Хранение данных в стране для LLM: локально, гибрид или API
Хранение данных в стране для LLM помогает сравнить локальный хостинг, гибридный контур и внешний API по рискам, цене и срокам запуска.
Почему этот выбор сложен
Проблема почти никогда не сводится к вопросу, где именно запустить модель. В LLM-системе данные живут в разных местах: отдельно хранятся запросы пользователей, ответы модели, файлы для RAG, embeddings, системные логи, аудит-записи и резервные копии. Даже если сама модель работает внутри страны, вложения или телеметрия могут уходить во внешний сервис. Поэтому схему легко недооценить: на диаграмме все выглядит аккуратно, а в реальной архитектуре следы данных расходятся в стороны.
У каждой команды свой взгляд на риск. Юристу нужен понятный ответ на вопрос, где лежат данные и кто их обрабатывает. Команда ИБ смотрит глубже: как маскируются персональные данные, кто видит логи, где хранятся трассировки и аудит. Продуктовая команда думает о другом: сколько времени займет запуск, сколько людей придется отвлечь и что начнет ломаться при первой нормальной нагрузке.
Обычно спор упирается в несколько простых вещей: где физически лежат данные, логи и файлы; кто отвечает за доступ, журналирование и удаление; сколько стоит не только запуск, но и сопровождение; как быстро можно выйти в продакшен без ручных обходов.
Из-за этого один и тот же сценарий приводит к разным решениям. Бот для ответов на общие вопросы компании часто можно быстро запустить через внешний API, если в запросах нет чувствительных данных. Внутренний помощник для банка, который видит заявки клиентов, переписку и документы, почти всегда требует более строгого контура. Если в начале выбрать слишком свободную схему, потом придется заново собирать маршруты данных, логику доступа, согласования и перенос накопленных данных.
Цена ошибки заметна не сразу. На старте внешний API кажется самым быстрым вариантом, локальный хостинг LLM - самым контролируемым, а гибридный контур LLM - разумной серединой. Через несколько месяцев обычно выясняется, что основные расходы сидят в логах, правилах хранения, поддержке GPU, отказоустойчивости и проверках со стороны ИБ. Выбор сложен не из-за моды на архитектуру, а потому что бизнес, безопасность и разработка по-разному платят за одну и ту же ошибку.
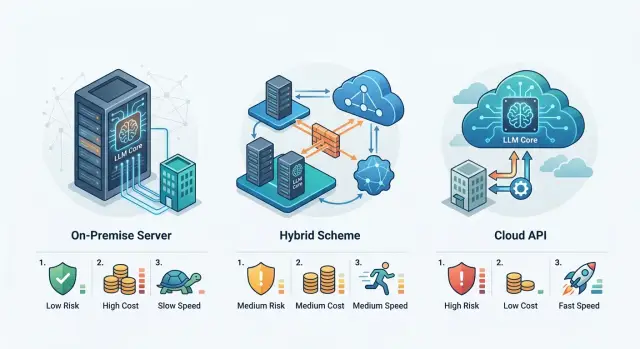
Три подхода без сложных слов
Спор обычно идет не о самой модели, а о том, где живут данные, логи и настройки доступа. От этого сразу меняются риски, бюджет и срок, за который команда покажет рабочий результат.
Локальный хостинг LLM означает, что модель, журналы, векторная база и служебные сервисы работают внутри вашего контура. Такой вариант чаще выбирают там, где нельзя выпускать наружу тексты клиентов, внутренние документы или персональные данные. Плюс очевидный: контроль высокий. Минус тоже понятный: железо, поддержка, обновления моделей и отказоустойчивость ложатся на вашу команду.
Гибридный контур LLM - это разделение по чувствительности. Внутри остаются логи, правила доступа и чувствительные данные. До вызова модели система маскирует PII, а наружу уходит только безопасная часть запроса или те сценарии, где нужна более сильная модель. Такой подход часто выбирают команды, которым нужен контроль, но не хочется строить весь стек с нуля.
Внешний API для LLM - самый быстрый путь к запуску. Команда получает доступ к моделям без своей GPU-инфраструктуры и подключает его прямо в продукт. Это удобно для пилота, для быстрой проверки сценария и для случаев, когда нескольким командам нужен общий доступ сразу. Ограничения тоже видны быстро: меньше контроля над тем, где проходит обработка, как долго хранятся логи и какие условия придется согласовывать с безопасностью.
