Автоматическое отсечение провайдера при сбоях без флаппинга
Автоматическое отсечение провайдера при сбоях снижает каскадные ошибки: разберем окна ошибок, пороги, возврат трафика и быстрые проверки перед продом.
Что происходит, когда канал падает
Сбой у провайдера почти никогда не выглядит как мгновенный обрыв. Сначала растут таймауты, потом приходят отдельные 5xx, затем ошибки идут сериями. За несколько минут канал может перейти из состояния "иногда отвечает" в состояние "съедает очередь и почти ничего не возвращает".
Хуже всего то, что деградация копится тихо. Один таймаут легко принять за случайность. Два подряд уже замедляют очередь. Десять таймаутов за короткий промежуток меняют поведение всей системы: воркеры заняты дольше, соединения висят, новые запросы ждут. Пользователь видит не только ошибки, но и резкий рост задержки.
Ретраи часто добивают ситуацию. Если система сразу повторяет запрос в тот же проблемный канал, она сама добавляет нагрузку туда, где и без того узкое место. Был один неудачный вызов - стало два или три. Провайдер отвечает еще медленнее, очередь растет быстрее, а шанс на успех почти не меняется. Через несколько минут трафик сам добивает канал, который еще мог пережить короткий всплеск.
Проблема быстро выходит за пределы одного маршрута. Пока роутер ждет таймаут или держит несколько повторов на плохом провайдере, общий пул соединений и рабочие потоки заняты. Из-за этого даже запросы, которые могли бы уйти в нормальный канал, получают лишние 200-500 мс, а иногда и больше. На графике это видно как расползание задержки по всей системе, а не только по одному провайдеру.
Краткий всплеск и настоящая деградация в первые секунды похожи. Разница проявляется дальше. При коротком всплеске ошибки быстро заканчиваются, а успешные ответы все еще преобладают. При деградации проблема держится дольше одного окна наблюдения: растут и ошибки, и задержка, а доля успешных ответов падает с каждой минутой.
В LLM шлюзе это особенно заметно, потому что трафик к разным провайдерам проходит через один слой API. Если не отделить шум от реального сбоя, система начнет метаться между маршрутами. Если ждать слишком долго, падающий канал успеет испортить задержку всему потоку. Первые минуты решают почти все.
Какие ошибки считать
Если считать подряд все неуспешные ответы, схема быстро начинает врать. Она наказывает провайдера даже там, где проблема в лимите, в конкретной модели или в самом запросе.
Обычно в счет отказов включают три типа сбоев: таймауты, 5xx и обрывы соединения. Это хорошие сигналы реальной нестабильности канала. Провайдер не ответил вовремя, вернул серверную ошибку или оборвал запрос на середине.
Код 429 лучше считать отдельно. Он часто говорит не о полной недоступности, а о том, что вы уперлись в квоту, лимит или локальный rate limit. Если смешать 429 с таймаутами и 5xx, роутер начнет уводить трафик так, будто провайдер умер, хотя он просто просит сбавить темп.
Ошибки клиента тоже не стоит класть в ту же корзину. Слишком длинный prompt, сломанный JSON или неверный параметр модели - это не проблема провайдера. Коды 4xx, кроме отдельно обработанного 429, лучше исключить из логики отсечения.
Есть еще один частый промах: считать только провайдера целиком. У одного и того же партнера одна модель может работать ровно, а другая - с задержками и редкими 502. Если отрезать весь пул сразу, вы потеряете рабочий канал без пользы. Поэтому метрики лучше собирать в разрезе "провайдер + модель", а решение о полном отключении принимать уже после этого.
Нужен и нижний порог по трафику. Если модель получила два запроса и оба упали, это еще не статистика. Практичнее начинать доверять метрике, когда в окне накопилось хотя бы 20-50 запросов. Отдельные пороги для 5xx и таймаутов тоже помогают: иногда провайдер не падает целиком, а просто начинает отвечать слишком медленно. Для 429 полезнее снижать нагрузку или включать backoff, а не резать канал сразу.
Такая фильтрация делает автоматическое отсечение спокойнее. Система убирает действительно проблемный маршрут и не начинает дергать трафик из-за чужой ошибки в запросе или короткого всплеска лимитов.
Как выбрать окно и пороги
Слишком короткое окно делает систему нервной. Слишком длинное держит трафик в плохом канале дольше, чем нужно. Поэтому длину окна лучше подбирать под тип нагрузки, а не брать одно значение по умолчанию.
