Шторм кэша при одинаковых промптах: как гасить пики API
Шторм кэша при одинаковых промптах бьет по лимитам и бюджету. Разберем схлопывание запросов, TTL, блокировки и быстрые проверки.
Где начинается проблема
Проблема обычно выглядит безобидно. Один и тот же промпт приходит не один раз, а сразу десятками. Пользователь жмет кнопку, фронтенд делает повтор, воркеры берут задачи из очереди, ретраи срабатывают почти одновременно. В логах это похоже не на атаку, а на обычный рабочий трафик.
Типичный пример - бот поддержки. Утром у него появляется популярный вопрос: "Где мой заказ?" Пока первый ответ еще строится, тот же запрос успевают отправить 20, 50 или 100 раз. Если система не понимает, что эта задача уже считается, она запускает одинаковый вызов к LLM для каждого запроса отдельно.
Обычный кэш здесь помогает только после того, как первый ответ уже готов. Пока кэш пуст, все параллельные запросы видят одно и то же: значения нет, значит нужно идти в модель. Так и начинается шторм кэша.
У LLM это особенно неприятно, потому что ответ строится не за миллисекунды. За это время успевает накопиться новая пачка одинаковых вызовов. Вместо одного дорогого запроса вы получаете много одинаковых, и все они бьют в один API.
Дальше проблема быстро расходится по всей цепочке. Очередь становится длиннее, задержка растет, лимиты заканчиваются быстрее, часть запросов уходит в 429 или таймаут, а счет растет из-за повторной оплаты одной и той же работы.
Если трафик идет через единый OpenAI-совместимый шлюз, это видно особенно ясно. Например, в логах AI Router легко заметить, что много одинаковых payload приходят почти в одну секунду, хотя бизнес-задача у них одна. Это хороший сигнал: проблема не в модели, а в том, что система не объединяет одинаковую работу в один запуск.
Почему одинаковые запросы приходят пачкой
Одинаковые запросы редко появляются случайно. Обычно у них есть общий триггер: кнопка в интерфейсе, массовая рассылка, автопроверка, запуск отчета по расписанию. Если много людей делают одно и то же почти одновременно, система получает не поток разных задач, а пачку копий.
Так бывает чаще, чем кажется. Пользователи заходят в сервис в начале рабочего дня, открывают чат поддержки после push-уведомления или массово жмут одну кнопку после письма. Для человека разница в несколько сотен миллисекунд незаметна, а для API это уже резкий пик.
Шум добавляет и инфраструктура. Один воркер отправил запрос, не дождался ответа за 10 секунд и решил повторить. Второй сделал то же самое. Потом очередь перекинула задачу еще раз. В итоге один исходный промпт быстро превращается в серию одинаковых вызовов, хотя пользователь нажал кнопку только один раз.
Планировщик тоже часто создает толпу. Команды любят ставить задачи на круглое время: 09:00, 12:00, начало часа, начало дня. Если сотни задач стартуют в одну секунду и строят один и тот же промпт, всплеск почти гарантирован. Иногда это опаснее, чем живой трафик, потому что у расписания нет естественного разброса.
Отдельно стоит помнить про TTL. Пока популярный ответ лежит в кэше, все спокойно читают готовый результат. Как только запись истекает, новые запросы одновременно уходят за тем же ответом. Кэш уже пуст, а новый результат еще никто не успел положить обратно.
Если несколько внутренних сервисов ходят через один шлюз, эффект заметен еще сильнее. Разные команды могут отправить одинаковый промпт в один и тот же момент, если у них общий сценарий проверки, суммаризации или классификации. Снаружи это выглядит как внезапный скачок нагрузки, хотя причина простая: несколько систем одновременно попросили одно и то же.
Главная причина пика обычно не в общем росте трафика, а в синхронности. Даже умеренная нагрузка быстро становится дорогой, если запросы совпадают по смыслу и по времени.
Что считать одной и той же задачей
Если два запроса выглядят одинаково для человека, это еще не значит, что для системы это одна и та же задача. Для кэша и схлопывания важен не только текст пользовательского сообщения. Один и тот же вопрос к разным моделям уже считается разными вызовами: у них могут отличаться цена, задержка и сам ответ.
Поэтому идентификатор задачи собирают из всего, что влияет на результат. Обычно туда входят модель и ее версия, system prompt, параметры вроде temperature, top_p и лимита токенов, формат ответа, язык, вложения и клиент, от имени которого пришел запрос.
