Очередь ручной проверки без бэклога: как настроить SLA
Очередь ручной проверки не должна расти сама по себе. Разберем приоритеты кейсов, SLA, правила эскалации и удобный интерфейс разметчика.
Почему ручная проверка быстро уходит в минус
Очередь ручной проверки редко ломается из-за одного большого сбоя. Чаще она проседает постепенно, при внешне нормальном потоке задач. Входящих кейсов не стало больше, но у команды стало меньше реального времени на каждый кейс.
Так происходит, когда в очередь попадает слишком много однотипных и слабых сигналов. Часть задач дублируется, часть приходит без контекста, часть вообще не требует участия человека. Оператор тратит минуты не на решение, а на то, чтобы понять, зачем кейс вообще открыли.
Обычно очередь раздувают не самые сложные случаи, а мелкие потери на каждом шаге: повторные эскалации одного инцидента, ложные срабатывания правил и моделей, кейсы без истории или причины флага, ручная проверка там, где риск почти нулевой, постоянное переключение между разными типами задач. По отдельности это выглядит терпимо. Вместе съедает смену.
Даже лишние 20-30 секунд на один кейс быстро превращаются в бэклог. Еще хуже, когда все задачи выглядят одинаково. Срочная жалоба клиента, спорный ответ модели и почти очевидный false positive лежат в одном списке. Люди берут то, что проще закрыть, потому что так легче держать темп. В результате легкие кейсы двигаются, а рискованные стареют внутри очереди.
Из-за этого средние метрики часто врут. На дашборде можно увидеть приемлемое среднее время обработки, но за ним скрываются старые задачи с высоким риском. Для банка, телеком-команды или ритейла это неприятный перекос: формально процесс жив, а реально опасные кейсы ждут дольше всех.
Бэклог опасен еще и тем, что скрывает не объем работы, а ее состав. Сто задач в очереди сами по себе почти ничего не говорят. Намного полезнее знать, сколько из них старше SLA, сколько затрагивают деньги, персональные данные или жалобы, и сколько вообще не стоило отправлять человеку.
Пока очередь считают одной общей массой, команда не видит, где теряет время и где растет риск. Поэтому ручная модерация уходит в минус даже при стабильном входе: поток тот же, а полезная пропускная способность падает каждый день.
С чего начать приоритизацию кейсов
Начать лучше с простого правила: сортируйте поток не по времени поступления, а по цене ошибки. Если безобидный кейс подождет 40 минут, потери почти нет. Если опасный кейс пройдет без проверки, цена ошибки заметно выше: жалоба клиента, утечка данных, неверное решение или штраф.
Поэтому очередь ручной проверки лучше строить вокруг ущерба, а не вокруг принципа "кто раньше пришел, того раньше и смотрим". FIFO кажется честным, но почти всегда смешивает срочное и несрочное в один поток.
На практике хватает 3-4 классов риска:
- Критический риск. Ошибка затрагивает деньги, персональные данные, безопасность или требования регулятора. Такие кейсы человек должен видеть сразу.
- Высокий риск. Ошибка дорого обходится, но не требует реакции в ту же минуту.
- Средний риск. Спорные случаи, где полезна выборочная ручная проверка.
- Низкий риск. Типовые кейсы с понятным паттерном. Их лучше отправлять в автообработку, а человеку оставлять только небольшой процент для контроля качества.
Правила для этих классов должны быть короткими и наблюдаемыми. Не "сложный запрос" и не "подозрительный кейс", а конкретные признаки: есть PII, есть жалоба на списание, ответ модели касается медсовета, нет обязательной маркировки AI-контента. Если команда работает с LLM в продакшене, такие признаки обычно видны уже на этапе маршрутизации.
Еще одна частая ошибка - путать срочность и сложность. Длинный или редкий кейс не всегда срочный. И наоборот: простой кейс иногда требует реакции за 5 минут, если связан с блокировкой клиента или риском утечки.
Поэтому поле приоритета лучше разделить на два независимых признака: риск и дедлайн. Тогда кейс "сложный, но терпит" не вытеснит кейс "простой, но горит".
Низкий риск не стоит тянуть в ручную очередь "на всякий случай". Лучше пустить его автоматически, поставить лимиты, логирование и выборочный аудит. Именно это обычно сразу освобождает время для тех задач, где человек действительно нужен.
Как задать SLA без лишней бюрократии
SLA работает только тогда, когда команда одинаково понимает, что считать просрочкой. Для ручной проверки это не абстрактное "кейс долго висит", а конкретный сбой в процессе: оператор не открыл кейс за 15 минут, модератор не дал первое решение до публикации, спорный ответ модели не ушел на старшего до конца смены. Чем точнее формулировка, тем меньше споров и красивых, но бесполезных отчетов.
