Фолбэки моделей без лишних расходов: как не платить дважды
Фолбэки моделей помогают пережить сбои, но без правил быстро удваивают счет. Разберем цепочки, лимиты и проверки, которые сдерживают расходы.
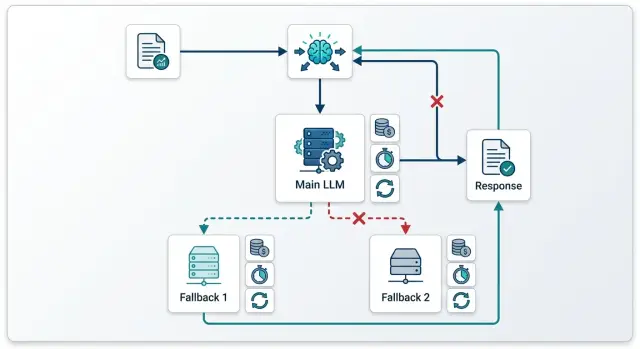
Где фолбэки съедают бюджет
Расходы растут в тот момент, когда первый сбой уже успел стать платным. Если основной запрос дошел до провайдера, тот часто списывает входные токены, даже если ответ оборвался, завис по таймауту или вернулся в неверном формате. Потом команда отправляет тот же промпт в резервную модель и получает второй счет за один пользовательский запрос.
Чаще всего так бывает при таймаутах. Ваш сервис видит, что ответ не пришел вовремя, и считает вызов неудачным. Но провайдер к этому моменту уже мог принять запрос, начать генерацию и потратить токены. Если сразу сделать повтор или перейти на резерв, вы платите дважды и еще рискуете получить два похожих ответа.
Ретрай и переход на резерв - это разные действия. Ретрай нужен, когда вы подозреваете короткий сетевой сбой между вашим сервисом и API. Вы повторяете тот же вызов в ту же модель, потому что сама модель, скорее всего, работала нормально. Фолбэк нужен в другой ситуации: провайдер недоступен, временно уперся в лимит, отвечает слишком долго или стабильно ломает формат на одном и том же типе задачи.
Не каждый код ошибки должен запускать цепочку дальше. Если промпт слишком длинный, сломана схема JSON, не заполнены обязательные поля, ошибка в авторизации или сработало правило безопасности, резервная модель не поможет. Она получит тот же плохой запрос и возьмет деньги еще раз.
Фолбэк обычно оправдан, когда причина вне самого запроса. Например, провайдер вернул 429 из-за временного лимита, 5xx, сетевое соединение оборвалось до начала обработки, или модель регулярно не укладывается в допустимое время. Тогда можно перейти на резерв, но по одному понятному правилу, без длинной цепочки из трех-четырех попыток.
Полезный вопрос здесь один: успел ли первый вызов реально начаться у провайдера. Если да, считайте его платным и не запускайте новый вызов автоматически без явной причины. Если нет, можно сделать один ретрай или один переход на резерв. Делать и то и другое подряд обычно дорого.
В рабочей системе это лучше всего видно по журналу попыток с одним request_id. Когда команда видит маршрут запроса и статус каждого шага, проще понять, где именно произошел сбой: до провайдера, у провайдера или уже после частичной генерации. Это не уменьшает число ошибок само по себе, но хорошо убирает лишние повторные списания.
Когда резервная модель нужна, а когда нет
Фолбэки нужны не при каждом сбое. Команды часто смешивают две разные проблемы: запрос не дошел до модели из-за сети или лимита, и модель ответила, но сам ответ оказался плохим. Это разные случаи, и деньги они сжигают по-разному.
Если вы получили timeout, 502, 503 или 429, не спешите прыгать на другую модель. Сначала проверьте, был ли это сбой доставки, а не сбой качества. Когда запрос обычно работает, один повтор того же вызова часто дешевле, чем мгновенный переход на резерв. Вы не меняете поведение приложения, не рискуете другой ценой за токены и не тратите время на новую проверку ответа.
Если модель ответила, но сломала JSON, пропустила поле, ушла в лишний текст или дала слабый результат, повтор того же вызова редко помогает. Вы просто покупаете почти тот же ответ второй раз. В таком случае резерв нужен, но выбирать его стоит по причине сбоя.
