Роутинг по типу задачи: матрица моделей без лишних затрат
Роутинг по типу задачи помогает выбрать модели для суммаризации, извлечения, чата и кода так, чтобы снизить расходы и не потерять качество.
Почему одна любимая модель быстро становится дорогой
Одна модель для всех задач кажется удобной только в начале. Пока трафик маленький, разница в цене почти незаметна. Но как только запросов становится больше, вы начинаете платить как за сложную работу даже там, где нужен самый простой ответ.
Проблема обычно не в самой модели, а в том, что ей отдают все подряд. Один и тот же дорогой уровень ответа уходит и на разбор длинного договора, и на простое "сожми текст в 3 пункта". В рабочем продукте таких простых запросов много: краткая суммаризация, извлечение номера договора, определение темы обращения, проверка формата ответа. Для них не нужна модель, которая хорошо пишет код или долго рассуждает.
Есть и вторая потеря, менее заметная. Когда чат для клиентов, обработка документов и задачи разработчиков сидят в одной очереди, длинные тяжелые запросы начинают тормозить весь поток. Один большой запрос на код может задержать десятки коротких диалогов, где человеку нужен ответ за пару секунд.
На практике это выглядит очень приземленно. Допустим, служба поддержки получает 1000 запросов в день. Лишь малая часть из них требует сильной модели: спорные случаи, длинные жалобы, ответы по строгому регламенту. Все остальное - классификация, выжимка из переписки, поиск полей, короткий чат. Если отправлять это в один дорогой маршрут, счет растет быстрее, чем качество.
Потом начинается спор внутри команды. Кто-то говорит: "эта модель пишет приятнее", кто-то - "та звучит умнее". Но смотреть стоит не на вкус, а на цифры: где реально растет точность, где падает задержка и какие запросы съедают бюджет. Пока задачи не разделены, вкусовые предпочтения почти всегда побеждают факты.
Поэтому роутинг по типу задачи обычно дает более трезвый результат. Дешевые модели берут короткую рутину. Сильные остаются там, где без них правда нельзя.
Какие задачи стоит разделить в первую очередь
Начинать лучше не с десятков сценариев, а с нескольких понятных групп, где разница в цене и поведении видна сразу.
Суммаризация длинных текстов почти всегда терпит небольшую потерю "красоты" ответа. Если нужно сжать протокол встречи, договор или длинную переписку в 5-10 пунктов и не потерять смысл, часто хватает более дешевой модели с длинным контекстом. Дорогую модель разумно оставлять для документов, где цена ошибки выше: юридические формулировки, медицинские записи, сложные отчеты.
Извлечение полей из писем, PDF и форм стоит выделить в отдельный поток еще раньше. Здесь не нужен живой стиль. Нужна дисциплина: найти номер счета, ИИН, дату, сумму, статус заявки и вернуть все в строгой структуре. Модель, которая приятно ведет диалог, нередко хуже держит формат JSON. Для банков, ритейла и любого бэк-офиса это часто дает первую заметную экономию.
Чат с пользователем - другая история. Тут люди замечают тон, скорость и то, как модель держит контекст разговора. Ответ за 2 секунды обычно полезнее, чем идеальный ответ за 12. Поэтому для чата часто выбирают отдельную модель и задают свои лимиты на длину ответа.
Генерацию и правку кода тоже лучше не смешивать с обычным чатом. Кодовые задачи сильно зависят от точности синтаксиса, умения читать diff и следовать ограничениям проекта. Модель, которая хорошо пишет письма клиентам, может слабо править тесты или ломать существующую логику.
Отдельно стоит пометить редкие сложные случаи. Это те самые 5-10% запросов, где правила перестают работать: нечитаемый PDF, смешанный язык, длинная цепочка писем, нестандартный код, конфликтующие данные. Не надо подбирать для них "среднюю" модель. Проще отправлять такие запросы в более сильный маршрут по понятным признакам или сразу на ручную проверку.
На первом этапе обычно хватает пяти веток: суммаризация, извлечение, чат, код и исключения. Уже этого достаточно, чтобы снизить расходы без заметной просадки по качеству.