Сразу договоритесь, какой момент вы измеряете. Обычно полезно смотреть не на одно число, а на три точки: когда кейс попал в очередь, когда его взяли в работу и когда закрыли. Если задачу пять раз перекинули между людьми, а отчет считает только последний шаг, SLA на бумаге будет хорошим, а хвост в очереди все равно начнет расти.
Один SLA для всех кейсов почти всегда ломает процесс. Проще разделить поток по риску и дать каждому классу свое время ответа:
- Высокий риск: 10-15 минут до первого решения.
- Средний риск: до 2 часов.
- Низкий риск: до конца смены или до следующего рабочего дня.
Так команда не тратит срочный слот на безобидный кейс, пока рядом лежит то, что может привести к жалобе, штрафу или потере клиента.
Эскалация должна срабатывать до просрочки, а не после нее. Часто хватает простого правила: когда кейс прожил 70-80% своего SLA, система поднимает его выше в очереди, отправляет сигнал старшему смены или переводит на резервную группу. Если ждать красного статуса, время уже потеряно.
Контроль SLA тоже стоит смотреть по всему процессу. Допустим, банк проверяет ответы модели, где сработал флаг на персональные данные. Если первый модератор не уверен и отправляет кейс юристу, часы не должны обнуляться. Иначе отчет покажет норму, хотя клиент ждал вдвое дольше.
Полезнее считать долю кейсов, которые уложились в SLA на каждом этапе, медианное время до первого действия и число эскалаций до просрочки. Эти метрики не выглядят эффектно, зато по ним сразу видно, где процесс тормозит: на входе, при передаче между ролями или на финальном решении.
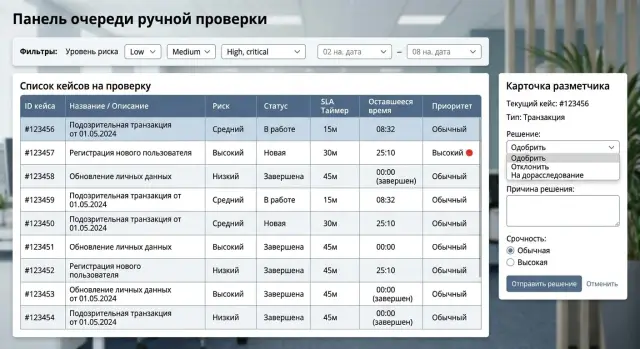
Каким должен быть интерфейс разметчика
Разметчик не должен тратить время на поиск нужных данных. Нормальный экран помогает принять решение за 10-20 секунд. Если человек каждый раз открывает пять вкладок, очередь растет даже тогда, когда команда работает быстро.
На карточке кейса оставляйте только то, что влияет на решение: сам фрагмент, короткий контекст, причину попадания в очередь, приоритет и дедлайн по SLA. Остальное лучше свернуть. Длинные логи, служебные поля, внутренние ID и полные технические параметры редко нужны в первые секунды просмотра.
Что разметчик должен видеть сразу
У кейса должен быть один понятный следующий шаг. Не набор равных по весу кнопок, а основной выбор для этого типа проверки. Если оператор чаще всего либо подтверждает, либо отправляет кейс на эскалацию, именно эти действия должны быть перед глазами. Редкие сценарии можно убрать в меню.
На одном экране обычно достаточно показать сам объект проверки, короткий контекст, метку риска или причину попадания в очередь, оставшееся время до нарушения SLA, историю прошлых решений по похожим случаям и готовые причины отказа или шаблоны ответа.
Шаблоны сильно экономят время, если написаны нормальным языком. Оператор не должен заново печатать одно и то же объяснение вроде "нужен документ лучшего качества" или "ответ модели требует повторной проверки". Два клика вместо десяти дают заметную разницу уже к концу смены.
Что сильнее всего тормозит работу
Чаще всего мешают переходы между экранами. Разметчик открывает карточку, потом фильтр, потом историю пользователя, потом возвращается назад и теряет место в очереди. Такой интерфейс раздражает и постоянно крадет минуты.
Лучше работает потоковый режим: решил текущий кейс, сразу получил следующий, без перезагрузки списка и повторного выбора фильтра. Если команда проверяет ответы LLM в продакшене, рядом с текущим кейсом полезно показывать прошлые решения по тому же правилу. Тогда стандарт остается одинаковым, а споров по пограничным случаям становится меньше.
