Backpressure для LLM-сервиса без каскадной аварии
Backpressure для LLM-сервиса помогает пережить пики нагрузки: разберём очереди, лимиты и сброс второстепенных запросов без каскадной аварии.
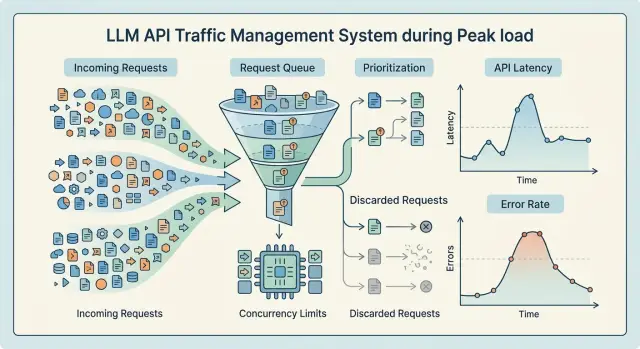
Что ломается при наплыве запросов
При резком росте трафика сервис редко падает сразу с 5xx. Сначала растет задержка. Очередь на входе удлиняется, воркеры дольше заняты, соединения висят до таймаута. Пользователь еще получает ответ, но уже не за 2 секунды, а за 10-15.
Это самый неприятный момент. Снаружи система выглядит живой, а внутри запас почти закончился. Если смотреть только на ошибки, легко пропустить точку, после которой очередь уже не удается вернуть в норму.
Для LLM это обычная картина. Длинный запрос дольше держит не только слот выполнения. Он занимает память, сеть, пул соединений, а иногда еще тянет за собой логирование, модерацию и маскирование PII. Поэтому задержка растет раньше, чем появляются заметные 5xx.
Пик часто раздувают сами клиенты
Когда ответ идет медленно, клиенты начинают ретраить. Иногда это делает SDK, иногда пользователь просто жмет кнопку еще раз. Один исходный запрос превращается в два или три, и перегрузка растет именно в тот момент, когда системе уже тяжело.
Обычно цепочка выглядит так: клиентский таймаут срабатывает раньше, чем сервис закончит работу, клиент отправляет повтор, а старый запрос все еще висит в обработке. Очередь начинает расти быстрее, чем сервис успевает ее разбирать.
Такой пик не похож на один большой сбой в одну секунду. Он идет волнами. Сначала увеличивается latency, потом начинаются локальные таймауты, затем часть узлов перегружается, и повторные запросы добивают соседние части системы.
Отдельная проблема - один медленный узел. Если провайдер, GPU-хост или воркер начал отвечать хуже остальных, балансировка не всегда спасает. Запросы к нему висят дольше, занимают слоты, а общая очередь тормозит весь путь. В шлюзе вроде AI Router это может выглядеть так: один маршрут к модели замедлился, а потом выросло время ответа всего OpenAI-совместимого эндпоинта, потому что общий пул ресурсов уже занят.
Каскадная авария почти никогда не начинается как полный обрыв. Чаще это серия мелких сбоев, которые подпирают друг друга. Сначала сервис просто стал чуть медленнее. Через несколько минут он уже не успевает разгребать хвост, и даже обычный трафик начинает выглядеть как атака.
Если в этот момент не резать очередь, не ограничивать параллелизм и не убирать второстепенные запросы, система продолжит деградировать, пока не начнет ронять уже самый нужный трафик.
Где возникает затор
При всплеске трафика затор редко начинается только в модели. Чаще он появляется раньше, на входе: API принимает запросы быстрее, чем система успевает их проверить, промаркировать, замаскировать PII и отправить на выполнение. Если входной API и исполнение живут в одном слое, воркеры зависают на долгих ответах модели, и новый трафик сразу давит на весь сервис.
Поэтому входной API лучше отделять от очереди исполнения. Первый слой быстро делает простые вещи: аутентификацию, валидацию, базовые лимиты и запись задания в очередь. Второй слой забирает задачи только по мере свободных слотов. Тогда короткий всплеск не превращается в общую пробку.
Следующий частый затор - параллельные вызовы к моделям и провайдерам. У каждой модели своя скорость, у каждого провайдера свои квоты и своя задержка. Один общий лимит для всех почти всегда работает плохо. Короткие запросы начинают ждать тяжелые, а легкий маршрут страдает из-за медленного соседа. Это особенно заметно, когда часть трафика идет во внешние модели, а часть - на свои GPU: очередь одна, а пределы у этих путей разные.
