Tail latency у LLM: как найти медленные 1% запросов
Tail latency у LLM часто прячется в длинных промптах, холодных моделях и инструментах. Покажем, как найти медленные 1% и убрать узкие места.
Почему тормозит малая часть запросов
У tail latency в LLM неприятная особенность: пользователь запоминает не среднее время ответа, а редкую длинную паузу. Если 99 сообщений приходят за 2 секунды, а одно - за 18, впечатление портит именно этот один ответ.
В чате это особенно заметно. Человек ждет, нажимает еще раз, думает, что окно зависло, или просто уходит. Серия быстрых ответов не спасает, если важный вопрос вдруг "задумался" на полминуты.
Средняя задержка хорошо выглядит в отчете, но плохо показывает реальный опыт. Она сглаживает всплески, поэтому команда видит "нормальную" цифру, а поддержка получает жалобы на медленные запросы LLM.
Хвост задержки обычно проявляется не на простых репликах, а на тяжелых ветках: длинный запрос, большой контекст, вызов внешнего инструмента, объемный ответ. В часы пик к этому добавляется очередь, и те же сценарии становятся еще медленнее.
Даже если компания работает через единый OpenAI-совместимый endpoint, общая картина может выглядеть ровной, пока малая часть трафика уходит в более тяжелый маршрут. Пользователь не видит внутреннюю схему. Он видит только то, что ответ пришел слишком поздно.
Поэтому среднее значение почти бесполезно без p95 и p99. Пока вы не смотрите на перцентили по типам запросов и времени суток, самые медленные 1% будут прятаться за красивой общей метрикой.
Где обычно прячется хвост задержки
У большинства LLM-приложений средняя задержка выглядит терпимо, пока команда не разберет p95 и p99. Именно там и прячется хвост: один пользователь ждет 2 секунды, другой - 18, хотя запросы на первый взгляд похожи.
Частая причина - раздутый системный промпт и слишком большой контекст. Модель читает каждый токен до того, как начнет отвечать. Лишние инструкции, длинная история чата и большие вставки из базы знаний быстро добавляют секунды. Особенно неприятны случаи, где 90% запросов короткие, а редкие диалоги тащат за собой весь архив переписки.
Второй тип проблем связан не с текстом, а с состоянием модели. После простоя некоторые модели стартуют медленнее: контейнер просыпается, GPU получает нагрузку, кэш пустой. Для пользователя это выглядит как случайный долгий ответ, хотя код не менялся. Такой холодный старт легко спутать с сетевой проблемой.
Много времени съедают и tool calls. Поиск, CRM, база данных или внутренний API могут работать дольше самой генерации. LLM уже выбрала инструмент, но потом ждет медленный SQL, перегруженный поиск или сервис, который отвечает рывками. Если цепочка вызывает несколько инструментов подряд, задержка растет почти незаметно, пока не посмотришь трассировку по шагам.
Есть и более прозаичная причина: повторы после таймаута. Один сервис не дождался ответа за 5 секунд и отправил retry. Потом то же сделал следующий слой. В логах кажется, что модель просто медленная, а на деле система сама умножила нагрузку.
Отдельная история - очереди у провайдера в часы пика. Днем все быстро, а вечером часть запросов ждет перед инференсом. В мультипровайдерной схеме это видно особенно хорошо: одна и та же модель у разных провайдеров может вести себя по-разному при одном и том же промпте.
Обычно хвост стоит искать в пяти местах:
- размер системного промпта и общего контекста
- холодные старты после паузы
- задержка каждого tool call
- ретраи после таймаута
- очередь у провайдера или в собственном шлюзе
Если смотреть только на общий таймер запроса, все эти причины смешаются. Тогда длинный контекст, холодный старт и медленный инструмент выглядят как одна проблема, хотя чинятся они по-разному.