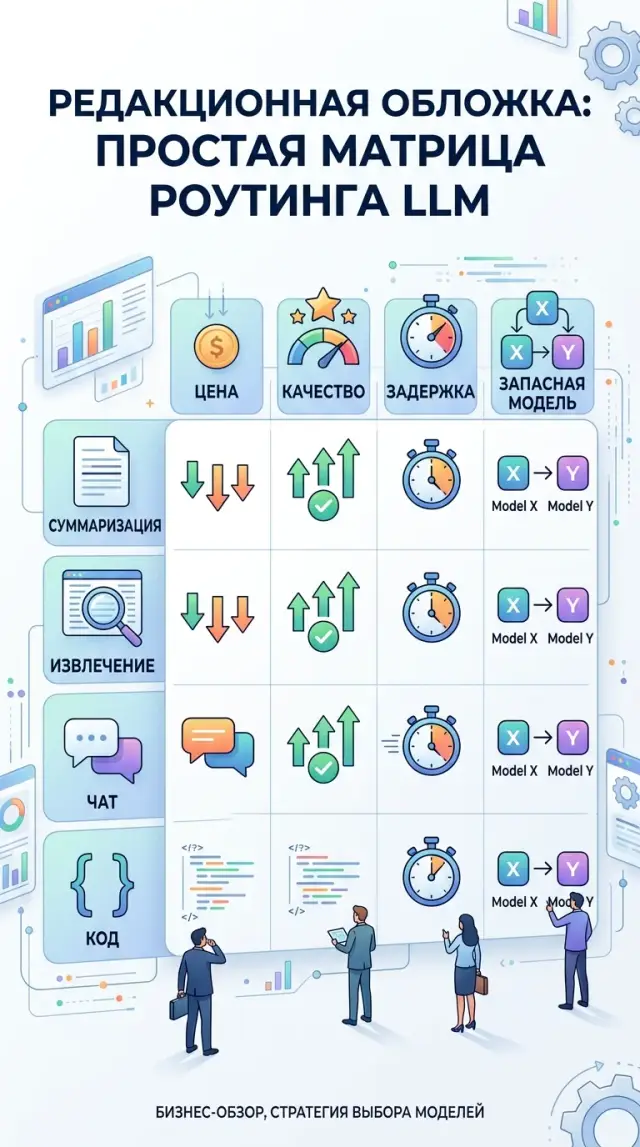
Матрица для суммаризации, извлечения, чата и кода
У разных задач разный риск ошибки. Для краткого пересказа важны цена и точность фактов. Для извлечения - стабильная структура. Для чата - скорость ответа. Для кода - тесты, а не красивый текст. Поэтому удобнее не искать одну "лучшую" модель, а собрать простую матрицу и закрепить за каждым типом задачи основной и запасной маршрут.
| Тип задачи | Что проверять в первую очередь | Что обычно подходит как основной маршрут | Что держать как запасной |
|---|---|---|---|
| Суммаризация | Цена за 1 млн токенов, длина контекста, ошибки в фактах | Недорогая модель с длинным контекстом и ровным стилем | Более точная модель для длинных или рискованных документов |
| Извлечение | Стабильный JSON, процент ошибок по полям, пропуски | Модель, которая строго держит схему и редко ломает формат | Более дисциплинированная модель, даже если она медленнее |
| Чат | Задержка, память диалога, тон ответа, число лишних слов | Быстрая разговорная модель со средней ценой | Более сильная модель для сложных кейсов и эскалаций |
| Код | Прохождение тестов, число правок после ответа, точность изменений | Модель, которая хорошо правит код в рамках файла или PR | Более сильная модель для сложной логики и рефакторинга |
Эта таблица полезна тем, что убирает разговоры "мне нравится". Вместо них команда смотрит на метрики.
С суммаризацией ошибка повторяется чаще всего: берут самую сильную модель и переплачивают. Если документ типовой, лучше начать с дешевой модели с большим окном контекста и проверить простую вещь: не перепутала ли она числа, сроки и имена.
Для извлечения лучше всего работает жесткий тест на 100-200 примерах. Здесь важна не общая "адекватность", а ошибки по каждому полю. Если модель стабильно теряет ИИН, дату или сумму, она не подходит, даже если пишет гладкий текст.
В чате задержка заметна сразу. Разница даже в 800 мс чувствуется. Еще важнее, чтобы модель держала контекст последних реплик и не меняла тон без причины.
С кодом правило простое: длинный ответ ничего не доказывает. Считайте, сколько задач прошло тесты с первой попытки, сколько правок внес разработчик и сколько времени ушло на доработку.
Если команда строит такую схему через AI Router, можно держать для каждого сценария основной и запасной маршрут под одним OpenAI-совместимым endpoint и переключать модели без смены SDK, кода и промптов. Это удобно, когда вы хотите проверить несколько вариантов без переписывания интеграции.
