Извлечение полей из заявлений: OCR, проверка и ручной разбор
Показываем, как настроить извлечение полей из заявлений: выбрать OCR, проверить данные, отправить спорные случаи на ручную проверку и снизить ошибки.
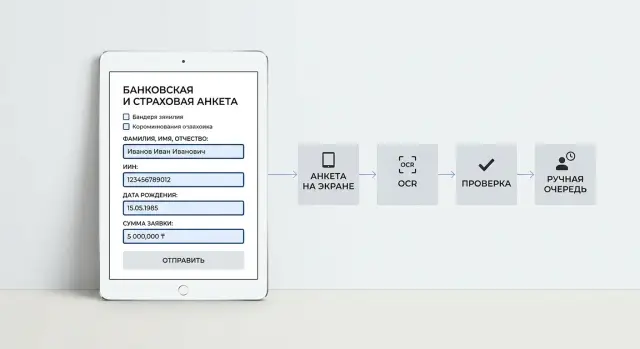
Что ломается в заявлении на практике
Один и тот же бланк почти никогда не приходит в одном виде. Один клиент загружает ровный PDF из личного кабинета, другой присылает скан с полосами от старого МФУ, третий фотографирует лист на кухонном столе вечером. Для системы это уже не "одно заявление", а несколько разных задач с разным качеством входа.
Фото с телефона портит распознавание чаще, чем кажется. Камера ловит блики на ламинированных полях, тени от руки, перекос страницы и смазанный текст по краям. Если документ снят под углом, строки "плывут", а небольшие поля вроде даты выдачи или номера договора OCR читает с ошибками.
Проблема не только в картинке. В заявлениях много символов, которые выглядят почти одинаково: 0 и O, 1 и I, 8 и B, кириллическая "С" и латинская "C". На печатном бланке разница видна, но после сжатия, пересылки в мессенджере или повторного скана она часто исчезает.
Больше всего проблем создают поля, где ошибка даже в одном знаке меняет смысл целиком. В Казахстане это хорошо видно на ИИН. Если OCR перепутал одну цифру, заявка может не найти клиента в базе, не пройти сверку с другой системой или уйти не в ту очередь. Тогда оператор тратит время не на проверку сути заявки, а на поиск места, где все сломалось.
Страдает и сам процесс. Допустим, в страховом заявлении имя распознано нормально, а ИИН содержит одну ошибку. Внешне документ выглядит "почти верным", но система не может связать его с полисом, историей обращений и правилами проверки. Одна цифра останавливает автообработку, заявка зависает, срок ответа растет.
Обычно сбой происходит не в одной точке. Сначала приходит плохое фото, потом OCR добавляет шум, дальше похожие символы ломают одно критичное поле, и уже из-за него рушится весь маршрут.
Какие поля брать в первую очередь
Если вы запускаете извлечение полей из заявлений, не пытайтесь сразу вытащить все, что есть на бланке. На старте хватит 10-15 полей, без которых заявка не может пойти дальше. Так проще снизить число ошибок и быстрее понять, где именно ломаются OCR и правила проверки.
Сначала отделите обязательные поля от тех, которые просто удобно иметь. Обязательные поля участвуют в поиске клиента, проверке личности, сверке с договором и передаче документа в следующую систему. Второстепенные чаще нужны для аналитики, редких сценариев или ручного чтения.
В первой версии обычно хватает такого набора:
- ФИО
- ИИН
- дата рождения
- номер договора или заявки
- дата заполнения
Этого часто достаточно, чтобы найти клиента, проверить формат данных и решить, можно ли двигать документ дальше без человека. Для страхового заявления к этому списку иногда добавляют номер полиса. Для банковской анкеты - телефон, если по нему идет сверка или обратная связь.
Адрес, свободные комментарии, примечания врача, описание случая и длинные текстовые блоки лучше оставить на потом. Они чаще распознаются с шумом, по-разному пишутся и редко влияют на первый шаг маршрута. Команда тратит много времени на их очистку, а пользы в начале мало.
Правило простое: если поле не влияет на решение "принять, отклонить или отправить на ручную проверку", не ставьте его в первую очередь. Сначала соберите короткий набор полей, проверьте точность на реальных сканах и фото, а потом расширяйте схему.
