проверка не прошла, системе не нужно повторять весь диалог. Она должна сохранить корректные поля и спросить только то, что сломано. Например: "Укажите ИИН из 12 цифр". Имя и дата уже есть, их не надо спрашивать снова.
Это простой, но очень показательный случай. Проблема редко в одном большом сбое. Чаще это маленькие трещины: валидный JSON, неверный тип, пустое обязательное поле, а затем падение на вызове инструмента или CRM. Если поставить валидацию до внешней системы и делать узкие повторные попытки только по битому полю, цепочка становится заметно спокойнее.
Какие ошибки команда повторяет
Многие сбои начинаются не с модели, а с привычек команды. Самая частая ошибка простая: если ответ похож на валидный JSON, его считают пригодным для работы. Но синтаксис может быть правильным, а смысл нет. Поле status есть, но значение не из списка. Массив пришел, но в нем не те объекты. tool_name заполнен, а аргументы пустые.
Вторая типичная проблема - один и тот же промпт отправляют во все модели и на все задачи. На бумаге это удобно. В продакшене так ломается формат ответа, потому что модели по-разному понимают ограничения, формат дат, пустые поля и вызов инструментов. Промпт, который держится на одной модели, на другой начинает добавлять пояснения, менять имена полей или пропускать обязательные значения.
Еще один слабый участок - логи. Команда хранит только итог после парсинга и не сохраняет raw output, tool_call.arguments и ответ после ретрая. Потом инцидент уже нельзя разобрать честно. Видно лишь, что CRM отклонила заявку, но не видно, какой ответ дала модель, что изменил парсер и на каком шаге все поехало.
Нередко встречается и слишком агрессивная автопочинка. Парсер исправляет кавычки, дорисовывает скобки, подменяет типы и пытается угадать пропущенные поля. В моменте это снижает число ошибок в логах, но на деле только прячет их. Через неделю команда уже не понимает, где реальная проблема - в модели, в схеме или в своем repair-слое.
Короткий чек-лист перед релизом
Перед выкладкой прогоните систему на живых примерах, где уже были сбои. Формат чаще ломается на мелочах: модель добавляет ```json, забывает поле, меняет тип или пишет пояснение перед объектом.
- Храните raw logs для каждого сбоя: промпт, сырой ответ модели, payload инструмента, id запроса, выбранную модель и код ошибки.
- Добавьте в ответ версию схемы, например
schema_version, чтобы не путать старые ответы с новыми после релиза. - Задайте явный retry budget: сколько повторов можно сделать, на каких ошибках и меняется ли модель или промпт на следующей попытке.
- Считайте метрики отдельно: parse rate, schema rate и tool success rate. Один общий процент успеха почти всегда скрывает источник сбоя.
Если у вас несколько моделей или провайдеров, смотрите эти метрики по каждому отдельно. Один маршрут может стабильно отдавать чистый JSON, а другой чаще ломать вызов инструментов при том же коде.
Хороший признак готовности простой: любой сбой можно быстро найти в логах, повторить локально и отнести к понятному классу ошибки. Если на это уходит полчаса ручного разбора, релиз лучше притормозить.
Что сделать дальше
Начните с одного сценария, где ошибка бьет по деньгам, срокам или ручной работе. Хороший кандидат - извлечение полей из заявки, где модель должна вернуть JSON, а потом вызвать инструмент без участия человека. Если там ломается один ответ из двадцати, команда уже теряет время на разбор и исправление.
Сначала замерьте базовую картину. Без цифр спор о качестве модели быстро превращается в спор о впечатлениях. Достаточно трех метрик: сколько ответов вообще разбираются как JSON, сколько проходят проверку по схеме и сколько вызовов инструмента реально исполняются без ручной починки.
Потом прогоните один и тот же контракт на нескольких моделях. Не меняйте промпт, схему и постобработку между тестами, иначе сравнение потеряет смысл. Часто одна модель пишет чуть красивее, а другая заметно реже ломает enum, даты или обязательные массивы.
Если вы сравниваете провайдеров, удобнее держать один OpenAI-совместимый endpoint и менять только base_url. В такой схеме AI Router может быть нейтральным слоем: команда использует те же SDK, код и промпты, а маршруты между моделями меняет без переписывания интеграции. Для быстрых сравнений это сильно сокращает лишнюю работу.