Для чата обычно хватает 30-60 секунд. Там нужна быстрая реакция: если провайдер начал сыпать 5xx или таймауты, пользователи замечают это сразу. Для batch задач окно можно сделать длиннее, например 3-10 минут. У пакетной обработки другая цена ошибки: редкий всплеск не так страшен, а ложное отключение может перегнать большой объем запросов в более дорогой или медленный канал.
Один порог почти всегда дает плохой результат. Лучше сочетать две проверки: долю ошибок в окне и число сбоев подряд. Доля ошибок ловит постепенную деградацию, когда провайдер отвечает нестабильно. Серия подряд идущих ошибок ловит резкое падение, когда канал фактически умер.
Как стартовый вариант можно взять такие настройки:
- для чата: окно 60 секунд и отсечение при 20-30% ошибок
- для чата: мгновенное отсечение при 5-7 сбоях подряд
- для batch задач: окно 5 минут и отсечение при 10-15% ошибок
- для batch задач: отдельный лимит на таймауты, если они забивают очередь
Без нижнего порога по трафику правило часто дает ложный сигнал. Если за минуту прошло всего три запроса и один из них упал, вы уже видите 33% ошибок, хотя это обычный шум. Поэтому полезно не принимать решение, пока канал не получил хотя бы 20-50 запросов в окне. Для редкого трафика можно смотреть не только на процент, но и на абсолютное число ошибок.
Порог стоит проверить на коротких всплесках. Допустим, провайдер дал четыре таймаута из сорока запросов во время сетевого сбоя. Если правило срабатывает уже на этом уровне, маршрут начнет дергаться без реальной пользы. Схема должна ловить поломку, а не любой шум.
Если вы ведете модели через единый шлюз, пороги лучше разделить по сценариям. Интерактивный чат, пакетная разметка и внутренние пайплайны почти никогда не должны жить с одним и тем же окном ошибок.
Как вернуть трафик без флаппинга
После сбоя не открывайте канал сразу, даже если провайдер снова отвечает. Короткий удачный отрезок еще не значит, что проблема ушла. Сервис часто оживает на пару минут, а потом снова начинает сыпать 5xx, 429 или резко замедляться.
Сначала дайте каналу остыть. Обычно хватает cooldown на 5-15 минут, но точное время зависит от частоты запросов и цены повторного сбоя. Если система только что отключила маршрут, лучше подождать чуть дольше, чем снова загнать поток в нестабильный канал.
Перед возвратом боевого трафика отправьте несколько пробных запросов. Они должны быть похожи на реальные: тот же размер prompt, тот же тип ответа, тот же лимит по времени. Формальная проверка вида "получили 200 OK" слишком слабая. Канал может отвечать, но делать это в три раза медленнее обычного.
Рабочая схема простая: сначала вернуть 5% трафика и подождать 3-5 минут, потом поднять долю до 15%, затем до 50%, и только после стабильного окна открыть 100%. Маленькие доли гасят флаппинг лучше, чем мгновенный полный возврат. Если канал снова начинает тормозить, вы теряете лишь часть потока, а не весь трафик.
Смотрите не только на ошибки. Если задержка быстро растет, возврат тоже стоит отменить. Для пользователя длинный ответ почти так же плох, как и явная ошибка. Поэтому полезно держать отдельный порог по latency и возвращать канал в cooldown, если он выходит за рабочий предел хотя бы в одном-двух окнах подряд.
Хорошее правило звучит скучно, но работает: любой заметный рост ошибок или задержки во время ramp-up возвращает маршрут в cooldown. Без ручных исключений и без "давайте еще немного подождем". Именно такие послабления обычно и ломают схему.
Как настроить схему по шагам
Сначала зафиксируйте цель. Не для платформы в целом, а для каждого сценария отдельно. Клиентский чат, внутренний поиск и ночная пакетная обработка терпят разную задержку и разный процент ошибок. Если смешать их в один набор правил, вы быстро получите ложные отключения.
Дальше настройка обычно идет так:
- Опишите 2-4 сценария и задайте для каждого свой SLO. Для онлайн чата важны быстрый ответ и низкая доля таймаутов. Для batch задач важнее общий процент успешных запросов.
- Выберите метрики, которые реально влияют на опыт пользователя: error rate, latency и timeout rate. Этого обычно достаточно.
- Возьмите прошлые инциденты и поставьте стартовые пороги по фактам, а не по догадке. Если во время сбоя timeout rate поднимался выше 7%, а p95 latency уходила за 10 секунд, начните с этих чисел.
