Ошибки OCR в RAG: 5 признаков грязного текста до индекса
Ошибки OCR в RAG ломают поиск, цитаты и ответы. Разберем 5 признаков грязного текста, быстрые проверки и порядок очистки перед индексом.
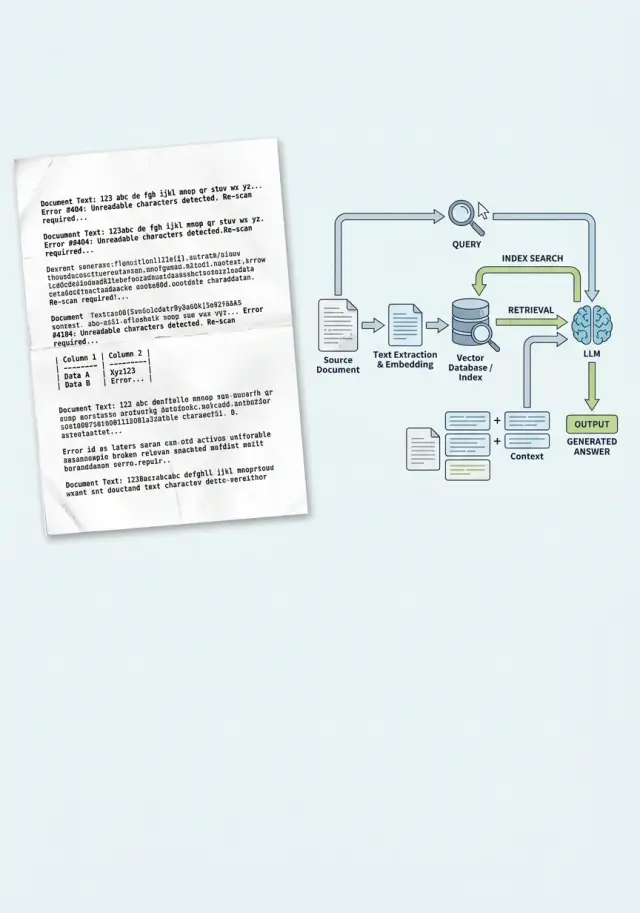
Почему проблема начинается до индекса
RAG чаще ломается не в момент генерации ответа. Сбой появляется раньше, когда система впервые читает документ как текст. Если OCR ошибся, индекс запоминает не смысл документа, а его испорченную копию. Потом поиск честно находит именно этот шум.
Это особенно заметно на сканах договоров, счетов и актов. OCR путает похожие символы: "О" и "0", "l" и "1", "S" и "5", теряет знак процента, дробь или номер пункта. Для человека это мелочь. Для поиска это уже другой токен, а иногда другой факт.
Есть и более тихая проблема. Скан ломает границы абзацев, сшивает соседние строки и превращает таблицу в набор слов и цифр. Пункт про срок оплаты может склеиться с реквизитами, а колонка с суммой - уехать в середину другого блока. Когда вы режете такой текст на чанки, каждый кусок уже испорчен.
Индекс получает не документ, а набор фрагментов с мусором и потерянной структурой. Эмбеддинги не "догадываются", где OCR ошибся. Они строятся по тому тексту, который получили. Если вместо "ставка 12%" система видит "ставка l2" или распавшуюся строку, поиск тянет не тот фрагмент.
Отсюда и правдоподобные, но неверные ответы. Модель видит текст, похожий на официальный, и отвечает уверенно. Это не всегда "галлюцинация". Часто ей просто дали плохую опору.
Практический сценарий простой: сотрудник загружает скан договора, OCR сливает два пункта в один, индекс сохраняет этот кусок, а потом запрос про штрафы возвращает блок про сроки поставки. Модель берет его за основу и пишет аккуратный ответ. Ошибка появилась еще до индексации.
Поэтому OCR в RAG опасен не только качеством распознавания. Он меняет то, что система вообще считает знанием. Если не проверить текст до загрузки, получится аккуратный пайплайн, который стабильно опирается на испорченные данные.
