ACL в RAG: как закрыть доступ на уровне документа
ACL в RAG нужно применять до поиска, в ранжировании и при сборке контекста. Показываем схему, частые ошибки и короткий чек-лист.
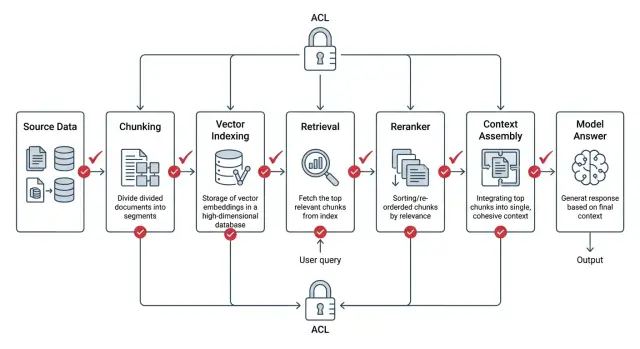
Почему обычный RAG пропускает лишнее
Обычный RAG часто проверяет права доступа слишком поздно. Система сначала ищет похожие фрагменты, потом ранжирует их, собирает контекст и только в конце решает, можно ли показывать текст пользователю. Для безопасности это плохой порядок.
Проблема начинается уже на шаге поиска. Векторный индекс понимает смысл запроса, но сам по себе не знает должность, отдел или уровень допуска. Если вы не встроили ACL заранее, запрос сотрудника колл-центра легко поднимет внутренний документ юристов или HR просто из-за похожих формулировок.
Обычно цепочка выглядит так: поиск находит самый похожий документ, даже если он закрыт; реранкер читает найденные фрагменты целиком; сборщик контекста склеивает чанки из разных мест; логи, кэш или отладочные трассировки сохраняют этот пакет. Даже если финальный ответ не покажет секретный абзац, утечка уже произошла. Чужой текст попал в память процесса, в служебный лог или в кэш повторных запросов.
Реранкер добавляет отдельный риск. Он читает текст глубже, чем простой поиск по embedding, и может поднять закрытый фрагмент выше открытого, если тот лучше отвечает на вопрос. Система сама помогает чужому документу пройти дальше по конвейеру.
Есть и более тихая ошибка: смешивание чанков. Один документ открыт для всей команды, другой доступен только финансам. Если сборщик контекста склеил их вместе по теме квартального отчета, модель получает пакет, где часть данных ей нельзя было видеть. Потом она может пересказать смысл закрытого куска своими словами, без прямой цитаты. Такие утечки особенно легко пропустить.
В ACL в RAG меняется сам взгляд на безопасность. Нельзя считать безопасным только последний экран с ответом. Проверка должна происходить до поиска, во время поиска и перед каждой передачей текста дальше по цепочке.
Простой тест хорошо это показывает. Представьте банк, где сотрудник розницы спрашивает про лимиты по кредитному продукту. Если система по пути прочитала служебную записку службы рисков с внутренними порогами, она уже увидела лишнее, даже когда ответ в чате выглядит безобидно.
Где в цепочке возникает утечка
Утечка редко живет в одной точке. Обычно это серия мелких решений, которые по отдельности кажутся безопасными.
Индексация забирает файлы из облачных папок, CRM, wiki и почты. Если конвейер сохранил текст, а правила доступа перенес частично, по старой группе или только на уровень папки, индекс уже содержит лишнее. После этого векторный поиск выбирает самые похожие чанки, а фильтр по правам накладывается позже. Это быстро, но закрытые куски уже попали в набор кандидатов.
Дальше подключается реранкер. Он читает сырой текст кандидатов, чтобы расставить их по релевантности. Если вы не отсекли лишнее раньше, он увидит договор, письмо HR или финансовый отчет, который пользователь открывать не должен. Затем ошибку может усилить генератор ответа. Если права висят на документе, а цитаты и чанки живут отдельно, модель возьмет удачную фразу из закрытого куска и вставит ее в ответ.
Логи и traces часто оказываются самым слабым местом. Команда пишет туда найденные чанки, промпт перед генерацией и текст после реранка, а потом эти записи читают разработчики, аналитики или внешняя система наблюдения. В итоге документ не попал в интерфейс, но его часть уже оказалась в другом месте.
Представьте простой случай в банке. Сотрудник филиала ищет "новый договор с поставщиком". У него есть доступ только к документам своего отдела, но retriever вытягивает десять похожих чанков, и два из них лежат в закрытой папке юристов. Финальный ответ может не показать эти куски, но реранкер уже прочитал их, а traces сохранили название файла, фрагмент суммы и несколько строк из условий.