Как собрать процесс по шагам
Рабочее извлечение полей начинается не с OCR, а с аккуратного приема файла. Сервис должен сохранить исходник без изменений, присвоить ему ID и записать базовые данные: канал загрузки, время, тип файла, число страниц. Если позже оператор или аудитор захочет проверить спорный случай, у команды будет точная копия того, что прислал клиент.
Дальше система готовит изображение к чтению. Она выравнивает страницу, убирает лишние поля по краям, правит контраст и, если нужно, делит многостраничный PDF на отдельные листы. На фото с телефона это часто дает больше пользы, чем смена OCR-движка.
Следующий шаг - OCR с координатами. Важно получить не только текст, но и привязку к зоне документа: где стоит фамилия, где номер полиса, где дата. Координаты сильно помогают, когда одно и то же слово встречается в нескольких местах или бланк похож на другой, но поля стоят чуть иначе.
После распознавания система собирает поля. Для стабильных форм обычно хватает шаблонов и правил: взять текст из нужной области, обрезать пробелы, привести дату к одному формату. Для сложных анкет, где люди пишут от руки или ставят данные не туда, подключают модель, которая выбирает нужный фрагмент по контексту.
Потом идут проверки. Система не должна просто вернуть значение, ей нужен понятный статус. Обычно хватает четырех вариантов: "ok", если формат и смысл совпали, "warning", если поле прочиталось, но уверенность низкая, "review", если правила нашли конфликт, и "missing", если поле пустое.
В ручную очередь лучше отправлять не весь документ, а только спорные места. Оператору нужны исходное изображение, подсвеченная зона, текст после OCR, предложенное значение и причина, почему система сомневается. Если в кредитной анкете OCR прочитал ИИН с одной ошибкой, оператор исправит один символ за 10 секунд, а не будет перечитывать весь файл с нуля.
Как выбрать OCR для сканов и фото
Хороший OCR редко выбирают по демо. Для извлечения полей важнее не презентация, а то, как сервис читает ваши документы. Один и тот же OCR может почти без ошибок разбирать чистый PDF и заметно хуже работать на фото анкеты с тенью, синим штампом и полем, заполненным от руки.
Соберите свой тестовый набор заранее. В нем нужны сканы с офисного МФУ, фото с телефона и PDF. PDF тоже лучше делить на два типа: файлы с цифровым текстом и растровые копии. Если смешать все в одну выборку, средняя точность будет выглядеть прилично, а в реальном потоке начнутся сбои.
Что проверять отдельно
Печатный текст и рукописные поля лучше считать разными задачами. Дата рождения, ИИН, номер телефона и номер договора обычно читаются лучше, потому что формат у них жесткий. ФИО от руки, адрес и свободные комментарии дают совсем другой уровень ошибок.
Язык тоже нельзя проверять "в среднем". Для Казахстана мало уверенного русского. Нужны казахский и латиница в одном наборе: имя клиента, адрес, email, марка автомобиля, название компании. Если OCR путает "Ә" и "A" или теряет символ в латинском номере полиса, ошибка уходит дальше по цепочке.
Отдельно замерьте сложные зоны: печати и штампы поверх текста, таблицы с узкими колонками, поля у края страницы, блики, тени, смазанные фото, мелкий шрифт и плохие копии. Смотрите не только на общую точность. Возьмите, например, 200 банковских и страховых заявлений и посчитайте долю документов, где OCR верно прочитал критичные поля целиком. Если сервис ошибается в одном символе ИИН, сумме или дате, такой документ все равно уйдет в ручную проверку.
Если после OCR у вас стоит LLM для нормализации и проверки, не пытайтесь закрыть им слабое распознавание. Модель может поправить формат даты или привести адрес к одному виду, но она не угадает цифры, которых нет в исходном тексте. Сначала нужен OCR, который спокойно держится на ваших сканах, фото и PDF.
Как нормализовать поля после OCR
После OCR текст почти никогда не готов к работе. Система может прочитать одну и ту же дату в трех видах, добавить лишний пробел в ИИН или спутать "0" и "О". На практике нормализация часто влияет на результат сильнее, чем выбор самой OCR-модели.
