Автоскейлинг инференса: сигналы из очереди и задержки
Автоскейлинг инференса стоит строить на длине очереди, времени ожидания и задержке p95, чтобы днем держать SLA, а ночью не гонять лишние GPU.
Почему кластер дергается без пользы
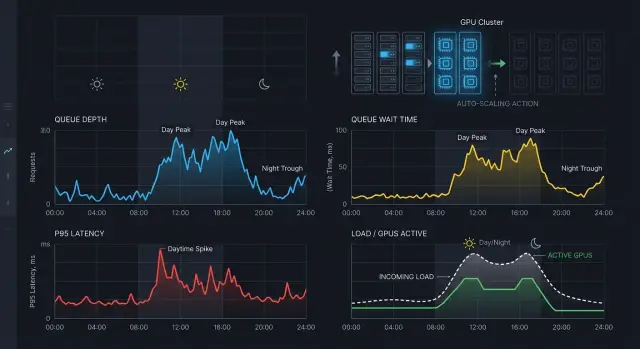
Кластер обычно дергается не из-за большой нагрузки, а из-за того, что автоскейлер плохо читает короткие изменения. Утром трафик растет ступеньками: люди почти одновременно открывают рабочие сервисы, очередь быстро набухает, потом так же быстро спадает. Ночью картина другая: запросов мало, и любой одиночный всплеск выглядит как авария.
Из-за этого автоскейлинг инференса часто принимает шум за новый нормальный уровень. Система видит минутный всплеск, поднимает еще один GPU-узел, а пик уже закончился. Через несколько минут она решает, что мощности лишние, и начинает сжимать кластер обратно. Так появляется дрожание: машины приходят и уходят, а пользователи все равно ловят скачки задержки.
Ночью это заметно сильнее. Днем очередь из 30 запросов может быть обычным делом на пару минут. Ночью та же очередь выглядит как повод для паники, хотя ее мог создать один пакет задач или один тяжелый промпт.
Отдельная ловушка - холодные старты GPU. Новый инстанс не начинает помогать сразу. Ему нужно подняться, загрузить модель в память, прогреть контейнеры и подключиться к маршруту. Пока это происходит, растут p95 задержки и время ожидания. Автоскейлер видит рост и может решить, что мощности по-прежнему мало, хотя нужные узлы уже запущены и системе надо просто дать время.
Еще одна частая ошибка - смотреть только на CPU или GPU. Для LLM-инференса этих метрик мало, и часто они запаздывают. Очередь уже копится, пользователи уже ждут, а утилизация GPU еще не дошла до порога, потому что запросы даже не попали в обработку.
Обычно кластер дергают четыре вещи: слишком короткое окно метрик, одинаковые пороги днем и ночью, игнорирование холодного старта и ставка только на CPU или GPU без учета очереди.
В банке это видно особенно ясно. В 9:00 сотрудники массово запускают внутренних помощников и поиск по документам. Если автоскейлер судит только по загрузке GPU, он опаздывает на несколько минут. Если он смотрит только на очередь за последние 30 секунд, он начинает паниковать и раздувает кластер сильнее, чем нужно.
Рабочая схема смотрит не на один сигнал, а на их связку: как быстро растет очередь, сколько запрос ждет до старта и успеет ли новый GPU прийти раньше, чем просадку заметят пользователи. Тогда кластер перестает метаться и начинает реагировать по делу.
Какие сигналы брать из очереди
Одна длина очереди почти всегда врет. Очередь из 20 запросов может быть нормой в 14:00 и проблемой в 14:03, если она растет каждую секунду и GPU уже заняты.
Для автоскейлинга инференса полезнее смотреть не на один счетчик, а на несколько связанных метрик. Тогда кластер не будет метаться из-за короткого всплеска и не пропустит момент, когда пользователи уже ждут слишком долго.
Первый сигнал - глубина очереди. Но сама по себе она мало что говорит. Намного полезнее считать еще и скорость роста: сколько запросов в секунду приходит в очередь и сколько система успевает забирать в работу. Если очередь держится на уровне 15 и не растет, это терпимо. Если за минуту она выросла с 15 до 80, пора реагировать.