Чаще всего поток тормозят смешанные очереди, лимиты одновременных вызовов к конкретной модели или провайдеру, пул исходящих соединений и слишком длинные таймауты. Не меньше проблем создают логирование, аудит-логи, база и хранилище. Эти узлы часто кажутся второстепенными, пока внезапно не начинают тормозить весь запрос.
Длина контекста тоже меняет картину. Один запрос с большим контекстом может держать слот дольше, чем десять коротких. Снаружи это выглядит как случайная просадка, хотя причина простая: система считает запросы поштучно, а ресурсы тратятся по токенам и времени выполнения.
Пул соединений часто недооценивают. Если он мал, запросы ждут свободное соединение еще до вызова модели. Если таймауты слишком щедрые, зависшие запросы дольше держат сокеты и воркеры. В итоге очередь растет даже при умеренном RPS.
Еще один слой, про который часто забывают, - запись событий. Медленная база, синхронные аудит-логи или тяжелое логирование ответа могут тормозить не хуже самой модели. Для сервисов, где нужны хранение данных внутри страны, маскирование PII и аудит, это особенно заметно.
Смотрите на весь путь запроса, а не только на время ответа модели. Если у вас шлюз вроде AI Router, полезно разнести метрики по входному API, очереди, вызовам к провайдерам и служебным записям. Тогда затор видно сразу, и его проще остановить до аварии.
Какие лимиты задать заранее
Бесконечная очередь почти всегда вредит. Снаружи кажется, что сервис еще держится, а внутри копится долг: растет задержка, память уходит под буферы, воркеры висят дольше обычного, ретраи съедают остатки запаса. Иногда часть запросов лучше отклонить сразу, чем мучить всю систему.
Первый лимит - длина очереди. Причем ограничивать ее стоит не только по числу запросов, но и по ожидаемому объему токенов. Короткая классификация и длинная генерация нагружают систему по-разному. Если считать только количество задач, очередь может выглядеть безопасной, хотя на деле уже забит весь пул модели.
Второй лимит - число in-flight запросов на каждый маршрут. Не один общий предел на весь API, а отдельные рамки для тяжелых и легких путей. Интерактивный чат, embeddings и ночная пакетная обработка не должны спорить за один и тот же остаток емкости. В шлюзе, который отправляет трафик к разным моделям и провайдерам через один эндпоинт, это видно особенно быстро: один медленный маршрут тянет вниз соседние.
Таймауты тоже лучше делить по этапам. Один общий лимит в 60 секунд редко помогает понять, где начался затор. Практичнее задать короткий бюджет на ожидание места в очереди, отдельный бюджет на соединение и ответ от апстрима, свой лимит на генерацию или стриминг и еще один короткий лимит на постобработку и запись логов. Если этап не уложился в свой бюджет, сервис должен завершить его сразу. Иначе перегрузка копится скрытно: клиент еще ждет, но система уже проиграла.
С ретраями нужна жесткость. Частая ошибка - разрешить клиенту и прокси повторять один и тот же запрос по нескольку раз. Тогда один сбой умножает нагрузку вдвое или втрое. Обычно хватает маленького бюджета: один повтор для короткого идемпотентного запроса и ноль повторов для длинной генерации после старта модели. Стоит отдельно ограничить число ретраев на клиента за минуту, чтобы один шумный интегратор не сжег всем лимиты нагрузки API.
Приоритеты тоже лучше разводить явно. И не только по API-ключу, но и по типу работы. Онлайн-чат, проверка оператора и fraud scoring логично защищать сильнее, чем суммаризацию архива, бэкфилл или эксперименты. Один и тот же клиент часто шлет и срочные, и второстепенные задачи. Если делить только по токену, полезный трафик легко утонет вместе с фоновым.
Нормальная стартовая схема простая: маленькая очередь, строгий лимит in-flight, короткие таймауты по шагам, 0-1 ретрай и отдельные квоты для высокого и низкого приоритета. Такая система не становится мягче. Зато она ломается предсказуемо и не тянет за собой соседние сервисы.
Как настроить очередь без лишней задержки
Длинная очередь выглядит как страховка, но для LLM-сервиса она часто делает только хуже. Пользователь уже не готов ждать 20-30 секунд, а система все еще честно держит его запрос в памяти и тратит место. Лучше держать очередь короткой и с жестким лимитом по числу задач. Если свободных мест нет, сервис сразу отвечает отказом, а не обещает работу, которую не успеет сделать.