Пять признаков грязного текста
Грязный OCR почти всегда видно еще до индексации. Хитрость в том, что текст часто выглядит "почти нормальным". Для человека этого хватает, для поиска - нет. RAG цепляется за токены, соседние слова и структуру документа. Если OCR ломает хотя бы два из этих слоев, ответы начинают ехать.
- Буквы и цифры путаются местами. Самый частый случай - O и 0, I и 1, S и 5. В договорах это ломает номера счетов, даты, суммы и артикулы.
- Слова режутся или слипаются. "Ответствен ность" и "срокдоговора" выглядят знакомо, но поиск по ним работает хуже, а эмбеддинги получают шум вместо нормальной фразы.
- Таблицы теряют форму. Строки, столбцы и подписи смешиваются, и модель уже не понимает, к чему относится сумма, срок или ставка.
- Служебный мусор лезет в основной текст. Колонтитулы, номера страниц и подписи внезапно попадают в середину абзаца. В итоге каждый второй фрагмент начинается со "Страница 4 из 12", хотя по смыслу это пустой шум.
- Куски текста дублируются. OCR часто повторяет строку на стыке страниц или заново считывает блок с печатью и подложкой.
По отдельности эти дефекты еще можно пережить. Вместе они быстро ломают retrieval. В скане договора таблица с тарифами распадается, номер страницы попадает в середину абзаца, а "10 000" превращается в "I0 OOO". Человек догадается, что имелось в виду. Индекс - не всегда.
Особенно заметны такие сбои на точных вопросах: про лимит, срок, ставку или конкретный пункт договора. Система вытаскивает соседний фрагмент, потому что нужные слова распались или смешались с мусором. Иногда ответ звучит уверенно, но ссылается не на тот раздел. Это хуже, чем явная ошибка.
Проверка простая: откройте сырой текст без форматирования и прочитайте 20-30 строк подряд. Если взгляд спотыкается каждые пару предложений, индексировать рано. Когда в одном документе видны хотя бы два признака из списка, его лучше сначала почистить, а уже потом резать на чанки.
Что ломается в ответах RAG
Пользователь редко видит "плохой OCR" как причину проблемы. Он видит другое: неточный ответ, странную цитату, номер договора, который не совпадает с оригиналом. Сбой почти всегда маскируется под слабый поиск или "галлюцинацию" модели.
Первый симптом - поиск не находит нужный абзац. Документ есть в индексе, но OCR разбил слово, склеил строки или испортил таблицу. Для человека фраза еще читается, для поиска это уже другой текст. Вместо абзаца про срок оплаты система поднимает соседний блок с общими условиями, и ответ уходит в сторону.
Дальше начинают ломаться цитаты. Модель ссылается на фрагмент, который похож на оригинал, но не совпадает с ним дословно. В договоре написано "оплата в течение 15 календарных дней", а в ответе внезапно появляются "10 дней" или исчезает слово "календарных". Для юриста, банка или закупки это уже рабочая ошибка.
Хуже всего OCR портит сущности, где важен каждый символ: суммы, даты, ИИН, номера договоров и приложений. "8 000 000" превращается в "800 000", дата 03.06.2024 переезжает в соседнюю строку, а номер договора цепляет кусок из шапки страницы. Модель отвечает по тому тексту, который получила, но ответ уже неверный.
В работе это выглядит буднично. Команда загружает скан договора и просит систему найти штраф за просрочку. Если OCR дважды распознал одну и ту же страницу, дубликаты забивают верх выдачи. Поиск возвращает почти одинаковые куски вместо разных релевантных абзацев. Модель видит узкий и шумный контекст, поэтому повторяет один и тот же фрагмент, хотя нужный ответ лежит ниже.
Есть и еще одна ловушка. Модель начинает достраивать пропущенные слова. Если OCR съел часть фразы "не позднее чем за 5 рабочих дней", в контексте может остаться "не позднее чем за ... дней". Языковая модель легко заполняет такой пробел по шаблону. Иногда верно. Иногда она берет число из соседнего абзаца.