Хороший интерфейс убирает сомнения и лишние движения. Если оператору сразу понятно, что смотреть, что нажимать и на что опираться, очередь перестает копиться даже без расширения команды.
Пошаговая настройка процесса
Если отправлять людям все спорные ответы подряд, очередь начнет расти почти сразу. Нормальный процесс строят не вокруг среднего числа кейсов за день, а вокруг риска и реальной скорости смены.
Сначала возьмите историю хотя бы за две недели. Идеальная схема здесь не нужна. Достаточно ответить на несколько простых вопросов: какие типы кейсов приходят чаще всего, где автомат ошибается, сколько минут уходит на одну проверку и в какие часы поток резко растет.
Дальше идите по шагам.
-
Разделите поток на 4-6 понятных классов. Обычно хватает групп вроде персональных данных, платежей или договоров, жалоб, токсичного контента, низкой уверенности модели и всего остального. Для каждой группы посчитайте долю в потоке и частоту ошибок. Если 40% очереди дает класс с почти нулевым риском, его не нужно смотреть вручную так же быстро, как жалобы или утечки данных.
-
Введите простые правила автоотбора. Чем правило проще, тем легче его поддерживать. Например, отправляйте на проверку все кейсы, где модель нашла PII, все ответы по финансовым операциям и случаи, где одновременно сработали два сигнала: низкая уверенность и жалоба пользователя. Если безопасный шаблон уже много раз проходил без ошибок, не тяните его в очередь снова.
-
Назначьте SLA по уровню риска и сразу укажите владельца. Высокий риск можно смотреть за 15-30 минут, средний - в течение смены, низкий - раз в день выборкой. Владелец нужен не для отчета, а для действия: кто разбирает просрочку, кто меняет правило, кто убирает ложные срабатывания.
-
Проверьте схему на реальной смене. Средние цифры часто обманывают. Во вторник днем команда может успевать, а вечером очередь уже растет. Прогоните историю по часам и посмотрите, сколько кейсов один разметчик реально закрывает за час без спешки и без падения качества.
-
Раз в неделю меняйте только то, что видно в цифрах. Смотрите на входящий поток, долю кейсов в ручной проверке, ложные срабатывания и пропущенные рискованные случаи. Меняйте по 1-2 правила за раз, иначе потом не поймете, что именно сработало.
Если LLM-приложение идет через AI Router, такой разбор обычно проще. В одном месте видны аудит-логи, маскирование PII и метки AI-контента, поэтому легче понять, какие события действительно требуют человека, а какие лучше оставить автоматике. Именно это часто и убирает бэклог: люди проверяют не больше, а точнее.
Где команды чаще всего ошибаются
Обычно очередь растет не из-за нехватки людей, а из-за плохих правил потока. Команда видит десятки "срочных" задач, но не понимает, какие из них правда бьют по риску, клиенту или деньгам. Порядка в такой очереди нет, даже если формально процесс настроен.
Первая частая ошибка проста: все срочное складывают в один поток. Жалоба клиента, подозрение на фрод, спорный ответ модели и обычный редкий кейс получают почти одинаковый статус. Через пару дней слово "срочно" перестает что-то значить. Разметчики берут то, что проще, а не то, что опаснее.
Не меньше вреда дает и обратная крайность. Команда тратит слишком много времени на редкие, но безопасные случаи только потому, что они выглядят необычно. В ручной модерации LLM-приложений это встречается постоянно: система аккуратно пометила ответ как сомнительный, но по факту риск низкий, а человек все равно разбирает его пять минут вместо тридцати секунд. Если таких кейсов много, действительно важные проверки ждут слишком долго.
SLA тоже часто считают не с той точки. Если отсчет начинается в момент создания события, цифра выходит красивой только на бумаге. На практике кейс мог еще не попасть в рабочую очередь, ждать батч-обработки или фильтрации. Команде кажется, что SLA нарушен постоянно, хотя проблема не в людях, а в неверной точке старта.
Еще одна частая потеря времени - оператор собирает контекст по кускам. Он открывает CRM, отдельный лог, историю диалога, правила эскалации и еще внутреннюю таблицу. На одно решение уходит не минута, а три-четыре. При потоке в 500 кейсов в день это уже часы потерь.
Снаружи это обычно выглядит одинаково:
- кейс долго ждет до первого просмотра;
- простые задачи разбирают слишком тщательно;
- сложные задачи уходят на повторную проверку;
- разметчики по-разному трактуют один и тот же случай;
- правила приоритета не пересматривают месяцами.