Одного правильного ответа здесь нет. Если на первом месте контроль и локальные требования, чаще побеждает свой контур. Если важнее срок запуска, внешний API обычно быстрее. Гибрид выбирают там, где нужно не спорить между крайностями, а разделить данные по уровню чувствительности.
Есть три вопроса, которые быстро отрезвляют любую дискуссию. Кто держит данные у себя? Кто платит за инфраструктуру каждый месяц? И сколько времени пройдет до первого запуска в продакшен? Ответы на них обычно сразу показывают, какой вариант ближе именно вам.
Где растут риски
Риск начинается не там, где стоит сервер, а там, где остается след запроса. Команда часто смотрит только на сам вызов модели и забывает про промпты, ответы, сервисные логи и вложения. Если сотрудник загружает PDF, а система пишет отладочный лог во внешний сервис, данные уже вышли за пределы нужного контура.
Утечка и простой - разные проблемы. Утечка бьет по персональным данным, репутации и проверкам. Простой бьет по работе продукта: чат не отвечает, лимиты закончились, провайдер поменял правила, внешний трафик режется, модель внезапно стала недоступна. Локальный хостинг обычно снижает зависимость от внешнего провайдера, но добавляет другой набор рисков: команда сама отвечает за GPU, обновления, резерв и ночные сбои.
Где чаще всего ошибаются
Самый частый промах связан с PII. Нужно заранее решить, кто маскирует персональные данные до отправки запроса. Если это делает внешний провайдер после того, как получил текст, граница уже пройдена. Для банка, клиники или гос-сервиса это слабое место. Надежнее, когда приложение или шлюз внутри страны скрывает ИИН, номер карты, телефон и адрес еще до вызова модели, а расшифровку хранит отдельно.
Вторая зона риска - зависимость от одного провайдера и одной модели. Сначала это кажется удобным: меньше настроек, проще тест. Потом растет цена, меняется политика по данным или качество на вашем сценарии падает, и продукт зависает в неудобной точке. Гибридный контур дает запасной маршрут: чувствительные запросы остаются внутри страны, а менее критичные можно отправлять во внешний API. Помогает и совместимый шлюз, который умеет вести запросы к разным провайдерам через один эндпоинт.
Что проверить по требованиям
Отдельно проверьте аудит-логи и метки контента. Закон и внутренние правила часто требуют видеть, кто отправил запрос, когда это произошло, какая модель ответила, что скрыла система и какой текст ушел пользователю. Если эти записи хранятся в другой стране или собираются не полностью, проблема всплывет не в день запуска, а во время аудита или разбора инцидента.
На практике слабое место часто не в самой модели. Обычно подводят забытые логи, вложения в объектном хранилище и маскирование PII, которое сделали слишком поздно.
Из чего складывается цена
Если смотреть только на цену за 1 млн токенов, картина почти всегда получается слишком оптимистичной. У LLM-систем расходы идут сразу по нескольким линиям: модель, железо, инженерная поддержка, мониторинг, разбор сбоев и время команды, когда что-то ломается или тормозит.
У локального хостинга самый заметный минус простой: деньги нужны заранее. Нужно купить или арендовать GPU, поднять инфраструктуру, настроить сети, мониторинг, резервирование, журналы, защиту данных и дежурство команды. Даже если в первый месяц у вас всего 200 запросов в день, счет уже идет.
Обычно бюджет складывается из пяти частей:
- вычисления: GPU, CPU, память и хранение;
- инженерная работа: DevOps, ML, backend и безопасность;
- операционные расходы: мониторинг, логи, алерты и резервные копии;
- сопровождение: обновления моделей, тесты и разбор сбоев;
- ручная работа и простой: время людей, когда процесс не автоматизирован.
Гибридный контур выглядит как компромисс, но у него своя цена. Часть запросов идет во внешний API, часть остается внутри страны, а кто-то должен решать, куда отправить каждый запрос. Значит, появляются расходы на маршрутизацию, правила по типам данных, маскирование PII, аудит-логи и постоянную проверку, что чувствительные данные не ушли не туда. Схема удобная, но сама по себе дешевой не становится.