Очередь должна сглаживать короткий всплеск, а не прятать перегрузку. Если сервис обычно переваривает 50 запросов в секунду, очередь на тысячи задач не спасает. Она просто сдвигает сбой по времени и растит задержку для всех.
У каждой задачи должен быть свой дедлайн рядом с данными запроса. Не в отдельной таблице и не только в логике клиента, а прямо в записи очереди. Тогда воркер перед вызовом модели быстро проверяет: запрос еще нужен или его срок уже вышел. Просроченные задачи стоит удалять до обращения к модели. Иначе GPU или внешний API тратят время на ответ, который уже никому не нужен.
Разделите очереди по смыслу
Интерактивные и пакетные запросы лучше не смешивать. Ответ в чате, подсказка оператору или проверка формы ждут секунды. Ночная обработка документов или массовая генерация описаний может подождать. Если все идет в одну очередь, пакетная загрузка легко съедает слот, который нужен живому пользователю.
На практике хватает хотя бы двух очередей: короткой для интерактивных запросов с малым таймаутом и отдельной для фоновых задач с более мягкими лимитами. Для них лучше держать разные лимиты воркеров и разные правила отказа при переполнении. Такой расклад проще контролировать и проще объяснить команде.
Это особенно полезно, когда один и тот же шлюз обслуживает и пользовательские сценарии, и фоновые пайплайны. В AI Router такой разбор по маршрутам и типам нагрузки помогает быстрее увидеть, где именно начал копиться хвост: на входе, у конкретного провайдера или на собственном хостинге моделей.
Если очередь уже уперлась в лимит, отказывайте сразу и явно. Быстрый ответ с понятной причиной лучше, чем молчаливое ожидание на 40 секунд и тот же отказ в конце. Клиент потом может повторить запрос позже, снизить приоритет или уйти в резервный сценарий.
Хорошая очередь не обязана быть большой. Она должна быть предсказуемой. Когда размер ограничен, дедлайн хранится в каждой задаче, а просроченное вычищается до вызова модели, задержка остается под контролем даже во время пика.
Как сбрасывать второстепенные запросы
Когда нагрузка растет, система не должна делать вид, что все запросы равны. Сначала отделите потоки, отказ по которым почти не бьет по бизнесу: фоновые саммари, повторные генерации "для удобства", пакетные оценки, несрочные embeddings. Если ответ нужен человеку на экране прямо сейчас или влияет на деньги, риск и соблюдение правил, такой поток режут в последнюю очередь.
Обычно хватает простого правила. Высокий приоритет оставляют там, где есть прямой пользовательский сценарий или решение, которое нельзя задержать. Для банка это чат оператора и проверка риска. Для ритейла - ответы в поддержке и антифрод на оплате. Ночную переразметку каталога или массовый пересчет рекомендаций лучше отправить в отдельную очередь без права спорить за главный ресурс.
Сам сброс стоит привязывать к двум вещам: приоритету и возрасту запроса. Низкий приоритет можно отвергать сразу, если очередь уже выше порога. Можно дать ему короткое окно, например 2-5 секунд, и после этого снять с обработки. Старый второстепенный запрос почти всегда хуже, чем новый срочный.
Не держите клиента в подвешенном состоянии. Если понятно, что запрос не пройдет, отвечайте сразу. Быстрый отказ лучше, чем 25 секунд ожидания и тот же отказ в конце. Для API обычно хватает явной причины вроде "low_priority_dropped" и короткой подсказки: повторить позже, перейти в асинхронный режим или уменьшить объем запроса.
Логи здесь нужны не для галочки. Полезно писать тип запроса, его приоритет, возраст в очереди, ожидаемый размер генерации, tenant или API key и причину сброса. Отдельно считайте объем потерь: сколько запросов отклонили, сколько токенов не обработали, какие сценарии это задело. На шлюзе вроде AI Router особенно удобно смотреть на rate-limits по ключу и аудит-логи: они быстро показывают, чья фоновая нагрузка начала душить живой трафик.
Как внедрять по шагам
Backpressure лучше вводить поэтапно. Если включить все защиты сразу, аварий станет меньше, но команда не поймет, какой лимит реально помог, а какой просто спрятал проблему.
-
Снимите базовые метрики. Смотрите p95 и p99 по задержке, глубину очереди, число in-flight запросов и долю ошибок. Разбивайте данные по маршрутам, моделям и типам задач. Среднее значение почти всегда выглядит лучше, чем реальная картина под пиком.