Самая дорогая ошибка появляется позже. Объем вырос вдвое, появились новые типы кейсов, а правила остались прежними. То, что работало на 50 проверках в день, ломается на 500. Если команда не меняет пороги риска, SLA и сам экран проверки, бэклог возвращается очень быстро.
Пример очереди без лишней ручной работы
Интернет-магазин принимает сотни заявок на возврат в день. Если отправлять на ручную проверку все подряд, команда быстро тонет в рутине. Намного лучше работает простая схема: обычные возвраты система закрывает сама, а люди смотрят только то, что действительно может стоить денег или вызвать спор с клиентом.
Автоматом проходят заявки, где сумма небольшая, товар типовой, история покупателя чистая, а причина возврата совпадает с частыми сценариями. Такие кейсы не держат в очереди даже несколько минут. Система проверяет правила, ставит решение и пишет понятный статус.
Ручная очередь остается короткой, потому что в нее попадают только спорные случаи: дорогой товар, повторные возвраты за короткий срок, несовпадение серийного номера, странная активность по аккаунту или конфликт между складом и поддержкой.
В живом процессе это может выглядеть так:
- обычный возврат до 20 000 тенге уходит в автообработку;
- возврат дорогой электроники попадает на проверку в течение 10 минут;
- кейс с признаком мошенничества получает SLA 5 минут;
- старший сотрудник видит только дорогие или конфликтные заявки.
Такая схема снижает нагрузку сразу в двух местах. Линейные сотрудники не тратят время на безопасные заявки, а старший сотрудник не листает весь поток ради пары сложных решений. Он подключается только там, где ошибка дорогая: крупная сумма, риск чарджбэка, жалоба клиента или явный спор по фактам.
Эффект обычно виден уже через неделю. Команда начинает замечать, какие кейсы снова и снова попадают в короткую очередь. Часто выясняется, что проблема не в нехватке людей, а в слабых правилах. Допустим, система отправляет на проверку все возвраты наушников, хотя спорными оказываются только случаи без фото упаковки. Значит, нужно не расширять смену, а точнее настроить правила и форму заявки.
Хорошая ручная модерация выглядит скучно, и это нормально. У операторов мало задач, но почти каждая требует внимания. Если в очереди много простых кейсов, процесс уже сломан.
Короткий чек-лист для ежедневного контроля
Если команда смотрит на очередь только по общему числу кейсов, проблему почти всегда замечают поздно. С утра все может выглядеть терпимо, а к обеду часть задач уже выходит за SLA и тянет за собой остальной поток.
Ежедневный контроль лучше строить вокруг пяти вопросов:
- Сколько кейсов уже старше своего SLA прямо сейчас. Смотрите не только на общий объем, но и на долю просрочки.
- Какой процент потока уходит в ручную проверку. Рост даже на несколько пунктов часто значит, что правило стало слишком строгим или модель стала чаще сомневаться.
- Сколько времени уходит на каждый частый тип кейсов. Один сложный класс может съедать половину смены, хотя по количеству он не самый большой.
- Какие причины решений встречаются чаще всего. Если разметчики снова и снова ставят один и тот же итог, часть этой работы пора убирать из ручного контура.
- Где очередь держится на одном человеке. Если только один сотрудник умеет разбирать спорные жалобы или медицинские кейсы, у вас уже есть узкое место.
На эти цифры лучше смотреть вместе. Например, доля ручной модерации может не расти, но среднее время на один тип кейса выросло с 2 до 7 минут. Для смены это уже совсем другая нагрузка, и бэклог появится к концу дня.
Полезно фиксировать и причину отклонения от нормы. Не просто "просрочено 84 кейса", а "просрочено из-за новой категории, смены правил или отсутствия второго разметчика на вечернем окне". Тогда руководитель меняет маршрут задачи, правило или расписание, а не просит команду просто работать быстрее.
Хороший ежедневный отчет помещается в один экран. Если на нем сразу видны просрочка, доля ручных задач, среднее время по типам и зависимость от конкретных людей, проблему можно заметить в тот же день, а не в конце недели.
Что делать дальше
Не пытайтесь чинить всю ручную модерацию сразу. Возьмите один процесс, где ошибка действительно дорогая: спорная выплата, ответ клиенту с персональными данными, отказ по заявке или публикация чувствительного контента. На одном таком потоке проще увидеть, почему очередь растет и где люди тратят время зря.
Потом пересмотрите пороги, по которым кейс уходит к человеку. Во многих командах они слишком осторожные: модель сомневается на 1-2 пункта, и задача сразу летит в ручную проверку. Обычно лучше сделать правила точнее на верхнем риске и отпустить низкий риск без участия оператора.
