Парные сравнения моделей: где A лучше B без среднего балла
Парные сравнения моделей показывают, где одна LLM выигрывает на извлечении данных, а другая - на диалогах, суммаризации и длинных ответах.
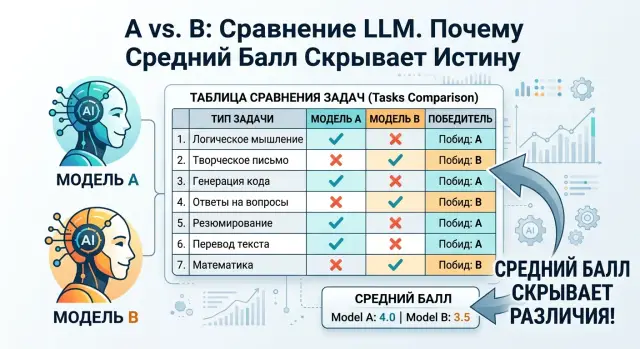
Почему средний балл сбивает с толку
Один общий балл выглядит удобно. Открыл таблицу, увидел 84 против 81, и кажется, что выбор очевиден. В работе это часто плохая подсказка.
Среднее число складывает в одну кучу разные ошибки, хотя их цена разная. Если модель чуть хуже пишет дружелюбные ответы, это неприятно, но терпимо. Если она путает сумму платежа, номер договора или статус обращения, последствия уже совсем другие.
На поддержке банка это видно особенно хорошо. Модель A может лучше вести чат: говорить спокойнее, понятнее объяснять условия, мягче переспрашивать клиента. Но та же модель может хуже заполнять поля в CRM, чаще терять дату операции или подставлять не тот тип продукта. Модель B отвечает суше, зато аккуратнее вытаскивает факты из диалога. Если свести все к одному числу, эта разница почти исчезает.
Среднее еще и смешивает простые и сложные кейсы. Допустим, 70% теста - это легкие вопросы про график работы, лимиты и базовые тарифы. Почти любая сильная модель пройдет их хорошо. Оставшиеся 30% - спорные случаи: двойное списание, эскалация по мошенничеству, запрос с неполными данными. Именно там ломается рабочий сценарий, но общий балл этого не показывает.
Иногда модель выигрывает за счет массы легких примеров. Она набирает очки на простых задачах и проигрывает там, где ошибка обходится дороже. В отчете она выглядит лучше. В реальной системе - нет.
Поэтому парные сравнения полезнее. Они заставляют смотреть не на красивое среднее, а на конкретные столкновения A против B по типам задач.
Перед выбором модели достаточно задать несколько прямых вопросов:
- где модель теряет смысл, а где портит только стиль ответа;
- какие ошибки можно закрыть правилом, а какие сразу бьют по процессу;
- какие задания редкие, но дорогие для бизнеса.
Решение по среднему баллу часто ломает не тест, а рабочий сценарий. Команда выбирает модель с лучшей общей оценкой, выкатывает ее в прод, а потом получает больше ручных проверок, пропущенные поля и лишние эскалации. Таблица обещала одно, а ежедневная работа показывает другое.
Что сравнивать в паре A и B
Если вы меняете сразу несколько параметров, сравнение теряет смысл. Модель A и модель B нужно проверять на одних и тех же условиях: один промпт, одна температура, один формат ответа, одинаковые системные инструкции и одинаковый лимит токенов. Иначе вы сравниваете не модели, а все вокруг них.
Тот же принцип работает для набора задач. Возьмите фиксированный список примеров и не подмешивайте новые по ходу теста. Если в первой половине у вас были короткие вопросы, а во второй длинные и запутанные, выводы по паре A и B станут шумными.
Критерии оценки тоже надо зафиксировать заранее. До запуска решите, что считать хорошим ответом: точность фактов, соблюдение формата, полнота, краткость, отказ от лишних догадок. Когда команда меняет правила после просмотра ответов, сравнение быстро превращается в спор о вкусах.
