GPU для open-weight моделей: VRAM, контекст и KV-cache
GPU для open-weight моделей выбирают не только по VRAM. Разберём, как длина контекста, KV-cache и параллелизм меняют расчёт GPU.
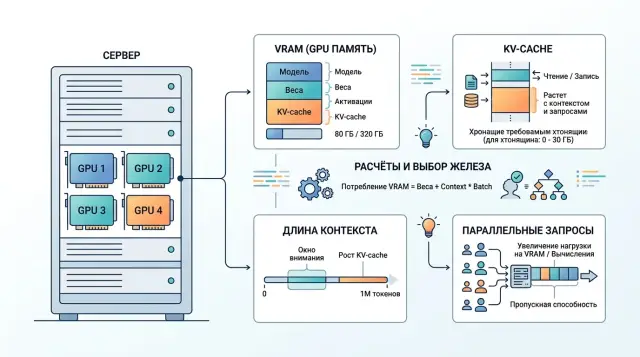
Почему одной VRAM мало
Когда выбирают GPU под open-weight модель, первым делом смотрят на VRAM. Это полезно, но почти никогда не даёт правильного ответа само по себе. Модель может спокойно загрузиться в память, пройти демо на одном запросе и всё равно начать тормозить под обычным трафиком.
Память карты уходит не только на веса. Часть занимает сама модель после квантования, часть - KV-cache, который растёт по мере генерации, и ещё часть - служебные буферы, батчинг и работа движка инференса. Поэтому карта на 80 ГБ не обязательно даст комфортный запас. Если веса уже забрали большую часть VRAM, на длинные диалоги и параллельные запросы места останется мало.
Сильнее всего картину меняет длина контекста. Короткий чат на 10-20 реплик обычно живёт спокойно. Длинный разговор с историей, документами и системными инструкциями быстро раздувает KV-cache, хотя сами веса модели не меняются.
Отсюда простой вывод: выбирать GPU нужно не по принципу модель влезла, а по трём связанным вещам - весам, контексту и целевой задержке. Если вам нужен первый токен за 1-2 секунды и стабильная работа при 20 одновременных запросах, мало знать объём VRAM. Нужно понимать, сколько памяти останется под живые сессии и сколько токенов в секунду карта выдаст без очереди.
Небольшой пример. Команда загружает 70B-модель в квантованном виде, запускает демо и видит, что всё работает. Потом к ней подключают чат поддержки, где часть разговоров доходит до 30-40 сообщений. Задержка резко растёт. Модель не стала тяжелее. Просто накопился KV-cache, а параллельные запросы заняли остаток памяти.
Какие данные собрать до выбора GPU
До выбора железа полезнее открыть логи, чем каталог видеокарт. Для расчёта нужны не абстрактные характеристики модели, а то, как люди реально пользуются вашим сервисом.
Сначала соберите длину входа в токенах. Смотрите не только на среднее, но и на p95. Среднее легко успокаивает: большая часть запросов короткая, а проблемы создаёт длинный хвост. Потом посмотрите на длину ответа. Бот, который обычно пишет 80 токенов, и бот, который регулярно генерирует по 600 токенов, нагружают систему совсем по-разному.
Дальше снимите нагрузку по времени. Сколько запросов в секунду приходит в обычный час и сколько - в пик? Лучше брать не один удачный день, а хотя бы несколько типичных недель. У многих команд среднее выглядит спокойно, а весь расчёт ломают 10-15 минут вечернего пика.
Ещё один недооценённый параметр - число одновременно живущих сессий. Два сервиса могут иметь одинаковые 10 RPS и разную нагрузку на GPU. В одном случае это короткие независимые вопросы. В другом - сотни открытых чатов, где история каждого разговора держит память под KV-cache и режет параллелизм.
Обычно для первой рабочей таблицы хватает пяти строк:
- длина входа: среднее, p95 и, если есть, p99
- длина ответа: среднее и крупные выбросы
- запросы в секунду: обычный час и пик
- число одновременно активных сессий
- запас на рост нагрузки хотя бы на ближайшие месяцы
Простой пример. У службы поддержки средний вход - 700 токенов, p95 - 2800, средний ответ - 180 токенов. В обычное время сервис держит 4 RPS, в пик - 11 RPS, а одновременно активны около 150 диалогов. Если считать GPU только по среднему запросу, расчёт почти наверняка получится слишком оптимистичным.