Второй сигнал - время ожидания до старта инференса. Оно ближе к реальному опыту пользователя, чем сухая длина очереди. Лучше смотреть не среднее, а p95: спокойный поток легко прячет медленные хвосты, а именно они и бьют по SLA.
Третий сигнал - разделение запросов на "в очереди" и "в работе". Когда in-flight запросов уже много, новый инстанс может понадобиться даже при короткой очереди. И наоборот, длинная очередь иногда появляется просто потому, что один воркер взял тяжелую задачу, а остальные свободны. Без этого разделения трудно понять, где именно узкое место.
На практике обычно хватает четырех метрик:
- текущая глубина очереди
- скорость роста очереди за 30-60 секунд
- p95 времени ожидания до старта инференса
- число запросов в работе отдельно от числа запросов в ожидании
Еще один полезный шаг - разнести короткие и длинные запросы по разным пулам. Чат на 200 токенов и обработка длинного документа не должны бороться за одни и те же GPU. Иначе несколько тяжелых задач испортят задержку всем остальным.
Это особенно заметно там, где часть трафика идет на быстрые диалоговые модели, а часть - на большие open-weight модели на собственных GPU. Если в одном контуре есть и внешние модели, и свои GPU-пулы, как в AI Router, отдельные очереди для коротких и длинных запросов обычно дают больше пользы, чем грубое масштабирование всего кластера сразу.
Если выбирать один недооцененный сигнал, то это время ожидания до старта. Очередь еще может выглядеть терпимо, а пользователи уже стоят в пробке.
Как читать задержку без самообмана
Задержка легко сбивает с толку, если смотреть на нее одним числом. Пользователь чувствует полное время ответа, но для автоскейлинга этого мало. Кластеру нужно понимать, где именно теряется время: в очереди, в сети, в рантайме модели или в повторах запроса.
Сначала разделите end-to-end задержку и чистое время модели. Если запрос ждал в очереди 1,5 секунды, а модель считала 400 мс, проблема не в модели. Если очередь пустая, а время модели выросло вдвое, дело уже не в мощности воркеров, а в размере промпта, длине ответа, холодном старте или проблеме у провайдера.
Если трафик идет через шлюз вроде AI Router, такое разделение особенно полезно. Один и тот же запрос может быстро пройти API-слой, но долго простоять в очереди на GPU. Без разбивки по этапам график покажет только общий рост задержки, и команда начнет масштабировать не туда.
Среднее значение почти всегда сглаживает неприятные пики. Смотрите хотя бы на p50 и p95 вместе. p50 показывает обычное состояние системы, а p95 - хвост, который и бьет по SLA.
Типичная картина выглядит так: p50 держится ровно, а p95 резко ползет вверх. Это не случайный шум. Чаще всего так выглядит локальная перегрузка, всплеск длинных запросов или очередь, которая еще не стала большой, но уже портит хвост задержки.
Полезно держать рядом четыре линии: полную задержку ответа, чистое время модели, время ожидания в очереди и p95 по тем же минутным окнам.
Еще одна ошибка - смешивать в одном графике клиентские ошибки и ретраи. Если клиент оборвал соединение на второй секунде и потом отправил тот же запрос снова, средняя задержка и p95 начинают врать. Для решений по масштабированию такие события лучше вынести отдельно: 4xx, отмены клиентом, таймауты на стороне клиента и повторные попытки.
Сверяйте задержку с глубиной очереди в тот же момент, а не примерно в тот же период. Если p95 вырос, а очередь не изменилась, ищите другую причину. Если очередь и p95 растут вместе, мощности уже не хватает. Если очередь растет, а чистое время модели нет, масштабироваться надо быстрее. Если время модели растет само по себе, сначала проверьте профиль нагрузки, а уже потом добавляйте GPU.
Какие пороги работают днем и ночью
Одинаковый порог на весь день почти всегда дает лишние скачки. Днем трафик плотнее, и цена промаха выше: очередь растет быстро, p95 ползет вверх, пользователи замечают это сразу. Ночью тот же всплеск часто короткий, и если кластер реагирует так же резко, GPU просто включаются и простаивают.
Днем порог для scale up обычно ставят ниже. Смысл простой: добавить емкость чуть раньше, чем очередь станет видна в задержке. Если рабочий трафик идет с 9:00 до 19:00, лучше реагировать на ранний рост времени ожидания, чем ждать, пока p95 уже выйдет за пределы SLO.