Удобнее смотреть не только на общий счет, а на исход каждого примера. Для каждого задания ставьте один из трех результатов: победа A, ничья или победа B. Такой подход сразу показывает, где одна модель стабильно сильнее, а где разница почти исчезает.
Рядом с качеством полезно фиксировать рабочие метрики. Иногда модель отвечает чуть лучше, но стоит в три раза дороже или добавляет две лишние секунды задержки. Для продакшена это уже не мелочь. Смотрите хотя бы на четыре вещи: качество ответа, цену, задержку и длину ответа в токенах.
Отдельно помечайте тип ошибки. Один и тот же проигрыш бывает разным по смыслу:
- факт - модель придумала или перепутала данные;
- формат - сломала JSON, таблицу или структуру ответа;
- пропуск - не ответила на часть вопроса;
- лишний текст - добавила воду, пояснения или догадки;
- отказ не к месту - перестраховалась и не выполнила обычный запрос.
Такая разметка быстро показывает характер модели. Одна чаще ошибается в фактах, другая почти всегда держит формат, но пропускает детали. Это помогает выбрать модель под конкретную задачу, а не по красивому среднему числу.
Если вы гоняете тесты через один OpenAI-совместимый шлюз, держать одинаковые настройки проще. Например, в AI Router можно менять модель, не переписывая SDK, код и формат вызова. Это убирает часть случайных различий, которые часто портят проверку.
Где считать отдельно, а не вместе
Одна общая оценка почти всегда скрывает разницу между задачами. Модель A может писать ровнее в чате, а модель B точнее вытаскивать реквизиты из длинного документа. Если свести все к одному числу, вы потеряете именно тот сигнал, который нужен для выбора модели в продакшене.
Сначала делите набор заданий по типу работы. Обычно хватает пяти групп: чат, извлечение, суммаризация, классификация и код. Это не формальность. У каждой группы свои правила победы, и сильная сторона в одной легко маскирует слабую в другой.
Хороший ответ в чате иногда можно простить за чуть менее строгий формат. В извлечении и классификации так нельзя. Если модель перепутала ИИН, тип заявки или статус клиента, приятный стиль уже ничего не меняет.
Не смешивайте короткие и длинные контексты. На коротком запросе обе модели могут идти почти вровень, а на 20 страницах разрыв станет заметным: одна держит факты до конца, другая начинает терять детали, повторяться или заполнять пробелы догадками.
То же самое с языком. Русские, казахские и английские запросы лучше считать отдельно, даже если смысл заданий одинаковый. Многие команды видят хороший средний балл на русском, а потом получают слабые ответы на казахском именно там, где это нельзя пропустить.
Отдельную группу стоит завести для задач, где формат ответа важнее стиля. Например:
- JSON по строгой схеме;
- классификация с одним допустимым ярлыком;
- извлечение полей без лишнего текста;
- SQL или код, который должен запускаться;
- ответы с обязательными метками и служебными полями.
В таких кейсах оценивайте не то, насколько хорошо написан текст, а то, можно ли сразу пустить ответ в систему. Модель с более сухим стилем нередко выигрывает, потому что реже ломает пайплайн.
Редкие кейсы тоже держите отдельно. Их мало, но цена ошибки там выше. Для банка это может быть спорная транзакция, для клиники - красный флаг в жалобе, для ритейла - возврат с юридическим риском. Если смешать их с обычным потоком, они растворятся в среднем балле.
Парные сравнения работают лучше, когда каждая группа отвечает на один ясный вопрос: кто лучше ведет диалог, кто точнее извлекает поля, кто держит длинный контекст, кто не ломает формат. После такого разбиения матрица побед и проигрышей начинает говорить по делу.
Как собрать набор заданий для проверки
Хороший набор заданий похож на то, что модель увидит в работе каждый день. Если брать только придуманные примеры, сравнение быстро уходит в сторону: одна модель красиво отвечает на учебных запросах, но сыпется на живых формулировках пользователей.