Правило здесь жесткое: каждый компонент, который читает текст, должен получать только то, что пользователь имеет право видеть. Если компонент не должен видеть документ, ему нельзя отдавать ни текст, ни сниппет, ни embedding, ни цитату.
Как хранить права рядом с документом
Если ACL живет только у исходного файла, RAG почти всегда ломается на уровне чанков. Индекс ищет не документы целиком, а фрагменты текста. Значит, каждый чанк должен хранить свои права рядом с текстом.
У каждого чанка в индексе нужен короткий, но полный набор метаданных. Обычно хватает document_id и chunk_id, чтобы связать фрагмент с источником, acl_version и content_version, чтобы не путать старые и новые права, а также списка пользователей, групп, ролей и разрешенных действий вроде read, search, quote.
Лучше хранить не только allow-правила, но и явные запреты, если они есть в вашей системе. Тогда индекс не гадает во время поиска, а просто сравнивает метаданные чанка с правами текущего пользователя.
Права по наследованию лучше считать заранее, еще до записи в индекс. Если доступ идет от папки, проекта, отдела или класса документа, соберите итоговое правило один раз и запишите его в каждый чанк в готовом виде. Иначе на этапе ответа появятся лишние запросы к IAM, гонки версий и странные расхождения. Один сервис уже видит новое правило, другой еще держит старое, и утечка случается именно в этот момент.
Бывает и более сложный случай. Документ по кредитной политике доступен всему рисковому блоку, а приложение с расчетами внутри него открыто только руководителям группы. После чанкинга такие куски уже нельзя хранить с одним общим ACL файла. У фрагментов с приложением должен быть свой, более узкий набор прав.
Версионируйте ACL отдельно от содержимого. Если текст обновился, меняется content_version. Если изменились права, меняется acl_version, даже когда сам текст остался прежним.
После смены прав не ждите ночную переиндексацию. Старые чанки нужно сразу удалить из векторного индекса, кэшей и промежуточных хранилищ или быстро пересобрать с новой версией ACL.
Жесткое правило простое: если у чанка нет полного ACL, версии прав и явной связи с документом, такой чанк не должен попадать в индекс.
Как встроить ACL в поиск
Если ACL в RAG проверяется после поиска, система уже успела увидеть лишнее. Правильный порядок другой: приложение сначала определяет, кто делает запрос, превращает это в фильтр доступа и только потом идет в индекс. Реранкер, кэш и модель работают уже внутри разрешенного набора.
На входе разберите субъект доступа. Это может быть конкретный пользователь, его роль, отдел, сервисный аккаунт или их сочетание. Не стоит полагаться только на роль из токена, если доступ зависит еще и от команды, проекта или временного допуска.
До запроса в индекс соберите разрешенный набор. На практике это не всегда список ID документов. Чаще это фильтр по ACL-полям: отдел, владелец, уровень секретности, tenant, срок действия доступа. Если сервис прав недоступен, поиск лучше остановить, чем отвечать без фильтра.
Один и тот же фильтр должен работать во всех режимах поиска. Лексический, векторный и гибридный поиск должны видеть одинаковые границы доступа. Если векторная база не умеет фильтровать кандидатов до выдачи, нельзя тянуть широкий top-k и резать его потом в коде. Это уже поздно.
В реранкер должны попадать только кандидаты, которые уже прошли ACL. То же правило действует для сборки контекста. Чанк может наследовать право от документа, а может иметь свое более строгое правило, например для приложения к договору или скрытого раздела. В prompt должны попадать только те фрагменты, которые прошли обе проверки.
На этом цепочка не заканчивается. Перед ответом права стоит проверить еще раз. Ошибка часто сидит в хвосте пайплайна: шаблон ответа подтягивает заголовок запрещенного файла, кэш сохраняет чужой контекст по тому же вопросу, а логи пишут полный текст найденных фрагментов.
Кэш должен учитывать не только текст запроса, но и отпечаток прав доступа. Логи и трассировки лучше хранить по ID документов, оценкам и служебным меткам, без сырых кусков текста. Если вызовы моделей идут через AI Router, это может помочь на соседнем слое инфраструктуры: сервис поддерживает аудит-логи, маскирование PII и хранение данных внутри Казахстана. Но ACL внутри retrieval все равно нужно строить в вашем индексе.
Короткий пример. Сотрудник отдела продаж спрашивает условия партнерского договора. В индексе лежит очень похожий договор юристов, и по смыслу он даже ближе к вопросу. Если фильтр по роли и отделу сработал до поиска кандидатов, этот документ не увидят ни поиск, ни реранкер, ни модель.