Если продакшен-логов ещё нет, берите данные пилота и сразу закладывайте резерв. Конфигурация без запаса хотя бы 20-30% по пику почти всегда оказывается тесной раньше, чем ожидает команда.
Как контекст меняет расчёт
Длина контекста меняет расчёт сильнее, чем кажется на старте. Веса модели лежат в памяти почти как постоянная часть. KV-cache растёт вместе с числом токенов. Чем длиннее окно, тем меньше одновременных запросов выдержит тот же GPU.
Упрощённая логика такая: если запрос на 8k токенов требует около 2 ГБ под KV-cache, то на 32k ему уже нужно примерно 8 ГБ, а на 128k - около 32 ГБ. Рост близок к линейному. Поэтому выбирать GPU только по VRAM под веса опасно. Часто именно память под контекст становится узким местом.
Возьмём простой пример. Пусть веса и служебные буферы занимают 48 ГБ, а у карты всего 80 ГБ. Под живые запросы остаётся 32 ГБ. Тогда при окне 8k можно держать около 16 запросов по 2 ГБ. При 32k - примерно 4 запроса по 8 ГБ. При 128k - один длинный запрос и, в лучшем случае, ещё один на очень плотной конфигурации.
Это ещё мягкий сценарий. В реальной системе контекст почти никогда не равен одному сообщению пользователя. В память попадают системный промпт, история диалога, инструкции приложения, куски документов из RAG и иногда повторный запрос после таймаута. Один ретрай легко увеличивает давление на память, если старая сессия ещё не освободила KV-cache.
Поэтому считать надо не по среднему диалогу, а как минимум по трём профилям: обычный запрос, длинный рабочий диалог и плохой день с длинными историями, ретраями и всплеском параллелизма. Если GPU проходит только средний сценарий, для продакшена этого мало.
Отсюда и практичное правило: не включайте окно 128k просто на всякий случай. Часто дешевле и стабильнее держать основную нагрузку на 8k или 32k, а длинный контекст включать только там, где он действительно нужен.
Откуда берётся расход памяти
Память при инференсе удобно делить на три части: веса модели, runtime и KV-cache. Первая часть почти фиксированная. Вторая меняется умеренно. Третья живёт по своим правилам и чаще всего ломает красивый расчёт на бумаге.
KV-cache растёт не от размера модели как такового, а от числа токенов, которые модель уже увидела. Каждый новый токен добавляет значения для всех слоёв. Поэтому длинный диалог на 16k токенов держит заметно больше памяти, чем короткий запрос на 500 токенов, даже если модель одна и та же.
Пока сессий мало, это не выглядит проблемой. Одна длинная сессия редко пугает. Пятьдесят таких сессий быстро упираются в память раньше, чем в вычисления GPU. Особенно это заметно при непрерывном батчинге, когда сервер всё время подмешивает новые запросы к уже идущим и держит в памяти много последовательностей одновременно.
Есть и частый промах с квантованием. Оно хорошо уменьшает память под веса, например при переходе с FP16 на 4-bit. Но это не значит, что так же сильно вырастет лимит по числу живых диалогов. Если движок не умеет отдельно сжимать KV-cache, он нередко остаётся в FP16 или BF16. В итоге вы выиграли гигабайты на весах, а предел по активным сессиям сдвинулся гораздо меньше, чем ожидалось.
На практике это выглядит знакомо: после квантования модель помещается на одну карту, демо работает, а с ростом трафика сервис всё равно ловит OOM на длинных чатах. Проблема не в весах. Память съедает история токенов, которую сервер держит для каждого активного разговора.
Как считать параллелизм и задержку
Ночная пакетная обработка и живой чат нагружают GPU по-разному. Для пакетной задачи важна общая выработка за час. Для чата важнее другое: через сколько секунд приходит первый токен и не раздувается ли очередь в пик.
Поэтому одних tokens/s мало. Для онлайн-сценария минимум нужны две метрики: time to first token и скорость генерации после старта. Первая показывает, сколько пользователь ждёт. Вторая отвечает за то, тянется ли ответ 6 секунд или 20.
Параллелизм тоже лучше считать не по среднему числу запросов в минуту, а по коротким всплескам. Допустим, обычно у вас 15 запросов в минуту, но после push-рассылки за 20 секунд прилетает ещё 40. Именно такой рывок и проверяет систему на прочность. Короткий всплеск очередь переживёт. Пик на 10 минут уже ломает SLA.