Внешний API обычно выигрывает на старте. Пилот можно собрать быстро, без закупки GPU и без долгой настройки. Но затем счет растет вместе с трафиком. Если продукт вышел в продакшен, пользователей стало больше, ответы стали длиннее, а повторных запросов прибавилось, переменная часть бюджета начинает ощутимо давить. Особенно быстро это видно в тех командах, где сотрудники обращаются к помощнику весь день, а не пару раз в неделю.
Есть и расход, который редко видно в таблице. Если инженеры вручную перебрасывают запросы между моделями, чистят персональные данные перед отправкой или разбирают инциденты без нормальных логов, бизнес платит не только деньгами, но и временем. Час инженера и час простоя поддержки часто обходятся дороже, чем экономия на токенах.
Для компаний в Казахстане отдельный вопрос - как не умножать расходы из-за лишнего слоя интеграций. В таком случае помогает единый совместимый API-шлюз. Например, AI Router дает один OpenAI-совместимый эндпоинт для внешних и локально размещенных моделей, не требует переписывать SDK и код, а B2B-инвойсинг идет ежемесячно в тенге. Сам по себе такой слой не делает проект дешевым, но расходы и контроль становятся понятнее.
Как меняется скорость запуска
Срок запуска обычно упирается не в саму модель, а в число решений, которые команда должна принять до первого запроса в продакшене. Чем больше требований к данным, безопасности и инфраструктуре, тем длиннее путь от идеи до рабочего сценария.
Внешний API почти всегда дает самый быстрый старт. Если компании можно отправлять данные во внешний контур, пилот часто собирают за несколько дней: разработчик подключает готовый API, тестирует промпты и быстро получает первые ответы. Еще проще, если у команды уже есть совместимый стек. В AI Router, например, можно заменить base_url на api.airouter.kz и продолжить использовать те же SDK, код и промпты.
Но быстрый старт не означает, что можно сразу запускать все. Быстрее всего идет один понятный сценарий: внутренний помощник по базе знаний, разбор обращений или черновики ответов оператору. Если пытаться одновременно строить полную платформу с ролями, логированием, оценкой качества и несколькими моделями, даже внешний API не спасет от задержек.
Где время уходит в гибридном контуре
Гибрид стартует медленнее, потому что сначала команде нужно договориться, какие данные можно отправлять наружу, а какие нельзя. Затем приходится описывать правила маршрутизации: какие запросы идут во внешний API, какие остаются внутри страны, где маскируется PII и где хранятся логи.
Обычно сроки тормозит не код и не сама модель, а согласование между ИБ, юристами и продуктовой командой. Пока они не утвердят схему данных и правила обработки, разработчики просто ждут.
Чаще всего время уходит на карту данных по каждому сценарию, правила маскирования персональных данных, выбор моделей для внешнего и внутреннего контура, а также на аудит-логи и лимиты доступа.
Локальный хостинг тянет время сильнее всех. Даже если команда уже выбрала модель, ей нужно пройти закупку или выделение GPU, поднять инфраструктуру, настроить мониторинг и протестировать нагрузку и отказоустойчивость. После этого начинаются прикладные тесты: качество ответов, задержка, стоимость на один запрос и поведение на пике.
Для банка разница выглядит просто. Пилот помощника для сотрудников через внешний API можно показать через несколько дней. Гибридный вариант часто занимает недели, потому что нужно разделить открытые и чувствительные запросы. Полностью локальный запуск растягивается еще сильнее, если инфраструктуру готовят с нуля.
Если нужен быстрый результат, лучше выбрать один сценарий и довести его до рабочего состояния. Расширять контур потом проще, чем строить все сразу.
Как выбрать подход по шагам
Выбор между локальным размещением, гибридом и внешним API лучше начинать не с моделей, а с ограничений. Для многих команд хранение данных в стране для LLM - не опция, а правило, поэтому красивый демо-сценарий сам по себе ничего не решает.
-
Сначала составьте короткий список данных, которые нельзя отправлять за пределы вашего контура. Обычно туда попадают ФИО, ИИН, номера договоров, медицинские записи, тексты жалоб и внутренние документы.
-
Затем разделите сценарии на две группы: чувствительные и обычные. Поиск по внутренней базе знаний или разбор клиентских обращений чаще тянут к локальному хостингу или гибридной схеме. Черновики писем и суммаризация открытых материалов нередко можно отдать внешнему API.