Рабочий план здесь довольно приземленный:
- выберите один сценарий и замерьте текущий объем ручных проверок за 1-2 недели;
- посмотрите, какие три причины чаще всего отправляют кейс в очередь;
- ужесточите проверку только там, где ошибка бьет по деньгам, риску или жалобам;
- сократите причины ручной проверки до 5-7 понятных групп;
- через неделю проверьте, стало ли меньше спорных кейсов и повторных просмотров.
Группы причин лучше делать короткими и ясными. Например: низкая уверенность модели, конфликт правил, подозрение на PII, риск по политике, неполные данные, спорный итог. Если причин двадцать, разметчики начинают путаться, а отчеты перестают что-то объяснять.
Если у вас LLM-процесс, уменьшать поток в ручную очередь часто можно не наймом людей, а более точной маршрутизацией. Быструю и дешевую модель можно оставить для простых запросов, а сложные и рискованные отправлять в более сильную. Аудит-логи тоже помогают: по ним видно, какой промпт, модель или правило чаще всего создают лишние проверки.
Для этого многим командам удобен единый шлюз вроде AI Router на airouter.kz. Он дает один OpenAI-совместимый эндпоинт, помогает менять модель или провайдера без переделки текущей интеграции и держать аудит-след в одном месте.
Если после этих шагов очередь не уменьшается, не расширяйте штат первым делом. Сначала добейтесь двух понятных изменений: меньше кейсов на человека в день и меньше возвратов на повторную проверку. Это хороший признак, что процесс начал работать лучше, а не просто стал дороже.
Часто задаваемые вопросы
Как понять, что ручная очередь уже уходит в бэклог?
Смотрите не только на общий объем, а на состав очереди. Если растет доля кейсов старше SLA, срочные случаи лежат рядом с безопасными, а люди тратят время на сбор контекста, очередь уже проседает, даже если входящий поток почти не меняется.
Что ставить первым при разборе кейсов: время поступления или риск?
Сначала сортируйте по цене ошибки. Безопасный кейс может подождать, а жалоба на списание, риск утечки данных или спорный ответ модели лучше показать человеку сразу. Время поступления оставьте вторым фактором, а не главным.
Сколько уровней приоритета реально нужно?
Обычно хватает 3-4 классов. Этого достаточно, чтобы отделить деньги, персональные данные, жалобы и регуляторные случаи от обычного потока, но не утонуть в правилах. Если классов слишком много, команда начнет спорить о названиях вместо работы.
Когда безопасно убрать низкий риск из ручной проверки?
Отдавайте низкий риск в автообработку, если у вас есть понятный шаблон, лимиты, логирование и выборочный аудит. Если один и тот же тип кейса много раз проходит без ошибок, нет смысла снова класть его в ручную очередь.
Как настроить SLA без лишней бюрократии?
Возьмите три точки: когда кейс попал в очередь, когда человек взял его в работу и когда закрыл. Потом задайте разное время ответа для разных рисков. Так команда перестанет тратить срочный слот на спокойные кейсы.
В какой момент лучше эскалировать кейс?
Не ждите просрочки. Как только кейс прожил около 70-80% своего SLA, поднимайте его выше в очереди или отправляйте старшему смены. Такой порог обычно спасает хвост очереди лучше, чем разбор уже красных задач.
Что разметчик должен видеть на одном экране?
На карточке держите только то, что влияет на решение: сам фрагмент, короткий контекст, причину флага, риск, дедлайн и похожие прошлые решения. Если оператор прыгает между вкладками и каждый раз заново ищет историю, вы теряете минуты на каждом кейсе.
Почему среднее время обработки часто врет?
Среднее скрывает хвост. На дашборде может быть нормальное число, хотя дорогие кейсы уже стареют в очереди. Поэтому смотрите медиану, долю задач старше SLA и время до первого действия по каждому классу риска.
Как сократить ложные срабатывания и не сломать процесс?
Начните с самых частых причин ручной проверки. Если правило стабильно дает безопасные кейсы, сузьте его или добавьте еще один признак, например жалобу пользователя, PII или низкую уверенность модели вместе с другим сигналом. Меняйте по одному-двум правилам за раз, чтобы видеть эффект.
Когда пора нанимать людей, а не править правила?
Сначала проверьте правила потока, интерфейс и повторные просмотры. Если после этого у людей все равно не хватает часов на рискованные кейсы, тогда уже считайте найм. Расширять смену раньше часто дорого и мало что меняет.