Частая ошибка - чистить все поля одинаково. Для даты, ИИН, БИН, адреса и ФИО нужны разные правила. Удобно хранить для каждого поля три значения: исходное, очищенное и статус проверки.
Даты приводите к одному формату, обычно YYYY-MM-DD. Если OCR вернул "12.03.24", "12/03/2024" и "12 03 2024", на выходе должна остаться одна запись: "2024-03-12".
Лишние пробелы, разные виды дефисов и случайные символы по краям поля стоит убирать, но без фанатизма. В адресе или номере квартиры лишний символ может оказаться частью данных.
ИИН и БИН лучше проверять по длине и маске до любых следующих шагов. Если в значении не 12 цифр, есть буквы или пропущен символ, поле стоит сразу пометить как ошибочное.
ФИО делите на части только по явному правилу. Если в форме есть отдельные ячейки для фамилии, имени и отчества, разделение безопасно. Если OCR вернул одну строку без четких границ, лучше сохранить полное имя целиком.
Исходное значение нужно хранить рядом с очищенным. Оператору на ручной проверке важно видеть, что пришло из документа и что изменила нормализация. Иначе спорные случаи разбираются дольше, а ошибки трудно объяснить на аудите.
Например, на страховом бланке OCR может вернуть ИИН как "940101-300123 " и дату как "1 2.0 3.2024". Нормализатор уберет мусор, проверит формат, сохранит raw-значение и передаст дальше только то, чему можно доверять.
Как ставить проверки до ручной очереди
Ручная очередь быстро разрастается, если отправлять туда все подряд. Лучше отсеивать простые случаи раньше: пустые поля, явные опечатки, нестыковки между листами и слабое распознавание. Тогда оператор смотрит только то, что правда нельзя решить автоматически.
Сначала проверьте обязательные поля. Если в заявлении нет ИИН, номера полиса, суммы или даты подачи, системе не нужно гадать. Такой документ сразу получает статус на уточнение или ручной разбор. Простое правило, но шума оно снимает много.
Потом сверяйте связанные значения. В страховом бланке сумма покрытия на первом листе должна совпадать с суммой в приложении. В кредитной анкете дата рождения не должна отличаться между заявлением и сканом удостоверения. Даже одна цифра разницы чаще говорит не о сложном случае, а об ошибке OCR или плохом фото.
Полезно хранить уверенность OCR на двух уровнях: по слову и по полю. Если модель не уверена в одной букве в фамилии, это терпимо. Если весь ИИН собран из фрагментов с низкой уверенностью, документ лучше не пропускать дальше без проверки.
Хорошо работают и простые формальные тесты. Даты проверяйте регулярным выражением и здравым смыслом, суммы сверяйте с допустимым диапазоном, ИИН, БИН и номера договоров гоняйте по шаблонам, названия страховщиков, банков и филиалов сравнивайте со справочником, а пустые или слишком короткие значения помечайте сразу.
После этого считайте общий риск заявки. Вместо одного бинарного флага удобнее дать баллы за каждый сбой: 40 за пустой ИИН, 25 за расхождение сумм, 15 за низкую уверенность OCR, 10 за странную дату. Если итог выше порога, документ идет в ручную очередь. Такой подход проще настраивать и объяснять команде.
Как устроить ручную проверку без хаоса
Ручная очередь нужна не для того, чтобы оператор перепечатывал весь бланк. Она нужна там, где система сомневается: OCR плохо прочитал ИИН, подпись закрыла дату, сумма не прошла проверку по формату. Если отправлять человеку весь документ, команда быстро увязнет в однотипной работе.
Хороший экран проверки показывает только спорные поля. Оператору нужны распознанное значение, оценка уверенности и небольшой фрагмент страницы рядом с полем. Когда человек сразу видит нужный кусок анкеты, он исправляет поле за несколько секунд и не листает весь PDF.
На кредитной заявке это выглядит просто. Система уверена в ФИО и дате рождения, но сомневается в телефоне и ИИН. В очередь уходят только эти два поля. Со страховым бланком логика та же: если номер полиса считался нормально, а дата события распознана с ошибкой, оператор открывает только дату и видит участок страницы с этим блоком.