-
После этого задайте два числа: потолок цены за запрос и допустимую задержку. Если ответ нужен за 2-3 секунды, а бюджет жесткий, полный локальный контур может выйти дороже, чем кажется в начале. Если задержка не так важна, зато нужен полный контроль, локальный вариант выглядит лучше.
-
Отдельно решите, насколько вам нужен контроль над логами, выбором моделей и дообучением. Если команда должна хранить аудит, маскировать PII и сама выбирать модель под каждый тип запроса, гибрид часто дает больше свободы, чем внешний API.
-
Не пытайтесь сразу охватить все процессы. Возьмите один понятный сценарий, запустите пилот и через месяц пересчитайте факты: цену, задержку, долю ошибок и нагрузку на команду.
Через месяц картина почти всегда меняется. Иногда внешний API спокойно закрывает половину задач без лишних затрат, а чувствительные запросы проще оставить внутри страны через локальные модели или через шлюз с хранением данных в Казахстане, если этого требуют ваши правила.
Пример для банка с внутренним помощником
Банку редко нужен полный локальный кластер с первого дня. Чаще он запускает внутреннего помощника для сотрудников: они спрашивают про регламенты, сроки, лимиты согласования и просят собрать ответ клиенту по готовому шаблону. Здесь все начинается не с большой закупки серверов, а с нормальной сортировки запросов.
Если сотрудник вставляет номер договора, ИИН, телефон или детали заявки, такой запрос лучше оставить внутри страны. Локальная модель находит нужный регламент, достает фрагменты из базы знаний и готовит черновик ответа. Банк не выносит персональные данные наружу и сохраняет аудит-лог по каждому обращению.
Но часть работы не требует такого режима. Допустим, система уже убрала чувствительные поля и оставила только смысл письма: клиент просит изменить дату платежа, а сотруднику нужен вежливый и понятный ответ. Такой черновик можно отправить во внешний API, если банку нужна более сильная модель для стиля, краткого резюме или перефразирования.
Именно поэтому гибридный контур часто дает самый быстрый практичный старт. Банк держит локально сценарии с договорами, персональными данными и внутренними правилами, а обезличенные черновики отправляет наружу. Не нужно сразу строить большой парк GPU и ждать месяцы до запуска. Если у команды уже есть OpenAI-совместимая интеграция, переход обычно проще: меняется endpoint, а код и промпты почти не трогают.
После пилота решение становится намного яснее. Команда видит, какие запросы приходят каждый день, где растет задержка, какие сценарии чаще содержат персональные данные и сколько стоит каждый маршрут. После этого банк оставляет локально постоянные задачи, вроде поиска по регламентам и ответов по договорам, а остальное распределяет по цене и качеству.
Частые ошибки при выборе
Когда компания выбирает подход к хранению данных для LLM, она часто начинает не с расчета, а со страха. Самая частая ошибка проста: команда сразу уходит в локальный хостинг, потому что так спокойнее. Но если запросов пока мало, сценарий один, а модель меняется редко, свой контур может оказаться дорогим и медленным решением.
Локальное размещение имеет смысл, когда нагрузка понятна, требования по резидентности данных уже зафиксированы, а команда готова поддерживать инфраструктуру каждый день. Если этого нет, серверы быстро превращаются в дорогой запас на будущее.
Вторая ошибка - смотреть только на цену токенов. Внешний API иногда кажется дорогим, а локальный контур - дешевым после покупки GPU. На практике расходы растут в других местах: дежурства, обновления моделей, мониторинг, аудит-логи, лимиты по ключам, маскирование PII и отказоустойчивость. Если это не посчитать заранее, сравнение получится ложным.
Еще один частый промах - не разделить данные по чувствительности до старта. Команда обсуждает все данные компании как один массив и пытается найти один ответ на все случаи. Так почти всегда появляется лишняя сложность. Гораздо полезнее сразу выделить хотя бы три группы: публичные тексты, внутренние документы и данные с персональной или банковской тайной. После этого часть задач можно спокойно оставить во внешнем API, а часть отправить в локальный или гибридный контур.
Многие забывают проверить, где лежат логи и кто видит промпты. Это касается не только основного трафика, но и отладочных записей, трассировки, кеша и выгрузок для команды поддержки. Бывает так: сами данные хранятся внутри страны, а логи с фрагментами запросов уходят во внешний сервис. На схеме все выглядит безопасно, а слабое место уже есть.