Более дешевый резерв подходит, когда вам важна доступность, а не максимум качества. Так делают для простых задач: краткое резюме, классификация, перефразирование, черновой ответ оператору. Если основная модель временно недоступна, дешевая замена держит сервис в работе и не раздувает счет.
Более сильный резерв нужен, когда первая модель не справляется именно с задачей. Например, она регулярно путает поля в структуре ответа, теряет шаги в логике или не держит формат на длинном контексте. Тогда переход на более дорогую модель может быть выгоднее: вы платите больше за один вызов, но не платите за повторные ошибки, ручную проверку и переделку.
Если вы используете единый шлюз, такие случаи стоит разводить по разным правилам. Для сетевых кодов ставят retry на ту же модель. Для содержательных провалов - fallback на другую модель с понятной ролью: либо дешевле, либо сильнее.
Простое правило
Для одного пользовательского запроса обычно хватает двух шагов: первый вызов основной модели и еще один шаг сверху. Это либо повтор той же модели при сетевом сбое, либо переход на резерв, если ответ пришел, но не прошел ваши проверки.
Третья попытка уже часто дороже, чем ее польза. Если после двух шагов ответ все еще плохой, лучше упростить задачу: сократить контекст, вернуть шаблонный ответ, поставить запрос в очередь или передать его человеку.
Хорошее правило звучит просто: сеть лечите повтором, качество лечите сменой модели. Так фолбэки снижают риск, а не превращают каждый сбой в двойную оплату.
Как собрать цепочку без двойной оплаты
Цепочка с резервом работает только тогда, когда основная модель берет на себя почти весь обычный трафик, а запасная включается редко и по понятным правилам. Если ставить слишком дорогую модель первой, экономии не будет. Если отправлять в резерв почти каждый второй запрос, команда просто платит за два полных прогона вместо одного.
Сначала выберите основную модель для повседневной нагрузки. Обычно это самая дешевая модель, которая держит нужное качество на ваших типовых задачах. Для чата поддержки это может быть быстрый ответ по базе знаний, краткое резюме диалога или простая классификация обращения.
Переход на резерв лучше привязать к одной-двум причинам, а не к длинному списку. На практике часто хватает трех условий: первая модель не ответила за заданное время, ответ пустой или не проходит простую проверку формата, либо провайдер вернул ошибку, которую не стоит сразу повторять.
После этого задайте жесткий предел для всей цепочки. Нужен не только лимит на число попыток, но и общий бюджет одного запроса. Например, один повтор и не больше 12 000 токенов на всю обработку. Если первая попытка уже съела почти весь лимит, резерв лучше не запускать.
Частая ошибка - передавать во вторую модель весь накопленный контекст: полный лог, служебные поля, промежуточные ответы и старые сообщения, которые уже не влияют на результат. Так счет растет сразу в двух местах: вы платите за лишние входные токены и даете запасной модели больше поводов ответить длинно.
В резерв стоит отправлять только то, без чего он не сможет решить задачу: последний запрос пользователя, короткий system prompt, нужные факты и технические параметры ответа. Этого обычно хватает.
Если маршрутизация идет через единый шлюз, например AI Router, такие правила удобно держать в одном месте, а не размазывать по разным сервисам. Но сама логика не меняется: первая модель работает на обычном потоке, вторая включается только при сбое или явном провале качества.
Перед релизом прогоните цепочку на 10-20 типовых запросах. Возьмите короткие, длинные, неоднозначные и заведомо неудобные примеры. Смотрите не только на качество ответа, но и на три цифры: как часто включается резерв, сколько токенов уходит на второй шаг и сколько стоит один успешный ответ.
Если резерв срабатывает слишком часто, не чините это третьей моделью. Сначала упростите правила перехода, сократите контекст и проверьте, не выбрали ли вы слишком слабую основную модель.
Как считать стоимость одного запроса
Команды часто считают только цену удачной первой попытки. Для цепочки с резервом этого мало: один пользовательский запрос стоит среднюю цену всех веток, которые реально срабатывают. Именно здесь фолбэки начинают незаметно раздувать счет.
Сначала посчитайте базу без резервов. Возьмите первую модель и отдельно оцените ее входные токены, выходные токены и тариф на оба типа токенов. Если средний запрос в поддержку несет 1800 входных токенов и обычно получает 350 выходных, считайте по этим числам, а не по короткому тестовому примеру.