Даже небольшой сдвиг в настройках меняет смысл дедупликации. Запрос с temperature=0 нужен для предсказуемого ответа. Запрос с temperature=0.8 уже решает другую задачу. Объединять их опасно: кто-то получит не тот результат, на который рассчитывал.
Перед вычислением хэша запрос полезно нормализовать. Уберите лишние пробелы, приведите регистр там, где он не меняет смысл, очистите служебные поля, которые могут приходить в разном порядке. Иначе Где заказ? и где заказ? создадут две разные записи, хотя по сути это один вопрос.
Но здесь легко перестараться. В коде, SQL, именах файлов и некоторых JSON-структурах регистр и пробелы значимы. Если пользователь приложил PDF, таблицу или изображение, в отпечаток задачи нужно добавить и сам файл, и его версию. Один и тот же вопрос к двум разным документам не считается дублем.
В общей инфраструктуре запросы почти всегда нужно разделять по клиенту. Один банк и один ритейлер могут задать одинаковый вопрос, но делить между ними один ответ нельзя. Если вы строите такую логику поверх общего шлюза, границы по клиентам и данным должны оставаться жесткими.
Простое правило такое: если параметр меняет ответ, стоимость или правила обработки данных, включайте его в хэш. Если не меняет, убирайте. Тогда система будет ловить настоящие дубли, а не случайные совпадения.
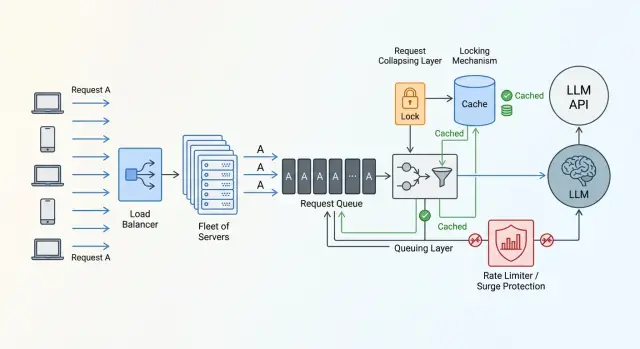
Как работает схлопывание запросов
Когда в систему почти одновременно прилетают одинаковые промпты, нет смысла отправлять их к модели по одному. Достаточно одного внешнего вызова. Остальные запросы могут подождать тот же результат несколько сотен миллисекунд и не создавать новый пик.
Обычно схема держится на "отпечатке" задачи. Это короткая строка или хэш, собранный из промпта, модели, system message и параметров, которые влияют на ответ. Если отпечаток совпал, система считает работу одинаковой.
Дальше все довольно просто.
- Первый запрос с новым отпечатком становится лидером.
- Лидер создает запись о том, что задача уже выполняется, и уходит к провайдеру.
- Следующие запросы с тем же отпечатком не вызывают модель повторно, а ждут результат лидера.
- Когда ответ готов, лидер сохраняет его в кэш и отдает всем ожидающим.
Это уже не совсем обычный кэш. Пока лидер еще не получил ответ, у системы есть знание, что такая работа идет прямо сейчас. Именно это знание и спасает от всплеска.
Если ответ пришел успешно, стоит сохранить не только текст, но и полезные метаданные: модель, время создания, TTL, число токенов и статус. Тогда ожидающие запросы могут быстро забрать готовый результат, а команда потом сможет разобрать спорные случаи и посчитать экономию.
Хороший эффект особенно заметен на коротких массовых всплесках. Если 40 пользователей нажали одну и ту же кнопку в интерфейсе, без схлопывания наружу уйдут 40 вызовов. Со схлопыванием чаще всего уходит один.
Самый неприятный момент начинается, когда лидер завис. Провайдер может тянуть ответ слишком долго, соединение может оборваться, а процесс может упасть до записи в кэш. Поэтому ожидание всегда должно иметь предел. Когда он истек, система должна действовать по правилу, а не наугад: выбрать нового лидера, вернуть старый ответ из кэша или быстро отдать ошибку и не пускать толпу в повторный штурм.
Как выбрать TTL и окно ожидания
TTL для схлопывания не должен быть большим. Его задача не хранить ответ "на всякий случай", а пережить короткую волну одинаковых запросов. Если один и тот же промпт прилетает десятки раз за 2-3 секунды, часто хватает 15-60 секунд.
Для частых и стабильных ответов TTL можно сделать чуть длиннее. Краткая классификация текста, типовой FAQ или извлечение одинаковых полей из одного шаблона документа обычно спокойно живут с коротким кэшем. Для данных, которые меняются в течение дня, лучше ставить минимум или не кэшировать ответ вообще.