- Прогоните правила на исторических логах. Так вы увидите, сколько раз схема отключила бы провайдера зря и где окно выбрано неудачно.
- Включайте fallback сначала на небольшой доле трафика. Часто хватает 5-10%, чтобы проверить логику на реальной нагрузке и не устроить лишний перенос запросов.
После этого добавьте ручное отключение для дежурной смены. Автоматика не успевает за всеми редкими случаями: частичной деградацией, проблемой в одном регионе или странным всплеском 429. У дежурного должен быть простой способ убрать провайдера из ротации на 15-30 минут и потом вернуть его после проверки.
Если вы работаете через единый шлюз, удобно считать эти правила на уровне провайдера, модели и API ключа. Тогда команда видит не абстрактное "все плохо", а точную картину: у какого провайдера растет задержка, где пошли таймауты и на каком трафике запасной маршрут уже помог.
Хорошая стартовая схема обычно скучная. Это плюс. Она режет только явные сбои, не дергает трафик каждые пять минут и оставляет дежурным понятный ручной контроль.
Пример с двумя провайдерами
Представьте чат бот контакт центра банка. Он отвечает на частые вопросы: баланс, блокировка карты, статус перевода, смена лимита. В обычный день почти весь поток идет через основного провайдера, потому что тот держит ровный отклик и редко дает сбои.
Проблема начинается не в одну секунду. Сначала ответы просто замедляются, потом растут таймауты, и через пару минут канал уже тянет вниз весь сервис. Если в этот момент гонять запросы туда и обратно, пользователи увидят то тишину, то резкие задержки. Поэтому схему отключения лучше строить не на одном неудачном запросе, а на окне ошибок и минимальном объеме трафика.
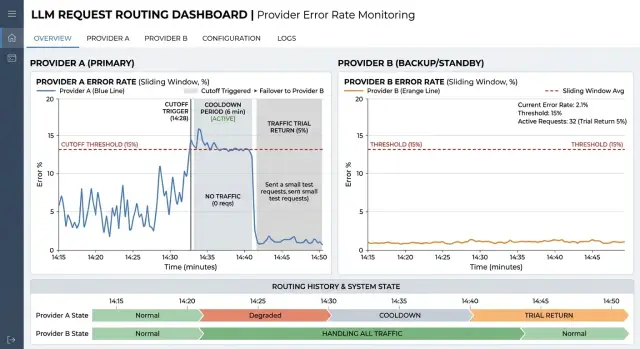
У банка может быть такое правило: окно 120 секунд, считаем только таймауты и 5xx, а 4xx не трогаем. Канал отключается, если за это окно прошло не меньше 200 запросов и доля сбоев превысила 18%. Один случайный всплеск порог не пробьет. Зато настоящий инцидент система заметит быстро.
Дальше картина выглядит так:
- в 10:00 основной провайдер отвечает нормально, средняя задержка в обычных границах
- к 10:01 таймаутов становится больше, но их еще мало для отключения
- к 10:02 за последние 120 секунд набирается 240 запросов, из них 52 заканчиваются таймаутом или 5xx
- правило срабатывает, и резервный маршрут принимает весь трафик до конца инцидента
Минимум по числу запросов здесь особенно полезен. Без него канал можно отключить из-за трех ошибок на маленьком потоке, хотя это обычный шум. На контакт центре банка это хорошо видно ночью, когда запросов меньше, а случайный сбой выглядит страшнее, чем есть на самом деле.
Когда инцидент у основного провайдера заканчивается, не стоит сразу возвращать на него весь поток. После cooldown, например пяти минут без новых признаков аварии, система отправляет обратно только 10% трафика на проверку. Если таймауты не растут, долю можно поднимать дальше: до 25%, потом до 50%, и только потом до 100%.
Такая схема сокращает простой без флаппинга. Бот продолжает отвечать через резерв, а основной канал получает время спокойно восстановиться и показать, что он снова держит нормальную нагрузку.
Где команды ошибаются
Самая частая ошибка - один и тот же порог для всех моделей, всех провайдеров и всех сценариев. Это почти всегда дает перекос. Короткий запрос на классификацию и длинный чат живут в разном ритме, а небольшая open weight модель и большая frontier модель дают разную норму по задержке и таймаутам. Если правило одно для всех, вы либо режете живой канал слишком рано, либо держите мертвый слишком долго.