-
Найдите участок, который упирается первым. Это может быть внешний LLM API, пул соединений, воркер с GPU или база для логов. Лимит ставьте именно там, где задержка резко растет и клиенты начинают ретраить. Если команда работает через единый шлюз, удобно держать пределы на уровне API-ключа, модели и провайдера.
-
После лимита добавьте небольшую очередь и короткие таймауты. Очередь должна сглаживать короткий burst, а не копить хвост на минуты вперед. Если запрос не начал исполняться за несколько секунд, лучше быстро ответить ошибкой, чем заставлять клиента ждать и потом ретраить еще сильнее.
-
Затем разделите трафик по приоритету. Обычно хватает двух или трех классов: интерактивные запросы пользователей, фоновые задачи и второстепенные массовые операции. При перегрузе система должна первой резать низкий приоритет. Иначе одна тяжелая batch-задача легко выбьет чат, поиск или саппорт-бота.
-
После этого устройте жесткий тест. Дайте burst, включите клиентские ретраи и посмотрите, как растут очередь, задержка и число in-flight. Затем проверьте ручной аварийный режим: может ли дежурный быстро отключить низкий приоритет, зажать лимиты или временно перевести часть трафика на более быструю модель.
На проде не выкатывайте такую схему на весь поток сразу. Дайте сначала часть трафика, сравните метрики до и после и только потом расширяйте охват. Если после burst очередь быстро сдувается, p99 не улетает, а второстепенные запросы отваливаются раньше пользовательских, схема уже держит удар.
Пример с вечерним пиком
Представьте вечерний пик в чат-помощнике банка. С 18:30 до 20:00 люди проверяют платежи, спорные списания и статус заявок. Поток растет почти в 4 раза, а внутри системы идут не только диалоги с клиентами, но и фоновые задачи: черновики ответов для операторов, суммаризация чатов и batch-разбор обращений.
Проблема начинается не на входе, а в worker slots. Допустим, у сервиса 40 слотов. Короткий вопрос клиента занимает 2-4 секунды, но длинный запрос с большой историей диалога или поиском по базе висит 25-40 секунд. Если десять-пятнадцать таких запросов приходят подряд, они забирают почти все слоты. Живой чат сразу чувствует это: очередь растет, задержка скачет, таймауты множатся.
В таком сценарии приоритеты нужны жесткие, а не декоративные. Живой клиент должен пройти первым. Все остальное можно ужать.
Как это выглядит на практике
Команда делит нагрузку на три класса. Первый - ответы клиенту в реальном времени. Второй - подсказки оператору и короткие внутренние сводки. Третий - черновики, ночные переоценки, пакетные задачи и прочая работа, которая может подождать.
Дальше вводят простые правила: для живого чата резервируют 24 из 40 слотов, длинные запросы держат в отдельном пуле и дают им не больше 8 слотов, задачи старше 8 секунд в очереди отменяют, а запрос к провайдеру обрывают, если он не ответил за 20 секунд. Третий класс начинают сбрасывать первым при росте очереди.
После этого сервис перестает пытаться спасти все сразу. Черновики отвечают реже, batch-задачи чаще уходят в отказ или перезапуск, зато клиент в чате получает ответ за 3-6 секунд даже в пик.
До таких лимитов картина обычно хуже: почти все типы запросов формально еще "в работе", но система тонет целиком. После лимитов второстепенные задачи теряют процент успеха, и это нормально. Зато не падает основной сценарий.
Для банка или ритейла это разумный обмен. Пользователь не должен ждать из-за того, что где-то в фоне сервис пишет черновик ответа оператору или гоняет вечерний batch. Если сервис пережил пик и сохранил живой диалог, схема сработала.
Ошибки, которые быстро валят систему
Backpressure чаще всего ломается не из-за одной большой поломки, а из-за нескольких плохих решений, которые усиливают друг друга. Сервис еще держится, потом модель или провайдер чуть замедляется, и очередь начинает расти уже сама по себе.
Самая частая ошибка - включить ретраи и на клиенте, и на сервере. Один неудачный запрос быстро превращается в три или девять. Если внешний LLM API уже отвечает медленно, такая схема создает шторм из повторов и добивает очередь быстрее, чем исходная нагрузка. Обычно ретраи должен контролировать кто-то один и с жестким лимитом попыток.