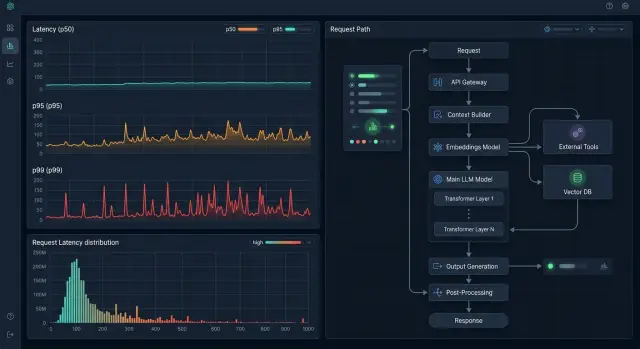
Как разложить задержку по этапам
Общая задержка почти не помогает, если вы ищете медленные 1% запросов. Один ответ на 10 секунд может тормозить из-за длинного промпта, холодной модели, повторного запроса или медленного инструмента. Пока все это лежит в одной цифре, причина не видна.
Полезнее смотреть на трассу каждого запроса как на цепочку шагов:
- вход в API-шлюз и первичную проверку
- выбор модели, провайдера или маршрута
- ожидание первого токена от модели
- генерацию ответа до последнего токена
- вызовы инструментов и возврат результата клиенту
Такой разбор особенно полезен, если команда работает через единый OpenAI-совместимый шлюз вроде AI Router. Тогда можно отдельно видеть время на входе в шлюз, маршрутизацию и ответ модели, а не складывать все в одну метрику.
Без токенов картина тоже будет смазанной. Логируйте, сколько токенов пришло на вход и сколько модель отдала на выходе. Тогда видно, где проблема в длине запроса, а где короткий промпт почему-то ждал дольше обычного.
Инструменты лучше считать по отдельности, а не одной строкой "tool calls". Поиск в базе за 300 мс и запрос во внешний скоринг за 4 секунды - это две разные истории. Если агент сделал три вызова подряд, у каждого должно быть свое время начала, конца и статус.
Retry, таймауты и смену маршрута тоже помечайте явно. Иначе запрос, который сначала попал в медленный бэкенд, а потом пошел по другому пути, будет выглядеть как случайный всплеск. На деле это уже другой сценарий выполнения.
Сравнивайте p95 и p99 только внутри одного сценария. Не смешивайте чат поддержки, пакетную обработку документов и внутреннего помощника в одну метрику. Даже внутри одного продукта лучше делить запросы по шаблону промпта, модели и наличию инструментов.
Если p95 у сценария держится на 2 секундах, а p99 прыгает к 11, смотрите не на среднее, а на редкие ветки. Хвост почти всегда сидит в одном конкретном этапе: длинный вход, холодный старт, медленный tool call или скрытый retry.
Как поймать медленные 1% по шагам
Искать хвост по всем сценариям сразу почти всегда бесполезно. Шума слишком много. Проще взять два среза: самый частый сценарий, который пользователи запускают каждый день, и самый дорогой по времени или деньгам.
Нужен не красивый датасет, а честный. Выгрузите хотя бы 1000 реальных запросов и не чистите их руками. Не выкидывайте длинные диалоги, странные повторы, обрывы фраз и редкие tool calls. Именно в таком "мусоре" часто и сидят медленные запросы.
Рабочий порядок простой:
- соберите для каждого запроса одни и те же поля: длину промпта, выбранную модель, число вызовов инструментов, время до первого токена и полное время ответа
- разделите массив на группы: короткие и длинные промпты, быстрые и медленные модели, запросы без инструментов и с ними
- отдельно посмотрите на p99 и спросите, что общего именно у самых медленных запросов
- формулируйте по одной причине за раз и проверяйте ее отдельным тестом
Частая ошибка проста: команда сразу меняет модель, лимиты токенов и порядок tool calls. График после этого может стать лучше, но причина так и останется неизвестной.