Сначала соберите реальные запросы из продукта, поддержки и внутренних прогонов. Лучше взять короткий срез из нескольких источников, чем сотню однотипных фраз. Если команда уже прогоняет трафик через API-шлюз, полезнее выгрузить анонимизированные запросы из пилота, чем сочинять тесты вручную.
Потом почистите набор. Уберите персональные данные, названия клиентов, номера счетов, телефоны и все, что нельзя показывать в тестовой среде. После этого удалите повторы. Десять одинаковых вопросов про смену пароля не дают новой информации, но сильно искажают итог.
Набор почти всегда стоит делить на три группы: простые, средние и пограничные примеры. В простых задачах обычно короткий вопрос и мало контекста. В средних уже есть несколько условий, таблица, кусок переписки или правило. В пограничных - длинный ввод, шум, противоречия, редкий формат или смешение языков.
Такая смесь быстро показывает разницу между моделями. Одна держит ровный уровень на простых задачах, другая лучше тянет длинный контекст, а третья чаще ошибается именно на редких случаях. Средний балл это сглаживает.
Для каждого задания заранее запишите, что считать хорошим ответом. Если задача точная, нужен ожидаемый результат. Если задача открытая, задайте простые правила проверки: модель не выдумывает факты, соблюдает формат, не пропускает важное условие, не раскрывает лишние данные. Иначе спор пойдет не о моделях, а о вкусах проверяющих.
И еще один момент: посмотрите на размер групп. Если у вас 60 простых запросов и 5 пограничных, вывод получится удобным, но слабым. Лучше уменьшить общий набор, но сохранить нормальное покрытие. На практике часто хватает 15-20 примеров в каждой группе, а потом можно расширять зоны, где модели идут почти вровень или часто меняются местами.
Как провести парное сравнение по шагам
Парное сравнение работает лучше, когда у него есть ясная цель. Сначала опишите, что модель делает в продукте каждый день: пишет ответ клиенту, заполняет поля из документа, проверяет тон, ищет факт в длинном тексте. Если цель расплывчатая, вывод тоже будет расплывчатым.
Потом разбейте работу на типы задач. Для каждого типа соберите отдельный набор примеров, обычно от 30 до 100. Меньше 30 часто дает шум, больше 100 нужно не всегда. Если у вас есть классификация обращений, поиск по базе знаний и краткие пересказы, тестируйте их раздельно, а не в одной куче.
Один прогон для двух моделей
A и B нужно прогонять в одинаковых условиях. Один и тот же промпт, один и тот же system message, одинаковые параметры, одинаковый формат ответа. Если у одной модели temperature 0.2, а у другой 0.8, вы уже сравниваете не модели, а настройки.
Удобно заранее сохранить весь тестовый набор и запускать его пакетно. Если команда работает через AI Router, она может быстро прогнать разные модели через один OpenAI-совместимый эндпоинт и не менять остальную обвязку. Это простая вещь, но она убирает лишние ошибки.
Дальше сравнивайте ответы попарно. На каждый пример ставьте один из трех результатов:
- победа A;
- ничья;
- победа B.
Лучше смотреть на ответы вслепую, без названия модели. Иначе люди начинают невольно подыгрывать более знакомому бренду. Если задача формальная, вроде извлечения номера договора или суммы, правила победы надо записать заранее. Если задача открытая, например ответ клиенту, дайте оценщикам короткую шкалу: точность, полнота, лишний текст, риск ошибки.
После этого считайте результат по группам задач. Один итоговый счет почти всегда скрывает полезную картину. Может оказаться, что A чаще выигрывает на извлечении данных, а B лучше пишет понятные ответы. Рядом с победами сразу смотрите цену и задержку. Модель, которая дает на 3% больше побед, но отвечает в четыре раза дольше, не всегда подойдет для продакшена.
Спорные случаи проверьте второй раз вручную. Полезный прием простой: отложить их на день и пересмотреть без первого решения перед глазами. Именно там обычно всплывают слабые критерии, неудачные примеры и задачи, которые вы зря смешали.