Не меньше вреда дает одна общая очередь для всего трафика. Фоновая пакетная задача внезапно начинает спорить за ресурсы с живым чатом или проверкой заявки. В итоге второстепенная работа душит то, что люди ждут прямо сейчас. Для LLM лучше разделять потоки хотя бы по приоритету: интерактивные запросы отдельно, batch отдельно.
Длинные таймауты тоже редко спасают. Когда команда оставляет 60 или 120 секунд в надежде, что модель успеет, она просто дольше держит занятыми соединения, память и воркеры. Пользователь все равно недоволен, а система теряет способность быстро восстановиться. Короткий и понятный отказ почти всегда лучше молчаливого зависания.
Еще одна плохая привычка - прятать отказ за пустым таймаутом без нормального кода причины. Тогда клиент не понимает, нужно ли повторить запрос, переключиться на более дешевую модель или показать пользователю сообщение о перегрузке. Для очередей запросов LLM это особенно болезненно: код 429, 503 или отдельный признак вроде "dropped_by_priority" дает шанс отреагировать правильно.
Отдельный риск - пытаться спасти сервис простым ростом числа воркеров, когда очередь уже вышла из-под контроля. Автомасштабирование запаздывает. Новые воркеры приходят в момент, когда downstream уже перегрет, и только усиливают давление на модельный шлюз, базу, кеш и сеть. Сначала нужно остановить приток лишней работы, сбросить низкий приоритет и лишь потом аккуратно добавлять емкость.
На практике цепочка часто выглядит так: провайдер отвечает на 4 секунды дольше обычного, клиент и сервер дружно ретраят, общая очередь пухнет, длинные таймауты держат сокеты открытыми, а мониторинг показывает просто "timeouts". Через несколько минут падает уже не одна функция, а весь сервис.
Быстрая проверка перед запуском
Перед релизом лучше проверять не среднюю нагрузку, а момент, когда система уже забита. Именно тогда видно, работает ли защита от каскадной аварии или просто откладывает сбой на пару минут.
Сначала посмотрите на очередь. У нее должен быть жесткий предел по длине. Если она может расти почти без конца, вы не спасаете сервис, а переносите проблему чуть дальше по времени. Потом пользователи получают долгие таймауты, а воркеры тратят память на задачи, которые уже никому не нужны.
Проверьте и разделение по приоритетам. Интерактивные запросы пользователей стоит держать отдельно от пакетных джоб, фоновых пересчетов и массовых прогонов. Иначе один ночной импорт легко съест весь запас и положит чат, поиск или поддержку.
Перед запуском полезно пройти короткий чек:
- очередь режется по твердому лимиту, а не по памяти сервера;
- интерактивный и пакетный трафик идут по разным классам приоритета;
- при нехватке места сервис быстро отвечает 429 или 503 без долгого ожидания;
- в метриках видны глубина очереди, возраст самой старой задачи и доля сброшенных запросов;
- дежурная команда может вручную отключить тяжелый маршрут, модель или провайдера.
Отдельно проверьте поведение отказа. Ответ 429 или 503 должен приходить быстро и предсказуемо. Хуже всего выглядит система, которая не отказывает честно, а держит соединение 40 секунд и потом все равно падает. Пользовательский опыт от этого только хуже, а upstream получает лишнюю нагрузку.
Для шлюза вроде AI Router это особенно важно: один медленный провайдер или тяжелый маршрут не должен тянуть вниз весь остальной трафик. Если команда может выключить проблемное направление вручную, она выигрывает время и не дает очереди расползтись по всей системе.
Последняя проверка простая: дайте сервису пик выше нормы, например в 2 раза, и посмотрите на три числа - длину очереди, возраст задач и долю мгновенных отказов. Если они растут управляемо, а интерактивный поток жив, конфигурация уже близка к рабочей.
Что делать дальше
Не раскатывайте backpressure сразу на все маршруты. Начните с одного главного сценария и одного второстепенного. Так команда быстрее увидит, где очередь реально помогает, а где только прячет перегрузку.
Хорошая первая пара выглядит просто: онлайн-запросы пользователей защищаете в первую очередь, а пакетные задачи ставите ниже по приоритету или режете первыми. Например, чат с клиентом держите до последнего, а ночную генерацию описаний товаров можно отложить без большой боли.
Дальше нужен короткий договор внутри команды. Продукт, разработка и поддержка должны заранее решить, что система обязана сохранить при пике, а что можно сбросить без ручного разбора утром. Если не договориться заранее, спор начнется уже во время инцидента.