Небольшой пример. Если в p99 почти все запросы длиннее 12 тысяч токенов и в них есть два обращения к внутренним сервисам, начните с раздельных тестов: сначала сократите контекст на той же модели, потом отключите один инструмент на том же наборе запросов. Так быстрее видно, где теряются секунды.
Что делают длинные промпты
Длинный промпт почти всегда бьет по времени до первого токена. Модель сначала читает вход, и только потом начинает отвечать. Если запрос раздут, задержка растет еще до генерации.
Из-за этого хвост часто прячется не в самом ответе, а во входных токенах. Один и тот же сценарий может пройти быстро 99 раз, а на сотом запросе зависнуть только потому, что туда попала слишком длинная история.
Чаще всего новый вопрос занимает мало места, а старый контекст - много. Пользователь пишет одну фразу, а система отправляет 20 прошлых реплик, длинные служебные инструкции, описание инструментов и куски базы знаний. Модель заново читает все это каждый раз.
Пустую нагрузку обычно создают одни и те же вещи: повтор правил формата ответа в каждом запросе, полная история чата вместо короткой выжимки, одинаковые блоки правил для всех сценариев и большие схемы инструментов, хотя нужен один простой вызов.
Такой балласт редко улучшает ответ. Зато он легко добавляет секунды к хвосту задержки.
Хороший пример - чат поддержки банка в час пик. Клиент спрашивает, почему карта отклонена, а приложение отправляет не только вопрос, но и всю переписку, старые проверки, шаблон вежливости, правила комплаенса и описание пяти инструментов. Сам ответ короткий, но модель тратит время на чтение лишнего.
Обычно помогает не "урезать все", а навести порядок в контексте. Историю чата лучше сжимать в короткое резюме после нескольких ходов. Постоянные инструкции стоит хранить в шаблоне, а не дублировать по десять раз. Если часть данных не влияет на ответ, ее не нужно отправлять.
На практике хорошо работают четыре меры: оставлять только последние релевантные сообщения, делать краткое резюме старых шагов, убирать дубли правил и передавать только те документы, которые относятся к текущему вопросу. Во многих случаях этого хватает, чтобы убрать медленные запросы LLM без заметной потери качества.
Если после сокращения контекста p50 почти не меняется, а p99 падает заметно, причина была именно в тяжелых промптах.
Почему холодные модели отвечают дольше
LLM отвечает медленнее не только из-за длинного промпта. Часто проблема в том, что сама модель "холодная": ее давно не вызывали, и провайдер не держит ее в полной готовности. Тогда первый запрос платит за загрузку весов в память, подготовку GPU и запуск всего контура. Для пользователя картина простая: вчера было 2 секунды, а сейчас внезапно 12.
Такое чаще видно на редких моделях. Популярные варианты обычно держат теплыми, потому что трафик идет постоянно. А нишевая модель, новый релиз или fine-tuned версия могут простаивать часами. После паузы первый вызов часто самый медленный, а следующие идут ровнее.
Автоскейл тоже меняет картину в течение дня. Ночью провайдер может держать меньше инстансов, утром поднимать новые, а в час пик перераспределять нагрузку между регионами и очередями. Из-за этого один и тот же запрос в 10:00 и в 14:00 ведет себя по-разному, хотя промпт не менялся.
Разница между провайдерами бывает очень заметной. Один и тот же запрос к одной и той же модели может стартовать быстро у одного оператора и медленно у другого, потому что у них разная политика прогрева и очередей. Если у вас единый шлюз, такие различия проще сравнивать на одном наборе запросов.
Практика тут простая: отделяйте время до первого токена от общей длительности ответа, помечайте, был ли запрос первым после простоя, и смотрите latency по провайдеру, модели и часу дня. Если холодные старты происходят редко, этого уже достаточно, чтобы увидеть закономерность.