Ночью логика другая. Порог можно поднять, а окно ожидания перед scale up сделать длиннее. Так вы отсекаете короткие пики, которые проходят сами. Это особенно полезно в банках, ритейле и SaaS, где ночью идут фоновые задачи, пакетные прогоны и редкие всплески от внутренних систем.
Стартовая схема обычно выглядит так:
- днем scale up срабатывает раньше, если глубина очереди заметно растет или время ожидания держится выше порога 2-3 минуты
- ночью тот же сигнал должен держаться дольше, часто 5-10 минут
- для scale down нужен отдельный таймер, медленнее и строже
- порог на уменьшение емкости должен быть ниже порога на рост, чтобы не гонять узлы туда-сюда
Scale up и scale down всегда стоит разделять. Если добавлять и убирать емкость по одному таймеру, кластер начнет дергаться около границы. На практике уменьшение емкости лучше делать в 2-4 раза медленнее, чем увеличение. Например, добавить GPU можно через 3 минуты перегруза, а убрать - только после 15-20 минут спокойной работы.
Одного расписания мало. Сначала соберите хотя бы неделю замеров по очереди, p95 и фактической загрузке GPU. Потом делите сутки на окна. Иначе вы просто закрепите неправильные пороги по расписанию.
Если трафик сильно меняется по дням недели, деления на день и ночь тоже мало. Утро понедельника и ночь субботы - это разные режимы, и пороги у них часто должны отличаться.
Как собрать правило автоскейлинга по шагам
Хорошее правило начинается с одной цели SLA. Обычно это либо время ожидания запроса в очереди, либо полная p95 задержки. Не ставьте две равные цели сразу. Иначе автоскейлер будет метаться: одна метрика просит добавить GPU, другая уже успокоилась.
Для автоскейлинга инференса удобно разделить роли так: одна метрика принимает решение, остальные страхуют. Например, команда держит время ожидания не выше 1,5 секунды, а p95 использует как проверку, что система правда стала быстрее, а не просто переложила очередь в другое место.
Дальше правило лучше собирать по порядку.
- Задайте целевое значение. Возьмите одно число, которое понятно и бизнесу, и инженерам. Например: "95% запросов ждут в очереди не больше 1,5 секунды".
- Добавьте ранний триггер на scale up по глубине очереди. Он нужен не потому, что очередь сама по себе плоха, а потому, что она растет раньше, чем успевает испортиться p95. Если на один GPU у вас обычно безопасно 8-10 активных запросов, ставьте порог чуть ниже зоны боли, а не в момент аварии.
- Поставьте окно сглаживания. Для большинства рабочих нагрузок хватает 2-5 минут. Без него кластер будет дергаться от коротких всплесков, которые проходят сами.
- Введите cooldown после каждого изменения размера. После scale up дайте системе 3-10 минут, чтобы новые реплики прогрелись, забрали очередь и показали реальную задержку. Для scale down окно обычно делают длиннее.
- Прогоните правило на вчерашнем трафике. Смотрите отдельно дневной пик и тихие часы ночью. Хорошее правило добавляет мощность до того, как пользователи замечают рост ожидания, и не держит лишние GPU после спада.
Есть простой рабочий шаблон: очередь выше порога 3 минуты подряд - добавить 1-2 реплики; очередь в норме 15 минут и p95 тоже в норме - убрать 1 реплику. Шаги лучше делать маленькими. Резкое масштабирование чаще стоит дороже и хуже сказывается на предсказуемости.
Если разные модели ведут себя по-разному, не пытайтесь покрыть все одним правилом. Тяжелую reasoning-модель и короткий чат лучше масштабировать раздельно. Для маршрутов с разной длиной ответа и разными провайдерами одна и та же глубина очереди может означать совсем разную нагрузку.
Пример: рабочий день банка и тихая ночь
У банка утренний пик обычно начинается не ровно в 9:00, а за несколько минут до этого. Сотрудники открывают внутренние системы, запускают поиск по документам, проверку писем и короткие сводки. Поток растет резко, и с 9:00 до 11:00 глубина очереди часто растет быстрее, чем новые GPU успевают прогреться и принять трафик.