Удобно держать расчет в таком виде:
C1 = Tin1 × Rin1 + Tout1 × Rout1
E_fallback = C1 + Pfb × C2
E_retry = C1 + Prt × Crt
Здесь C1 - цена первой попытки, Pfb - вероятность перехода на резерв, C2 - цена резервной модели, Prt - вероятность ретрая, а Crt - цена повторного вызова. Если после ошибки вы сначала делаете ретрай, а потом уже идете в резерв, добавьте обе ветки по отдельности, а не одной общей строкой.
Вероятность перехода на резерв лучше брать из логов за живой период, например за последние 2-4 недели. И считать ее стоит отдельно по типам запросов. Короткий FAQ и длинная юридическая переписка ломаются по-разному и стоят по-разному.
Длина промпта и ожидаемого ответа сильно меняют итог. Резервная модель может быть дешевле по тарифу, но если вы шлете в нее тот же длинный контекст и разрешаете такой же длинный ответ, экономия быстро тает. Иногда проще урезать max tokens для резерва или отправлять в него более короткий системный промпт.
Ретрай и фолбэк лучше сравнивать на деньгах, а не по привычке. Если первая ошибка связана с кратким 429 или 5xx, повтор той же модели часто дешевле перехода на более дорогой резерв. Если основной провайдер регулярно упирается в таймаут на длинных запросах, ретрай просто дублирует расход на входные токены. Если резерв дает приемлемый ответ при меньшем лимите ответа, он может оказаться дешевле даже при более высоком тарифе за токен. И если провайдер берет оплату за вход даже при неудачном вызове, это надо явно включать в расчет.
В конце задайте жесткий лимит на один пользовательский запрос. Например, не больше 6-8 тенге для обычного чата поддержки и не больше 20 тенге для сложного кейса с большим контекстом. Когда цепочка доходит до лимита, остановите ее: лучше вернуть короткий ответ или попросить уточнение, чем запускать еще один дорогой вызов.
Если у вас единый шлюз для маршрутизации запросов, считать это заметно проще: все попытки видны в одном месте, и цена запроса не теряется между провайдерами.
Простой сценарий для чата поддержки
У интернет-магазина в чате обычно много коротких вопросов. Люди спрашивают, где заказ, сколько стоит доставка, как оформить возврат, почему не проходит оплата. Для таких сообщений дорогая модель чаще всего не нужна.
Базовая схема проста: недорогая модель отвечает на обычные запросы, а резервная включается только когда первая не ответила вовремя или вернула явную ошибку API. Это заметно дешевле, чем сразу слать каждый диалог в две модели или автоматически дублировать вызов после любого сбоя.
Основная модель спокойно закрывает статус заказа, сроки доставки, правила возврата, способы оплаты и смену адреса или контактов. Если вопрос короткий и опирается на готовые правила магазина, дорогая модель редко дает разницу, за которую стоит платить.
Проблемы начинаются, когда команда делает фолбэки слишком щедрыми. Частый промах выглядит так: первая модель получила длинную историю чата, не уложилась в таймаут, а система тут же отправила в резерв ту же историю целиком. В этот момент компания уже заплатила за входные токены один раз и почти сразу платит второй раз.
Для поддержки лучше резать контекст жестко. Если клиент спросил: "Где мой заказ 54128?", резервной модели обычно не нужна вся переписка за последние 20 сообщений. Хватает последнего окна: текущий вопрос, одна-две последние реплики и нужные поля из CRM или базы заказов. Это снижает расход токенов без потери качества.
Как выглядит экономия
До настройки цепочки магазин мог отправлять каждый сложный или зависший запрос в дорогую модель целиком. Допустим, средняя цена ответа выходила 18 тенге, потому что в вызов постоянно ехала длинная история.
После настройки картина меняется. Основная модель обрабатывает, например, 88 из 100 запросов по 4 тенге. Еще 12 запросов уходят в резерв после таймаута или ошибки, но уже с коротким контекстом, и стоят по 14 тенге. Средняя цена тогда будет такой:
(88 x 4 + 12 x 14) / 100 = 5.2 тенге за запрос
Разница заметная: не 18 тенге, а 5.2. При потоке в 50 000 чатов в месяц это уже не мелочь.