Для расчёта достаточно нескольких чисел:
- TTFT для 95% запросов
- полное время ответа для 95% запросов
- средний размер входа и выхода в токенах
- число одновременных запросов в пиковый интервал
- допустимая длина очереди до нарушения SLA
Эти данные быстро показывают, сколько одновременных запросов выдержит модель без резкого роста задержки. Если новые запросы приходят быстрее, чем система успевает отдавать первые токены, очередь начнёт расти, даже если стендовый тест показывает хорошие tokens/s.
Полезно отдельно проверить rate limit и отменённые ответы. Ограничение по ключу или клиенту часто лучше, чем попытка принять всё сразу. Так вы сохраняете нормальную задержку для большинства пользователей. Отмены тоже влияют на расчёт: если часть людей закрывает ответ на середине, GPU освобождается раньше, и фактическая нагрузка оказывается ниже, чем видно по числу стартовавших запросов.
Пошаговый расчёт под свой поток
Начинать лучше не с выбора карты, а с одной рабочей связки: модель, точность и целевая длина контекста. Один и тот же вариант на 8B ведёт себя очень по-разному в FP16, FP8 и INT4. Для грубой оценки память под веса считают просто: число параметров умножают на размер одного веса. У 8B модели это около 16 ГБ в FP16, около 8 ГБ в FP8 и около 4 ГБ в INT4.
Дальше расчёт выглядит так.
-
Возьмите модель, которую вы действительно собираетесь запускать, и выберите точность. FP16 обычно предсказуемее, FP8 часто даёт хороший компромисс, INT4 заметно экономит память, но может просадить качество на сложных задачах.
-
Посчитайте память под веса и сразу прибавьте служебный расход. Под runtime, граф вычислений и фрагментацию разумно оставить ещё 15-25% VRAM. Если карта впритык помещает только веса, для продакшена этого мало.
-
Добавьте KV-cache под нужное число сессий. Здесь важны не средние значения, а ваши рабочие пики. Если бот держит 200 сессий по 8-12 тысяч токенов, KV-cache легко становится главным ограничением, даже когда веса модели уже удобно помещаются.
-
Сверьте расчёт с целью по задержке. Карта может подходить по памяти и всё равно отвечать слишком медленно, если для нужного throughput ей приходится уходить в высокий batch. Для чата лишние 300-700 мс пользователи замечают очень быстро.
-
После этого сравните архитектурные варианты. Один большой GPU обычно лучше для длинного контекста и тяжёлого KV-cache: всё живёт в одной памяти, без лишнего обмена между картами. Две меньшие карты подходят, если поток легко делится на независимые запросы и важнее суммарный throughput. Для одной длинной сессии такой вариант нередко добавляет больше сложности, чем пользы.
Если вы работаете через шлюз вроде AI Router, этот расчёт всё равно нужен. Он помогает понять, где выгоднее держать open-weight модель у себя, а где разумнее отправлять редкие длинные запросы во внешний маршрут.
Пример для чат-бота поддержки
Представим службу поддержки с 12 новыми запросами в секунду. Бот отвечает в среднем на 300 токенов и работает на модели 32B с окном 32k. Уже по этим данным видно, что нагрузка высокая: только на генерацию ответа нужно около 3600 токенов в секунду.
По памяти картина такая. В 8-битном виде веса модели 32B занимают около 32 ГБ. Ещё несколько гигабайт уходят на служебные буферы и движок инференса. Если считать полный контекст 32k, KV-cache у такой модели легко доходит примерно до 8 ГБ на один активный диалог.
С одним H100 на 80 ГБ модель обычно помещается, но комфортного запаса тут нет. После загрузки весов и буферов остаётся примерно 35-40 ГБ под KV-cache и батчинг. Это значит, что карта выдержит всего несколько одновременных сессий с полным окном 32k. Если один ответ занимает хотя бы 3 секунды, то при 12 запросах в секунду в системе уже около 36 активных запросов. В этот момент упираемся и в память, и в задержку генерации.
С двумя L40S картина другая. Общей памяти на бумаге больше, но она не складывается автоматически. Для модели 32B обычно нужен tensor parallel, то есть карты постоянно обмениваются данными. Память распределяется легче, зато растёт задержка и усложняется настройка. Для чат-бота поддержки это неприятный компромисс: пользователю важен быстрый первый токен, а межкарточный обмен часто бьёт именно по нему.