Полезно на короткое время хранить и временные ошибки. Если провайдер вернул 429 или словил таймаут, а вы ничего не кэшировали, все ожидающие клиенты сразу пойдут повторно и сами поднимут новый пик. Такой негативный кэш должен жить совсем недолго.
На старте обычно хватает простых ориентиров. Успешный ответ можно держать 15-60 секунд. Для 429 и таймаута часто достаточно 1-3 секунд. Для временной ошибки провайдера вроде 500 или 502 обычно хватает 5-15 секунд. Ошибки валидации лучше не кэшировать, если причина зависит от конкретного пользователя.
Еще одна полезная мелочь - добавить случайный сдвиг к TTL. Если все записи истекут ровно через 30 секунд, система сама создаст новый пик. Проще дать небольшой разброс, например 30 секунд плюс случайные 0-5 секунд, или добавить jitter на 10-20%.
С окном ожидания логика такая же. Ждать бесконечно нельзя. Если первый запрос завис, очередь за ним только растет. Для быстрых операций часто хватает 300-800 мс. Для генерации, которая обычно идет 1-2 секунды, окно можно поднять до 2-3 секунд. Дальше пользователи уже начинают чувствовать хвост задержки.
Если вы ведете вызовы через AI Router, эти значения удобно подбирать по логам и смотреть не только среднюю задержку, но и p95 с p99 для повторяющихся отпечатков. Обычно по ним быстро видно, где TTL слишком короткий, а где ожидание собрало лишнюю очередь.
Порядок внедрения
Если делать это по частям, рабочую схему часто можно собрать за один спринт. Самая частая ошибка - сначала поставить кэш и надеяться, что этого хватит. При шторме одинаковых промптов порядок важнее самого кэша.
Сначала соберите отпечаток запроса. Берите только поля, которые действительно влияют на ответ: system prompt, user prompt, модель, температуру, формат ответа, язык, ID вложений или документов, если они участвуют в генерации. Не добавляйте timestamp, request_id, IP и другой шум. Иначе одинаковые задачи станут разными, и дедупликация просто не сработает.
Потом создайте запись о выполняющейся задаче до вызова внешнего API. Это может быть строка в Redis, локальная карта в памяти или запись в общем хранилище с короткой арендой. Смысл один: первый запрос становится лидером, а все следующие видят, что работа уже идет.
После этого подключите ожидание для дублей. Лидер уходит во внешний API и держит за собой эту запись. Дубликаты не вызывают модель повторно, а ждут результат по тому же отпечатку. Если лидер завис или умер, запись протухает, и один из ожидающих берет работу на себя. Когда ответ готов, сервис кладет его в кэш и удаляет запись о выполняющейся задаче.
В кэш стоит писать не только сам текст. Сохраняйте модель, провайдера, время генерации, число токенов, статус, created_at и TTL. Эти данные помогают разбирать спорные случаи и считать реальную экономию.
И еще одно правило, о котором часто забывают: блокировку нужно снимать всегда в finally. Ошибка модели, сетевой таймаут или отмена запроса клиентом не должны оставлять висящую запись. Иначе один сбой быстро превратит защиту от пика в пробку.
Пример с ботом поддержки
Банковский бот поддержки часто ловит пик не из-за сбоя, а из-за обычной рассылки. Банк отправил push про новую карту, и через минуту в поддержку прилетели сотни одинаковых сообщений: "Какой лимит по этой карте?" Первые 200 диалогов почти не отличаются друг от друга.
Если бот отправляет каждый такой вопрос в LLM отдельно, он сам создает проблему. За несколько секунд наружу уходит 200 одинаковых вызовов, хотя по сути система решает одну задачу.
Без схлопывания картина выглядит так: пользователь A спрашивает про лимит, через 50 миллисекунд то же самое делает пользователь B, потом приходят еще десятки таких же сообщений, и каждое идет в модель отдельно. Бот получает один и тот же ответ много раз, но платит за каждый вызов. Если внешний API уже загружен, часть запросов ждет дольше, а часть упирается в лимиты.
Со схлопыванием все проще. Система считает отпечаток запроса, проверяет, есть ли такой же расчет в работе, и отправляет в модель только первый вызов. Остальные сессии ждут тот же результат. Когда ответ приходит, бот кладет его в кэш на короткий TTL, например на 30-60 секунд, и сразу раздает всем ожидающим. Если еще 20 человек зададут тот же вопрос в это окно, бот ответит из кэша без нового обращения наружу.