Пример с ролями и отделами
Представьте одну корпоративную базу знаний. В ней лежат инструкции поддержки, шаблоны договоров, HR-регламенты и внутренние разборы клиентских жалоб. Поиск у всех общий, но ответы у всех должны быть разными.
Сотрудник поддержки вводит запрос: "правила возврата товара без чека". Система ищет только в его контуре: статьи базы знаний поддержки, утвержденные скрипты и свежие правила по возвратам. Она не трогает папку юристов с договорными оговорками и не тянет HR-документы, даже если там есть похожие слова вроде "обращение", "жалоба" или "срок ответа".
Юрист пишет почти то же самое: "шаблон договора на возврат". Слова пересекаются, но набор документов уже другой. Поиск берет только документы юридического отдела: шаблоны, согласованные версии, комментарии к пунктам. Если в базе поддержки есть статья с частым словом "договор", модель все равно не должна увидеть этот чанк.
Похожая история с HR. Допустим, HR-специалист ищет "жалоба сотрудника". В векторном индексе могут найтись похожие куски из клиентской поддержки, потому что там тоже часто встречается слово "жалоба". Если права доступа встроены правильно, система отрежет эти чанки еще до ранжирования и до передачи в модель. HR получит только кадровые регламенты, формы обращений и инструкции по эскалации.
Один и тот же поиск ведет себя по-разному из-за контекста пользователя. Поддержка видит статьи по возвратам и скрипты общения с клиентом. Юрист видит договоры, приложения и правки своего отдела. HR видит кадровые процедуры и формы внутренних обращений. Никто не получает чанки из чужого отдела "на всякий случай".
Теперь представьте перевод сотрудника из поддержки в отдел качества. Здесь ломаются многие схемы. Если система хранит доступ на уровне документа и проверяет права на каждом запросе, набор доступных чанков меняется сразу после обновления роли. Старые результаты поиска, сохраненные подборки и кэш тоже надо пересчитать или сбросить. Иначе человек уже ушел в другой отдел, а поиск еще некоторое время показывает прежний контур.
Хорошая проверка проста: дайте трем сотрудникам похожий запрос и сравните не только финальный ответ, но и список чанков, который ушел в модель. Если наборы пересекаются там, где не должны, проблема уже есть.
Ошибки, которые открывают лишнее
Чаще всего утечку делает не модель, а порядок действий вокруг поиска. Одна небольшая уступка быстро ломает всю схему: пользователь не должен видеть документ, но система все равно берет его текст на промежуточном шаге и уже потом пытается что-то отфильтровать.
Самая частая ошибка выглядит безобидно. Команда сначала получает top-k результатов из индекса, затем убирает запрещенные документы и считает, что все в порядке. Но лишний текст уже успел попасть в ранжирование, в кэш, в логи или в контекст следующего шага. Фильтр должен срабатывать до выдачи кандидатов наружу.
Еще одна проблема возникает, когда права доступа хранят на уровне файла, а сам файл потом режут на чанки без наследования правил. В итоге один PDF закрыт для отдела продаж, но его куски лежат в индексе как обычные записи без ACL. Поиск находит такой чанк по хорошему совпадению, и модель получает абзац, который пользователь не должен был видеть.
Кэш часто подводит сильнее, чем сам индекс. Если система сохраняет результаты поиска только по запросу, а не по пользователю, роли и набору разрешений, другой человек может получить чужую выдачу. Это особенно неприятно в коротких вопросах вроде "план найма" или "условия договора", где совпадения повторяются.
Есть и менее заметный сбой: тестовый индекс смешивают с боевым. Разработчик загружает примеры, старые выгрузки или документы для проверки качества поиска, а потом забывает их убрать. Внешне все работает нормально, но часть ответов начинает тянуть куски из данных, которых в боевой среде вообще не должно быть.
Отладка тоже часто открывает лишнее. Команда включает дампы запросов, найденных чанков и финального промпта, чтобы понять, почему поиск ошибся. Это полезно на пару дней. Но если такие дампы живут неделями, они становятся отдельным архивом чувствительных данных. Иногда исходный документ уже удалили, а его текст все еще лежит в логах.
Для быстрой самопроверки хватает пяти вопросов. ACL применяется до поиска кандидатов? Права наследуются на каждый чанк, а не только на файл? Кэш привязан к пользователю, роли и версии прав? Тестовые данные отделены от боевых? У отладочных дампов короткий срок жизни? Если хотя бы на один вопрос ответ неуверенный, риск уже есть.
Проверки перед релизом
Перед релизом полезнее не смотреть на красивую схему, а прогнать короткие тесты на живых данных. ACL в RAG ломается на стыке поиска, реранка, кэша и логов. Если проверить только финальный ответ, можно пропустить утечку еще до того, как модель начала писать текст.