После тестов закрепите правила в коде, а не в презентации. Добавьте автоматическую валидацию, лимит на повторные попытки, понятные причины отказа и логирование сырого ответа для разбора инцидентов. Отдельно пропишите рабочую инструкцию: что считать ошибкой схемы, когда делать retry, а когда отправлять запрос в ручную очередь.
Если у команды уже есть пилот, не расширяйте его сразу на десять сценариев. Доведите один поток до стабильного состояния, где parse rate и успешные вызовы держатся на понятном уровне хотя бы неделю подряд. После этого масштабирование идет спокойнее и обходится дешевле.
Часто задаваемые вопросы
Что ломается первым в структурированном выводе?
Чаще всего все падает из-за мелочи: модель добавляет одну фразу перед объектом, оборачивает ответ в ```json или ставит лишнюю запятую. Человек это читает без труда, а строгий парсер останавливается сразу.
Сначала смотрите сырой ответ модели. Если он уже грязный, не ищите причину в CRM или базе данных.
Почему валидный JSON все равно не подходит для продакшена?
Даже валидный JSON может быть бесполезным. Поле amount приходит строкой вместо числа, order_id теряет ведущие нули, обязательное поле пустое, а статус не входит в допустимый набор значений.
Проверяйте не только синтаксис, но и типы, обязательные поля и смысл для продукта.
Стоит ли просить модель вернуть JSON в markdown-блоке?
Нет, лучше не просить markdown-блок. Для чата это удобно, для API это лишний мусор, который потом приходится вырезать и легко сломать на чистке.
Просите один чистый JSON-объект без пояснений до и после ответа.
В каком порядке лучше проверять ответ модели?
Сначала сохраните сырой payload без чистки. Потом запустите строгий парсинг, отдельно проверьте схему и типы, а уже после этого гоните бизнес-проверки и внешние вызовы.
Так вы быстро видите, где именно порвалась цепочка: на JSON, на контракте или на правилах продукта.
Когда нужен retry, а когда он только мешает?
Повтор полезен не всегда. Если сломан только JSON, попросите исправить формат и не менять поля. Если не сходится схема, укажите точное поле и нужный тип. Если сеть вернула таймаут или 429, это должен разрулить оркестратор, а не модель.
Один и тот же общий retry для всех ошибок почти всегда тратит время и токены зря.
Сколько повторных попыток ставить по умолчанию?
Обычно хватает 2–3 попыток на формат и одной дополнительной попытки после сбоя инструмента. Дольше тянуть цепочку редко есть смысл: задержка растет, а ответ не становится заметно лучше.
Сразу ставьте общий лимит по времени, чтобы пользователь не ждал бесконечно.
Как снизить число ошибок при вызове инструментов?
Чтобы вызовы инструментов не сыпались, дайте им разные по смыслу названия и проверяйте arguments до запуска. Если инструмент ждет объект, не принимайте строку "почти такого же вида".
Еще помогает простой режим ответа: либо текст, либо tool call. Тогда оркестратор не пытается угадать, что делать с двойным ответом.
Что обязательно логировать для разбора сбоев?
Храните сырой ответ модели, сам промпт, tool_call.arguments, выбранную модель, id запроса и точную причину отказа вроде parse_error или schema_error. Без этого инцидент потом приходится разбирать вручную по кускам.
Если у вас есть только уже "исправленный" JSON, источник сбоя вы уже потеряли.
Почему один и тот же контракт проходит на одной модели и падает на другой?
Одна и та же схема ведет себя по-разному на разных моделях. Одна держит формат жестко, другая любит комментарии, третья чаще путает типы или пропускает пустые поля.
Гоняйте один и тот же контракт через несколько моделей без изменения промпта и постобработки. Так вы быстро увидите, где проблема в модели, а где в вашей схеме.
С чего начать, если хочется быстро навести порядок?
Начните с одного сценария, где ошибка стоит денег или времени, например с извлечения полей заявки перед отправкой в CRM. Замерьте три вещи: сколько ответов вообще парсятся как JSON, сколько проходят схему и сколько внешних вызовов завершаются без ручной правки.
Когда этот поток держится стабильно хотя бы несколько дней, расширяйте подход на другие сценарии.