Пример для службы поддержки банка
У банка обычно не одна задача, а целая цепочка. Клиент пишет в чат, потом оставляет обращение в форме, а сотрудник сверяется с длинными правилами и исключениями. Если дать моделям один общий тест и свести все к среднему баллу, получится слишком гладкая картина.
Представим две модели. Модель A лучше ведет диалог с клиентом. Она держит спокойный тон, не сбивается после 6-8 сообщений и помнит, что клиент уже назвал город, тип карты и прошлую попытку решения. В живом чате это заметно сразу: клиенту не нужно повторять детали, а ответ выглядит собранным.
Но в форме обращения картина меняется. Там нет длинного диалога, зато есть поля, вложенный текст и много мелких данных. Модель B чаще правильно вытаскивает номер договора, дату операции и сумму из неаккуратного описания вроде: "Списание было 14.02, договор 4571/22, кажется, по старой карте". A в таком режиме чаще путает дату с датой обращения или теряет один реквизит.
Разница еще сильнее видна на правилах банка. Когда ответ зависит от длинного документа с оговорками, A звучит увереннее, но иногда пропускает исключение. Например, она может сказать, что перевыпуск карты бесплатный, и не заметить пункт про плату при срочном выпуске в другом городе. B отвечает суше, зато чаще попадает в правило целиком и реже додумывает лишнее.
Если посмотреть на процесс по частям, картина становится понятной:
- в клиентском чате A дает более ровный и вежливый ответ;
- в разборе форм B лучше извлекает факты;
- в правилах и регламентах B чаще точнее;
- в одном среднем балле эта разница почти не видна.
Поэтому выбор зависит не от абстрактного вопроса "кто сильнее", а от места в процессе. Если модель стоит на первой линии в чате, банку может подойти A. Если модель разбирает обращения, заполняет поля в CRM или подсказывает оператору по регламенту, B часто полезнее.
Оценка по задачам дает честнее результат, чем одна таблица со средним числом. Для продакшена нужен не общий победитель, а модель, которая меньше ошибается в вашем узком месте.
Какие ошибки чаще всего портят выводы
Самая частая причина плохих выводов проста: команда меняет сразу несколько условий и потом считает, что сравнила две модели. На бумаге это выглядит как честный тест, а по факту вы сравниваете разные настройки вокруг A и B.
Ошибка в дизайне теста
Первый сбой случается, когда для моделей пишут разные промпты. Одной дают короткую и строгую инструкцию, другой - более подробную версию с примерами, а потом смотрят на ответ и делают вывод о качестве модели. Так вы тестируете работу автора промпта, а не сами модели.
Почти так же ломает результат неравный контекст. Если модель A получила полный диалог клиента, правила, шаблон ответа и вторую попытку на перегенерацию, а модель B увидела только часть данных и ответила с первой попытки, сравнение уже испорчено. Зафиксируйте длину контекста, число попыток, температуру, max tokens и правила ретраев. Если вы гоняете тесты через единый шлюз, эти параметры лучше закрепить в конфиге и логах, иначе потом никто не поймет, почему модель вдруг стала лучше.
Ошибка в трактовке победы
Еще одна ловушка - считать победой красивый стиль там, где нужен строгий формат. Для витрины или чат-ответа приятный тон может быть плюсом. Но если задача просит JSON, заполнение полей CRM или метки для маршрутизации обращения, лишнее слово уже портит результат. Модель может писать живее и при этом проигрывать по делу, потому что ломает схему или пропускает обязательное поле.
Многие команды не считают цену ошибки. А зря. Допустим, модель отвечает чуть лучше по тону, но в 8 случаях из 100 путает статус заявки, и оператор тратит по 3 минуты на исправление. В итоге более приятная модель съедает часы ручной работы за неделю. В оценку стоит включать не только победы в тесте, но и цену переделки, число эскалаций и риск неверного действия.
И наконец, плохие выводы часто рождаются из слишком маленькой выборки. Пять удачных примеров еще ничего не доказывают. Модель A может выиграть на коротких FAQ, а модель B - на длинных инструкциях, извлечении полей и ответах по политике банка. Поэтому выбор модели для продакшена нельзя делать по нескольким красивым кейсам. Нужны десятки или сотни заданий, разбитых по типам, иначе матрица побед и проигрышей превратится в случайный снимок.
