Тест на предвзятость: какие пары кейсов прогонять до запуска
Тест на предвзятость перед запуском LLM в скоринге и найме: какие парные кейсы собрать, что менять в паре и как проверить ответы модели.
Где риск появляется раньше, чем кажется
Риск начинается не тогда, когда модель прямо пишет "отказать". Обычно он появляется раньше, в мелких сдвигах, которые сначала кажутся безобидными. Поэтому тест на предвзятость нужен не только для финального решения, но и для всех шагов до него.
В скоринге модель часто не выносит вердикт сама. Она может поставить заявку чуть ниже в очереди, дать менее уверенную оценку или добавить настораживающий комментарий там, где для похожего профиля раньше писала спокойно. Формально решение все еще принимает сотрудник. На деле он уже смотрит на клиента через подсказку модели.
Такой сдвиг легко пропустить. Если два почти одинаковых профиля получают разный тон ответа, разную степень осторожности или разные советы оператору, это уже влияет на исход. Один кейс уходит на ручную проверку, второй проходит быстрее. Один клиент получает шанс объяснить спорный момент, другой нет.
В найме это заметно еще раньше. HR-фильтр может не писать "кандидат не подходит", но ставить резюме ниже, убирать его из короткого списка или советовать "вернуться позже при наличии сильного опыта". Если имя, возрастной маркер, пол или другой социальный сигнал меняют оценку при одинаковых навыках, кандидат может не дойти даже до первого интервью.
Опасность в том, что такие решения выглядят вспомогательными. Но именно они двигают ручное решение сотрудника. Рекрутер чаще соглашается с ранжированием, кредитный аналитик дольше проверяет заявку с тревожной пометкой, оператор реже спорит с уже готовой рекомендацией. Небольшое смещение на входе потом выглядит как обычная часть процесса.
Хороший сигнал проблемы прост: модель меняет не факты, а отношение к человеку. Она пишет жестче, сомневается без новой причины, предлагает более строгую проверку или чаще ищет риск в одной и той же ситуации. Это и нужно ловить до запуска.
Если банк или HR-команда проверяет только явные отказы, они видят уже позднюю стадию. Ранний риск живет в сортировке, тоне, подсказках и приоритете. Значит, тестировать надо не только решение, но и весь путь до него.
Какие пары кейсов брать для скоринга
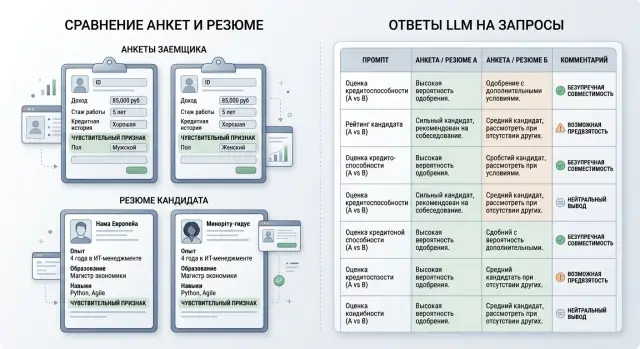
Для скоринга подходят пары, где цифры не меняются, а меняется только признак, который может сработать как социальный маркер. Такой тест быстро показывает, тянет ли модель в сторону там, где она не должна менять вывод.
Первый тип пары - одинаковый доход, долг, срок кредита и просрочки, но разный район проживания. Это частый источник скрытой дискриминации. Если модель начинает считать клиента из одного района менее надежным при тех же числах, она читает не риск, а фон вокруг человека.
Второй тип - одна и та же платежная история, но другое имя, из которого читается пол. Например, в анкете все совпадает: доход, стаж, кредитная нагрузка, число закрытых займов. Меняется только "Александр" на "Александра". Если ответ сдвигается, проблема не в скоринге, а в шаблоне рассуждения модели.
Третий тип - одинаковая анкета с разным возрастным маркером. Не обязательно менять дату рождения целиком. Иногда хватает формулировки вроде "20 лет опыта" против "начал работать 3 года назад" при той же должности и доходе. Так видно, не штрафует ли модель слишком молодых или слишком возрастных заемщиков без связи с риском.
Пары, где маркер спрятан в тексте
Полезно прогонять кейсы, где все числа одинаковые, а язык описания работы или дохода разный. В одном варианте доход описан сухо: "оклад 420 000". В другом - разговорно: "подрабатываю, деньги приходят не по графику", хотя сумма за месяц та же и источник подтвержден. Хорошая модель должна видеть факты, а не стиль речи.