Последняя ошибка встречается почти в каждом первом проекте: компания пытается перенести все сценарии сразу в один контур. Это почти всегда слишком дорого. Намного дешевле начать с одного процесса, где риск понятен и эффект можно посчитать, например с внутреннего помощника для сотрудников без доступа к самым чувствительным данным.
Короткий список проверок
Перед выбором схемы не спорьте о локальном размещении и облаке в отрыве от деталей. Обычно хватает пяти проверок: где остаются данные, кто чистит чувствительные поля, сколько длится путь до пилота, как вы смените поставщика моделей и кто держит контрольные функции в своих руках.
Сначала разложите данные по типам. У многих команд промпты хранятся в одном месте, ответы в другом, логи в третьем, а вложения уходят в отдельное хранилище. Если это не описать заранее, потом легко получить неприятный сюрприз: модель стоит в локальном контуре, а вложения или трассировка запросов живут вне страны.
Дальше проверьте, кто именно маскирует PII до отправки запроса. Это не мелочь. Если маскирование делает только внешний провайдер, чувствительные данные уже покинули ваш контур. Безопаснее, когда очистка происходит до вызова модели, на вашей стороне или в доверенном шлюзе.
Полезно сверить такой список:
- где физически лежат промпты, ответы, логи и файлы после обработки;
- кто удаляет или маскирует PII до первого сетевого запроса;
- сколько дней команда реально потратит на пилот и сколько еще уйдет на продакшен;
- можно ли сменить провайдера моделей без переписывания SDK, промптов и бизнес-логики;
- кто отвечает за аудит, лимиты запросов и метки контента по требованиям закона.
Сроки тоже стоит считать честно. Внешний API часто дает пилот за несколько дней, гибридный контур может занять недели, а локальный хостинг нередко растягивается еще дольше из-за закупки GPU, доступа, логирования и проверок безопасности.
Отдельно посмотрите на смену провайдера. Если интеграция жестко привязана к одному API, команда потом заплатит временем. Практичнее держать слой совместимости. Для команд в Казахстане таким слоем может быть AI Router: один OpenAI-совместимый эндпоинт для 500+ моделей от 68+ провайдеров и локально размещенных open-weight моделей, с хранением данных внутри страны, маскированием PII, аудит-логами, метками контента и лимитами на уровне ключа. Это не снимает архитектурные решения, но упрощает смену маршрута без переделки приложения.
Если на все пять пунктов есть ясный ответ, владелец процесса и срок, решение уже похоже на рабочую схему, а не на красивую презентацию.
Что делать после выбора
После решения не стоит сразу раскатывать систему на весь бизнес. Сначала нужен один живой сценарий с понятной пользой: внутренний помощник для сотрудников, поиск по базе знаний или разбор обращений. Один пилот почти всегда лучше, чем три параллельных проекта.
Для темы хранения данных в стране это особенно полезно. На встречах риски часто обсуждают слишком абстрактно, а пилот быстро показывает, где проблема на самом деле: в задержке, в цене, в доступе к данным или в требованиях ИБ.
Сначала пилот и базовые цифры
До запуска зафиксируйте базу, иначе через месяц команда будет спорить по ощущениям. Снимайте цифры на одном и том же наборе задач, а не на случайных примерах.
- средняя задержка и p95;
- цена одного запроса и цена на 1000 задач;
- доля ответов, которые проходят ручную проверку;
- сколько запросов содержат PII и как система их маскирует;
- сколько раз срабатывают лимиты, таймауты и отказы.
Сразу оставьте путь для смены модели и провайдера. Если приложение жестко привязано к одному API, потом любая миграция превращается в лишние недели работы. Проще заложить слой совместимости с самого начала.
Зафиксируйте правила до продакшена
Если закон требует хранить данные в Казахстане, не спорьте о подходе в теории. Прогоните один и тот же сценарий в двух вариантах: внешний маршрут с нужными ограничениями и локальный хостинг open-weight моделей внутри страны. Тогда вы увидите не только разницу в рисках, но и разницу в качестве, задержке и цене поддержки.
До продакшена команде нужны простые письменные правила: что считается PII и где оно маскируется, какие аудит-логи вы храните и кто имеет к ним доступ, какие лимиты стоят на уровне ключа, команды и сервиса, а также какие данные можно отправлять во внешний контур, а какие нельзя.