Еще один промах - смотреть только на число ошибок без объема трафика в окне. Три неудачных запроса подряд звучат тревожно, но ночью это может быть всего 12 запросов за 10 минут. Тогда система реагирует не на сбой провайдера, а на шум. При низком трафике нужен минимум по числу запросов, например 30 или 50 попыток в окне.
Многие считают ответы 400 и 422 отказом провайдера. Это ломает схему. Такие коды часто говорят о плохом запросе, слишком длинном контексте, неверном формате или ошибке в валидации. Если смешать их с 5xx, таймаутами и сетевыми обрывами, маршрутизация начнет лечить не тот сбой.
С 429 путаницы не меньше. Rate limit и полная недоступность - разные вещи. Если провайдер ограничил скорость, иногда достаточно уменьшить долю трафика, включить очередь или перевести часть запросов на запасной канал. Если считать 429 тем же, что и таймаут, система слишком резко отключит маршрут и создаст лишний скачок нагрузки у соседнего провайдера.
Самый дорогой промах происходит при возврате трафика. Канал дал один успешный ответ, и команда тут же возвращает на него 100% запросов. Через минуту он снова падает, потом оживает, и начинается флаппинг. Нормальная схема возвращает поток ступенчато: 5%, потом 20%, потом 50%, и только после стабильного окна - полный объем.
Есть и более тихая ошибка: правила проверяют днем на тестовой нагрузке и забывают про ночь и пик. Одно и то же окно ведет себя по-разному при 40 запросах в минуту и при 4000. Поэтому пороги стоит сверять отдельно для низкой, обычной и пиковой нагрузки.
Чек-лист перед запуском
Перед запуском полезно пройтись по короткому списку.
- В окне должно быть достаточно запросов. Если на модель приходит 3-5 запросов в минуту, короткое окно почти ничего не значит. Для редкого трафика берите окно длиннее и задавайте минимум наблюдений, например 30-50 запросов.
- Разделите 429 и 5xx. Код 429 чаще говорит о лимите, а не о поломке. В таком случае сначала лучше снизить долю трафика или включить backoff.
- После отсечения задайте cooldown. Пока он не прошел, не возвращайте обычный поток. Сначала дайте пробную долю, например 1-5%, и смотрите на новое окно ошибок.
- Дашборд должен показывать метрики отдельно по провайдеру и по модели. Иначе вы увидите только общую деградацию и не поймете, падает весь канал или одна конкретная модель.
- У команды должен быть ручной override и журнал решений. Дежурный инженер должен суметь исключить провайдера, вернуть его в ротацию и потом открыть запись с причиной: какой порог сработал, в каком окне и кто изменил состояние.
Перед продом полезно устроить короткий прогон на тестовом трафике. Поднимите долю 5xx у одного провайдера, отдельно смоделируйте 429 и проверьте, что схема ведет себя по-разному. Если в журнале видно каждое решение, а на дашборде легко найти проблемную модель, запуск пройдет заметно спокойнее.
Что сделать после первого релиза
После запуска не меняйте правила на второй день. Дайте схеме прожить хотя бы неделю и соберите метрики в одном месте: долю ошибок по каждому провайдеру, число отключений, длительность простоя, время возврата трафика и жалобы со стороны приложения. За эту неделю обычно становится понятно, где система действительно ловит сбой, а где реагирует на короткий шум.
Потом разберите реальные инциденты вручную. Смотрите не только на сам факт сбоя, но и на цену реакции. Иногда схема правильно уводит запросы с падающего канала. Иногда она слишком рано переключает поток на более дорогой или медленный маршрут. Это нормально. Первые правки почти всегда появляются именно после такого разбора.
Раз в месяц полезно пересматривать окно ошибок и пороги по журналу инцидентов, а не по памяти команды. Обычно достаточно ответить на четыре вопроса: сколько было ложных отключений, сколько сбоев схема пропустила, как быстро трафик вернулся после нормализации и сколько стоило переключение по задержке и деньгам.
Хотя бы один раз стоит устроить учебный сбой на тестовом трафике. Принудительно дайте одному провайдеру серию 5xx, таймауты или резкий рост задержки и проверьте, что система отключает канал, не уходит во флаппинг и спокойно возвращает поток назад. Лучше найти проблему на 1% тестовых запросов, чем в полном проде.
После этого проверьте не только технику, но и требования к данным. Маршрутизация не должна ломать хранение данных в нужной стране, маскирование PII и журнал аудита. Если часть запросов нельзя выводить за пределы страны, а часть нужно хранить с полным следом действий, это стоит закрепить в правилах маршрута и в тестах.