Разница получается очень заметной. Без дедупликации банк делает 200 внешних вызовов. Со схлопыванием наружу уходит один, а остальные 199 получают готовый ответ из ожидания или кэша.
Этот прием хорошо работает для общих вопросов после рассылки, баннера или новости в приложении. Но если человек спрашивает свой персональный лимит, остаток или статус заявки, такие запросы уже нельзя склеивать только по общему тексту. В ключ нужно включать данные конкретного клиента.
Ошибки, которые возвращают всплеск
Один промах в логике, и пик нагрузки возвращается за пару минут. Обычно дело не в одной большой ошибке, а в нескольких мелких сразу.
Самая частая ошибка - включать в отпечаток случайные поля: request_id, timestamp, trace_id или nonce. Тогда два одинаковых промпта получают разные хэши, и схема просто не срабатывает. В отпечаток нужно класть только то, что реально меняет ответ.
Другая крайность - слишком длинный TTL. Команда видит, что защита от всплесков сработала, а потом через час пользователи получают старый ответ на уже изменившийся вопрос. Для цен, остатков, статусов заявки и похожих данных это плохой вариант. Короткое окно ожидания для выполняющейся задачи и отдельный TTL для готового ответа обычно работают лучше, чем один большой срок на все случаи.
Еще одна дорогая ошибка - вообще не кэшировать временные сбои провайдера. Провайдер вернул 500, воркер упал, и все ожидающие клиенты сразу делают повтор. Один сбой превращается в бомбардировку API. Короткий негативный кэш и небольшой jitter в ретраях сильно снижают этот риск.
Проблемы создает и глобальная блокировка. Если одна тяжелая задача заняла lock, остальные, даже совсем другие, ждут ее без причины. Схлопывание должно работать по отпечатку задачи, а не по всему сервису. Иначе вы не уменьшаете всплеск, а просто размазываете задержку по всем пользователям.
Часто ломают схему и забытые записи о выполняющейся задаче после падения воркера. Запрос уже никто не обрабатывает, но флаг висит. Новые клиенты либо ждут до таймаута, либо обходят кэш и снова идут наружу. Такие записи нужно чистить по TTL, heartbeat или через явное завершение при рестарте процесса.
Быстрая проверка перед запуском
Даже аккуратная дедупликация легко ломается на мелочах. До релиза полезно проверить не весь код сразу, а несколько простых метрик и два неприятных сценария: всплеск одинаковых запросов и ошибку у провайдера.
Сначала посчитайте долю дублей. Возьмите обычный трафик за день или хотя бы за час пик и сгруппируйте запросы по вашему правилу идентичности: промпт, модель, параметры, системный контекст, язык, вложения. Если дублей меньше 1-2%, схема может не окупить свою сложность. Если их 10%, 20% и выше, эффект обычно заметен сразу.
Дальше посмотрите на пять вещей: сколько входящих запросов попало в одну группу дублей, сколько из них стали лидерами и реально ушли к провайдеру, сколько дождались ответа из общей задачи или кэша, какое среднее время ожидания у дублей и какой у него p95, а также что происходит после ошибки - новая попытка, сброс записи или залипшая блокировка.
Отдельно полезно посчитать соотношение между числом входящих запросов и числом реальных внешних вызовов. Это одна из самых понятных метрик. Если на 100 одинаковых запросов вы все еще делаете 70 внешних вызовов, схема почти ничего не экономит. Если делаете 1-5, значит логика работает как надо.
Перед запуском стоит отдельно проиграть два теста. В первом подайте всплеск одинаковых запросов в одну секунду и проверьте, сколько лидеров уйдет наружу. Во втором специально сломайте вызов к провайдеру и посмотрите, не побегут ли все ожидающие в повтор одновременно.
Что делать дальше в продакшене
Не пытайтесь включить схлопывание сразу во всех цепочках. Сначала выберите один горячий сценарий, где дубли уже бьют по бюджету или по задержке. Чаще всего это чат поддержки, поиск по базе знаний или всплеск одинаковых вопросов после рассылки.
После первого релиза проблема редко исчезает полностью. Лучше проверить схему на одном узком участке, чем раскатать ее везде и потом разбирать странные таймауты. На одном сценарии проще понять, где дедупликация реально экономит вызовы, а где она только добавляет ожидание.
Без цифр команда быстро начинает спорить по ощущениям. Поэтому сразу собирайте базовые метрики: долю дублей среди входящих запросов, число внешних вызовов, которых удалось избежать, среднее и пиковое время ожидания у присоединившихся запросов, долю таймаутов в ожидании и случаи, когда ошибка одного лидера разошлась на всех ожидающих.