Запасной маршрут тоже полезен. Когда основная модель просыпается слишком долго, система может отправить запрос в другой бэкенд или на близкую по качеству модель. Пользователь не заметит внутреннюю перестановку, зато не будет ждать лишние 8-15 секунд.
Холодная модель - не баг и не "случайный шум" в графике. Это обычное свойство инфраструктуры. Если не учитывать его в трассировке и маршрутизации, медленный 1% так и будет казаться необъяснимым.
Как инструменты добавляют секунды
У медленного ответа причина часто сидит не в самой модели. Модель ждет внешний вызов, и весь ответ стоит на паузе, пока не вернется поиск, база данных или сторонний API.
Поиск по документам тянет время сразу в нескольких местах. Сеть до хранилища дает лишние сотни миллисекунд, индекс может отвечать неровно, а фильтры по дате, роли или продукту делают запрос тяжелее, чем кажется. Если система берет слишком много фрагментов, а потом долго их ранжирует, задержка растет еще до первого токена.
С SQL история еще жестче. Широкие выборки, лишние поля, сортировка по большим таблицам и джойны без нормальных индексов легко добавляют 2-5 секунд. Команда часто смотрит только на то, что запрос "работает", но не проверяет, сколько строк он читает на самом деле.
Один медленный API может держать весь ответ. Так бывает с CRM, антифродом, платежным сервисом или внутренним каталогом. Если цепочка вызовов идет последовательно, каждая пауза просто прибавляется к следующей.
Обычно быстрее работает такой подход:
- искать документы и тянуть профиль клиента параллельно
- ставить таймаут на каждый внешний вызов
- возвращать частичный ответ, если второстепенный инструмент не успел
- кэшировать частые запросы к справочникам
Если вы ведете трафик через единый шлюз, разделяйте в логах время модели и время каждого tool call. Иначе легко решить, что тормозит модель, хотя секунды съедает внешний сервис.
Среднее время ответа тут почти бесполезно. Смотрите p95 и p99 по каждому инструменту отдельно. Тогда сразу видно, кто именно портит хвост задержки.
Ошибки, которые мешают найти причину
Среднее время ответа почти всегда успокаивает зря. Если система в среднем отвечает за 2 секунды, это не значит, что пользователю хорошо. Один процент запросов может висеть 12-20 секунд, и именно они ломают опыт.
Еще одна частая ошибка - свалить разные сценарии в один график. Короткий вопрос в чате, запрос с поиском по базе знаний и длинный разбор документа нагружают систему по-разному. Если смешать их в одну линию, вы увидите "среднюю температуру" и пропустите место, где рождаются медленные запросы.
Многие команды не сохраняют рядом с задержкой размер промпта. Потом они видят всплеск и спорят: виновата модель или сеть. На деле причина может быть проще. Вход вырос с 2 000 до 20 000 токенов, поиск добавил лишние куски текста, а модель начала дольше читать и дольше генерировать ответ. Без длины входа, длины выхода и числа tool calls картина почти слепая.
Часто лечат не тот слой. Команда меняет модель, режет температуру и крутит параметры, а тормозит внешний сервис: поиск, CRM, антифрод или база документов. Если модель начала ответ быстро, а потом 4 секунды ждала результат инструмента, проблема не в модели.
Еще один промах - делать выводы по нескольким удачным прогонам. Хвост редко ловится с пяти тестов в тихое время. Он выходит под нагрузкой, на холодном старте, на редком длинном промпте или при медленном внешнем вызове.
Нормальная дисциплина здесь простая:
- считать p50, p95 и p99 отдельно
- делить запросы по типам, а не мешать все вместе
- сохранять токены, размер контекста и число вызовов инструментов
- мерить этапы отдельно: роутинг, модель, поиск и tool calls
Когда эти данные лежат рядом, спорить приходится меньше. Причина обычно видна за один разбор, а не после недели догадок.