Обычно сбой видно сразу по нескольким сигналам: ответ звучит уверенно, но цитата не бьется с PDF; поиск возвращает почти одинаковые чанки; суммы и даты меняются от ответа к ответу; система игнорирует точный вопрос и уходит в общие формулировки.
Если это уже видно в тестах, новая модель редко спасает ситуацию. Сначала проверьте текст до индекса. Иначе RAG будет ошибаться быстро и аккуратно.
Быстрые проверки перед загрузкой
Перед индексацией хватает 15-20 минут, чтобы отсеять большую часть проблем. Если пропустить этот шаг, команда потом чинит не RAG, а мусор в источнике.
Начните с ручной выборки. Возьмите не один удачный PDF, а 20-30 страниц из разных документов: первую, середину, конец, страницу с таблицей, со сносками, со штампом, с плохим контрастом. OCR редко ломается везде одинаково. Обычно он срывается в самых неудобных местах.
Сначала проверьте точные сущности. Номера договоров, ИИН, суммы, даты, артикулы и проценты должны читаться без догадок. Если "12.03.2024" стало "12.O3.2024", а "№ 451-7" превратилось в "N 45l-7", поиск и ответы начнут врать очень уверенно.
Потом быстро пройдитесь по страницам и найдите мусорные символы: наборы вроде "@#|", случайную латиницу внутри кириллицы, разорванные слова, повторы одной и той же строки, куски текста без пробелов. Один плохой абзац не страшен. Если такие места встречаются на каждой пятой странице, индекс уже нельзя считать чистым.
Отдельно проверьте верстку. В двухколоночных документах OCR часто склеивает левую и правую колонку в одну строку. Со сносками похожая история: основной текст прыгает вниз, а потом в середину абзаца внезапно попадает примечание мелким шрифтом. Для RAG это особенно неприятно, потому что чанк выглядит связным, а смысл внутри уже сломан.
Автоматические тесты можно сделать без сложной системы. Достаточно посчитать долю страниц с необычно коротким или слишком длинным текстом, найти строки с высокой долей странных символов, проверить повторы абзацев и сравнить соседние чанки на частые дубликаты.
Дубликаты особенно вредны. Если один и тот же фрагмент попал в индекс три раза, retrieval тянет его чаще других, и ответ кажется "убедительным", хотя опирается на повтор.
Полезный минимум выглядит так: вручную посмотреть выборку, проверить точные номера и даты, поймать мусорные символы, убедиться, что колонки и сноски не смешались, и убрать дубли до чанкинга или сразу после него. Если документ не проходит этот набор, загружать его в индекс рано.
Как почистить текст по шагам
Грязный OCR редко чинится одной настройкой. Надежнее идти короткой цепочкой: отделить плохие файлы, убрать явный шум, вернуть тексту нормальную форму и только потом отправлять его в индекс. Иначе система запомнит мусор и будет уверенно цитировать его в ответах.
Сначала отделите плохие файлы
Не складывайте все документы в одну кучу. Договор, счет, скан письма и таблица ломаются по-разному. Если смешать их в одном потоке, трудно понять, где ошибка в шаблоне, а где проблема в исходном скане.
Достаточно простой группировки по двум признакам: тип документа и качество изображения. Для типа хватит категорий вроде "договоры", "акты", "анкеты" и "таблицы". Для качества удобно держать три корзины: хороший скан, терпимый и плохой. Плохие файлы лучше не пускать дальше автоматически. Их дешевле отправить на повторный скан, чем потом разбирать странные ответы RAG.
Перед OCR проверьте саму страницу. Если текст завален даже на пару градусов, система часто склеивает строки. Если в PDF есть пустые страницы, разделители, черные поля по краям или дубликаты, удалите их сразу. На большом наборе это экономит больше времени, чем кажется.