Если реальные диалоги короткие, например 2k-4k токенов вместо 32k, H100 ещё можно рассматривать для пилота или небольшого продакшена. Если длинный контекст нужен часто, смотреть надо не на вопрос влезает ли модель, а на то, сколько одновременных сессий выдержит KV-cache без скачка задержки.
Практический вывод простой: один H100 удобнее как базовый узел, если нужен предсказуемый профиль задержки и меньше сложностей с эксплуатацией. Две L40S иногда выглядят дешевле на входе, но быстрее приносят операционные проблемы. Для заданного потока разумнее думать не про одну машину, а про несколько реплик или маршрутизацию по моделям. Тогда 32B остаётся для сложных диалогов, а основную массу коротких обращений можно отдавать более компактной модели.
Где ошибаются чаще всего
Самая частая ошибка проста: команда смотрит только на размер весов и считает, что выбор GPU почти сделан. На практике это только начало. Память съедают длина контекста, KV-cache, служебные токены, батчинг и параллельные запросы. Модель может помещаться на бумаге и всё равно давать резкие скачки по задержке под обычной нагрузкой.
Вторая ошибка - считать по среднему запросу. Это удобно, но почти всегда слишком оптимистично. Если средний диалог занимает 1800 токенов, а 10% сессий доходят до 8000, именно этот хвост и ломает план. Для саппорта, банка или телеком-сервиса такой сценарий обычен: пользователь присылает историю переписки, договор, потом задаёт уточняющий вопрос.
Третья ловушка - считать только текст пользователя. В реальном запросе есть system prompt, история, шаблоны, роли, иногда куски из RAG и служебные токены. Фактический контекст почти всегда длиннее, чем видно в интерфейсе.
Четвёртая ошибка - верить красивому тесту на одном потоке. Такой прогон полезен только для первого знакомства. В продакшене важен параллелизм: 8, 16 или 32 одновременные генерации ведут себя совсем не так, как один идеальный запрос. На одном потоке карта может показывать отличную скорость, а под реальной нагрузкой внезапно терять темп из-за памяти и пропускной способности.
И, наконец, команды часто не оставляют запас. Сегодня вы считаете под промпт на 4k, а через месяц продукт просит 16k, больше истории и второй этап проверки ответа. Конфигурация, которая уже сейчас выглядит ровно впритык, почти наверняка потребует переделки.
Проверка перед закупкой
Перед закупкой полезно сделать короткую проверку. Зафиксируйте одну модель и одну точность. Возьмите p95 и p99 по входу и выходу, а не только среднее. Посмотрите пики по минутам, а не среднюю нагрузку за день. Потом посчитайте KV-cache на нужный параллелизм и добавьте запас на рост плюс сценарий отказа одного узла.
На практике чаще всего ошибаются в двух местах: недооценивают длину длинных диалогов и переоценивают, сколько параллельных сессий карта выдержит без очереди. Допустим, у поддержки обычно 30 запросов в минуту, а в пике - 90. Если 99-й перцентиль длины контекста в три раза выше среднего, а параллельно система держит 12-16 активных генераций, карта может упереться не в веса модели, а в KV-cache. Тогда задержка растёт скачком, а очередь набирается за несколько минут.
Если вы уже тестируете несколько маршрутов через AI Router, часть этой картины можно снять заранее на реальном трафике: длину запросов, пики по минутам, долю длинных диалогов, поведение после rate limit. Для команд в Казахстане и Центральной Азии это удобный способ прогнать одни и те же сценарии через один OpenAI-совместимый эндпоинт без переписывания SDK, кода и промптов.
Хороший результат проверки выглядит скучно, и это нормально. У вас есть одна выбранная модель, одна точность, реальные перцентили токенов, пиковая нагрузка по минутам, расчёт KV-cache, запас на рост 20-30% и понятный план на случай отказа одного узла. Если хотя бы одного числа нет, лучше потратить ещё день на сбор данных, чем потом переделывать всю схему.
Что делать после расчёта
Расчёт на бумаге нужен, но окончательное решение всё равно принимает тест под живой нагрузкой. Таблица даёт ориентир. Стенд быстро показывает, где расчёт был слишком смелым: в длине контекста, числе одновременных запросов или ожидании в очереди.