Не просите людей вводить документ заново. Полная перепечатка редко помогает и чаще маскирует проблему в OCR, шаблоне формы или правилах валидации. Чем уже задача у оператора, тем меньше новых ошибок.
Полезно сохранять не только исправленное значение, но и причину правки. Обычно хватает нескольких коротких меток: "неверно распознан символ", "поле закрыто печатью или подписью", "фото смазано", "клиент заполнил поле нестандартно", "правило валидации слишком жесткое". По этим меткам быстро видно, что чинить дальше: модель, предобработку изображения или бизнес-правило.
У каждой задачи должен быть простой статус и срок ответа. Часто хватает трех статусов: "новая", "в работе", "готово". Для банковской анкеты можно ставить ответ за 15 минут, для страхового заявления - за 2 часа. Тогда очередь не расползается, а команда понимает, что делать прямо сейчас.
Пример с кредитной заявкой и страховым бланком
Клиент отправил фото кредитной анкеты с телефона и отдельно приложил паспорт. В другом случае страховой бланк пришел как скан из отделения. Оба документа попали в один поток, где обработка идет по одной схеме: OCR, нормализация, проверки и только потом ручная очередь.
OCR сразу вытащил ФИО и ИИН. С номером телефона все пошло хуже: на фото анкеты был блик, и одна цифра просто пропала. Если пустить такую заявку дальше без проверки, колл-центр не дозвонится, а клиенту придется заполнять форму заново.
Дата рождения дала еще один сигнал. На первом листе анкеты стояло 14.03.1989, а в приложенном документе система увидела 13.03.1989. Тут гадать не стоит. Правило сравнения полей пометило расхождение и отправило оператору только этот пакет, а не всю партию заявок за день.
Оператор открыл карточку и увидел не весь документ целиком, а только спорные места: телефон, дату рождения и обрезки строк, из которых OCR взял значения. Это заметно ускоряет ручную проверку. Человек не перепечатывает анкету с нуля, а правит два поля и сразу подтверждает результат.
После правки заявка уходит дальше по обычному маршруту: скоринг, проверка лимитов, создание записи в CRM или страховой системе. Повторный ввод не нужен. И это важно. Когда команда убирает лишнее ручное копирование, она теряет меньше времени и реже ловит новые ошибки уже после исправления.
Нормальный рабочий сценарий выглядит так: машина забирает все, что читает уверенно, правила ловят противоречия, а человек смотрит только сомнительные случаи. Тогда валидация данных не тормозит поток и не превращает каждую заявку в ручной разбор.
Где команды чаще всего ошибаются
Команды редко спотыкаются об один большой сбой. Обычно процесс ломают несколько мелких решений, которые на старте кажутся разумными.
Первая ошибка - попытка тянуть из заявления все поля сразу. Это выглядит как запас на будущее, но на деле растит сложность. Если банку для первого решения нужны ФИО, ИИН, номер телефона, сумма и дата, не надо в тот же спринт доставать адрес регистрации, семейное положение, место работы и десятки вторичных полей. Жадность на старте почти всегда дает больше шума, чем пользы.
Вторая ошибка - отсутствие эталонного набора документов. Без него споры о качестве идут по кругу. Один человек говорит, что OCR слабый, другой винит правила, третий считает, что проблема в плохом скане. Проверить это нечем. Нужен небольшой, но честный набор: хорошие PDF, смятые фото, тени, обрезанные страницы, старые версии бланков, рукописные пометки.
Измерения тоже лучше разделить сразу. Отдельно считайте точность распознавания текста, отдельно - разбор полей по правилам, отдельно - то, что уходит в ручную очередь, и отдельно - итоговую долю документов без ошибок. Иначе одна красивая цифра скроет слабое место.
Третья ошибка бьет по бюджету. Команда считает цену OCR и забывает цену ручной проверки. А потом выясняется, что даже 5% спорных заявлений дают сотни карточек в день. Если один оператор тратит по 3 минуты на документ, очередь начинает стоить заметно больше, чем сам автоматический слой.
Еще одна частая проблема связана с версиями. Формы меняются, OCR-модель обновляют, правила нормализации правят по ходу работы. Если не хранить версии шаблонов, моделей и правил, команда не понимает, почему вчера поле "дата выдачи" читалось нормально, а сегодня просело на 12%.