Потом верните структуру текста
После распознавания уберите повторяющиеся куски, которые OCR любит тащить на каждой странице: колонтитулы, номера страниц, служебные подписи, отметки сканера. Иначе поиск начнет считать их важными словами и будет подсовывать не тот фрагмент.
Затем восстановите абзацы. OCR часто рвет одну мысль на пять строк или, наоборот, склеивает весь раздел в сплошной блок. Для RAG это плохо: чанки режутся в случайных местах, и смысл расползается. Базовые правила простые: склеивайте строки внутри одного абзаца, оставляйте пустую строку между абзацами, сохраняйте нумерацию и маркеры списков, а таблицы переводите в понятный текстовый вид.
На таблицы лучше смотреть трезво. Если OCR превратил колонки в кашу, перепишите их в пары "поле - значение" или в короткие строки по каждой записи. Такой текст индексируется заметно лучше.
Проверяйте результат до переиндексации. Возьмите 10-20 документов из каждой группы и посмотрите, читаются ли абзацы, не повторяется ли шапка, не сломались ли списки и таблицы. Если хотя бы одна из этих частей едет, индекс обновлять рано.
На одном договоре это выглядит прозаично: выровняли страницы, удалили две пустые, срезали номера листов, склеили абзацы, привели таблицу реквизитов к виду "поле - значение" и снова проверили текст. Только после этого его стоит отправлять в индекс. Иначе вы просто быстрее загрузите ошибку.
Пример на одном договоре
Команда загружает в RAG скан договора поставки на 24 страницы. На каждой странице есть печать, подпись внизу и мелкий подвал: номер страницы, дата, номер шаблона. Основной текст читается нормально, но раздел с ответственностью выглядит хуже всего: тонкий шрифт, плотные абзацы, короткие цифры рядом с пунктами.
OCR снимает текст неравномерно. В пункте 8.4 он читает начало строки вместе с подвалом страницы и склеивает их в один фрагмент. Вместо "8.4 Поставщик обязан уведомить заказчика за 10 рабочих дней" в индекс уходит что-то вроде "8.4 24/24 форма D-17 Поставщик обязан уведомить заказчика...". На следующей странице похожая помеха цепляется к пункту 8.5.
Проблема всплывает позже. Когда пользователь спрашивает, за сколько дней нужно предупредить о расторжении, поиск находит не 8.4, а соседний пункт 8.5. Он тоже говорит об уведомлении, но уже про изменение цены, и срок там другой - 5 дней. Модель отвечает уверенно, цитата выглядит правдоподобно, а причина сидит в грязном OCR-тексте.
Так и выглядят многие ошибки в RAG: сломан не сам ответ, а фрагмент, который система посчитала самым близким.
Здесь помогает короткая проверка. Откройте 3-5 страниц с мелким шрифтом и сравните картинку со строками OCR. Посмотрите, не повторяется ли подвал в середине абзацев. Проверьте, идут ли номера пунктов по порядку, без скачков и склеек. Затем задайте тестовый запрос по двум спорным пунктам и посмотрите, какой фрагмент поднял поиск.
В этом примере проблема нашлась быстро: в тексте видно мусор возле номера раздела и повтор строки из подвала. После этого документ чистят без сложной магии: вырезают верхнюю и нижнюю зоны страницы, прогоняют OCR заново, отдельно проверяют блоки с мелким шрифтом и только потом отправляют текст в индекс.
После очистки поиск возвращает уже нужный отрывок - пункт 8.4 без чужих цифр и служебных строк. Модель ссылается на правильный фрагмент и отвечает точно: уведомление нужно отправить за 10 рабочих дней. Разница кажется мелкой, но для договора это уже не косметика, а смысл.
Где команды чаще ошибаются
Ошибки обычно начинаются не в модели и не в индексе. Чаще всего команда просто слишком рано считает текст "достаточно чистым" и грузит его в пайплайн как есть.