Если команде тяжело поддерживать такую логику поверх нескольких API и провайдеров, этот слой часто выносят в отдельный шлюз. Например, AI Router на airouter.kz дает один эндпоинт, совместимый с OpenAI, для разных моделей и провайдеров. В таком случае проще держать в одном месте маршрутизацию, журнал аудита, маскирование PII и требования по хранению данных внутри страны без правок в каждом сервисе отдельно.
Часто задаваемые вопросы
Какие ошибки правда стоит считать сбоем провайдера?
Считайте таймауты, 5xx и обрывы соединения. Эти сигналы обычно говорят, что канал реально нестабилен.
429 держите отдельно: он чаще указывает на лимит, а не на полную поломку. Ошибки клиента вроде 400 или 422 в отсечение не включайте, потому что их вызывает сам запрос.
Почему нельзя просто ретраить запрос в тот же падающий канал?
Потому что вы сами раздуваете нагрузку на слабое место. Один неудачный вызов быстро превращается в два или три, очередь растет, а шанс на успех почти не меняется.
Лучше быстро увести запрос в запасной маршрут или дать backoff, чем добивать тот же канал повторами.
Какое окно ошибок выбрать для чата и для batch-задач?
Для чата обычно хватает окна 30–60 секунд. Пользователь быстро замечает задержку, поэтому роутер должен реагировать без долгой паузы.
Для batch-задач окно лучше сделать длиннее, часто 3–10 минут. Так вы не отключите маршрут из-за короткого всплеска и не перегоните большой объем в более дорогой канал.
Нужен ли минимум запросов в окне?
Да, без этого правило часто дергается на шум. Если за окно прошло три запроса и один упал, процент выглядит страшно, но вывод делать рано.
На старте удобно брать минимум 20–50 запросов в окне. Для редкого трафика окно можно удлинить и смотреть не только на процент, но и на абсолютное число сбоев.
Почему метрики лучше считать по связке провайдер и модель?
Потому что у одного провайдера одна модель может работать ровно, а другая — сыпать 502 и таймаутами. Если вы режете провайдера целиком, вы теряете живой маршрут без пользы.
Собирайте метрики в разрезе провайдер + модель, а уже потом решайте, стоит ли отключать весь пул.
Какой порог взять на старт, если точных данных еще нет?
Обычно лучше работает не один порог, а две проверки сразу. Первая смотрит на долю ошибок в окне, вторая ловит серию подряд идущих сбоев.
Для чата можно начать с окна 60 секунд, отсечения при 20–30% ошибок и мгновенного отключения при 5–7 сбоях подряд. Для batch часто подходит окно 5 минут и порог 10–15%, плюс отдельный контроль таймаутов.
Как вернуть трафик после сбоя и не получить флаппинг?
Не открывайте канал сразу на весь поток. Сначала дайте ему cooldown на 5–15 минут, потом отправьте несколько пробных запросов, похожих на боевые.
Если ответы нормальные, возвращайте трафик ступенчато: сначала маленькую долю, потом среднюю, и только после стабильного окна — полный объем. Если ошибки или задержка снова растут, сразу верните маршрут в cooldown.
Что делать с ошибками 429?
Сначала уменьшите нагрузку на этот маршрут. Часто помогает backoff, очередь или перенос части запросов на запасной канал.
Не смешивайте 429 с таймаутами и 5xx. Иначе роутер решит, что провайдер умер, хотя тот всего лишь просит сбавить темп.
Где команды чаще всего ошибаются в такой схеме?
Часто команды ставят один порог для всех сценариев, не задают минимум трафика в окне и считают клиентские 4xx отказом провайдера. Из-за этого схема то режет живой канал, то держит плохой слишком долго.
Еще одна дорогая ошибка — вернуть 100% трафика после одного удачного ответа. Так вы почти наверняка получите новый провал через пару минут.
Когда пересматривать пороги и что проверить после первого релиза?
После запуска не трогайте настройки в первый же день. Дайте схеме прожить хотя бы неделю, соберите число отключений, длительность сбоев, время возврата и жалобы со стороны приложения.
Потом разберите реальные инциденты вручную и раз в месяц сверяйте пороги с журналом. Если вы работаете через единый шлюз, сразу проверьте и правила по данным: хранение внутри страны, маскирование PII и аудит не должны ломаться при переключении маршрута.