Если вы строите такую логику через OpenAI-совместимый шлюз, правило лучше держать на уровне маршрутизации: сначала дешевая модель, потом резерв только по таймауту или явной ошибке, без повторной отправки всей переписки. Для чата поддержки это один из самых прямых способов снизить счет без ухудшения ответа пользователю.
Ошибки, из-за которых счет растет
Деньги чаще всего уходят не на саму модель, а на логику вокруг нее. Один лишний переход в цепочке, один повтор длинного контекста, и запрос уже стоит в два-три раза дороже, хотя пользователь не получил ответ лучше.
Первая частая ошибка - запускать и ретрай, и фолбэк для одной и той же проблемы. Например, сервис получил timeout от первой модели, тут же отправил повтор в нее же и почти одновременно перевел тот же запрос на резервную модель. В итоге команда оплачивает два или три вызова там, где хватило бы одного решения.
Лучше заранее разделить типы сбоев. Для 429 и коротких сетевых сбоев обычно хватает одного ретрая. Для 5xx, долгого таймаута или явной деградации провайдера нужен переход на резерв. Для 400 и ошибок валидации не нужен ни ретрай, ни фолбэк - запрос надо чинить, а не слать дальше по цепочке.
Вторая ошибка - отправлять длинный контекст в каждую следующую модель целиком. Это особенно дорого в чатах поддержки и внутренних ассистентах, где история быстро разрастается до десятков сообщений. Если первая модель уже прочитала 12 тысяч токенов, а вторая и третья читают тот же объем заново, счет растет очень быстро.
Обычно для следующего шага хватает короткого пакета данных: последнего вопроса пользователя, сжатого резюме диалога, одного-двух найденных фрагментов из базы знаний и служебной причины перехода на другую модель.
Еще одна дорогая привычка - переключать запрос после медленного, но уже полезного ответа. Такое бывает, когда система смотрит только на время, а не на качество результата. Если первая модель дала нормальный черновик за 8 секунд, а правило требует фолбэк после 6 секунд, сервис может зря запустить вторую модель и оплатить оба ответа.
Лучше проверять не только таймер, но и состояние ответа. Если модель уже начала отдавать осмысленный текст, завершите запрос и покажите его пользователю. Жесткий фолбэк нужен, когда модель молчит, обрывает ответ или пишет явный мусор.
Отдельная проблема - не записывать причину перехода между моделями. Без этого команда видит только общий рост расходов и не понимает, что именно сломалось: сеть, лимиты, плохой промпт или слишком строгий таймаут. Нужен простой лог: какая модель приняла запрос, почему система ушла на другую, сколько токенов ушло на каждом шаге.
Если маршрутизация идет через AI Router, такие попытки и аудит-логи удобно держать в одном месте. Это помогает быстро находить цепочки, где фолбэки срабатывают слишком часто и просто жгут бюджет.
И еще одна типичная ошибка - не ставить лимиты на уровне API-ключа. Без них один цикл ретраев или один неудачный релиз могут за час создать тысячи дорогих вызовов. Лимиты по ключу, rate limits и простой дневной бюджет останавливают такие сбои раньше, чем придет неприятный счет.
Один практичный сценарий выглядит так: команда выпустила новый промпт для поддержки, и он начал вызывать длинные ответы. Первая модель тормозит, оркестратор запускает ретрай, потом фолбэк, потом еще один фолбэк с тем же полным контекстом. Если бы команда записывала причину перехода, резала контекст и ставила лимит на ключ, перерасход нашли бы в тот же день, а не в конце месяца.
Быстрый чек перед релизом
Перед запуском задайте жесткий потолок цены на один запрос. Без этого фолбэки быстро портят экономику: первый вызов упал, второй сработал, а деньги ушли на оба. Лимит лучше считать не "в среднем по дню", а на уровне одного пользовательского действия. Если ответ в чате поддержки не должен стоить дороже 4-5 тенге, это правило должно останавливать цепочку сразу, как только следующий шаг выходит за рамку.
После этого зафиксируйте, какие ошибки вообще имеют право запускать резервную модель. Список должен быть коротким и понятным. Обычно туда входят таймаут, 429, 5xx у провайдера и явный обрыв ответа. Плохой стиль текста, странный тон или ситуация "модель ответила не так, как хотелось" не должны автоматически включать дорогой резерв. Иначе команда начнет лечить качество там, где нужно чинить промпт или валидацию.