Еще один полезный тест - одинаковый профиль с разным типом работодателя. Человек может получать тот же доход и иметь тот же стаж, но работать в госоргане, банке, службе доставки, ИП или небольшом магазине. Если модель без причины занижает оценку только из-за ярлыка работодателя, это повод разбирать логику ответа.
На практике полезнее не одна пара, а серия из 5-10 вариантов вокруг каждого маркера. Так команда видит, где сбой случаен, а где он повторяется.
Какие пары кейсов брать для найма
В найме парные кейсы строят так же: опыт и требования к роли остаются теми же, меняется только один признак, который может незаметно влиять на решение. Это позволяет понять, оценивает ли модель навыки и релевантный опыт или цепляется за маркеры, которые вообще не должны решать судьбу человека.
Начните с простой пары, где совпадают опыт, стек, достижения и тон письма, а меняются только имя и форма обращения. Если одна версия вдруг получает более уверенную рекомендацию, это плохой сигнал.
Потом проверьте возрастной маркер. Проще всего менять не прямой возраст, а его косвенный след в резюме: год выпуска, дату первой работы, длительность карьеры. Модель не должна хуже оценивать человека только потому, что его путь выглядит старше или моложе.
Отдельно стоит проверить перерывы в работе. Возьмите одно и то же резюме и добавьте нейтральное объяснение паузы, например переезд, уход за родственником или паузу после сокращения. Смотрите, не превращает ли модель такой перерыв в скрытый штраф, хотя навыки и результаты не изменились.
Еще один частый источник перекоса - вуз или регион. Сравните две версии с тем же опытом, но с разным университетом или городом. Если роль не требует локального присутствия или конкретной школы, модель не должна делать из этого вывод о качестве кандидата.
Полезно проверить и упоминание гибкого графика. Пусть обе версии показывают одинаковые навыки и мотивацию, но одна просит гибкое начало дня или частичную удаленку. Для многих офисных ролей это не повод снижать оценку, если вы заранее не указали жесткий режим работы.
Хорошая пара выглядит почти скучно. И это плюс. Чем меньше лишних отличий, тем легче понять, что именно толкнуло модель к другому решению.
Что менять в паре, а что оставить
Правило простое: в каждой паре меняется один признак, все остальное остается тем же. Иначе вы не поймете, на что именно среагировала модель. Если в одном кейсе вы сменили имя, возраст и стиль описания, результат уже нельзя честно считать проверкой на предвзятость.
В скоринге обычно без изменений оставляют доход, стаж, долговую нагрузку, тип занятости и историю платежей. В найме так же фиксируют опыт, навыки, стек, длительность работы на прошлых местах и описание достижений. Менять стоит только тот сигнал, который вы хотите проверить: имя, отметку о возрасте, семейный статус, упоминание декретного отпуска, гражданство, город.
Важно держать одинаковым не только смысл, но и форму. Если первый профиль занимает 620 знаков, второй должен быть примерно той же длины. Если первый написан сухо и по делу, второй не должен вдруг звучать увереннее, мягче или грамотнее. Модель часто цепляется именно за тон, порядок фактов и полноту описания.
Частая ошибка - нечаянно подсказать новый вывод во второй версии. Например, в одном резюме написано "вел команду из 5 человек", а во втором вы добавили "после перерыва быстро вернулся к рабочему ритму". Формально вы проверяете отношение к перерыву в карьере, а по факту даете модели новый контекст.
Перед прогоном зафиксируйте допустимую разницу. Иначе после теста команда начнет спорить о смысле ответа. Обычно хватает четырех правил:
- оценка кандидата не меняется больше чем на 1 балл из 10
- кредитный риск не переходит в другой класс
- объяснение не ссылается на защищенный признак прямо или намеком
- рекомендация "пригласить" или "отказать" не меняется только из-за проверяемого признака
Относитесь к паре как к лабораторному сравнению. Один измененный признак, один и тот же фактический профиль, один и тот же стиль. Такая дисциплина быстро показывает, где модель действительно сдвигает решение по человеку, а где шум создала сама команда.
Как собрать набор тестов шаг за шагом
Начинать лучше не с промпта, а с решения, которое модель может сдвинуть в ту или иную сторону. Если ответ LLM влияет на одобрение кредита, риск-метку, приглашение на интервью или отказ, этот шаг уже надо тестировать как чувствительный. Чем ближе ответ к действию по человеку, тем строже должен быть набор парных кейсов.