В такой фазе автоскейлинг нельзя строить только на загрузке GPU. Она покажет проблему поздно. Лучше смотреть на связку из трех сигналов: глубина очереди, время ожидания запросов и p95 задержки. Если очередь держится выше обычного уровня 60-90 секунд, а ожидание уже вышло за пределы нормы, автоскейлеру стоит добавлять не один инстанс, а сразу небольшой шаг.
Утром правило часто сводится к четырем вещам: держать теплый минимум до начала смены, запускать scale up по устойчивой очереди, а не по разовому всплеску, добавлять емкость шагом 2-3 реплики при долгом прогреве и откладывать scale down, пока трафик не успокоится.
После обеда картина меняется. Запросы идут ровнее, и масштабирование GPU должно быть спокойнее. Здесь полезен небольшой запас, который закрывает обычные колебания без постоянных включений и выключений. Если очередь почти пустая, а p95 вернулась в норму, кластер можно уменьшать медленно. Спешка тут обычно только тратит деньги и делает систему нервной.
Ночью многие команды ошибаются одинаково: видят редкий всплеск и будят весь пул. На практике после 22:00 один batch на пересчет отчетов или разметку документов может дать короткий скачок, но это не значит, что нужно поднимать весь интерактивный контур. Лучше задать ночной профиль с более длинным окном наблюдения.
Хороший ночной сценарий простой. Редкий всплеск длиной 1-2 минуты вы игнорируете. Если очередь держится дольше и пользователи правда ждут, тогда добавляете емкость. Один ночной batch лучше сразу вынести в отдельную очередь с собственным лимитом. Для команд, которые держат модели на своей GPU-инфраструктуре, это особенно полезно: интерактивные запросы не страдают, а фоновая задача не разгоняет кластер без причины.
Где команды чаще всего ошибаются
Чаще всего команды смотрят на одну красивую метрику и пропускают реальную проблему. В автоскейлинге инференса это обычно загрузка GPU. Она заметна первой, но не показывает, сколько запросов уже застряло на входе и как долго люди ждут ответ.
Если очередь растет перед роутером, батчером или модельным сервером, GPU может выглядеть нормально. На графике 55% загрузки, а p95 времени ожидания уже ушел вверх. Пользователь чувствует именно ожидание, а не среднюю утилизацию железа.
Если у вас есть LLM-шлюз вроде AI Router, полезно смотреть не только на GPU, но и на очередь на входе шлюза. Там перегрузку часто видно раньше, чем на самих воркерах.
Ошибка в выборе сигнала
Одна метрика редко дает честную картину. Глубина очереди без скорости обработки тоже обманывает: очередь может быть короткой, но старый запрос уже ждет слишком долго. Одна задержка тоже не спасает, потому что она растет с опозданием.
Обычно лучше работают три сигнала вместе: глубина очереди, возраст самого старого запроса и p95 времени ожидания. Такой набор показывает и давление на систему, и то, как это уже бьет по SLA.
Еще одна частая ошибка - смешивать интерактивные запросы и длинные batch-задачи в одной очереди. Тогда один тяжелый прогон портит метрики для чата, поиска или операторского помощника.
Здесь правило простое: интерактивные запросы должны идти в отдельную очередь, batch-задачи - в свой пул воркеров, а для каждого класса трафика нужны свои пороги масштабирования.
Ошибка во времени реакции
Команды часто реагируют на всплеск длиной в несколько секунд, хотя холодный старт длится дольше. Новый GPU-инстанс может подниматься минуты, а не секунды. Если автоскейлер дергает кластер на каждом коротком пике, он все время догоняет уже прошедшую нагрузку.
Обратная ошибка не менее дорогая. После короткого затишья команды быстро гасят инстансы, потому что очередь на минуту опустела. Через пять минут трафик возвращается, и все начинается заново: холодный старт, рост очереди, жалобы на задержку.
Поэтому scale out и scale in не должны жить по одним правилам. Расти можно быстрее, а уменьшать емкость стоит осторожнее: с окном наблюдения, cooldown и минимальным теплым пулом. Это не так эффектно, как агрессивная экономия, зато кластер перестает метаться без пользы.