Отдельный лог для ретраев и фолбэков нужен почти всегда. В обычном журнале запросов такие переходы теряются, и потом никто не может быстро ответить, сколько стоил сбойный маршрут. Лог должен показывать исходную модель, причину переключения, длину входа, цену каждой попытки и итоговый статус.
Перед релизом полезно прогнать два неприятных теста, которые часто пропускают. Первый - длинный контекст, близкий к лимиту окна. Именно там резервные модели чаще всего ведут себя не так, как ожидала команда: одна модель принимает запрос, другая режет его или отвечает заметно дороже. Второй тест - пустой ответ. Он выглядит безобидно, но часто запускает повторный вызов, а потом еще и фолбэк, хотя пользователю по сути не ответил никто.
Проверьте это на коротком сценарии. Пользователь пишет в поддержку: "Где мой заказ?" Запрос идет в быструю модель. Если у провайдера таймаут, система пробует вторую. Но если первая вернула пустую строку без ошибки, а ваш код считает это успехом, оператор увидит тишину, а метрики не покажут проблему. Если же код считает пустой ответ сбоем, но не пишет отдельный лог, финансы увидят только выросший счет.
Перед выпуском посмотрите хотя бы на две метрики: среднюю цену запроса по маршруту, а не по модели отдельно, и долю переходов на резерв. Если средняя цена растет, а доля переходов выше 3-5% без явной причины, цепочку уже пора править. Иногда достаточно убрать один лишний ретрай, чтобы сэкономить заметную сумму за месяц.
Нормальный релизный чек не должен быть длинным. Нужны ясный лимит цены, короткий список ошибок для переключения, отдельный лог, два стресс-теста и пара метрик, на которые команда смотрит каждую неделю.
Что делать дальше в проде
После тестов не выкатывайте цепочку на весь трафик сразу. Начните с 5-10% запросов и дайте схеме поработать несколько дней. Так команда увидит не только ошибки, но и скрытые потери: где первая модель отвечает слишком долго, где фолбэк срабатывает чаще нормы, где дорогой провайдер включается без пользы.
Смотреть на фолбэки стоит каждый день, а не только по итогам месяца. Общая доля переходов мало что говорит сама по себе. Полезнее разрезать ее по моделям, типам задач и времени суток. Если одна и та же резервная модель резко растет по доле вечером, проблема часто не в логике приложения, а в лимитах или сбоях у конкретного провайдера.
Для рабочей рутины хватает простого набора метрик:
- доля запросов, которые ушли на резервную модель
- средняя цена одного успешного ответа с учетом повторов
- время до первого токена и полный ответ по каждой модели
- доля пустых, оборванных и слишком длинных ответов
- число переходов в цепочке на один пользовательский запрос
Раз в неделю чистите цепочку вручную. Если какой-то переход почти не спасает запросы, уберите его. Если модель отвечает медленно, но не дает заметно лучшего результата, не держите ее в середине цепочки. Часто два аккуратно подобранных шага работают лучше, чем четыре на всякий случай.
Смотрите и на живые примеры. Допустим, чат поддержки сначала идет в быструю недорогую модель, а потом при таймауте переключается на более стабильную. Если в отчетах видно, что резерв включается в 18% случаев и при этом средний чек вырос на 40%, это уже не страховка, а лишний расход. В такой ситуации лучше сократить таймаут первой модели, заменить провайдера или совсем убрать один переход.
Для команд в Казахстане и Центральной Азии такую схему удобно проверять через AI Router на airouter.kz: это единый OpenAI-совместимый API-шлюз, где можно держать маршрутизацию в одном эндпоинте, видеть попытки по разным провайдерам и ставить лимиты на уровне ключа. Если у вас уже есть интеграция с OpenAI-совместимым API, обычно достаточно сменить base_url, чтобы прогнать ту же логику без переписывания SDK, кода и промптов.
Если у вас несколько команд или сервисов, задайте для каждой свой предел расходов и свои отчеты. Тогда маркетинговый бот, внутренний поиск и поддержка не будут мешать друг другу. В продакшене лучше работают не самые хитрые схемы, а те, которые легко считать, быстро чинить и спокойно показывать финансистам.
Часто задаваемые вопросы
Что обычно дешевле: retry или fallback?