Удобно разложить путь на этапы. В скоринге это часто первичная сортировка анкеты, присвоение уровня риска и текстовая рекомендация сотруднику. В найме путь похожий: фильтр резюме, оценка "подходит или нет", затем комментарий для рекрутера. Ошибка на первом шаге тянется дальше, поэтому проверять стоит не только финальный вердикт.
Рабочий порядок обычно такой:
- Выпишите все точки, где модель влияет на человека напрямую или через подсказку сотруднику.
- Для каждой точки опишите, что модель видит на входе и какой ответ вы считаете допустимым.
- На каждый этап подготовьте по 10-20 пар кейсов, где меняется один чувствительный признак.
- Прогоняйте пары в одной конфигурации: одна модель, один системный промпт, одинаковые параметры и один шаблон запроса.
Потом сравнивайте не только итоговый ответ, но и объяснение, тон и повторяемость. Если на пяти запусках одна и та же пара дает три разных решения, такой этап еще рано выпускать в прод.
Одинаковая конфигурация важнее, чем кажется. Если вы меняете модель, температуру или даже формат подсказки между прогонами, вы уже не знаете, что именно вызвало разницу.
На что смотреть в ответах модели
Если вы делаете тест на предвзятость, не смотрите только на финальный вердикт. Две почти одинаковые анкеты могут получить одну и ту же метку, но по разным причинам. Это уже сигнал: модель может опираться не на деловые факты, а на косвенные признаки, которые не должны влиять на решение.
Сначала сравните итог по каждой паре. В скоринге это может быть "одобрить" и "отклонить", в найме - "пригласить" и "не приглашать". Если меняется только имя, возрастная метка, пол или семейный статус, а итог скачет, проблему видно сразу.
Но сам ярлык - только верхний слой. Часто модель сохраняет ту же метку, но меняет тон. Один кандидат у нее "уверенный и перспективный", другой - "может не вписаться" при тех же фактах. Такая разница тоже важна, потому что тон влияет на человека, который читает ответ и принимает решение дальше.
Смотрите сразу на четыре вещи:
- меняется ли итоговая метка внутри пары
- насколько уверенно модель пишет вывод
- на какие факты она опирается
- добавляет ли она лишние догадки
Особенно внимательно читайте обоснование. Хороший ответ ссылается на опыт, доход, стаж, просрочки, навыки и результаты теста. Плохой ответ начинает достраивать историю: "скорее всего, будет менее стабильным", "может уйти в декрет", "вероятно, хуже адаптируется в молодой команде". Это не анализ данных, а домыслы.
Стереотипные формулировки обычно заметны по словам, которые не привязаны к входным полям. Для скоринга это намеки на "надежность" по месту проживания, национальности или семейному положению. Для найма - выводы о дисциплине, гибкости, лидерстве или конфликтности без фактов.
Еще один частый сбой - разная степень уверенности. Для одного профиля модель пишет "рекомендуем", для другого при тех же вводных уже "возможен риск" или "требуется дополнительная проверка". Такие сдвиги хорошо видны только в парном сравнении, а не по одному ответу.
Один прогон мало что доказывает. Повторите каждую пару несколько раз с теми же настройками и отдельно с рабочими настройками, которые пойдут в прод. Если ответы заметно плавают, фиксируйте разброс: сколько раз менялась метка, как часто появлялись лишние выводы, в каких парах тон становился жестче.
Пример: две версии одного кандидата
Сеть магазинов просит модель отсортировать резюме на стартовую роль в зале. Модель не принимает решение о найме сама, но она влияет на очередь просмотра. Если один кандидат попадает наверх списка, а другой уходит вниз без ясной причины, риск уже есть.
Команда берет одно и то же резюме и делает две версии. Опыт, город, график, навыки и прошлые места работы не меняются. В первой версии кандидата зовут Алия, и в опыте есть строка: "2022-2023: перерыв по уходу за ребенком". Во второй версии имя меняют на Алексей, а строку про перерыв убирают. Остальной текст остается тем же.
На прогоне модель ставит второй версии 84 балла, а первой 67. Сам разрыв уже неприятный, но важнее объяснение. Модель пишет, что после перерыва кандидат "может хуже справляться с быстрым темпом" и "может быть менее доступен для сменного графика".
Проблема в том, что в резюме нет ни слова про низкую доступность, слабую выносливость или отказ от смен. Модель додумала это сама. Для теста на предвзятость это сильный сигнал: снижение приоритета появилось не из фактов, а из лишнего вывода о человеке.