Для страховых и банковских анкет это особенно важно. Один новый шаблон от филиала, одно изменение в порядке полей, и метрики съезжают. Если у вас уже есть audit-логи и строгая трассировка шагов, разбор занимает часы. Если этого нет, проблема тянется неделями.
Короткий список проверок перед запуском
Перед пилотом полезно остановиться на день и проверить базовые вещи. Большая часть сбоев появляется не в модели, а в данных, очередях и неясных правилах, когда документ уходит человеку.
Соберите реальные примеры по каждому виду формы. Не пять идеальных PDF, а живую выборку: мятые сканы, фото с телефона, бланки старых версий, частично заполненные анкеты. Если для одного типа формы нет примеров, система почти наверняка начнет путать поля уже в первую неделю.
Посчитайте долю входящих форматов. Фото, сканы и PDF ведут себя по-разному. Если 60% потока приходит как фото, а вы тестировали в основном PDF, OCR для анкет покажет красивую демо-точность и слабый результат в работе.
Зафиксируйте пороги уверенности заранее. Для каждого поля решите, где система принимает значение сама, а где отправляет документ на ручную проверку. Причины эскалации тоже стоит назвать прямо: низкая уверенность, конфликт дат, пустой обязательный блок, странный ИИН, плохое качество изображения.
Проверьте, видите ли вы метрики по всему пути документа. Нужны хотя бы время обработки, доля ручного разбора, процент документов с ошибками валидации и список самых частых причин возврата. Без этого вы не поймете, что именно ломает извлечение полей.
Подготовьте план исправлений на первые частые ошибки. Например, если OCR регулярно путает 0 и О в номере полиса, команда должна заранее понимать, кто и как меняет правило: аналитик, инженер или оператор. Хорошо работает короткий цикл: утром нашли ошибку, днем поправили правило или словарь, вечером проверили новую выборку.
Один простой тест многое показывает. Возьмите 100 документов из реального потока и посмотрите, сколько заявлений дошло без ручного вмешательства, сколько ушло в очередь и сколько вернулось с неверными полями. После такого прогона слабые места видны сразу.
Что делать дальше
Не пытайтесь сразу автоматизировать все формы. Начните с одного типа заявления и малого набора полей, без которых процесс не двигается: ИИН, ФИО, дата рождения, номер договора, сумма, дата подачи. Так проще увидеть, где именно все ломается: на качестве фото, на OCR, на нормализации или на проверках.
Одна общая цифра точности почти ничего не говорит. Гораздо полезнее смотреть на этапы отдельно: сколько символов OCR читает без ошибок, какая точность у каждого поля, какой процент заявлений проходит без оператора, сколько документов уходит в ручную очередь и сколько времени сотрудник тратит на исправления. Такой разрез быстро показывает слабое место. OCR может читать бланк нормально, а валидация будет часто резать адреса из-за слишком жестких правил.
С правилами лучше не усложнять. Для дат, ИИН, номеров полисов, сумм и кодов обычно хватает шаблонов, словарей и простых проверок. LLM нужен там, где текст пишут свободно: описание страхового случая, цель кредита, комментарий клиента, нестандартный адрес. Если поле можно проверить регулярным выражением и справочником, так и делайте. Это дешевле и понятнее при разборе ошибок.
Если команда сравнивает модели разных провайдеров или обязана хранить данные в Казахстане, удобен единый слой доступа вроде AI Router. Сервис дает один OpenAI-совместимый эндпоинт для работы с моделями разных провайдеров без смены SDK, кода и промптов. Для задач, где важны data residency и низкая задержка, у airouter.kz есть и hosted open-weight модели на собственной GPU-инфраструктуре в Казахстане.
После пилота не откладывайте базовый контроль. Добавьте аудит-логи, маскирование PII и лимиты на уровне ключа. На демо без этого часто закрывают глаза, но в рабочем процессе такие пропуски потом обходятся дороже, чем сам запуск.
Если через пару недель команда не может назвать три поля с самой низкой точностью и долю заявлений, которые уходят на ручную проверку, систему еще рано расширять.