Короткий список проверок
Автоскейлинг инференса ломается не из-за одной плохой цифры, а из-за путаницы в базовых сигналах. Если кластер то растет, то сжимается без пользы, сначала проверьте наблюдаемость, а уже потом крутите пороги.
- Держите отдельно три метрики: глубину очереди, время ожидания до старта обработки и чистое время работы модели. Если смешать их в одну задержку, система начнет лечить не ту проблему.
- Считайте p95 на спокойном окне, а не по секундам. Обычно хватает окна 5-10 минут и нижнего порога по числу запросов, чтобы редкий всплеск не запускал лишнее масштабирование GPU.
- Поднимайте мощности быстрее, чем опускаете. Новую емкость лучше добавлять после 1-2 плохих окон подряд, а убирать только после более длинного спокойного периода.
- Не ставьте один режим на весь день. Днем и ночью нагрузка ведет себя по-разному, поэтому пороги или расписание тоже должны отличаться.
- Показывайте команде цену каждого лишнего запуска GPU. Когда люди видят стоимость лишних scale up событий, они спокойнее относятся к более консервативному scale down.
Есть еще одна частая ловушка. Команда смотрит только на p95 задержки, видит рост и решает, что не хватает GPU. Но p95 может расти из-за очереди на входе, холодного старта, rate limit или долгого ответа внешнего провайдера. Для шлюза вроде AI Router особенно полезно отличать задержку до маршрутизации, ожидание в очереди и время самой модели.
Ночной режим почти всегда требует отдельной логики. Днем вы чаще защищаете пользовательский отклик. Ночью важнее не держать пустые GPU ради пары редких запросов. Поэтому для ночи обычно ставят более высокий порог на scale up, более долгую паузу перед scale down или фиксируют минимальный размер кластера по расписанию.
Если хотя бы один пункт из этого списка не закрыт, автоскейлер почти наверняка будет гоняться за шумом. Сначала разделите сигналы, потом проверьте окна и цену ошибок, и только после этого меняйте правила.
Что делать после первых настроек
Первые пороги почти никогда не живут долго. Автоскейлинг инференса нужно пересматривать по живому трафику, а не по одному нагрузочному тесту. Дайте системе поработать хотя бы неделю и снимите метрики по часам: глубина очереди, p95 задержки, время ожидания запросов, занятость GPU и число холодных стартов.
Смотрите не только на средние значения. Днем очередь может расти короткими всплесками на 5-10 минут, а ночью тот же порог будет держать лишние машины без пользы. Хороший признак ошибки простой: масштабирование GPU срабатывает часто, а задержка для пользователей почти не меняется.
Через неделю обычно видно две разные картины. Первая - рабочие часы, когда поток плотный и дорог каждый лишний хвост в очереди. Вторая - ночь, когда запросов мало, но длинный промпт или один тяжелый batch легко ломает общую картину. Поэтому пороги лучше хранить отдельно для аварийного роста и для ночного простоя.
Полезно регулярно сверять четыре вещи: сколько запросов ждет дольше целевого времени, как меняется p95 при той же глубине очереди, сколько инстансов поднялось зря и почти не получило нагрузки, и как часто scale down почти сразу сменяется новым scale up.
Нагрузочные тесты тоже лучше разделять. Короткие и длинные промпты дают разный профиль нагрузки на GPU, память и очередь. Если смешать их в одном тесте, получится усредненный порог, который плохо работает в реальности. Намного удобнее прогонять два сценария отдельно и потом смотреть, где система начинает опаздывать по SLA.
Еще одна полезная привычка - заранее записать правила на плохой день. Что делать при резком росте входящего трафика, как быстро добавлять емкость, кто может временно поднять лимиты и при каком уровне ночного простоя кластер можно сжимать почти до минимума. Когда это не зафиксировано, дежурная команда обычно дергает настройки вручную и только добавляет шум.
Если команде нужен единый OpenAI-совместимый шлюз, чтобы собирать такие метрики в одном месте и держать часть моделей локально в Казахстане, можно посмотреть на AI Router. Это удобно, когда часть трафика идет во внешние модели, а часть остается на собственных GPU, и правила автоскейлинга нужно сравнивать в одной схеме наблюдения.