Эти числа нужны не для отчета. Они показывают, где схема ломается: на слишком коротком TTL, на плохом ключе кэша или на неверном окне ожидания.
Правила схлопывания лучше держать рядом с маршрутизацией. Если нормализация промпта живет в одном сервисе, блокировки в другом, а выбор модели в третьем, отладка становится долгой и нервной. Один слой должен решать, что считать одной задачей, когда объединять запросы, сколько ждать ответ и когда запускать новый вызов.
Если команда уже использует AI Router как единый OpenAI-совместимый шлюз, это удобная точка для наблюдения за такими сценариями. В одном месте видно повторяющиеся запросы, задержки и поведение провайдеров, поэтому проще понять, откуда взялся пик и где именно нужно ставить дедупликацию.
Лучший подход здесь довольно приземленный: выбрать один горячий путь, довести его до спокойных графиков, проверить ошибки и только потом подключать следующий. Так шторм кэша действительно становится реже, а не просто переезжает в другое место системы.
Часто задаваемые вопросы
Что такое шторм кэша при LLM-запросах?
Это ситуация, когда много одинаковых запросов приходят почти одновременно, а система отправляет каждый из них в модель отдельно. Обычный кэш помогает только после первого готового ответа. Пока ответ еще считается и кэш пуст, дубли успевают уйти наружу и создают пик по задержке, лимитам и счету.
Что включать в отпечаток запроса для дедупликации?
Берите только то, что меняет ответ или правила обработки: модель и ее версию, system prompt, текст запроса, temperature, top_p, лимит токенов, формат ответа, язык, вложения и клиента. Не добавляйте request_id, timestamp, trace_id и другой шум, иначе одинаковые задачи перестанут совпадать.
Нужно ли нормализовать промпт перед хэшированием?
Да, но аккуратно. Обычно хватает убрать лишние пробелы, привести служебные поля к одному виду и отсортировать данные, если порядок не важен. Не трогайте то, что меняет смысл: код, имена файлов, часть JSON и содержимое вложений.
Какой TTL выбрать для схлопывания одинаковых запросов?
Для старта ставьте короткий TTL. Успешный ответ часто можно держать 15–60 секунд, 429 и таймаут — 1–3 секунды, временные ошибки провайдера вроде 500 или 502 — 5–15 секунд. Если данные быстро меняются, лучше сократить TTL или вообще не кэшировать готовый ответ.
Сколько ждать результат лидера, прежде чем запускать новый вызов?
Ориентируйтесь на обычную задержку сценария. Если вызов быстрый, часто хватает 300–800 мс. Если генерация обычно идет 1–2 секунды, разумно ждать до 2–3 секунд. Дольше держать дубль в ожидании редко полезно: человек уже заметит задержку.
Что делать, если первый запрос завис или воркер упал?
Не оставляйте систему гадать. Дайте записи о выполняющейся задаче короткий срок жизни, снимайте блокировку в finally и решите заранее, что делать после таймаута: выбрать нового лидера, вернуть старый ответ из кэша или быстро отдать ошибку. Так один зависший вызов не потянет за собой толпу повторов.
Можно ли схлопывать одинаковые запросы от разных клиентов?
По умолчанию нет. Даже если текст совпадает, у разных клиентов разные данные, правила доступа и границы хранения. Общий ответ между банком и ритейлером отдавать нельзя. Если хотите объединять такие запросы, включайте идентификатор клиента в отпечаток.
Когда дедупликацию лучше не включать?
Не для всех задач. Если ответ зависит от личных данных, текущего статуса, остатка, цены или другого быстро меняющегося состояния, общий кэш может вернуть чужой или устаревший результат. В таких случаях либо включайте персональные поля в отпечаток, либо не объединяйте запросы вовсе.
Как понять, что схлопывание реально экономит вызовы?
Смотрите на простое соотношение: сколько одинаковых входящих запросов превратилось в реальные внешние вызовы. Если на 100 дублей наружу уходит 1–5 запросов, схема работает хорошо. Еще полезно смотреть долю дублей, среднее ожидание присоединившихся запросов, p95 и поведение после ошибок провайдера.
С чего начать внедрение, чтобы не сломать продакшен?
Начните с одного горячего сценария, где дубли уже заметны, например с бота поддержки или поиска по базе знаний. Сначала соберите отпечаток запроса, потом добавьте запись о задаче в работе, затем ожидание для дублей и короткий TTL для готового ответа. После этого проверьте всплеск одинаковых запросов и отдельно проиграйте сбой у провайдера.