Первая типичная промашка - брать сырой OCR без ручной выборки. Люди смотрят на пару удачных файлов, видят читаемый текст и решают, что вся партия в порядке. Потом выясняется, что в половине документов склеились колонки, сломались переносы, а номера пунктов превратились в набор символов. Даже выборка из 20-30 файлов обычно показывает картину честнее, чем общий процент "успешного распознавания".
Вторая ошибка - одинаково обрабатывать все типы документов. Договор, счет и анкета похожи только на уровне "там есть текст". На деле структура разная: в договоре важны пункты и приложения, в счете - строки, суммы и даты, в анкете - пары "вопрос - ответ" и галочки. Если пропустить все через один шаблон очистки и нарезки, смысл ломается еще до поиска.
Еще одна плохая привычка - чистить текст слишком поздно, уже после эмбеддингов. Если индекс получил мусорные фрагменты, он их уже запомнил. Потом команда исправляет источник, но ответы все равно тянут старый шум, пока индекс не пересоберут.
Отдельная проблема - повторы страниц и разные версии одного документа. В индекс попадает черновик, подписанная копия, скан той же копии из другой папки и еще дубликат с другой ориентацией страницы. RAG начинает "голосовать" за то, что встречается чаще, а не за то, что верно. В итоге ответ может сослаться на старую редакцию договора только потому, что ее загрузили три раза.
И наконец, команды часто теряют связь текста с источником. Чистый фрагмент сохраняют отдельно от номера страницы, имени файла и версии документа. Пока система живет в демо, этого не видно. Как только юрист, аудитор или аналитик просит показать источник ответа, начинается ручной поиск по папкам.
Для банка, клиники или госсектора это особенно неприятно. Если система не может показать страницу и документ, ответу не доверяют, даже когда формально он точный.
Поэтому рядом с каждым фрагментом стоит хранить хотя бы тип документа, номер страницы, идентификатор файла или версии и признак дубликата или близкой копии. Это кажется мелочью, но потом экономит часы на разборе странных ответов. Если в индекс попал текст без версии, страницы и проверки на дубли, проблему часто приходится чинить уже в рабочей системе.
Что сделать дальше
Не загружайте весь архив одним махом. Сначала задайте простой порог качества страницы до индекса: текст читается подряд, служебный мусор не забивает абзацы, таблицы не распадаются, а на странице нет длинных цепочек вроде "п0дпись/п0дпись/п0дпись". Такой порог нужен не для красоты. Он снижает риск уверенных, но неверных ответов.
Полезно разделить документы на два потока. Те, что проходят порог, идут дальше. Те, что не проходят, отправляются в отдельную очередь на разбор. Не смешивайте их, иначе потом трудно понять, откуда пришла ошибка - из модели, из чанкинга или из самого текста.
На старте хватит небольшой выборки, а не всей базы. Возьмите 30-50 документов одного типа, например договоры или акты, и сравните их до и после очистки на одном наборе вопросов. Разница обычно видна быстро: модель реже путает даты, меньше теряет суммы и лучше цитирует нужный фрагмент.
Если команда уже тестирует несколько моделей для RAG, полезно держать одинаковый индекс и менять только модель. Тогда видно, где проблема в индексе, а где в поведении самой модели. Сравнивайте ответы хотя бы двух или трех моделей на одинаковых вопросах и одинаковом контексте: насколько точно они находят нужный фрагмент, не придумывают ли лишнее, умеют ли честно сказать "не найдено" и не сыплются ли на таблицах и сносках.
Для такой проверки удобно, когда модели переключаются без переделки SDK и текущих промптов. В этом месте может пригодиться AI Router: у сервиса один OpenAI-совместимый эндпоинт, так что команде не нужно менять код при сравнении разных моделей. Для команд в Казахстане это еще и практичный вариант, если важно хранить данные внутри страны и вести B2B-инвойсинг в тенге.
Не ждите идеального пайплайна. Достаточно ввести порог качества, отправлять плохие страницы в отдельную очередь и прогнать короткий A/B тест на малой выборке. После этого у команды появляется не абстрактное ощущение, что грязный OCR мешает, а конкретный список страниц, правил очистки и вопросов, на которых индекс ломается.