Начните с двух ролей и одного запроса. Система должна вернуть разный набор чанков, если права у ролей отличаются. Смотрите не только на итоговый ответ, но и на список кандидатов после retrieval. Если у бухгалтера и сотрудника поддержки совпадает выдача там, где она не должна совпадать, фильтр стоит слишком поздно.
Отдельно проверьте реранкер. Он не должен получать ни одного закрытого чанка, даже если потом такой чанк не попадет в итоговый контекст. Это частая ошибка: команда фильтрует выдачу после реранка и считает, что все исправила. На деле закрытый текст уже прошел через промежуточный шаг.
Затем запросите документ без доступа и прочитайте ответ глазами обычного пользователя. Хорошая система не цитирует закрытый фрагмент, не называет его заголовок и не пересказывает смысл абзаца своими словами. Отказ должен быть коротким и сухим. Если модель пишет что-то вроде "я не могу показать документ, но там сказано...", тест провален.
После этого измените права у одного документа и засеките время. После смены ACL должны обновиться индекс, retrieval-кэш, кэш промптов и любые сохраненные наборы кандидатов. Нужен понятный срок: сразу или в течение нескольких минут. Вариант "после ночной задачи" здесь слишком слабый.
Наконец, откройте аудит-лог и найдите один конкретный запрос. В нем должны быть actor id, tenant, роль, набор сработавших фильтров, ID чанков до и после фильтрации и причина отказа, если она была. Если вы используете отдельный шлюз для вызова моделей, полезно проверить, что этот след не теряется между поиском, политиками и самим LLM-вызовом.
Есть один нюанс, который часто пропускают. Проверяйте не только "правильные" запросы, но и пограничные случаи: опечатки, очень короткие формулировки, широкие запросы и повторный запрос сразу после смены прав. Именно там обычно всплывает старый кэш или неверный fallback.
Если эти проверки проходят стабильно, шанс неприятного сюрприза в проде заметно ниже. Если хотя бы одна плавает, релиз лучше задержать на день, чем потом разбирать утечку по логам.
Что делать после запуска
Сразу после запуска не подключайте все источники данных разом. Возьмите один источник и простую матрицу ролей, где правила легко проверить вручную. Например, оставьте несколько ролей с понятными границами: HR видит кадровые документы, юристы видят договоры, остальные не видят их совсем. Такой узкий старт быстрее показывает, где ACL в RAG работает честно, а где поиск все еще тянет лишнее.
Потом соберите негативные тесты. Они полезнее обычных happy path проверок. Нужны запросы от тех, кто не должен получить ни одного чанка, ни названия документа, ни кусочка метаданных. Хорошо работают простые сценарии: сотрудник продаж ищет приказы HR по фамилии коллеги; подрядчик задает общий вопрос, который раньше находил внутренние регламенты; менеджер ищет старое название документа после переименования; пользователь без доступа формулирует запрос через синонимы и сокращения.
Если в таких тестах модель отвечает слишком уверенно, проблема обычно не в самой модели. Чаще течет фильтр на этапе retrieval, повторное ранжирование или сборка контекста.
В первые недели полезно смотреть не на один общий график, а на три метрики отдельно: recall после ACL, задержку и число отказов. Если после включения фильтров поиск стал возвращать сильно меньше релевантных чанков, вы могли слишком грубо отрезать доступ. Если выросла задержка, проверьте, где именно вы фильтруете: до векторного поиска, после него или на обоих этапах. Если число отказов резко пошло вверх, часто ломается связка между ролью пользователя и атрибутами документа.
Эти метрики лучше раскладывать по ролям и по источникам. Тогда видно, что проблема живет не во всей системе, а, например, только в одном индексе или в одной группе сотрудников.
Если вы строите LLM-сервис в Казахстане, правовые ограничения лучше учитывать сразу. До подключения реальных документов проверьте, где хранятся данные, остается ли хранение внутри страны, как маскируется PII и кто видит журнал аудита. Работа скучная, но она обычно и спасает от самых неприятных сюрпризов после пилота.
Инфраструктурный слой для вызова моделей тоже стоит отделять от логики ACL в поиске. Если команде нужен единый OpenAI-совместимый шлюз с хранением данных внутри Казахстана, маскированием PII и аудит-логами, можно отдельно оценить AI Router на airouter.kz. Он не заменяет фильтрацию документов в вашем индексе, но закрывает соседний риск: кто, куда и с какими данными отправляет запросы к моделям.
Главная мысль простая: в безопасном RAG модель вообще не должна видеть лишнее. Не в финальном ответе, не в реранкере, не в кэше и не в логах. Если закрытый чанк хоть раз попал в цепочку, проблема уже случилась.