Как собрать роутинг шаг за шагом
Роутинг по типу задачи не начинают с выбора "самой умной" модели. Сначала нужен живой набор запросов. По каждой задаче обычно хватает 50-100 примеров: письма для суммаризации, формы для извлечения полей, диалоги поддержки, куски кода, техзадания. Берите то, что уже встречалось в работе, включая короткие, длинные и неудобные случаи.
Потом прогоните один и тот же набор через 3-5 моделей. Не меняйте промпт под каждую модель. Иначе сравнение получится нечестным. Смотрите на три вещи: качество ответа, среднюю цену и задержку. Иногда модель отвечает чуть лучше, но стоит в несколько раз дороже. Для суммаризации и извлечения это часто лишняя трата.
После этого задайте простые пороги. Для суммаризации ответ годится, если он сохраняет смысл и не теряет важные детали. Для извлечения поле считается верным только при точном совпадении. Для чата важны тон, полнота и число опасных промахов. Для кода мало проверить синтаксис - результат должен запускаться. По цене стоит сразу установить потолок на один запрос и на 1000 запросов.
Когда цифры готовы, напишите правила выбора без сложной логики. Короткие тексты на суммаризацию можно отправлять в дешевую модель, длинные и спорные случаи - в модель уровнем выше. Извлечение по шаблонным документам можно держать на отдельном маршруте, а чат с клиентом отдать модели, которая быстрее и реже ошибается в диалоге.
Такую схему легко проверить на реальной задаче. Допустим, банк обрабатывает обращения клиентов: сначала система определяет тип задачи, потом отправляет запрос по нужному маршруту, а не в одну дорогую модель для всего потока. Расходы обычно становятся заметны уже на первой неделе теста.
И еще один момент, который часто пропускают: запасной маршрут нужен с первого дня. Если провайдер начинает тормозить, упирается в лимит или временно недоступен, система должна уйти на резерв без ручного вмешательства. Если вы используете шлюз вроде AI Router, основной и резервный путь можно держать под одним API и менять маршрут без переписывания приложения.
Как мерить качество и расходы без сложной схемы
Считать только цену за 1 млн токенов почти бесполезно. Команда платит не за токены сами по себе, а за завершенный сценарий: разобрать письмо, достать поля, ответить клиенту, сгенерировать патч. Если одна модель дешевле по токенам, но чаще требует второй запрос или ломается на проверке, итоговая цена уже выше.
Для первого сравнения обычно хватает четырех показателей: цена одного завершенного прогона, время до первого токена, полное время ответа и оценка качества по простой проверке. Этого достаточно, чтобы увидеть, где роутинг действительно снижает расходы, а где только добавляет повторы и задержки.
Задержку полезно делить на две части. Время до первого токена показывает, насколько быстро человек видит начало ответа в чате. Полное время ответа показывает, когда задача закончена целиком. Для поддержки важнее первая цифра. Для бэк-офиса, где модель вытаскивает поля из документов, чаще важна вторая.
Для извлечения не нужен сложный бенчмарк. Возьмите небольшую выборку, например 50 документов, и проверьте руками нужные поля: ИИН, номер договора, сумму, дату, статус. Считайте долю верно заполненных полей и долю полностью верных записей. Эти две цифры быстро показывают разницу между моделями.
С суммаризацией команды часто спорят о стиле и теряют суть. Один ответ может звучать лучше, но пропустить срок, сумму или имя клиента. Поэтому сравнивайте факты: что произошло, кто участвует, какие есть числа, какой следующий шаг. Если модель потеряла факт, такой ответ хуже, даже если он выглядит аккуратно.
Для кода все еще проще. Запускайте тесты и считайте долю ответов, которые проходят их без правок. Отдельно отмечайте ответы, где разработчик тратит 5 минут на мелкую правку, и ответы, которые приходится переписывать почти с нуля. Это дает честную картину качества.
Если у вас единый шлюз для нескольких моделей и провайдеров, полезно хранить одинаковые логи для всех маршрутов. Тогда команда видит не то, какая модель нравится больше, а то, какая лучше решает конкретную задачу по цене, скорости и результату.
Пример для поддержки и бэк-офиса
В поддержке и бэк-офисе почти никогда не бывает одной задачи. За час приходят короткие вопросы в чат, длинные цепочки писем по тикетам, вложения в PDF и редкие запросы на SQL или правку кода. Если все это отправлять в одну дорогую модель, расходы растут без явной пользы.