Часто задаваемые вопросы
Как понять, что ошибается OCR, а не модель?
Чаще всего это видно по следам в источнике. Ответ звучит уверенно, но цитата не совпадает с PDF, суммы и даты плавают, а поиск поднимает соседний абзац вместо нужного.
Откройте сырой текст без форматирования и сравните 20–30 строк с оригиналом. Если OCR путает символы, склеивает строки или тянет подвал страницы в середину абзаца, сбой начался до модели.
Какие документы OCR портит чаще всего?
Сильнее всего страдают сканы договоров, счетов, актов и анкет. Там важен каждый символ, а OCR часто ломает номера, даты, проценты и короткие пункты.
Отдельно страдают страницы с таблицами, сносками, печатями, мелким шрифтом и плохим контрастом. Именно на них поиск чаще всего уходит в соседний фрагмент.
Нужно ли проверять весь архив вручную?
Нет, весь архив руками смотреть не нужно. Обычно хватает выборки из 20–30 страниц или 30–50 документов одного типа.
Берите не только удачные файлы. Проверьте начало, середину, конец, таблицы, страницы со штампами и мелким шрифтом. Так вы быстрее поймете, где OCR срывается регулярно.
Что проверять в сыром тексте перед индексацией?
Смотрите на вещи, которые ломают смысл: даты, суммы, номера договоров, ИИН, проценты и артикулы. Если здесь уже есть путаница вроде "O" вместо "0" или "l" вместо "1", индекс начнет ошибаться.
Потом быстро оцените структуру. Текст должен читаться подряд, без мусорных символов, повторов строк, склеенных колонок и внезапных номеров страниц внутри абзаца.
Почему таблицы так часто ломают ответы в RAG?
Потому что таблица после плохого OCR теряет связи между колонками. Сумма, срок и ставка остаются в тексте, но уже не ясно, что к чему относится.
Если таблица распалась, не индексируйте ее как есть. Лучше переписать строки в понятный вид вроде "поле: значение" или сохранить каждую запись отдельным текстовым блоком.
Когда документ лучше сразу остановить и не индексировать?
Не пускайте документ в индекс, если взгляд спотыкается о текст каждые пару предложений. Это простой, но честный тест.
Если на странице смешались колонки, повторяется подвал, цифры читаются с догадками или один и тот же абзац встречается несколько раз, сначала почистите документ или запросите новый скан.
Надо ли чистить текст до чанкинга?
Да, сначала чистка, потом чанкинг. Если вы режете грязный текст на части, каждый чанк уже несет ошибку дальше в поиск.
Сначала уберите повторы, колонтитулы, пустые страницы и склейки строк. Только после этого делите текст на фрагменты и стройте индекс.
Что делать с дублями страниц и разными версиями одного документа?
С дублями нужно разбираться сразу. Иначе поиск начнет чаще тянуть не самый верный фрагмент, а тот, который просто повторяется в индексе.
Храните у каждого куска номер страницы, имя файла и версию документа. Тогда вы быстро увидите, откуда пришел ответ, и не смешаете черновик с подписанной копией.
Спасет ли новая модель, если OCR уже наделал ошибок?
Обычно нет. Новая модель может говорить аккуратнее, но она все равно опирается на тот текст, который лежит в индексе.
Проверьте это просто: оставьте один и тот же индекс и задайте одинаковые вопросы двум или трем моделям. Если все спотыкаются на одних и тех же местах, проблема в источнике или в поиске, а не в модели.
С чего начать, если команда только внедряет RAG на сканах?
Начните с малого: возьмите один тип документов, задайте порог качества страницы и заведите отдельную очередь для плохих сканов. Этого уже хватит, чтобы убрать большую часть грубых сбоев.
Если вы сравниваете несколько моделей, держите один и тот же индекс и меняйте только модель. Для такой проверки удобно, когда можно переключать модели через один OpenAI-совместимый эндпоинт без переделки SDK и текущих промптов.