Возьмите реальные промпты или максимально похожие на них. Не ограничивайтесь одним средним запросом. Проверьте короткие диалоги, длинные документы, всплеск по числу пользователей и хотя бы один тяжёлый сценарий с большим контекстом. Во время теста достаточно смотреть на четыре метрики: TTFT, tokens/s после старта, memory used и queue time. Важна именно связка этих чисел. Например, tokens/s могут выглядеть нормально, но queue time вечером вырастет в три раза. Для пользователя это хуже, чем чуть более медленный, но стабильный ответ.
После этого сравните два режима: локальный хостинг и API-маршрутизацию. Для чувствительных данных, низкой задержки внутри страны или fine-tuned вариантов свой контур часто оправдан. Для редких, тяжёлых или экспериментальных задач доступ к нескольким моделям по API бывает дешевле, чем покупка железа с большим запасом.
Для такой проверки AI Router может быть полезной промежуточной ступенью. На airouter.kz команды могут быстро прогнать один и тот же набор сценариев через разные frontier-модели и open-weight варианты через api.airouter.kz, не меняя привычные SDK, код и промпты. Это помогает понять, когда уже пора поднимать свой GPU-кластер, а когда маршрутизации по API достаточно.
Если тест прошёл нормально, не закупайте сразу весь объём. Возьмите один рабочий профиль нагрузки, оставьте запас по очереди и контексту, а через пару недель повторите измерения на новых данных. Такой подход обычно дешевле, чем попытка угадать идеальную конфигурацию с первого раза.
Часто задаваемые вопросы
Почему нельзя выбирать GPU только по объёму VRAM?
Потому что VRAM уходит не только на веса модели. Память съедают KV-cache, служебные буферы, батчинг и сам движок инференса. Из-за этого модель может загрузиться и нормально отвечать в демо, но под живым трафиком начать тормозить или ловить OOM.
Какие данные собрать до выбора GPU?
Сначала возьмите реальные логи. Нужны длина входа и ответа в токенах, средние значения и p95, нагрузка в обычный час и в пик, число одновременно активных сессий и запас на рост хотя бы 20–30%. Без этих цифр расчёт почти всегда выходит слишком оптимистичным.
Что сильнее всего влияет на память кроме самих весов модели?
Сильнее всего расчёт меняет длина контекста. Веса модели почти не меняются, а KV-cache растёт вместе с числом токенов в истории. Поэтому переход с 8k на 32k или 128k быстро съедает свободную память и режет параллелизм.
Что такое KV-cache простыми словами?
KV-cache — это память, где модель держит уже прочитанные токены для текущего диалога. Чем длиннее история, тем больше места она занимает. Одна длинная сессия редко пугает, но десятки таких сессий быстро упирают сервер в память.
Решает ли квантование проблему памяти?
Не полностью. Квантование хорошо уменьшает память под веса, но KV-cache часто остаётся намного тяжелее, чем ждёт команда. Поэтому после квантования модель помещается на карту, а предел по числу живых диалогов растёт не так сильно.
Какие метрики важны для чат-бота, а не для пакетной обработки?
Для чата смотрите не только на tokens/s. Нужны TTFT для p95 запросов, полное время ответа, скорость генерации после первого токена и queue time в пик. Если первый токен приходит долго, пользователю уже неважно, что стенд показал хорошую среднюю скорость.
Нужно ли сразу брать конфигурацию под 128k контекст?
Нет, если у задачи нет длинных диалогов или больших документов. Часто выгоднее держать основную нагрузку на 8k или 32k, а длинный контекст включать только для редких сценариев. Так проще удержать нормальную задержку и не раздувать требования к железу.
Что лучше для длинного контекста: один большой GPU или две меньшие карты?
Обычно одна большая карта удобнее. Она даёт более предсказуемую задержку и не тратит время на обмен между GPU. Две карты имеют смысл, когда поток легко делится на независимые запросы и вам важнее общий throughput, а не одна длинная сессия.
Какой запас по мощности и памяти стоит заложить?
Если продакшен-логов нет, закладывайте хотя бы 20–30% поверх пикового сценария. Этого запаса хватает, чтобы пережить рост нагрузки, длинные диалоги и мелкие промахи в расчёте. Если сервис не должен падать при отказе одного узла, учтите и этот случай сразу.
Что делать после расчёта на бумаге?
Сначала прогоните живой тест на реальных или очень похожих промптах. Проверьте короткие и длинные диалоги, всплеск по числу пользователей и тяжёлый сценарий с большим контекстом. Если тест проходит ровно впритык, не покупайте весь объём сразу — лучше взять одну рабочую конфигурацию и через пару недель перепроверить цифры на новых данных.