Хороший пример - служба поддержки ритейла или банка. Клиент в чате спрашивает, где его заявка. Оператору нужна сводка по тикету за три дня. Бэк-офис получает письмо с договором и актом, где надо вытащить номер, дату и сумму. Потом аналитик просит поправить SQL для отчета. Это разные задачи, и им не нужна одна и та же модель.
Обычно лучше работает такое разделение. Чат клиентов уходит в быструю диалоговую модель с низкой задержкой. Сводка по тикету - в недорогую модель с длинным контекстом. Из письма и PDF система извлекает поля в строгом формате. Сложный SQL, патч или разбор ошибки идет в отдельный маршрут для кода.
Разница особенно заметна в потоке. Сто ответов в чате не должны ждать, пока одна тяжелая задача по SQL разбирает схему на 20 таблиц. Когда вы разводите очереди, лимиты и таймауты, массовые запросы идут быстро, а редкие сложные задачи не забивают весь канал.
Самая частая ошибка здесь простая: команда видит сложные кейсы и поднимает модель для всех. В итоге чат и извлечение начинают стоить как кодовая задача, хотя пользы от этого почти нет. Намного разумнее сначала разделить поток, а потом сравнивать качество внутри каждого типа задачи.
Где команды ошибаются чаще всего
Первая ошибка - ставить на все подряд одну модель, которая хорошо выглядела в демо. На презентации она уверенно отвечает в чате, но в реальной работе у вас есть и суммаризация, и извлечение полей, и короткие классификации, и код. Для этих задач нужны разные сильные стороны, а платить по верхней ставке за каждую мелочь бессмысленно.
Вторая ошибка - проверять модели на удобных примерах. Люди берут десять аккуратных запросов без опечаток, без длинных вложений и без странных формулировок. Потом схема ломается на живых данных: в письмах смешаны русский, казахский и английский, в документах плохой OCR, а в чатах пользователи пишут обрывками. Даже 100-200 реальных примеров дают честнее картину, чем красивый набор, собранный вручную.
Третья ошибка - смотреть только на цену токенов. Дешевая модель может проиграть по цене результата, если она чаще ошибается, просит повторный прогон или заставляет сотрудника исправлять ответ руками. Для суммаризации полезно считать цену принятого резюме, для извлечения - цену корректного набора полей, для чата - цену решенного обращения.
Четвертая ошибка - не делать запасной маршрут. Если провайдер тормозит, режет лимит или временно недоступен, часть запросов просто падает. Пользователь видит пустой ответ, а команда потом долго ищет причину. Намного спокойнее сразу держать второй путь для задач того же типа, пусть даже с чуть более мягкими требованиями.
Еще одна проблема - роутинг по отделам вместо роутинга по типу задачи. У бэк-офиса и поддержки могут быть одинаковые задачи на извлечение. У юристов и продуктовой команды - похожая суммаризация длинных документов. Если строить матрицу по отделам, она быстро разрастается и начинает мешать.
Рабочая логика проще: сначала определить тип выхода, потом выбрать модель. Если нужен короткий структурированный JSON, это одна ветка. Если нужен живой диалог, другая. Если нужен код, третья. Такой подход обычно дает меньше ошибок и заметно снижает расходы.
Быстрая проверка перед запуском
Сама идея роутинга редко ломается на моделях. Чаще она ломается на мелочах: команда не договорилась о метриках, не поставила потолок по цене и не записывает, что именно сработало. Из-за этого первые дни выглядят нормально, а через неделю счета растут, ответы плавают по качеству, и никто не понимает, где причина.
Перед запуском полезно пройти короткую проверку. Для каждой задачи нужна своя метрика качества. У суммаризации это точность фактов и длина ответа, у извлечения - точность полей, у чата - полезность или доля решенных обращений, у кода - pass rate на тестах. Одна общая метрика для всех сценариев обычно врет.
У каждой модели должен быть понятный лимит цены. Если запрос дороже заданного порога, маршрут должен уйти на более дешевую модель или сократить контекст. Иначе одна тяжелая ветка быстро съест весь эффект от схемы.
У каждого маршрута нужен запасной вариант. Логи должны хранить не только текст запроса, но и тип задачи, выбранную модель, стоимость, задержку и итоговую оценку качества. И еще стоит заранее решить, кто в команде меняет правила роутинга. Если пороги и маршруты правят все подряд, система быстро превращается в хаос.
Есть и простой тест перед запуском. Возьмите 20-30 живых запросов по каждому типу задачи и прогоните их вручную. Если хотя бы по половине примеров команда спорит, какая модель победила, правило еще сырое. Если победитель виден почти сразу, маршрут готов.