Быстрый чек-лист перед разбором
Перед поиском причины не смотрите на среднее время ответа. Оно почти всегда успокаивает и почти всегда врет. Хвост видно только там, где плохие случаи измеряются отдельно.
Проверьте базовые вещи:
- у вас есть p95 и p99 не в целом по сервису, а по каждому сценарию: чат, суммаризация, RAG, агентные задачи
- вы видите отдельно время до первого токена и полное время ответа
- логи сохраняют размер промпта, число выходных токенов, retry и все tool calls с их длительностью
- таймаут у модели и таймаут у инструментов настроены по отдельности
- есть простой запасной маршрут: другая модель, другой провайдер или более короткий путь для критичных запросов
Если хотя бы одного пункта нет, разбор быстро упрется в догадки. Вы увидите запрос на 18 секунд и решите, что виновата модель. А потом окажется, что модель дала первый токен за 900 мс, а 14 секунд ушло на медленный поиск по базе и повторный вызов инструмента.
Полезно держать один экран или один запрос в логах, где вся цепочка лежит рядом: вход, маршрутизация, вызов модели, инструменты, retry, итог. В OpenAI-совместимой схеме это особенно удобно, потому что формат событий можно сохранить одинаковым даже при смене провайдера.
И еще один практичный шаг: проверьте запасной маршрут заранее, а не во время инцидента. Когда p99 внезапно уезжает вверх, вы не захотите одновременно чинить проблему и разбирать поток жалоб.
Пример: чат поддержки банка в час пик
У банка чат поддержки днем работает ровно. Большая часть вопросов простая: "Где посмотреть лимит?", "Почему не прошел платеж?", "Как сменить номер?" Такие запросы укладываются в 2-4 секунды. Но вечером p99 резко ползет вверх, хотя средняя задержка почти не меняется.
Проблема всплывает в другом типе диалога. Клиент пишет после длинной переписки, пересылает детали по карте, спорной операции и прошлым обращениям. Модель получает огромный контекст, тратит больше времени на чтение истории и позже начинает отвечать. Так хвост и маскируется: 99% чата выглядят нормально, а редкий тяжелый запрос портит SLA.
В этом сценарии есть и второй тормоз. Когда бот должен проверить статус карты, он идет во внутренний сервис банка. Сам LLM отвечает быстро, но старый API иногда держит запрос 6-8 секунд. Пользователь видит один общий ответ и не понимает, что задержку дал не текстовый блок, а внешний инструмент.
Команда обычно снимает часть хвоста двумя простыми мерами. Сначала она сжимает историю: оставляет последние реплики, факты по клиенту и короткое резюме старого диалога вместо полного лога. Потом кэширует частые справочные ответы, например про комиссии, лимиты и перевыпуск карты. Это не лечит все, но убирает заметную долю долгих запросов.
Если вечерняя нагрузка растет и основная модель начинает отвечать хуже по времени, помогает запасной маршрут. Часть запросов можно отправить на другую модель с похожим качеством, но более стабильной задержкой. Ответ выходит чуть проще по стилю, зато чат остается в пределах SLA, а очередь не раздувается.
На таком примере видно простое правило: искать нужно не "медленный чат", а редкое сочетание факторов - длинный контекст, внешний вызов и перегруженная или холодная модель.
Что делать дальше
Не чините всю платформу сразу. Возьмите один сценарий, где задержка бьет по людям напрямую: чат поддержки, поиск по базе знаний или внутренний помощник для операторов. Соберите небольшой набор реальных запросов, хотя бы 100-200 штук, и гоняйте только его.
Потом уберите самые явные источники хвоста. Во многих случаях задержка растет не из-за самой модели, а из-за лишнего контекста и одного медленного tool call, который иногда зависает на 3-5 секунд. Если ответ не меняется без части системного промпта, длинной истории или внешнего шага, убирайте это без сожаления.