Обычно дешевле начать с одного retry, если вы видите короткий сетевой сбой или разовый 429/5xx. В этом случае та же модель часто отвечает со второй попытки без лишней смены маршрута.
Fallback имеет смысл, когда проблема тянется у провайдера дольше обычного или модель стабильно не проходит вашу проверку. Не ставьте retry и fallback подряд по умолчанию: так один вопрос легко превращается в две оплаты.
Когда резервную модель лучше вообще не запускать?
Не включайте резерв, если сам запрос уже сломан. Слишком длинный промпт, неверный JSON, пустые обязательные поля, ошибка авторизации или правило безопасности не исчезнут во второй модели.
В такой ситуации вы просто отправите тот же плохой запрос еще раз и получите новый счет. Сначала чините входные данные, потом повторяйте вызов.
Как понять, что первый вызов уже стал платным?
Смотрите на журнал попыток с одним request_id. Если провайдер уже принял запрос и начал обработку, он часто списывает входные токены, даже когда ответ оборвался или не успел прийти к вам.
Если лог показывает, что сбой случился до обработки у провайдера, можно сделать один повтор или один переход на резерв. Если обработка уже стартовала, считайте первую попытку платной и не дублируйте ее без явной причины.
Сколько попыток стоит держать в цепочке?
Для одного пользовательского запроса обычно хватает двух шагов. Первый шаг делает основная модель, второй — либо повтор той же модели при сетевом сбое, либо переход на резерв при провале ответа.
Третий шаг редко окупается. Если после двух попыток ответ все еще плохой, лучше сократить контекст, вернуть короткий шаблон, попросить уточнение или передать кейс человеку.
Какой контекст отправлять в резервную модель?
Во вторую модель отправляйте только то, без чего она не решит задачу. Чаще всего хватает последнего вопроса пользователя, короткого system prompt, нужных фактов и требований к формату ответа.
Не тащите весь лог чата и служебный мусор. Лишний контекст раздувает входные токены и часто провоцирует более длинный ответ, а значит и новый расход.
Когда выбирать дешевый резерв, а когда более сильный?
Берите более дешевую замену, если вам важна доступность и задача простая. Это хорошо работает для кратких ответов, классификации, перефразирования и черновиков.
Ставьте более сильную модель, если первая ломает формат, путает поля или теряет логику на длинном контексте. Там дороже один вызов, но вы экономите на повторах, ручной проверке и переделке.
Как посчитать реальную цену одного запроса с учетом fallback?
Считайте не цену удачной первой попытки, а среднюю цену всех веток, которые реально срабатывают. Удобная форма такая: E = C1 + Pfb × C2 + Prt × Crt, где C1 — первая попытка, Pfb — доля переходов на резерв, C2 — его цена, Prt — доля повторов, Crt — цена повтора.
Берите вероятности из живых логов за несколько недель и отдельно по типам задач. Короткий FAQ и длинный диалог поддержки стоят по-разному даже при одной и той же модели.
Какие ошибки стоит привязать к fallback?
Оставьте короткий набор причин. Обычно хватает таймаута, 429, 5xx, обрыва соединения до ответа и пустого ответа, если ваш код считает его сбоем.
Не отправляйте в резерв запрос только потому, что вам не понравился стиль текста. В таком случае полезнее чинить промпт, схему ответа или проверку результата, а не покупать второй прогон.
Какие метрики помогут не пропустить перерасход в проде?
Каждый день смотрите на долю переходов на резерв, среднюю цену успешного ответа с учетом повторов, время до первого токена и полное время ответа по моделям. Еще полезно держать перед глазами долю пустых, оборванных и слишком длинных ответов.
Если резерв внезапно начал срабатывать заметно чаще нормы, ищите причину сразу. Чаще всего виноваты лимиты провайдера, слишком строгий таймаут или неудачный релиз промпта.
Как снизить расходы на fallback в чате поддержки?
В поддержке лучше ставить недорогую основную модель и включать резерв только по таймауту или явной ошибке API. Для большинства коротких вопросов этого хватает, а счет падает заметно.
Сильнее всего экономит короткий контекст на втором шаге. Если клиент спросил про заказ, не пересылайте резерву всю историю переписки; дайте текущий вопрос, пару последних реплик и данные по заказу.