Что сделать в ближайшие две недели
За две недели можно собрать пилот, который покажет цифры, а не мнения. Для старта не нужен большой проект. Достаточно небольшого набора реальных запросов, первой матрицы и проверки на части трафика.
Неделя 1
Соберите 30-50 живых примеров из рабочих потоков. Возьмите не только удачные случаи, но и те, где модель путается, тянет лишний текст или дает слишком дорогой ответ. Промпты лучше оставить как есть, без косметической правки, иначе тест получится слишком красивым.
Разложите примеры на четыре группы: суммаризация, извлечение полей, чат и код. Для каждого примера коротко запишите, что считается нормальным результатом. Этого уже хватит для первой оценки.
После этого соберите простую матрицу: тип задачи, основной маршрут, запасной маршрут, предел цены за запрос и критерий качества. На этом шаге обычно быстро видно, что суммаризацию и извлечение можно отдать более дешевым моделям, а чат и код оставить более сильным.
Неделя 2
Пустите через новую схему 10-20% трафика. Не меняйте все сразу. Сравните итоговую цену, задержку и ручную оценку ответа на одном и том же наборе задач. Если извлечение держит точность, а чат не стал хуже по тону и полезности, матрица работает.
Если вам нужен один OpenAI-совместимый endpoint для такой схемы, AI Router позволяет поменять base_url на api.airouter.kz и продолжить работу с теми же SDK, кодом и промптами. Это удобно, когда вы не хотите собирать отдельные интеграции под каждого провайдера.
Если у команды есть строгие требования, их лучше проверить до расширения пилота. Для компаний в Казахстане это часто часть архитектуры, а не формальность: хранение данных внутри страны, audit-логи, маскирование PII и rate limits на уровне ключа. В AI Router такие вещи уже предусмотрены, поэтому пилот можно собрать быстрее и без лишней обвязки вокруг API.
Роутинг по типу задачи хорош не тем, что делает схему сложнее. Он убирает лишнюю дороговизну и возвращает здравый смысл: простые запросы должны стоить дешево, сложные - получать сильную модель только там, где это действительно нужно.
Часто задаваемые вопросы
Почему одна модель для всех задач быстро выходит дороже?
Потому что вы платите по высокой ставке даже за простые запросы. Короткая суммаризация, классификация или извлечение полей редко требуют сильной модели, а длинные тяжелые запросы еще и тормозят весь поток.
Какие задачи лучше разделить в первую очередь?
Начните с четырех групп: суммаризация, извлечение полей, чат и код. Уже такое деление обычно снижает счет, потому что каждая группа требует разной скорости, точности и цены.
Сколько примеров нужно для первого теста моделей?
Для первого круга обычно хватает 50–100 живых примеров на каждый тип задачи. Берите не только аккуратные случаи, но и длинные письма, плохой OCR, смешанный язык и обрывочные сообщения.
Как понять, что для суммаризации хватит более дешевой модели?
Смотрите не на стиль, а на факты. Если модель держит смысл, не путает числа, сроки и имена, а цена заметно ниже, ее можно ставить на типовые документы.
Что проверять в задачах на извлечение полей?
Проверьте точное совпадение по каждому полю: ИИН, номер договора, дату, сумму, статус. Если модель пишет приятный текст, но теряет поле или ломает JSON, для извлечения она не подходит.
Почему для чата часто нужна отдельная модель?
В чате человек сразу чувствует задержку и сбои в контексте. Лучше дать ответ за пару секунд ровным тоном, чем ждать долго ради небольшого выигрыша в формулировках.
Как честно оценивать модель для кода?
Не верьте длинному ответу на слово. Гоняйте тесты, считайте, сколько задач проходят с первой попытки, и смотрите, сколько времени разработчик тратит на правки после ответа.
Когда стоит отправлять запрос в более сильную модель?
Сильный маршрут нужен там, где ошибка дорого стоит или случай выбивается из правил. Туда обычно попадают длинные жалобы, рискованные документы, нестандартный код, нечитаемые PDF и конфликтующие данные.
Зачем держать запасной маршрут с первого дня?
Резерв спасает поток, когда провайдер тормозит, упирается в лимит или временно недоступен. Если запасного пути нет, часть запросов просто падает, и команда разбирает аварию вручную.
Как запустить пилот роутинга за две недели?
Соберите 30–50 реальных примеров, разложите их по типам задач и задайте простые метрики качества и потолок цены. Потом пустите через новую схему 10–20% трафика и сравните цену, задержку и результат на тех же сценариях.