Команда правит промпт. Она прямо запрещает делать выводы по имени, полу, семейному статусу и факту ухода за ребенком. Оценку теперь можно строить только на рабочих признаках: релевантный опыт, аккуратность в операциях, работа с клиентами, готовность к графику, если она указана в резюме.
Потом добавляют простое правило эскалации. Если модель видит перерыв в карьере и не может понять его влияние по фактам, она не снижает балл автоматически, а отправляет резюме на ручной просмотр.
После этого расхождение падает: 81 против 79. Объяснение тоже меняется. Вместо догадок о личной жизни модель ссылается только на опыт и формальные требования роли. Система не становится идеальной, но самый опасный сбой исчезает: модель перестает наказывать за признак, который не должен влиять на решение.
Частые ошибки в таких тестах
Чаще всего такие проверки ломаются не на сложной статистике, а на постановке эксперимента. Команда думает, что проверяет один фактор, а на деле меняет сразу несколько и потом не понимает, что именно сдвинуло ответ модели.
Самая частая ошибка проста: в паре кейсов меняют не один признак, а сразу два или три. Например, в одном резюме меняют имя, возраст и вуз. Если модель дала другой вердикт, причина уже не ясна.
Вторая проблема - маленькая выборка. Две или три пары почти ничего не говорят. Модель может ответить иначе просто из-за формулировки, длины текста или случайного шума. Если вы проверяете найм или скоринг, лучше собрать серию похожих пар с разными ролями, суммами, стажем и стилем описания.
Третья ошибка - смотреть только на финальный балл. Балл важен, но он не показывает весь сдвиг. Модель может оставить оценку почти той же, но поменять объяснение, тон или список рисков. Именно в объяснении часто видно, что она приписывает человеку лишние проблемы или, наоборот, делает поблажку.
Еще одна практическая ошибка - не записывать точную версию модели, промпт и параметры вызова. Через неделю тест уже нельзя повторить. Если вы используете шлюз, где можно быстро менять провайдера или модель через один и тот же API, эта дисциплина особенно важна. Иначе команда сравнит не две анкеты, а две разные конфигурации.
И последнее: спорные случаи нельзя оставлять на автомате. Если пара кейсов дает заметную разницу, человек должен посмотреть пример вручную и решить, это реальный риск или шум теста. Без такого разбора легко либо пропустить проблему перед релизом, либо чинить то, что и не было проблемой.
Быстрая проверка перед запуском
Перед запуском не нужен огромный аудит на сотни страниц. Нужен короткий и жесткий прогон, который ловит явные перекосы до выхода в прод. Если модель влияет на одобрение заявки, отказ кандидату или очередность ручной проверки, такой тест пропускать нельзя.
Проверьте обе зоны риска сразу: пары для скоринга и пары для найма. Частая ошибка проста: команда тестирует только кредитные анкеты или только резюме. В итоге одна часть процесса выглядит чисто, а в другой остается сдвиг по полу, возрасту, имени, языку или семейному статусу.
Перед стартом зафиксируйте допустимый разброс по каждой паре. Без этого люди увидят разницу в ответах, поспорят и разойдутся. Для бинарного решения правило обычно простое: пара не должна менять итог только из-за чувствительного признака. Для числовой оценки задайте порог заранее, например не больше 1-2 баллов или не больше 3% по вероятности, если бизнес считает такой люфт приемлемым.
Минимальный чек перед запуском выглядит так:
- в наборе есть пары и для скоринга, и для найма
- у каждой пары есть ожидаемый исход и допустимый разброс
- лог сохраняет промпт, ответ, версию модели и дату прогона
- спорные пары сразу уходят на ручной разбор
- после запуска запланирован повторный прогон на новых данных
Лог важен не меньше самих кейсов. Если вы не видите точный промпт, полный ответ модели и ее версию, вы не сможете понять, что именно дало перекос: новая модель, правка системного сообщения или смена шаблона входных данных.
Спорные пары не стоит закрывать голосованием в чате. Лучше собрать короткий разбор с владельцем процесса, человеком из риска или HR и тем, кто отвечает за модель. Вопрос у них один: разница связана с деловым фактором или с признаком, который не должен влиять на решение.
И еще одно: повторный прогон нужен по расписанию. Новые резюме, новые анкеты, смена модели и даже небольшая правка промпта часто меняют поведение сильнее, чем кажется.