Быстрая проверка перед выбором модели
Перед запуском хватит десяти минут, чтобы отсечь плохое решение. Если смотреть только на средний балл, легко выбрать модель, которая красиво выглядит в отчете и слабо ведет себя на основном потоке запросов.
Короткий фильтр обычно работает лучше одной общей цифры:
- разбейте тесты на группы задач и не смешивайте извлечение, суммаризацию, классификацию, диалог и работу по строгому шаблону;
- смотрите победы и проигрыши по каждому примеру, а не только итоговый счет;
- считайте цену, задержку и долю брака отдельно;
- проверьте спорные ответы вручную;
- сверьте результат с главным сценарием, на который приходится большая часть нагрузки.
Такой фильтр быстро убирает ложных лидеров. Допустим, модель B выигрывает по средней оценке, но проигрывает на коротких ответах с точной структурой, а у вас именно они идут в основной поток. Тогда ее первое место мало что значит.
Отдельный подсчет цены, задержки и брака часто меняет решение сильнее, чем итоговая оценка. Для службы поддержки разница между 1.8 и 2.4 секунды ответа заметна сразу. Если к этому добавляется рост доли бракованных ответов даже на 3-4%, команда потом платит за ручные проверки.
Спорные примеры лучше не оставлять в серой зоне. Возьмите 20-30 ответов, где матрица побед и проигрышей выглядит странно, и пересмотрите их руками. После этого обычно становится ясно, где модель правда ошибается, а где тест просто смешал разные типы работы.
Если после быстрой проверки одна модель лучше на главном сценарии, укладывается в бюджет и не ломает формат ответа, этого уже достаточно для пилота. Остальное можно добрать на следующем раунде тестирования, а не растягивать выбор на недели.
Что делать с результатами дальше
Парные сравнения редко дают одного победителя на все случаи. После теста лучше не искать идеальную модель, а принять рабочее решение: оставить одну модель базовой для основного потока, а вторую держать как запасную для задач, где она стабильно сильнее.
В продакшене это особенно полезно. Одна модель может быстрее и дешевле отвечать на типовые запросы, а вторая лучше пишет длинные объяснения, аккуратнее извлекает поля или реже ошибается на спорных кейсах. Такой подход обычно честнее, чем выбор по одному среднему числу.
Результаты стоит хранить так, чтобы любой участник команды понял, почему вы сделали именно такой выбор. Лучше не ограничиваться общей оценкой, а сохранить короткую карточку решения:
- какая модель стала базовой, а какая запасной;
- на каком наборе задач вы их сравнивали;
- какая версия промпта и данных участвовала в тесте;
- где каждая модель выигрывает и где проигрывает;
- какие ограничения важны для запуска.
Такой журнал экономит время. Через месяц никто не будет вспоминать, почему команда отказалась от более дешевого варианта, если причина не записана рядом с примерами ошибок.
Сравнение нужно повторять каждый раз, когда меняется хотя бы один из трех элементов: модель, промпт или данные. Даже небольшая правка системного сообщения может поменять победителя на части задач. То же самое происходит после обновления модели у провайдера или после смены реального потока пользовательских запросов.
Если вы работаете с чувствительными данными, проверяйте требования заранее, а не после пилота. Нужны понятные аудит-логи, маскирование PII, лимиты на уровне ключа и хранение данных внутри страны, если этого требует политика компании или закон. Для команд в Казахстане такие условия можно учитывать наравне с качеством ответа. У AI Router они есть, поэтому его удобно использовать не только для сравнения моделей через один эндпоинт, но и для проверок, где важны локальное хранение данных и единые правила доступа.
Хороший итог теста выглядит просто: базовая модель, запасная модель, понятные правила переключения и сохраненная причина выбора. Тогда следующий релиз начинается не с нового спора, а с повторяемой проверки.