Стоит зафиксировать всего несколько правил: какие запросы идут без очереди или с короткой очередью, какие задачи можно отложить на 5-15 минут, что система сбрасывает первым при нехватке емкости и кто меняет лимиты в аварийном режиме.
Отдельно опишите контракт для клиентов API. Нужны понятные коды ошибок и ясное поведение ретраев. Для временного превышения лимита обычно хватает 429, для общей нехватки емкости - 503. Если клиент может повторить запрос, дайте Retry-After и просите делать редкие ретраи с джиттером. Бесконечные повторы без паузы быстро добивают даже здоровый сервис.
Если вы строите LLM API в Казахстане, не всегда есть смысл собирать весь контур с нуля. Иногда проще взять готовый шлюз вроде AI Router: один OpenAI-совместимый эндпоинт, маршрутизация к разным провайдерам и моделям, rate-limits на уровне ключа, аудит-логи и локальный хостинг open-weight моделей, когда важны хранение данных внутри страны, низкая задержка или data residency. Это не заменяет вашу схему приоритетов и лимитов, но снимает часть базовой инфраструктуры.
Когда первый маршрут спокойно проживет вечерний пик без сюрпризов, добавляйте следующий. Если метрики очереди, доля сбросов и время ответа остаются в норме хотя бы неделю, подход можно расширять дальше.
Часто задаваемые вопросы
Почему LLM-сервис сначала тормозит, а не сразу падает с 5xx?
Потому что перегрузка обычно сперва бьет по времени ответа. Очередь растет, воркеры дольше заняты, соединения висят до таймаута, и сервис еще отвечает, но уже слишком медленно. Если смотреть только на 5xx, вы заметите проблему поздно.
Где обычно начинается затор при наплыве запросов?
Часто затор появляется еще до вызова модели: на проверке запроса, маскировании PII, логах или записи в очередь. Потом его усиливают лимиты на конкретную модель, провайдера, пул соединений или медленная база.
Нужна ли большая очередь на случай вечернего пика?
Нет, длинная очередь чаще вредит. Она прячет перегрузку, растит задержку и держит в памяти задачи, которые уже потеряли смысл. Лучше держать короткую очередь с жестким пределом и быстро отказывать, если мест нет.
Как не дать фоновым задачам задушить живой трафик?
Разведите их хотя бы на две очереди и дайте им разные лимиты воркеров. Чат, поиск и ответы пользователю пусть идут отдельно, а batch, суммаризация и ночные задачи — отдельно. Тогда фоновая нагрузка не съест слоты живого сценария.
Какие таймауты ставить для LLM-запросов?
Разбейте время по этапам. Дайте короткий срок на ожидание в очереди, отдельный срок на соединение с апстримом, свой лимит на генерацию и маленький лимит на постобработку. Так вы сразу видите, где сервис застрял, и не держите зависшие запросы слишком долго.
Сколько ретраев можно оставить без риска для системы?
Обычно хватает одного повтора для короткого идемпотентного запроса и нуля повторов после старта длинной генерации. Самое важное — не ретраить на клиенте и на сервере одновременно, иначе один сбой быстро умножит нагрузку.
В какой момент лучше сразу отклонять запрос, а не держать его в очереди?
Когда задача уже не успеет принести пользу. Если очередь дошла до порога, а запрос низкого приоритета или его дедлайн истек, лучше ответить сразу. Быстрый отказ лучше, чем долгое ожидание с тем же отказом в конце.
Какие метрики первыми показывают, что backpressure не справляется?
Смотрите на p95 и p99 задержки, глубину очереди, возраст самой старой задачи, число in-flight запросов и долю мгновенных отказов. Полезно отдельно разложить метрики по маршрутам, моделям, провайдерам и типам задач, чтобы быстро найти узкое место.
Как проверить backpressure перед релизом?
Дайте сервису нагрузку выше обычной, включите клиентские ретраи и посмотрите, как ведут себя очередь, возраст задач и время ответа. Хорошая схема быстро режет низкий приоритет, держит интерактивный поток живым и после пика быстро возвращается в норму.
Когда есть смысл взять шлюз вроде AI Router, а не собирать все самому?
Он полезен, когда вам нужен один OpenAI-совместимый эндпоинт для разных моделей и провайдеров, rate-limits по ключу, аудит-логи и хранение данных внутри страны. Это снимает часть инфраструктурной работы, но ваши приоритеты, лимиты и правила отказа все равно нужно настроить отдельно.