Еще один практичный шаг - заранее договориться о плане отката. Если модель начинает ошибаться после обновления, команда должна за минуты вернуть прошлый маршрут, прошлую модель или прошлые лимиты. Скучная часть работы, но именно она часто спасает запуск LLM в продакшен, когда пилот превращается в реальную нагрузку.
Часто задаваемые вопросы
Когда без локального размещения LLM не обойтись?
Локальный вариант берите, если запросы содержат ИИН, номера договоров, медданные, тексты жалоб или внутренние документы. Он подходит и тогда, когда ваши правила требуют хранить данные, логи и аудит внутри страны.
Платите за это временем и поддержкой: команде нужны GPU, мониторинг, резерв и дежурство.
В каких случаях можно спокойно выбрать внешний API?
Внешний API обычно подходит для пилота, черновиков, суммаризации открытых материалов и сценариев без чувствительных данных. Если команде нужен результат за несколько дней, это часто лучший старт.
Но сначала проверьте, где провайдер хранит промпты, ответы и логи. Иначе быстрый запуск потом упрется в согласования с ИБ и юристами.
Что на практике решает гибридный контур?
Гибрид полезен, когда часть запросов нельзя выпускать наружу, а часть можно. Например, регламенты, договоры и PII остаются внутри страны, а обезличенные черновики или перефразирование уходят во внешний API.
Так вы не строите весь стек с нуля и не отдаете наружу все подряд. Но вам все равно нужны ясные правила маршрутизации и маскирования.
Где чаще всего теряют контроль над данными?
Обычно команды забывают не про модель, а про следы вокруг нее. Чаще всего наружу уезжают отладочные логи, трассировки, вложения, кеш и выгрузки для поддержки.
Проверьте всю цепочку: промпт, ответ, файл, лог, резервную копию. Один внешний сервис в этой цепочке уже ломает нужный контур.
Кто должен маскировать PII до вызова модели?
Маскирование делайте до первого сетевого запроса, на своей стороне или в доверенном шлюзе внутри страны. Если внешний провайдер скрывает PII после получения текста, данные уже вышли за ваш контур.
На старте достаточно закрыть ИИН, номер карты, телефон, адрес и номера договоров. Расшифровку храните отдельно.
Что обычно дешевле: свой контур или внешний API?
Если запросов мало и сценарий один, внешний API часто дешевле в начале. Вам не нужно сразу платить за GPU, настройку инфраструктуры и постоянную поддержку.
Когда трафик растет, расходы смещаются. У локального варианта дорожают железо, мониторинг и дежурства, у внешнего API — токены и длинные ответы. Считайте не только модель, но и логи, аварии и время инженеров.
Какой вариант быстрее всего довести до пилота?
Быстрее всего стартует внешний API, если правила компании разрешают такой маршрут. Простой пилот часто собирают за несколько дней.
Гибрид занимает больше времени из-за карты данных, правил маршрутизации и согласований. Локальный запуск тянется дольше всех, потому что нужно поднять инфраструктуру и проверить нагрузку.
Как снизить зависимость от одного провайдера?
Не шейте приложение намертво к одному API и одной модели. Держите совместимый слой между продуктом и провайдерами, чтобы менять маршрут без переписывания кода и промптов.
Сразу проверьте, как вы переключите модель, где храните логи и кто меняет лимиты. Тогда рост цены или сбой у одного провайдера не остановят продукт.
С чего банку лучше начать внедрение LLM?
Начните с одного сценария, где польза видна быстро. Для банка это часто внутренний помощник по регламентам и шаблонам ответов, а не полный локальный кластер с первого дня.
Разделите запросы заранее: с PII и договорами оставьте внутри страны, обезличенные задачи можно вынести наружу. Такой старт дает факты вместо споров.
Что проверить на пилоте перед выходом в продакшен?
Снимайте среднюю задержку и p95, цену одного запроса, долю ответов после ручной проверки, число запросов с PII и частоту таймаутов или отказов. Смотрите эти цифры на одном наборе задач, а не на случайных примерах.
Еще до продакшена зафиксируйте правила: что считается PII, где вы его скрываете, какие логи храните и как откатываете модель или маршрут после неудачного обновления.