Дальше уже есть смысл сравнивать маршруты. Один и тот же набор запросов может показать, что более дорогая модель отвечает быстрее на длинных задачах, а простая модель выигрывает на коротких. Такие выводы появляются только на одинаковой нагрузке, а не по общему среднему в продакшене.
Если для таких тестов нужен единый OpenAI-совместимый endpoint, удобно работать через AI Router на airouter.kz. Он позволяет прогонять запросы через один API, не меняя SDK, код и промпты, а для команд с требованиями к data residency и локальной задержке там же есть размещение open-weight моделей в Казахстане. Это упрощает сравнение маршрутов на одном и том же наборе запросов.
Главное - мерить не среднюю задержку, а путь конкретного запроса по шагам. Тогда самые неприятные 1% перестают быть загадкой.
Часто задаваемые вопросы
Что такое tail latency у LLM простыми словами?
Это редкие запросы, которые отвечают заметно дольше остальных. Пользователь чаще запоминает именно их, а не среднее время по системе. Если почти всё приходит за 2 секунды, а часть ответов висит 12–18 секунд, проблему создает этот хвост.
Почему нельзя смотреть только на среднюю задержку?
Среднее сглаживает всплески. Оно может показывать «норму», даже когда p99 уже уехал вверх и часть людей ждет слишком долго. Для чата и агентных сценариев это особенно плохо: один долгий ответ ломает впечатление сильнее, чем десятки быстрых.
Какие метрики реально помогают поймать медленные 1%?
Сначала смотрите p95 и p99 по каждому сценарию отдельно. Потом добавьте время до первого токена, полное время ответа, размер входа, размер выхода и длительность каждого tool call. Эти числа быстро показывают, где именно теряются секунды.
Где обычно прячутся самые медленные запросы?
Чаще всего хвост сидит в длинном системном промпте, раздутой истории чата, холодном старте модели, медленном внешнем сервисе или ретраях после таймаута. В часы пик к этому часто добавляется очередь у провайдера или в своем шлюзе.
Как понять, тормозит сама модель или внешний инструмент?
Разложите запрос на шаги и замерьте каждый отдельно. Если первый токен пришел быстро, а полный ответ тянется долго, смотрите инструменты и внешние API. Если задержка растет еще до первого токена, чаще всего виноваты длинный контекст, очередь или холодная модель.
Что делать, если хвост задержки растет из-за длинного контекста?
Начните с уборки лишнего. Оставьте только релевантные сообщения, старую переписку сжимайте в короткое резюме, не дублируйте одни и те же правила в каждом запросе и не тащите документы «на всякий случай». Часто этого хватает, чтобы заметно опустить p99 без потери качества.
Как распознать холодную модель?
Смотрите на время первого запроса после паузы и сравнивайте его с обычными вызовами той же модели. Если после простоя первый ответ резко медленнее, а следующие идут ровно, вы нашли холодный старт. В продакшене помогает запасной маршрут на другой бэкенд или более стабильную модель.
Могут ли ретраи сами создавать медленные запросы?
Да, и это частая причина. Один слой не дождался ответа и отправил повтор, потом то же делает следующий слой, и система сама наращивает нагрузку. Задайте явные таймауты, помечайте каждый retry в логах и проверьте, не дублируют ли повторы друг друга.
Какой минимум логов нужен для нормального разбора?
Хватит простого набора: сценарий, модель, провайдер, время до первого токена, полное время, входные и выходные токены, число tool calls, длительность каждого вызова, таймауты и retry. Если используете единый OpenAI-совместимый шлюз, держите этот формат одинаковым для всех маршрутов. Тогда сравнение не разваливается при смене провайдера.
Как снизить p99 без большой переделки системы?
Не меняйте всё сразу. Возьмите один частый сценарий, соберите 100–200 реальных запросов и по очереди проверьте гипотезы: сократите контекст, уберите один tool call, смените маршрут, разделите таймауты модели и инструментов. Так вы быстро увидите, что именно режет хвост, а не просто сдвигает график.