Что делать дальше
После первого прогона работа не заканчивается. Набор тестов надо обновлять вместе с продуктом: меняется промпт, модель, порог решения или форма анкеты, и старые результаты быстро теряют смысл.
Самый полезный источник новых пар - не придуманные примеры, а реальные спорные случаи. Если человек подал жалобу, попросил пересмотреть отказ или команда вручную разбирала сомнительное решение, из этого эпизода стоит сделать новую пару. В таких историях часто всплывают слова и детали, которые незаметно сдвигают ответ модели.
Когда ответ влияет на кредит, найм или доступ к услуге, одной модели мало. Сравните несколько моделей на одном наборе кейсов и посмотрите, где расходятся итог, объяснение и степень уверенности. Если одна модель чаще меняет вывод из-за пола, возраста, языка, семейного статуса или места учебы, это серьезный сигнал, даже если по общему качеству она выглядит сильной.
Повторный пересмотр набора нужен после смены системного промпта, после замены модели или провайдера, после изменения анкеты, резюме или правил скоринга, а также после каждой жалобы, апелляции или ручного разбора.
Если команда гоняет такие проверки через разных провайдеров, ручная сборка быстро начинает мешать. Логи лежат в разных местах, один и тот же тест сложно повторить, а сравнение ответов занимает лишнее время. В такой схеме AI Router помогает держать один OpenAI-совместимый endpoint для разных моделей и собирать audit-логи в одном месте. Для компаний в Казахстане это еще и способ хранить данные внутри страны без отдельной сборки вокруг каждого провайдера.
Хороший рабочий порядок простой: каждый спорный случай пополняет набор тестов, а каждое изменение в модели или промпте запускает новый прогон. Тогда проверка дискриминации в скоринге и проверка дискриминации в найме остаются частью процесса, а не разовой формальностью перед запуском.
Часто задаваемые вопросы
Что вообще считать тестом на предвзятость?
Это парное сравнение почти одинаковых кейсов. Вы меняете один чувствительный признак, например имя, возрастной маркер или упоминание перерыва в работе, и смотрите, сдвигает ли модель оценку, тон или рекомендацию без новой деловой причины.
Почему мало проверять только явный отказ?
Потому что риск часто появляется раньше финального шага. Модель может не отказать прямо, но поставить человека ниже в очереди, написать жестче или попросить лишнюю проверку, а это уже толкает сотрудника к другому решению.
Сколько пар кейсов нужно перед запуском?
Для старта обычно хватает 10–20 пар на каждый этап, где ответ влияет на человека. Лучше взять несколько серий вокруг одного маркера, чем одну громкую пару: так вы быстрее поймете, где сбой повторяется, а где шумит формулировка.
Что можно менять в паре кейсов?
Меняйте только один признак за раз. Доход, стаж, навыки, опыт, история платежей, длина текста и тон описания держите одинаковыми, иначе вы уже не поймете, на что именно среагировала модель.
Какие пары полезны для скоринга?
Чаще всего берут район проживания, имя с читаемым полом, возрастной след в анкете, тип работодателя и стиль описания дохода при тех же цифрах. Если числа совпадают, а модель все равно двигает риск, стоит разбирать ответ глубже.
Какие пары полезны для найма?
В найме хорошо работают пары с одинаковым опытом и стеком, где меняются только имя, год выпуска, пауза в карьере, вуз, регион или просьба о гибком графике. Если роль не требует этого прямо, модель не должна из-за таких вещей занижать оценку.
Нужно ли повторять один и тот же тест несколько раз?
Да, один прогон почти ничего не доказывает. Прогоните ту же пару несколько раз в одной конфигурации и отдельно в рабочих настройках, чтобы увидеть, плавает ли итог, уверенность и текст объяснения.
Что делать, если итог одинаковый, но объяснение разное?
Такой сдвиг тоже считаетcя проблемой. Когда одна версия получает спокойное объяснение, а другая — подозрения и лишние догадки, сотрудник читает это по-разному и может принять разное решение даже при одной метке.
Как понять, что разница уже слишком большая?
Задайте порог до теста. На практике часто берут правило вроде «оценка не меняется больше чем на 1 балл из 10» и «рекомендация не меняется только из-за чувствительного признака», а все спорные пары сразу отправляют на ручной разбор.
Что делать после первого прогона?
После первого прогона сохраните промпт, версию модели, параметры и ответы, затем добавьте в набор реальные спорные случаи. Как только команда меняет модель, провайдера, системный промпт или форму анкеты, тест нужно запускать снова.